在数据库表、文本文件和数据馈送中对文本进行加盐的制作方法
本发明的领域是对数据进行加盐以确定数据是否被不当地复制或使用,且具体而言用于为此目的对消费者数据进行加盐。加盐是将独特数据(盐)插入数据子集,使得在数据被泄漏的情况下,被包含在该数据子集中的数据可被标识回数据所有者的机制。
背景技术:
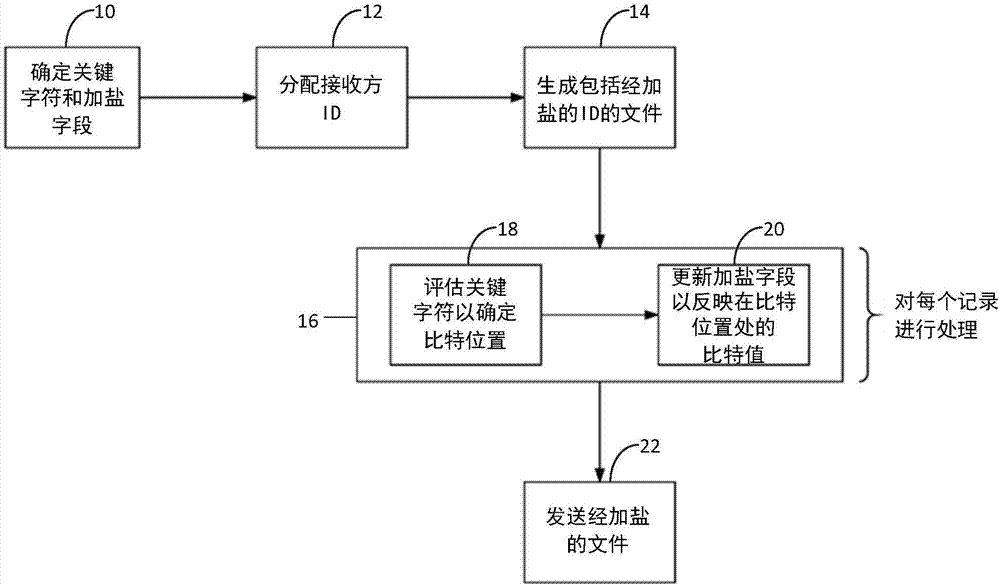
:本背景部分中提到的参考不被承认是相对于本发明的现有技术。数据泄漏可被定义为除所有者或授权用户以外的其他人偷用数据。估计每年全球数据泄漏的财务影响达数亿美元,并因此代表了数据服务行业中一个非常重要的问题。试图防止数据泄漏的解决方案已经存在一段时间了。这些解决方案防止数据泄漏到组织的防火墙之外,或在数据离开防火墙并在开放网络上“走钢丝”般移动时对其进行加密。还存在一旦图形、视频、音频、或文档(即文本或pdf)数据实际以明文暴露在防火墙外则声明该数据的所有权的解决方案;各组织使用这些众所周知的“数字水印”解决方案以保护其数据免遭滥用。(术语“水印”借用于印刷媒体,其中水印由印刷文档上的印记图像或图案组成以验证真实性,而数字水印是出于相同目的嵌入数字文件中的一种标记。)水印允许数据所有者追讨无授权使用的赔偿因为他们可在法庭上将水印用作所有权和版权侵权的证据。与此同时,这种法律救济措施的存在阻碍了个人或团体希望获得并随后免费使用此受版权保护的材料。遗憾的是,无论在使用时以明文还是密文传输,文本和数据库文件的数据泄漏仍然是未解决的问题。消费者数据的所有者(“数据所有者”)经常将其数据给予、租赁、或贩售给被受信仅以合法方式、遵守合同要求或数据处理规定(诸如金融服务中的b条例或地方、州或联邦政府制定的隐私法)使用该数据的个人或组织(“受信的第三方”或“ttp”)。此数据通常作为一系列数据库表(例如.sql格式)、文本文件(例如.csv、.txt、.xls、.doc和.rtp格式)、或作为实时数据馈送(例如,xml或json)传送。尽管如此,经常发生数据所有者的数据泄漏(被泄漏的文件在本文被定义为“被泄漏的子集”)到那些没有正当许可甚至非法地故意或无意使用该数据的其他人(“不良行为者”)的手中。这可能因为以下原因而发生,例如,ttp故意发布数据并且其本身就是不良行为者;ttp的员工故意或意外地发布数据;或数据所有者本身的员工故意或无意地泄露数据。这在业内有时称为“最后一英里”问题,因为就是在从数据所有者到数据用户的一系列步骤的最后一步,原文数据从安全形式转变为容易发生泄漏的格式。数据库和文本文件的水印提出了独特的挑战。图像、视频或音频文件密集且高度结构化。在这些文件中嵌入少量数据作为水印而不降级文件的信息内容或用户体验是容易的,因为这些类型的文件是抗噪声的。抗噪声文件是一种可在不降级结果数据的情况下添加少量噪声(诸如水印)的文件;例如,可通过改变少量数据比特或改变相邻帧的顺序将水印添加到视频文件中,而观看者不会注意到该变化。以此同时,这种类型数据的高度结构化特性使得不良行为者很难移除水印。相比之下,数据库表和文本文件比较轻质,并因此不能容忍噪声的引入。例如,更改姓名或地址中的单个字符都可能会导致该记录中的数据无效。这种类型的数据的结构可能容易地以使得水印易碎、易于检测、并因此容易使试图确定数据被不当使用的那方无法识别的方式(例如,重排序、追加行、删除行)被操纵。例如,数据表内的各元素可被更改;数据可与来自其他数据源的数据合并;并且数据可被划分为子集和/或以其他方式重排和操纵以避免检测。因此,对于想要声明数据库或文本文件(或其json或xml等价物)的所有权和/或检测对泄漏数据负责的机构的数据所有者而言存在重大障碍。数据所有者也不能通过法律行动容易地追讨收入损失,因为其缺少符合适用证据标准的不法行为的证据。此外,当前用于检测数据泄漏的方法主要通过手动操作,且因此是耗时、劳动密集、昂贵、且容易出错的。因此,对这些类型的文件加水印或“加盐”的经改进的系统和方法将是非常有益的。技术实现要素:本发明涉及一种用于对数据库表、文本文件、数据馈送等类似数据加盐(或应用水印)的方法,其在本文中被称为“水平”加盐。水平加盐是由本文发明人开发的水印技术,其中对全套数据或数据子集进行微小的独特的且可标识的改变。水平加盐基于以下两个部分影响数据文件:关键字段和经过评估的该字段中的字符位置;以及包含在不影响数据可用性的情况下可合法地处于至少两种状态之一的内容的加盐字段。在各种实施例中,这些部分可以是记录中的相同字段或不同字段。在某些实施例中,关键字符可具有各种各样的值,诸如全系列的字母数字字符。术语“水平”加盐是本文创造的,因为更改是针对个体数据记录进行的,当数据文件以表格格式排列时,各个体数据记录通常被描绘为各个体行;因此,从以逐行方法进行操作的意义上来说,加盐是“水平的”。此方式的结果是,如下文将解释的,不必分析整个文件以找到盐,而是仅需分析少量的行或在一些情况下甚至仅需分析一行。这极大地提高了该处理的计算速度。根据本文描述的本发明的某些实现的水平加盐系统遵循以下原则:1.限制扰动。除指纹识别之外的每种形式的水印都涉及一些数据扰动。问题在于,在数据质量受到损害到足以使其无法使用之前,可将多少扰动插入到数据库中。此外,数据是否无法使用很大程度上取决于其预期用途。例如,在邮件列表中更改哪怕一个人的姓名都会造成商业后果,而加水印可能需要更改多个姓名。因此,在此用途中将此字段用于加水印目的是不可能的。但是,如果名字是用于医疗数据统计分析的数据库的一部分,则名字的轻微变化可能是可容忍的。2.水印的独特性。水印对用途所需的粒度级别而言应该是独特的。在商业系统中,水印被用于声明公司的所有权,并标识最可能泄露该数据的个人和公司。因此,在此用途中,绑定至公司的水印可能是合理的粒度级别。针对每个文件具有不同的水印可提供甚至更高的精度,但这增加了创建和检测水印所需的系统的大小。每次规模增加都有相关联的成本,而在公司级加水印可行时,文件级粒度级别可能太昂贵而不值得付出努力。在本发明的某些实现中,系统具有在文件级或客户级应用高度独特的水印的灵活性。这是通过为文件或客户分配收件方id来实现的,如下文所解释的。3.不可行性。理想情况下,标识数据库或文本文件中的水印既不需要知道原始的未加水印的数据库也不需要知道水印信息。这一性质很重要,因为它允许在数据库的副本中检测水印,即使原始数据源是未知的。本文给出的系统不需要知道原始的未加水印的数据库,也不需要知道水印信息。相反,系统处理带水印的野生文件以检索水印。可将检测到的水印及其对应的收件方id与数据库进行匹配以检索水印的所有者。4.不干涉性。在野生发现的文件可能包含来自两个或多个源的数据,其中任何一个数据都可能已被加了水印。因此,一个水印的存在不应干涉文件中另一水印的发现。本系统能够检测文件中的多于一个的水印。水印检测处理试图从野生文件中发现所有可能的水印和相应的收件方id以匹配回水印数据库以检索野生文件的所有者。5.对罪责的法律确认的充分性。任何商业水印系统都必须产生可在法庭上举证的水印。独特的水印是一个良好的开端。但在法庭上,可能不仅必须证明水印属于特定公司的档案,而且检索到的水印不能与用于另一家公司的水印相混淆。系统输出检测到的水印以及收件方id。收件方id将与水印数据库进行匹配,以确保在水印应用于文件时系统分配检测到的收件方id。在检测到单个水印的情况下,极有可能找到数据的所有者。在检测到多个水印的情况下,系统提供的信息将充当指向性线索以潜在地发现文件中数据的多个源。作为本文所述的水平加盐的结果,被泄漏的子集或“野生文件”中包含的数据,即使被改变,也可被标识为已经被给予特定收件方和接收方接收到的特定文件。标识不良行为者和特定的被泄露的数据集的处理被称为罪责分配(guiltassignment)。罪责分配允许数据所有者基于数据的水平加盐建立强有力的证据案例,通过该证据案例可起诉不良行为者。水平加盐很难被不良行为者检测到,并因此不良行为者很难或不可能移除水平加盐,即使不良行为者知道数据已经或可能已经被加盐。水平加盐因此降低了潜在的不良行为者真正不当使用其首先获得的数据的可能性,因为潜在的不良行为者知道此类不当使用会被检测到并导致法律行动。本发明的这些和其他特征、目标及优点将通过结合如以下描述的附图考虑以下对优先实施例和所附权利要求书的详细描述而变得更好理解。附图说明图1例示了根据本发明的实施例的将盐添加到新文件的处理。图2例示了根据本发明的实施例的分析未知来源的文件是否存在盐的处理。图3例示了根据本发明的实施例的加盐系统的基础设施和架构。具体实施方式在本发明被更详细描述之前,应理解,本发明不限于所描述的特定实施例和实现,并且在描述特定实施例和实现时使用的术语仅用于描述那些特定实施例和实现的目的,而不旨在进行限制,因为本发明的范围将仅通过权利要求书来限制。为了开始讨论本发明的某些实现,相关联的技术陈述的精确定义如下。设d是数据库,包括但不限于公司c所拥有的平面文件。d由关系形式的元组或结构化文本(例如,.csv、xml或sql数据)组成。设si是来自d的元组的子集。设m是生成w的独特的方法,w是d或比d小得多的si的表示。目标然后变为生成w使得:1.w是针对给定m的d或si的独特的“指纹”(即,m不能针对两个不同的d或si生成相同的w)。2.使用统计置信度w可确定代理人a1对于其他代理人a2、a3、……an而言是分配或改变d或s1的不良行为者,代理人a2、a3、……an接收d的副本或与s1部分重叠的不同的si。3.w将足够牢靠以满足证据标准,以便证明d’(d的第二副本或子集)是在未经c同意的情况下创建的。这意味着假阴性(在d’合法时将其标识为是非法的)或假阳性(将d’非法时将其标识为是合法的)的概率必须极小。4.即使不良行为者知道m,w也是不可读或不可复制的。5.在为特定ai生成d或si时,w必须不会导致丢失来自d或si的信息。6.如果m将w嵌在d中,则恢复w是不可行的。也就是说,当且仅当d’和d,或者分别取自d和d’的精确复制s和s’相等时,才可在不知道d的情况下从d’获得w。7.创建w的过程必须足够牢靠,以处理d和d'之间的元组的显著差异(例如,额外的空格、数据求助(resort)、元组删除、元组相加)而不会生成假阴性。8.m必须考虑到来自c的di定期更新成dj,并允许将di与dj进行区分的能力。9.m必须是利用容易获得的计算设备在计算上可行的。10.当d或si变为d’或si’时,m无需精确地标识变为d’或si’所作出的变化,尽管对d’或si’的详细检查可以而且应该为作为ai是不良行为者的指示的w提供支持证据。通过实现满足这些要求的本文所描述的水平加盐方法,数据所有者可更频繁地将被泄漏的子集标识为源自其自己的数据集,并甚至标识最初发送数据的ttp。这是通过分析被泄漏的子集内的某些数据元素来完成的,其中巧妙地嵌入了针对数据和接收方独特的标识符(“盐(salt)”)。在没有预先知道加盐机制的情况下就无法检测到该盐,因为对于未经训练的眼睛而言它是不可见的。如上所述,水平加盐基于以下两个部分影响文件:关键字段和经过评估的该字段中的字符位置(“keycharacter(关键字符)”);以及包含在不影响数据可用性的情况下可合法地处于至少两种状态之一的内容的加盐字段(“saltingfield(加盐字段)”)。这些部分可以是相同的字段或不同的字段;但是,关键字符不能被加盐方法可能使用的各种状态修改。理想情况下,关键字符应具有各种各样的值,诸如全系列的字母数字字符。更广泛且更均匀地分配各值,关键特征将更好地服务于其目的,如下文所解释的。加盐字段的不同且合法的状态可能包括:数字值精度的变化(例如,1.00对照1.0);缩写使用的变化(例如,road对照rd);标点符号使用的变化,诸如句点(例如,jr.对照jr);使用或不使用称呼(例如johndoe先生对照johndoe);字体变化的应用,诸如书名中的斜体(例如,指环王对照指环王)等等。分配给数据的接收方的独特标识符通过使用加盐字段中的状态变化表示二进制0或1隐藏在数据中,其中关键字符的值标识独特标识符中二进制0或1的比特位置。作为示例,为了说明的目的而简化,可为非常小的一组可能的接收方中的一个接收方分配独特的标识符6,在二进制中以值0110来表示。假设接收方已发送包括性别(gender)和以厘米为单位的身高(height)字段的数据,其中性别字段可能包含的值为“m”、“f”、“u”和空,而其中身高字段包含具有百分之一厘米精度的值。性别字段中的第一(也是独特)字符可被用作关键字符,其中值“m”对应第1比特、“f”对应第2比特、“u”对应第3比特、且“”(空)对应第4比特,而身高字段可被用作加盐字段,其中精度为百分之一的值指示二进制值0,精度为千分之一的值指示二进制值1。在检查来自经加盐的数据中的一些记录时,可看到以下内容:性别,身高m,183.63f,177.420f,180.220,166.17m,179.11u,175.130u,168.960在检查数据时,可以看到第一记录保存与第一比特位置相关的加盐数据(因为其在性别字段中具有值“m”)和值0(因为身高字段具有的精度为百分之一)。第二记录保存与第二比特位置相关的加盐数据(因为其在性别字段中具有值“f”)并且我们知道第二比特位置的值是1(因为身高字段具有的精度为千分之一)。对各记录的进一步分析支持比特值0110,并因此我们知道该文件被发送给被分配了该标识符的接收方。虽然这是一个简单的示例,并且一旦知道机制加盐就相对容易被发现,但在具有更多字段且并非已知加盐机制的较大数据文件中,盐可能是非常难以手动标识的。现在参考图1,可更详细地描述根据本发明的实现的用于创建经加盐的文件的系统。在步骤10,为将被加盐的文件确定关键字符和加盐字段。在上文的示例中,关键字符是性别字段,而身高字段被用作加盐字段。这只是一个示例,并且如上所述,根据可用的数据字段,许多其他类型的字段都可被用作关键字符和加盐字段。某些类型的数据记录,诸如综合消费者数据库中包含的记录(例如由acxiom公司维护的infobase数据库)可能针对与消费者或家庭有关的每个记录包括数百个数据字段;在这种情况下,存在许多可被用作关键字符和加盐字段的候选字段,这进一步使试图阻挠加盐系统的人的任务复杂化。在步骤12,接收方id被分配给文件。此信息由数据提供者维护在一个表中,该表将针对该文件的数据(诸如创建日期、数据类型、接收数据的实体和数据用途)与接收方id数据库中的接收方id相匹配。在步骤14,使用盐修改文件以产生经加盐的文件。此处理包括针对原始文件中的每个记录的迭代的两步操作(步骤16)。首先,在子步骤18,关键字符被评估以确定比特位置。其次,在子步骤20,此记录中的加盐字段被更新以反映在比特位置处的比特值。一旦每个记录都在步骤18被处理,经加盐的文件就完成了,并可在步骤22被发送给客户。现在参考图2,更详细地描述了用于确定野生文件中盐的存在的处理。在步骤30,文件被数据提供者接收,并且在步骤32,将文件的字段与来自数据提供者的接收方id数据库的已知关键字符和加盐字段进行比较。对所有已知的接收方id重复此操作,这将解释不良行为者已合并多个经加盐的文件的情况。如果在步骤34没有找到匹配,则该处理在步骤36结束,指示在文件中没有找到盐。如果找到匹配,则处理继续在步骤38评估每种可能的盐的字段组合。这涉及迭代处理,如果需要,则对文件中的每个记录执行步骤40。子步骤42评估关键字符以确定比特位置。子步骤44评估加盐字段以确定比特位置处的比特值。一旦每个记录都在步骤40被处理,就在步骤46将确定盐的存在或缺失的分析结果返回给数据提供者。现在参考图3,现在可描述用于实现上述处理的计算机网络系统的物理结构。网络50(诸如因特网)被用于访问系统。虚拟专用网络(vpn)52可被用于提供进入到“dmz”区域中的安全连接,即,在进入系统防火墙之前,对外部文件进行检疫隔离的区域。使用安全文件传输协议(sftp)系统,文件可被传输到sftp外部负载平衡器54;ftp是一种众所周知的网络协议,用于在计算机网络上在客户端和服务器之间传输计算机文件。ui/app外部负载平衡器56可被用于接收由计算机应用发送的文件,并且ap外部负载平衡器58可被用于接收根据应用编程接口(api)发送的文件,这是开发允许在应用软件之间的通信的子程序定义、协议和工具的众所周知的概念。系统的负载平衡器可确保系统中的各个服务器不会因文件请求而过载。现在移动到系统的前端层,与其自己的sftp服务器可恢复存储62相关联的sftp服务器60在通过ftp发送的文件从dmz区域传到之后接收该文件。同样地,ui/app内部负载平衡器64在文件离开dmz区域之后从ui/app外部负载平衡器56接收文件,并将它们传递给一个或多个ui/app虚拟机(vm)66(图3中示出了两个ui/app虚拟机)。移动到服务区域,这些子系统将数据传递给api内部负载平衡器70,该api内部负载平衡器将信息传递给一个或多个apivm72(同样,图3中例示了两个apivm)。在系统后端,来自apivm72的数据传递到文件分层推理引擎(flie)内部负载平衡器76,其将信息传递到一个或多个filevm78。flie系统的目的是自动标识输入数据文件的每个字段中的数据类型。除了将数据传递到flie系统之外,apivm72还将数据传递到处理集群和数据存储82,该处理集群和数据存储82被配置为将数据存储在一个或多个多租户数据存储84中,每个多租户数据存储84都与一个数据存储可恢复存储区域86相关联(图3中例示了其中三组)。存储在多租户数据存储84中的数据的示例包括接收方id和与每个文件的水印相关的其他数据。在开发和测试本文描述的系统时考虑了许多类型的攻击。其中包括以下内容:1.良性更新。经标记的数据可被添加、删除或更新,这可能移除嵌入的水印或者可能使嵌入的水印变得不可检测。2.子集攻击。删除或更新数据的子集。3.超集攻击。一些新的数据或属性被添加到带水印的数据库中,这可能会影响水印的正确检测。4.共谋攻击。此攻击要求攻击者能访问同一文件的多个带水印的副本。三种测试方案被用于测试针对这些攻击类别的有效性。在第一种方案下,删除被采用(通过从经加盐的文件中移除多个记录来测试检测到盐的可能性)。这与子集和良性攻击有关。在第二种方案下,插入被采用(测试随机插入数据文件的不同数量的未经加盐的记录的插入)。这与良性和超集攻击有关。在第三种方案下,混合接收方id测试被采用(通过组合从多于一个接收方id生成的经加盐的记录来测试检测到盐的可能性)。这与共谋攻击有关。在第一种方案下,以下步骤被执行:1.从2014年1月的infobase的1%文件中抽取100k个记录的随机样本。(infobase是由acxiom公司维护的综合消费者数据库文件。)此文件被称为数据文件。2.使用一个接收方id对整个数据文件进行水平加盐。3.通过随机地移除10k来减少数据文件中的记录的数量。此文件被称为野生文件。4.检测并记录野生文件中存在的接收方id比特的数量。5.如果接收方id比特的数量等于36,则重复步骤3和4,否则转到步骤6。6.通过随机地移除1k个记录来减少数据文件中的记录的数量。7.检测并记录野生文件中存在的接收方id比特的数量。8.如果野生文件中的记录的数量大于1k,则重复步骤6和7,否则转到步骤9。9.通过随机地移除500个记录来减少数据文件中的记录的数量。10.检测并记录野生文件中存在的接收方id比特的数量。11.通过随机地移除400个记录来减少数据文件中的记录的数量。12.检测并记录野生文件中存在的接收方id比特的数量。该测试的结果如表1所示:记录的数量接收方id比特的数量20000+36200003610000369000348000347000346000325000314000293000282000281000255002310021表1可以看出,对于大小超过10k个记录的野生文件,标识和匹配的接收方id比特的数量是36,这导致在68b分之一的独特性,并因此置信区间100%有效。在野生文件大小为100到10k个记录的情况下,标识和匹配的接收方id比特的数量在22至35之间,这导致在4mm分之一的独特性,并因此置信区间大于99%。即使在大小为100个记录的非常小的野生文件的情况下,标识和匹配的接收方id比特的数量是21,这导致2.1mm分之一的独特性,并因此置信区间约99%。测试结果例示,10k是使全部36个接收方id比特(即0-9、a-z)可被标识的最小文件大小。当全部36个接收方id比特被标识时,野生文件包含水平加盐的置信区间是100%,因为36个接收方id表示680亿分之一的独特性。当文件大小低于10k时,接收方id比特的数量减少;但是,测试显示系统仍可标识21个接收方id比特,而野生文件中的记录只有100个。21个接收方id的标识表示2.1mm分之一,这导致接近99%的极高的置信区间。因此,这意味着系统处理和可扩展性,因为系统不需要处理完整文件以分配罪责。在100个记录的批次中处理增量记录直到系统标识出21个接收方id就足够了。在第二种方案下,以下步骤被执行:1.生成5000个接收方id以模拟在任何给定时间估计的最大客户帐户的数量。2.从2014年1月的infobase的1%文件中抽取5k、50k、和100k个记录的随机样本。这些文件被称为数据文件1、数据文件2以及数据文件3。3.在步骤1中随机选择各接收方id中的一者以对每个数据文件进行完全水平地加盐。4.对于数据文件1、数据文件2和数据文件3,插入从2015年1月的infobase的1%文件中随机选择的1%(相对于数据文件大小)的未经加盐的记录。这些文件被称为野生文件1、野生文件2以及野生文件3。5.检测并记录野生文件中存在的接收方id比特的数量。6.通过插入20%、40%、60%和80%的未经加盐的记录(随机地选择的记录)来重复步骤3。7.检测并记录每个区间处野生文件中存在的接收方id比特的数量。该测试的结果如表2所示:表2基于跨从上面的测试结果表2中观察到的测试文件标识的大数量的接收方id比特(大于31),测试结果例示了大于99%的高置信水平,系统可跨不同的野生文件大小和插入百分比检测水平加盐而不受随机记录插入的影响。在第三种方案下,执行以下步骤以测试检测两个、三个和五个接收方id生成盐的能力,该两个、三个和五个接收方id具有来自任何接收方id的未知数量的经加盐的记录。方式是通过生成五千个接收方id来模拟存在五千个客户端的方案:1.生成5000个接收方id以模拟在给定时间估计的最大客户帐户的数量。2.从2014年1月的infobase的1%文件中抽取每个都包含100k个记录的两个随机样本。这些文件被表示为数据文件1和数据文件2。3.使用5000个接收方id中的一个接收方id对整个数据文件1进行水平加盐。4.使用在步骤1中从5000个接收方id中随机选择的第二接收方id对整个数据文件2进行水平加盐。5.插入从2015年1月的infobase的1%文件中随机选择的10k(原始数据文件大小的10%)未经加盐的记录。6.使用置信区间:100%、80%、70%和60%检测并记录野生文件中存在的接收方id比特的数量。在100%处,接收方id比特(非1即0)由该比特此刻100%被映射到相同比特来确定。在80%处,接收方id比特由该比特此刻至少80%被映射到相同比特来确定。其余的区间(70%和60%)都遵循相同的规则。7.在步骤6中检测并记录每个区间处野生文件中存在的接收方id比特的数量。执行这些步骤的结果如表3所示:表3测试结果例示,当野生文件是使用两个不同的接收方id合并两个经加盐的数据文件的结果时,系统可完全标识全部接收方id。该系统非常有效,因为它可(从5000个潜在的接收方id)缩小到10个潜在的接收方id,该10个潜在的接收方id包含野生文件中存在的全部三个接收方id。当接收方id的数量超过三个时,测试显示存在太多可能经标识的接收方id,这对自动化系统而言可能是无效的;然而,据信,在现实生活中,不良行为者很难合并来自同一数据提供者的两个以上的经加盐的数据文件。作为来自该测试的总体结论,可以看出水平加盐机制很容易在记录被插入或删除以及文件被合并的常见攻击中幸存。具体而言,测试结果证明该系统可以在大多数插入/删除方案下以>99%的置信度标识接收方id;在只有100个记录的方案下以约99%的置信度标识接收方id;当野生文件包含两个接收方id时,在合并攻击下以100%的置信度标识两个接收方id;以及当野生文件包含3个接收方id时,消除全部接收方id的99.8%,从而提高此数字水印处理的计算速度和效率。可以看出,所描述的本发明的实现产生了用于确定给定数据文件的接收方而不会使该接收方意识到或破坏数据的可用性的独特方法。此外,该系统是可扩展的,能够在流通的一系列潜在的数百万的“野生”文件中标识文件及其接收方的独特性。为了实用,商业级水印系统必须能够每天处理数百个文件,这意味着整个处理基础设施必须是可延伸的和可扩展的。在这个大数据时代,要处理的数据文件的大小范围很大,大小从几兆字节到几太字节不等,这些文件流入系统的方式可能非常难以预测。为了构建可扩展的系统,必须建立预测模型以估计在任何给定时间的最大处理要求,以确保系统大小被调整成能够处理该难以预测性。根据本文描述的实现的加盐系统具有对数据文件、数据库表和无限大小的数据馈送进行加盐的能力。然而,处理速度也很重要,因为客户不能等待数天或数周以在文件被传送之前进行加水印。他们可能每天(并可能甚至更快)都会发布对其基础数据的更新。系统必须能够在生成下一文件的周期内对文件加水印,否则系统将出现瓶颈且文件将落入队列中,这将导致整个业务模型崩溃。因此,边缘可行的产品(mvp)发布必须在约20秒内具有1mm记录的最小加盐吞吐量。对于任何给定文件大小的野生文件,盐检测过程需要处理少至100个记录以便确定水印的存在。在mvp发布中检测水印的处理时间是几秒钟。计算能力降低,因为不需要解析整个文件以及将野生文件与主数据库相匹配以确定野生文件是否是被盗用的。不需要人类交互和检查作为使用此系统的盐检测的一部分。因此,实现了进一步的时间和成本节省并且减少了错误。几乎全部关于数据水印的研究都是基于针对一个或两个数据所有者和一个或两个不良行为者进行测试的算法。在恢复具有完全未知来源的文件的情况下,商业级系统必须能够为众多客户和未知数量的不良行为者生成、存储和检索水印。例如,考虑商业水印公司具有5000个需要为其提供水印文件的客户。在此示例中,水印公司对来自第三方的文件进行检索,该第三方想要验证该文件不包含被盗数据。为了确定这一点,水印公司必须对照每个公司的水印测试该文件,直到其找到匹配为止。在最坏的情况下,其在测试5000次之后仍没有找到匹配,在这种情况下,可作出的独特声明是该数据并非被盗自该系统中5000个所有者中的任何一个。根据某些实施例,该系统对客户的数量没有限制,并且该系统能够支持在水印中表示的无限数量的系统生成的独特接收方id。水平加盐是一种牢靠的机制,该机制仅需要少至100个随机记录来证明数据所有权,而非需要解析和处理数百万个记录。在acxiom的示例中,典型文件包含256mm记录,在最佳方案下,此机制可将检测提高达100/256mm(或2.56mm倍)。在当前的系统基础设施下,我们在系统必须读取和处理文件中的所有记录(全扫描)(最坏情况)下,在具有从4752到1百万个记录的文件大小之间对盐检测进行基准测试。盐检测处理的平均速率为每个记录0.00084984681秒。在全扫描方案的最坏情况下,具有1百万个记录的文件需要6.96分钟进行盐检测。由于通过这种机制施加的盐是不可见的,因此在缺乏任何在被任何企业认为是实用和可用的时限内将信号从噪声中提取出来的先进的信号处理机制的情况下,手动的盐标识是不切实际和不可能的。表4除非以其他方式说明,否则本文中所使用的所有技术和科学术语具有如本发明所属的本领域的普通技术人员共同理解的相同含义。虽然类似于或等同于本文所描述的方法或材料的任何方法和材料可在实践或测试本发明时使用,本文中描述了有限数目的示例性的方法和/或材料。本领域的那些技术人员将领会,更多的修改是可能的,而不背离本文中的发明概念。本文中使用的所有术语应当以与上下文一致的尽可能最宽的方式来解释。当本文中使用编组时,该组中的所有个体成员以及该组中所有可能的组合和子组合均旨在被个体地包括。当在此说明范围时,该范围旨在包括该范围内的所有子区域和单个点。本文中引用的所有参考都被通过援引纳入在此到不存在与本说明书的公开不一致的程度。本发明已参考某些优选和替换实施例来描述,这些实施例旨在仅为示例性的而非旨在限制如所附权利要求书中阐述的本发明的整个范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1