字符串辞典的构建方法、字符串辞典的检索方法及字符串辞典的处理系统与流程
本发明涉及字符串辞典的构建方法、字符串辞典的检索方法及字符串辞典的处理系统。
背景技术:
随着dna(deoxyribonucleicacid,脱氧核糖核酸)测序(sequencing)技术的进步,dna测序器输出的dna排列数据的量正在迅速地增大。因此,在调查大量得到的dna排列数据之中是否不包含有害的变异排列的变异解析等数据解析中,需要的计算开销也不断增大。
为了使数据解析有效率化,将以被计测的顺序输出的dna排列数据(字符串数据)以字母(拉丁字母)顺序(辞典式顺序)排序是有效的。这是因为对于排序后的数据能够进行高速的检索。特别是,作为适合于dna排列数据的方法,已知有采用bw(burrows-wheeler、伯罗斯-惠勒)变换(或fm索引)的方法(非专利文献1)。
将dna排列数据进行bw变换后的数据被表现为以dna和分隔字符($)为要素的1条排列,其各要素与将处于原来的dna排列数据内的全部排列的全部后缀以字母顺序排序而列举的列表的各要素一对一地对应。进而,已知有能够利用bw变换的结果作为将全部的后缀以字母顺序排序的辞典利用的有效率的方法(非专利文献1)。因此,将bw变换结果也称作字符串辞典。
由于dna排列数据的尺寸较大,所以在字符串辞典的构建中也花费较大的计算开销。已知有高速地构建字符串辞典的方法(专利文献1、非专利文献2、非专利文献3)。为了更高速化,还使用将字符串辞典的构建按照碱基的种类(字母字符)a、c、g、t并行化的方法(非专利文献4)。结果,能得到与碱基的种类数(字母尺寸)大致相等的并行度,能得到约4倍的高速化率,但不能得到其以上的并行度。
现有技术文献
专利文献
专利文献1:美国专利第8798936号说明书
非专利文献
非专利文献1:ferraginap,manzinig.proceedingsofthe41stsymposiumonfoundationsofcomputerscience(focs2000).losalamitos,ca,usa:ieeecomputersociety;2000.opportunisticdatastructureswithapplications;p.390-398.
非专利文献2:lippert,rossa.,clarkm.mobarry,andbrianp.walenz."aspace-efficientconstructionoftheburrows-wheelertransformforgenomicdata."journalofcomputationalbiology12.7(2005):943-951.
非专利文献3:ferraginap,gagiet,manzinig.“lightweightdataindexingandcompressioninexternalmemory.”latin2010:theoreticalinformatics.volume6034oftheserieslecturenotesincomputerscience,springer,pp697-710.
非专利文献4:li,heng."fastconstructionoffm-indexforlongsequencereads."bioinformatics(2014):btu541.
技术实现要素:
发明要解决的课题
另一方面,对于近年来的计算机而言,通过使用多个多核心化的cpu的多线程处理,以数十倍的并行度能够进行数十倍的高速化的情况较多。但是,在将对于大量的字符串数据的字符串辞典的构建按照字符种类进行并行化的方法(非专利文献4)中,并行度被抑制在字母的尺寸的程度(例如,如果是dna排列数据的情况,则碱基是4种,所以为4倍左右)。因而,对于具备几十个以上的cpu核心的计算机而言,不能进行有效地使用全部核心的并行计算的高速化。
由此,研究了使并行度进一步提高那样的并行计算的方法。通常,为了使处理高速化,经常将整体处理划分为部分处理而并行地执行。此时,在部分处理之间,将相互的计算结果相互参照,访问共有存储器或输入输出设备等,因此需要等待会合(同步)的情况较多。如果频繁地发生这样的等待会合,则处理器的开工率(运转率、产能利用率)下降,成为妨碍处理的高速化的原因。
此外,通常在部分处理所需要的计算时间中有偏差,如果部分处理的数量是cpu核心数量的程度,则对于cpu核心的计算负荷而言发生不平衡,难以有效地利用全部的cpu核心。所以,为了将对于全部的cpu核心的计算负荷分散进行均等化、从而进行有效率的高速化,需要细分化为与核心数量相比充分多的部分处理。如果能够这样,则通过多线程的动态负荷分散,能够使核心间的计算负荷均等化,能够实现因为将全部的核心有效地使用的有效率的并行化所带来的高速化。
所以,本发明的主要的目的是提供一种并行化的方法,在登记字符串数据的字符串辞典的构建处理中、能够进行有效地利用了cpu核心的数量的高速化。
用来解决课题的手段
为了解决上述课题,本发明的字符串辞典的构建方法是执行以下的各处理的方法。
即,本发明的特征在于,由字符串数据解析装置执行,
该字符串数据解析装置具备多个cpu核心所构成的多核cpu、和存储器;
对于展开到上述存储器上的、将字符串辞典划分得到的多个块,对各块分别赋予不同的标签,标签由构成字符串数据的字母与分隔字符以1字符以上而构成;
上述多核cpu:
关于被输入的各个上述字符串数据,针对带有分隔字符的标签的块,将上述字符串数据的末尾字符作为块的条目登记,将上述字符串数据的其余的字符串作为未登记字符串针对该末尾字符建立对应;
关于将上述未登记字符串与各块中的条目建立了对应的登记源块读入、针对根据上述登记源块的标签及条目所确定的登记目标块、将上述登记源块的上述未登记字符串的末尾字符作为新的条目向上述登记目标块登记、将上述未登记字符串的其余的字符串作为新的未登记字符串而针对该新的条目建立对应的条目登记处理,对于能够相互独立地执行的块的组并行地执行;
在成为没有各块的上述未登记字符串的状态下,关于登记在各块的条目中的字符串,将以块的标签表示的字母及分隔字符的顺序连结而成的字符串作为已登记上述字符串数据的上述字符串辞典的bw(burrows-wheeler、伯罗斯-惠勒)变换数据而输出。
其他技术方案将在后面进行叙述。
发明效果
根据本发明,能够提供一种在登记字符串数据的字符串辞典的构建处理中、能够进行有效地利用了cpu核心的数量的高速化那样的并行化的方法。
附图说明
图1是表示关于本发明的一实施方式的字符串检索系统的结构图。
图2是将关于本发明的一实施方式的图1的字符串检索系统应用到dna解析系统中的例子。
图3是表示关于本发明的一实施方式的图1的字符串检索系统的整体处理的流程图。
图4是表示关于本发明的一实施方式的字符串辞典的构建处理的详细情况的流程图。
图5是表示关于本发明的一实施方式的处理p(w)及处理i(c)的详细情况的流程图。
图6是表示关于本发明的一实施方式的处理q(w)的详细情况的流程图。
图7是表示关于本发明的一实施方式的处理r(w,a)的详细情况的流程图。
图8是表示关于本发明的一实施方式的处理s及处理p(w)的具体例的说明图。
图9是表示关于本发明的一实施方式的在图8后执行的处理q(w)及处理r(w,a)的具体例的说明图。
图10是表示关于本发明的一实施方式的在图9后执行的处理q(w)及处理r(w,a)的具体例的说明图。
图11是表示关于本发明的一实施方式的在图10后执行的处理q(w)及处理r(w,a)的具体例的说明图。
图12是表示关于本发明的一实施方式的在图11后执行的字符串辞典的输出处理的说明图。
具体实施方式
以下,参照附图详细地说明本发明的一实施方式。
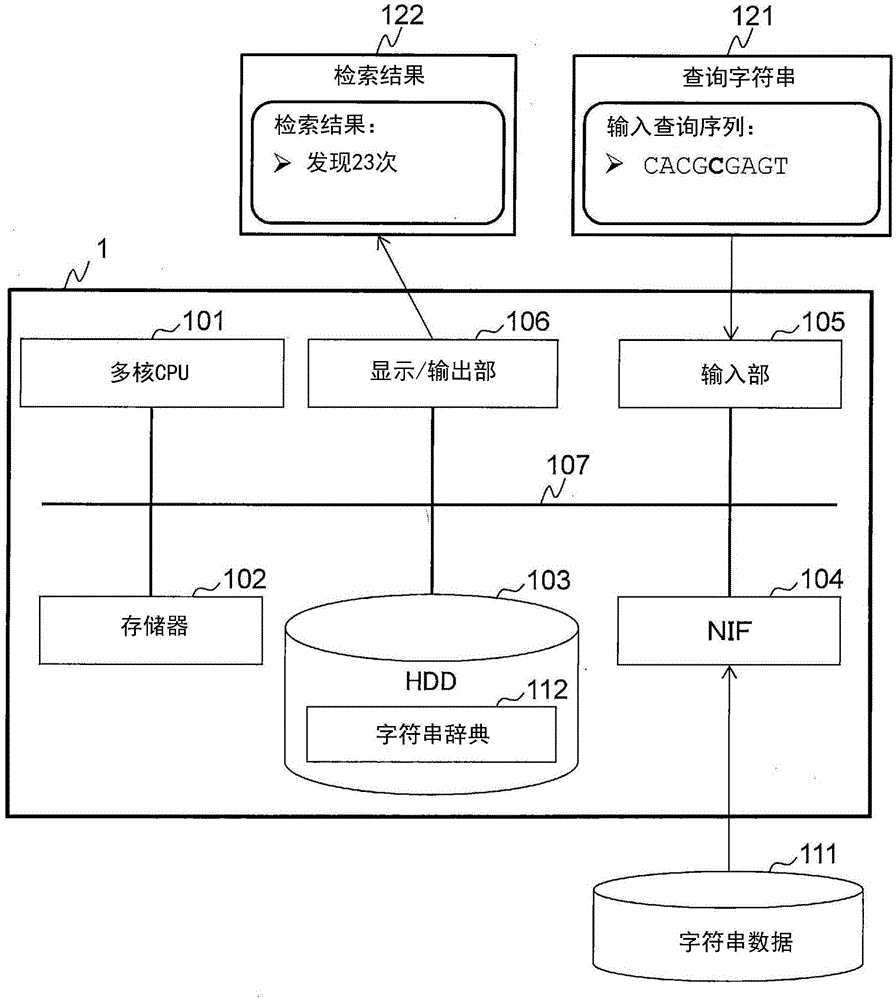
图1是表示字符串检索系统的结构图。字符串数据解析装置1由具有通常的计算机结构的服务器等的计算机实现。
字符串数据解析装置1具备在总线107上连接着多核cpu(centralprocessingunit)101、存储器102、hdd103、nif104、输入部105和显示/输出部106的结构。
多核cpu101是具备多个核心、能够进行并行计算的中央处理部。以下说明的各种处理经过由多核cpu101进行的程序的执行而实现。
存储器102是暂时地存储程序及各种作业用数据等的存储部。
hdd103是作为存储字符串辞典112或各种作业用数据等的存储部发挥功能的硬盘驱动器。存储在hdd103中的字符串辞典112既可以存储到与字符串数据解析装置1外部连接的存储装置中,也可以存储到经由网络连接的数据中心等。
nif104是用来连接到因特网等的网络接口。字符串数据解析装置1经由nif104所连接的lan(localareanetwork)及因特网等与外部装置连接,访问处于连接目的地的字符串数据111。该字符串数据111是被登记在字符串辞典112的数据。
输入部105是进行命令输入及参数输入等的键盘等的输入机构。输入部105受理查询字符串(querysequence)121的输入。
显示/输出部106显示用于操作的gui(graphicaluserinterface)及解析结果等。显示/输出部106显示查询字符串121的出现次数(hits)等,作为以查询字符串121为检索键字的来自字符串辞典112的检索结果122。另外,也可以代替出现次数,而设为出现1次以上(有出现)还是0次出现(不出现)这样的出现的有无信息。
图2是将图1的字符串检索系统应用到dna解析系统中的例子。另外,如果使用dna排列数据作为字符串数据111,则能够将字符串检索系统应用到dna排列数据的检索系统中。此外,如果使用氨基酸排列(蛋白)数据作为字符串数据111,则能够将字符串检索系统应用到蛋白数据的检索系统中。
这里,使用对于从患者501采集的dna样本502通过dna测序器503进行解析后的结果的dna排列数据504,作为图1的字符串数据111。
字符串辞典112是按照各个患者501而独立的dna排列辞典505,基于字符串数据111而构建。
首先,输入部105受理对于哪个患者使用哪个基因面板来进行变异解析的解析指示521。字符串数据解析装置1经由nif104,从连接在网络上的数据库512取得被指示的基因面板511的信息。在基因面板511的信息中,包括各基因的野生型排列w和变异型排列m、以及关于各变异的附带信息(该变异为原因而产生的病状、有效的治疗法及药剂等)。
接着,字符串数据解析装置1对于基因面板511内的各基因,通过以其野生型排列和变异型排列为查询字符串121、调查在dna排列辞典505中是否登记有查询字符串121的各排列,从而判定在患者501的dna样本502中是否检测到查询字符串121。显示/输出部106将该判定结果作为解析结果522显示或输出。
此外,显示/输出部106对于由解析结果522检测到的变异,通过gui(graphicuserinterface)等提供基因面板511中所包含的附带信息的链接。通过追溯该链接,能够得到用来预测患者501的病状的发展的参照信息、及用来选择适合于患者501的治疗法或药剂的参照信息。
图3是表示图1的字符串检索系统的整体处理的流程图。
作为s231,多核cpu101以字符串数据111和正整数参数r为输入,构建字符串辞典112(详细情况见图4)。
作为s232,多核cpu101输入查询字符串121。
作为s233,多核cpu101利用使用了字符串辞典112的公知的高速检索方法(非专利文献1),调查字符串数据111内的查询字符串121的出现次数。
作为s234,多核cpu101将s233的出现次数作为检索结果122输出或显示。
以下,定义在字符串辞典112的构建处理(s231)中使用的数据构造。
所述的“块”,是将构建中的字符串辞典112划分而成的,构成为以字母字符或分隔字符为构成要素(条目)的列表。所述的“空块”,是空的列表。各块被配置在共有存储器上。
所述的“标签”,是块的识别符,为了确定未登记字符串的登记源及作为登记目标的块而使用。标签的表述,是对长度r(设r为正整数参数)的字母字符串或长度为0以上且r-1以下的字母字符串的末尾附加了分隔符$。将以标签w起始的后缀的组称作“w块”。
所述的“链接”,是从块内的条目向块外的字符串连接。从1个条目(链接源)向1个链接目标字符串设立链接。另外,在块内可能既存在有链接的条目也存在没有链接的条目。另外,由于链接目标字符串以后被新登记到块内的条目中,所以将链接目标字符串也可以称作目前对于块的“未登记字符串”。
在1个块上带有1个标签。例如,图8的$块412,是标签为“$”的块。这样,将块用矩形表示,在该块的左侧表示标签,在该块的右侧表示链接目标字符串。例如,从$块412的第1个条目“a”链接着“aatt”(链接目标字符串413)。
图4是表示字符串辞典112的构建处理(s231)的详细情况的流程图。
作为s301,多核cpu101以正整数参数r为输入,对于长度r以下的各标签,在存储器102上制作空块。
作为s302,多核cpu101作为处理s而将新的字符串数据111一条条地经由nif104输入,将该输入字符串的末尾字符登记到$块中,将输入字符串的其余的字符串链接到其末尾字符。输入字符串的末尾字符也可以说是长度0的后缀(空字符串ε)。
作为s311,多核cpu101将参数m设置为0。
作为s312,多核cpu101对于长度m的全部的字母字符串w,并行地执行图5的处理p(w)。
作为s313,多核cpu101将m的值增加1。
作为s314,多核cpu101判定是否为m<r。在s314中如果为是,则向s312返回,如果为否,则向s321前进。
作为s321,多核cpu101判定是否留有从块内的条目链接的未登记字符串。在s321中如果为是则向s322前进,如果为否则向s331前进。
作为s322,多核cpu101对于长度r-1的全部的字母字符串w,并行地执行图6的处理q(w)。
作为s331,多核cpu101制作将各块内的登记的条目字符连结而成的每个块的连结字符串。
作为s332,多核cpu101制作将s331的连结字符串以块的标签顺序连结为1条的输出字符串,将该输出字符串作为字符串辞典112向hdd103输出。
图5是表示从s312调用的处理p(w)及处理i(c)的详细情况的流程图。
首先,对处理p(w)进行说明。
作为s351,多核cpu101将指针h复位至w$块开头。
作为s352,多核cpu101对于全部的字母字符c进行处理i(c)。
作为s361,多核cpu101将指针h的参照目标的登记字符设为c,将从该登记字符c链接的字符串(未登记字符串)设为u。
作为s362,多核cpu101判定是否存在s361的字符串u。在s362中如果为是则向s363前进,如果为否则向s371前进。
作为s363,多核cpu101将u的末尾字符设为d,将从u去除了末尾字符d后的其余的字符串设为v。
作为s364,多核cpu101将d插入到指针k(c)的位置,设立从该插入的d向v的链接。
作为s365,多核cpu101将u及从其c向u的链接删除。
作为s371,多核cpu101将指针k(c)每次1个地向下个条目前进。
作为s372,多核cpu101判定h是否是w$块末尾。在s372中如果为是则将处理p(w)结束,如果为否则向s373前进。
作为s373,多核cpu101将指针h每次1个地向下个条目前进。
接着,对处理i(c)进行说明。
作为s353,多核cpu101判定是否为r<m-1。s353中为是则向s354前进,如果为否则向s355前进。
作为s354,多核cpu101将指针k(c)复位为cw$块开头。
作为s355,多核cpu101将指针k(c)复位为cw块开头。
图6是表示从s322调用的处理q(w)的详细情况的流程图。
作为s201,多核cpu101向变量a代入字母的最初的字符。例如,如果字母字符是a和t这两种,则向变量a代入“a”。
作为s202,多核cpu101将指针k(a)复位为处理p(w)被写入到aw块内的位置的紧接着之后的位置。
作为s203,多核cpu101将a更新为字母的下个字符。例如,字母字符是a和t这两种,如果在当前的变量a中代入了“a”,则将接着的“t”向变量a代入。
作为s204,多核cpu101判定是否存在能够在s203中代入的a。在s204中如果为是则向s202返回,如果为否则向s211前进。
作为s211,多核cpu101与s201同样,再次将a设为字母的最初的字符。
作为s212,多核cpu101依次执行图7的处理r(w,a)。
作为s213,多核cpu101与s203同样,将a更新为字母的下个字符。
作为s214,多核cpu101与s204同样,判定是否存在能够在s213中代入的a。在s214中如果为是则向s212返回,如果为否则结束处理q(w)。
图7是表示从s212调用的处理r(w,a)的详细情况的流程图。
作为s220,多核cpu101将指针h复位至wa块开头。
作为s221,多核cpu101将指针h的参照目标的登记字符设为c,将从该c的链接目标字符串设为u。
作为s221b,多核cpu101判定是否存在u。在s221b中如果为是则向s221c前进,如果为否则向s222前进。
作为s221c,多核cpu101判定u是否是空字符串ε。在s221c中如果为是则向s223前进,如果为否则向s224前进。
作为s222,多核cpu101将指针k(c)每次1个地向下个条目前进。
作为s223,多核cpu101将分隔字符$插入到指针k(c)的位置。
作为s224,多核cpu101将u的末尾字符设为d,将从u去除了末尾字符d后的其余的字符串设为v。
作为s225,多核cpu101将d插入到指针k(c)的位置,设立从该d向v的链接。
作为s226,多核cpu101将u及从c向u的链接删除。
作为s227,多核cpu101判定h是否是wa块末尾。在s227中如果为是则结束处理r(w,a),如果为否则向s228前进。
作为s228,多核cpu101将指针h每次1个地向下个条目前进。
以上,对于在图3~图7的流程图中说明的各处理,通过图8~图12的具体例使其变得清楚。该具体例是构成字符串数据111的字母字符为a和t这两种,r=2的情况。
在s301(空块生成处理)中,制作$块、a$块、t$块、aa块、at块、ta块、tt块各自的空块。
图8是表示处理s及处理p(w)的具体例的说明图。
在s302(处理s)中,进行框内400所表示的处理。即,将是空块的$块412通过处理s登记以下的3个条目。另外,在框内411中读入了3行的字符串数据111。
·作为处理s,将框内411的第1行“aatta”作为$块412的新的a和其链接目标的aatt(标号413)登记。
·作为处理s,将框内411的第2行“ataat”作为$块412的新的t和其链接目标的ataa(标号414)登记。
·作为处理s,将框内411的第3行“tatat”作为$块412的新的t和其链接目标的tata(标号415)登记。
如框内420所示,在从s312调用的第1次(m=0)的处理p(w)中,从$块412的第3条目起分别每次1个字符地向其他的块登记。另外,由于长度m=0的字符串w仅为空字符串ε,所以在m=0时仅执行处理p(ε)。
·作为处理p(ε),将从$块412的a链接的aatt(标号413)作为a$块421的新的t和其链接目标的aat登记。在其登记后,将$块412的a保留,并将其链接目标的aatt(标号413)和其链接删除。
·作为处理p(ε),将从$块412的t链接的ataa(标号414)作为t$块422的新的a和其链接目标的ata登记。在其登记后,将$块412的t保留,并将其链接目标的ataa(标号414)和其链接删除。
·作为处理p(ε),将从$块412的t链接的tata(标号415)作为t$块422的新的a和其链接目标的tat登记。在其登记后,将$块412的t保留,并将其链接目标的tata(标号415)和其链接删除。由此,$块412成为$块481。
另外,与图5的处理p(w)建立对应地来说明,将从$块412的a链接的aatt(标号413)作为a$块421的新的t和其链接目标的aat登记、在其登记后将$块412的a保留、并将其链接目标的aatt(标号413)和其链接删除的例子。
上述的例子中的作为此次的登记对象的未登记字符串是“aatt(标号413)”。作为向该未登记字符串的链接源的条目所属的登记源块是“$块412”。
在上述的流程图中,在处理p(w)中,将登记源块设为w$块(s351),将未登记字符串设为字符串u(s361),将链接源的条目设为处于指针h表示的位置的字符c(s361)而进行了说明。
上述例子中的未登记字符串的登记目标块是“a$块421”。新登记在该登记目标块内的条目“t”是未登记字符串“aatt”的末尾字符。从条目“t”的链接目标的字符串“aat”是将未登记字符串“aatt”的末尾字符去除后的其余的字符。
在上述的流程图中,在处理p(w)中,将登记目标块设为cw$块(s354)或cw块(s355),将新登记的条目设为向指针k(c)表示的位置插入的字符d(s363),将新登记的链接目标的字符串设为字符串v(s363)而进行了说明。
如框内420所示,在从s312调用的第2次(m=1)的处理p(w)中,作为长度m的字符串w,由于有a和t这两种,所以将处理p(a)和处理p(t)并行地执行。换言之,将处理p(a)处置的块的集合和处理p(t)处置的块的集合作为能够相互独立地执行的部分处理而分组为2个组。
·作为处理p(a),将从a$块421的t链接的aat作为ta块433的新的t和其链接目标的aa登记。在其登记后,将a$块421的t保留,并将其链接目标的aat和其链接删除。由此,a$块421成为仅条目t保留的a$块482。此外,aa块431作为此次的处理p(a),虽然不符合登记目标块,但由于在下个处理(框内435)中处置,所以在这里为了容易理解而进行了记载。也适当图示了不符合登记目标块的这样的块。
·作为处理p(t),将从t$块422的a链接的ata作为at块432的新的a和其链接目标的at登记。在其登记后,将t$块422的a保留,并将其链接目标的ata和其链接删除。
·作为处理p(t),将从t$块422的a链接的tat作为at块432的新的t和其链接目标的ta登记。在其登记后,将t$块422的a保留,并将其链接目标的tat和其链接删除。
然后,成为m=r=2,由于在s314中为否,所以不执行第3次(m=2)的处理p(w)。
并且,由于ta块433的未登记字符串“aa”等保留,所以在s321中成为是,执行s322。
图9是表示在图8之后执行的处理q(w)及处理r(w,a)的具体例的说明图。
如框内440所示,在从s322调用的第1次的处理q(w)中,由于长度r-1的全部的字母字符串有a和t这两种,所以将处理q(a)和处理q(t)并行地执行。
在处理q(a)内的s212中,对于字符a=a、t,将处理r(a,a)和处理r(a,t)以该顺序依次执行。
表示处理q(a)的输入组(框内435)和处理q(a)的输出组(框内437)。
在处理q(a)的输入组侧,将应依次参照的块集中而分组。在处理q(a)的输出组侧,将应同时并行地写入的块集中而分组。
·作为处理q(a)的处理r(a,a),由于在aa块431中没有具有链接的条目,所以将处理跳过。
·作为处理q(a)的处理r(a,t),将从at块432的a链接的at作为aa块441的新的t和其链接目标的a登记。在其登记后,将at块432的a保留,并将其链接目标的at和其链接删除。
·作为处理q(a)的处理r(a,t),将从at块432的t链接的ta作为ta块443的新的a和其链接目标的t登记。在其登记后,将at块432的t保留,并将其链接目标的ta和其链接删除。
另外,与图7的r(w,a)建立对应而说明,将从at块432的a链接的at作为aa块441的新的t和其链接目标的a登记、在其登记后将at块432的a保留并将其链接目标的at和其链接删除的例子。
上述的例子中的作为此次的登记对象的未登记字符串是“at”。作为向该未登记字符串的链接源的条目所属的登记源块是“at块432”。
在上述的流程图中,在r(w,a)中,将登记源块设为wa块(s220),将未登记字符串设为字符串u(s221),将链接源的条目设为处于指针h表示的位置的字符c(s221)而进行了说明。
上述的例子中的未登记字符串的登记目标块是“aa块441”。被新登记到该登记目标块内的条目“t”是未登记字符串“at”的末尾字符。从条目“t”的链接目标的字符串“a”是将未登记字符串“at”的末尾字符去除后的其余的字符。
在上述的流程图中,在r(w,a)中,将登记目标块设为aw块(s202),将新登记的条目设为向指针k(c)表示的位置插入的字符d(s224),将新登记的链接目标的字符串设为字符串v(s224)而进行了说明。即,r(w,a)的登记目标块是由cw块构成的组(c是任意的字符),关于全部的a是共通的,此外,将在s202中被复位后的相同的指针k(c)依次继续利用。结果,将向各cw块的写入以辞典顺序正确地进行。
在处理q(t)内的s212中,对于字符a=a,t,将处理r(t,a)和处理r(t,t)以该顺序依次执行。
表示处理q(t)的输入组(框内436)和处理q(t)的输出组(框内438)。
·作为处理q(t)的处理r(t,a),将从ta块433的t链接的aa作为tt块444的新的a和其链接目标的a登记。在其登记后,将ta块433的t保留,并将其链接目标的aa和其链接删除。
·作为处理q(t)的处理r(t,t),由于在tt块434中没有具有链接的条目,所以将处理跳过。
并且,由于aa块441的未登记字符串“a”等保留,所以在s321中成为是,执行s322。
图10是表示在图9之后执行的处理q(w)及处理r(w,a)的具体例的说明图。
如框内450所示,在第2次的处理q(w)中,也将处理q(a)和处理q(t)并行地执行。
表示处理q(a)的输入组(框内445)和处理q(a)的输出组(框内447)。
·作为处理q(a)的处理r(a,a),将从aa块441的t链接的a作为ta块453的新的a和其链接目标的ε登记。由指针k(t)指示用于该登记的插入位置439。在其登记后,将aa块441的t保留,并将其链接目标的a和其链接删除。
·作为处理q(a)的处理r(a,t),由于在at块442中没有具有链接的条目,所以将处理跳过。即,将向aa块451内的指针k(a)与向ta块453内的指针k(t)向前推进。
表示处理q(t)的输入组(框内446)和处理q(t)的输出组(框内448)。
·作为处理q(t)的处理r(t,a),将从ta块443的a链接的t作为at块452的新的t和其链接目标的ε登记。由指针k(a)指示用于该登记的插入位置459。在其登记后,将ta块443的a保留,并将其链接目标的t和其链接删除。
·作为处理q(t)的处理r(t,t),将从tt块444的a链接的a作为at块452的新的a和其链接目标的ε登记。在其登记后,将tt块444的a保留,并将其链接目标的a和其链接删除。
并且,由于ta块453的未登记字符串“ε”等保留,所以在s321中成为是,执行s322。
图11是表示在图10之后执行的处理q(w)及处理r(w,a)的具体例的说明图。
如框内460所示,在第3次的处理q(w)中,也将处理q(a)和处理q(t)并行地执行。
表示处理q(a)的输入组(框内455)和处理q(a)的输出组(框内457)。
·作为处理q(a)的处理r(a,a),由于在aa块451中没有具有链接的条目,所以将处理跳过。即,将向aa块461内的指针k(a)和向ta块463内的指针k(t)向前推进。
·作为处理q(a)的处理r(a,t),将从at块452的t链接的ε作为ta块463的新的$登记。在其登记后,将at块452的t保留,并将其链接目标的ε和其链接删除。
·作为处理q(a)的处理r(a,t),将从at块452的a链接的ε作为aa块461的新的$登记。在其登记后,将at块452的a保留,并将其链接目标的ε和其链接删除。
表示处理q(t)的输入组(框内456)和处理q(t)的输出组(框内458)。
·作为处理q(t)的处理r(t,a),将从ta块453的a链接的ε作为at块462的新的$登记。在其登记后,将ta块453的a保留,并将其链接目标的ε和其链接删除。
·作为处理q(t)的处理r(t,t),由于在tt块454中没有具有链接的条目,所以将处理跳过。即,将向at块462内的指针k(a)和向tt块464内的指针k(t)向前推进。
由此,由于未登记字符串被全部消除,所以在s321中成为否,执行s331。
图12是表示在图11之后执行的字符串辞典112的输出处理的说明图。
在s331(按照块的连结字符串的制作处理)中,将在以标签顺序排序的各块($块481、a$块482、aa块461、at块462、t$块483、ta块463、tt块464)中登记的条目以图示的箭头的顺序作为字符串471~477提取。
在s332(字符串辞典112的输出处理)中,如框内490所示,制作将字符串471~477依次连结为1条的输出字符串作为字符串辞典112。
在以上说明的本实施方式中,作为字符串辞典112的构建处理(s231),字符串数据解析装置1经由nif104输入、从字符串数据111输入字符串。字符串数据解析装置1将所输入的字符串作为未登记字符串,将其全部的后缀从较短者起依次按照在处理p(w)、处理q(w)、处理r(w,a)中表示的各次序,依次向空块登记。
这里,所述的将后缀向块登记,是将先行于后缀的字符(其中,在后缀与字符串整体一致的情况下为分隔字符$)向块登记。对于登记在块中的各字符将后续于它的后缀复原的有效率的计算方法是公知的(非专利文献1)。此外,将从未登记字符串去除了后缀的其余的字符串链接到此次登记的后缀并暂时地保持。
在对于全部的字符串的全部的后缀完成了向块的登记处理后,按照在图12中表示的次序,对全部的块制作将登记在其中的字符连结而成的字符串,再将按照块的标签的辞典式顺序把这些字符串连结的字符串辞典112作为bw变换,向hdd103内输出。
另外,在s301中,在hdd103内(或从网络的连接目的地经由nif104取入而hdd103内)有已制作的字符串辞典112的情况下,也可以代替空块而将制作字符串辞典112时的块的信息装载到存储器上。在此情况下,可以对于已制作的字符串辞典112,将经由nif104新输入的字符串数据111追加登记。
此外,如在s364、s223、s225中说明那样,当向存储器102上的块每次追加登记新的条目时,需要向作为列表的块的插入处理。所以,作为块的数据构造,既可以采用(在非专利文献4中记载那样的平衡木那样的)动态构造,或者也可以采用(如在专利文献1中记载那样每次再构建列表的拷贝那样的)静态构造。
以下,关于本实施方式的字符串辞典112的构建处理,对其并行计算中的并行度及等待会合等进行补充说明。
在上述的例子中,将字母字符设为a和t这两种,但将字母字符的种类扩展为h种(字符a1,a2,…,ah)。
首先,对处理p(w)的并行度进行说明。
处理p(w)读入的登记源块是w$块,对于各m,如果字符串w不同则相异。
处理p(w)写出的登记目标块,如果m不到r-1,则是a1w$块,a2w$块,…,ahw$块,如果m=r-1,则是a1w块,a2w块,…,ahw块。在登记目标块中,在任一情况下,若字符串w不同则相互不相容。因而,对于各m,处理p(w)不相互干涉而能够独立并行地执行。
接着,对处理q(w)的并行度进行说明。
处理q(w)读入的登记源块是wa1块,wa2块,…,wah块,如果字符串w不同则相互不相容。
处理q(w)写出的登记目标块是a1w块,a2w块,…,ahw块,它们也是如果字符串w不同则相互不相容。因而,处理q(w)不相互干涉而能够独立并行地执行。
接着,对处理r(w,a)的并行度进行说明。
处理r(w,a1),r(w,a2),…,r(w,ah)中的登记目标块有h个,它们在a1w块,a2w块,…,ahw块中是共通的。由于它们的登记处理以字母顺序依次地执行,所以向各块的登记处理也以字母顺序正确地进行。
这样,必须遵守顺序而依次执行的处理r(w,a)的数量等于字母的尺寸,且不依存于参数r而为一定。因而,即使增加参数r而使作为并行处理的粒度变细,依次执行的等待会合的长度也被保持为一定,不会发生因等待会合造成的cpu开工率下降。
通过以上,细分化为能够相互独立地进行的部分处理,除了依次执行处理r(w,a1),r(w,a2),…,r(w,ah)以外,不需要等待会合,能够避免因等待会合所造成的处理器开工率的下降。
这里,多核cpu101既可以输入正整数参数r的值,也可以基于多核cpu101的cpu核心数量而自动计算。
如在s301中说明那样,当r=2,字母字符为a和t这两种时,使用7种块($块、a$块、t$块、aa块、at块、ta块、tt块)。即,通过将计算式“7=2的3次幂-1”一般化得到的计算式“(块数量)=((h的(r+1)次幂-1)/(h-1)”,能够求出块数量。并且,多核cpu101例如如(cpu核心数量)×k=(块数量),(k例如为表示数十倍的10~90的常数)那样,根据cpu核心数量求出块数量,通过将该块数量代入到上述的一般化的计算式中,能够自动计算参数r。
如果将正整数参数r增加,则块数量以指数函数增大,所以可以设定r的值以使块数量成为cpu核心数量的数十倍左右。此时,如果进行借助多线程的动态负荷分散,则即使发生处理p(w)或处理q(w)的计算时间的偏差,也能够使核心间的计算负荷均等化,能够实现有效地使用了全部的核心的有效率的高速化。
例如,能够独立地并行执行的处理q(w)的数量相当于长度r-1的字符串w的数量。如果设字母的尺寸为h,则该数量等于h的r-1次幂。因而,即使是如dna排列数据那样h=4的情况,也能够选择r以使处理q(w)的数量成为可利用的cpu核心数量的数十倍左右。
由此,能够提供细分化为cpu核心数量的数十倍左右的部分处理的方法,此外提供避免因部分处理彼此的等待会合所造成的处理器开工率的下降的方法。
另外,本发明并不限定于上述的实施例,而包含各种的变形例。例如,上述的实施例是为了容易理解本发明而进行了详细地说明,并不限定于一定具备所说明的全部的结构。
此外,可以将某个实施例的结构的一部分替换为其他实施例的结构,此外,也可以对某个实施例的结构添加其他实施例的结构。
此外,关于各实施例的结构的一部分,能够进行其他结构的追加、删除、替换。此外,上述的各结构、功能、处理部、处理机构等也可以通过将它们的一部分或全部例如用集成电路设计等而由硬件实现。
此外,上述的各结构、功能等也可以通过处理器将实现各个功能的程序解释并执行而由软件实现。
实现各功能的程序、表格、文件等的信息可以放置到存储器或硬盘、ssd(solidstatedrive)等的记录装置、或者ic(integratedcircuit)卡、sd卡、dvd(digitalversatiledisc)等的记录介质中。
此外,控制线及信息线表示在说明上被认为所需要的,并不一定表示全部的控制线及信息线。实际上可以考虑几乎全部的结构被相互连接。
标号说明
1字符串数据解析装置;101多核cpu;102存储器;103hdd;104nif;105输入部;106显示/输出部;107总线;111字符串数据;112字符串辞典;121查询字符串;122检索结果;501患者;502dna样本;503dna测序器;504dna排列数据;505dna排列辞典;521解析指示;522解析结果;511基因面板;512数据库。
- 还没有人留言评论。精彩留言会获得点赞!