协同过滤推荐系统中基于遗忘特性的用户相似度计算方法与流程
本发明涉及一种在协同过滤推荐系统中用户相似度计算方法。
背景技术:
近年来,推荐系统已经被广泛应用到电子商务(如Amazon,淘宝等)和一些社会化站点(如豆瓣)。这也进一步说明在新世纪高速发展的互联网环境下,面对海量数据,用户需要更加智能的,能够将无用的信息进行过滤,只留下他们需求信息的发现机制。
协同过滤推荐系统作为传统推荐系统因其简单高效的特点,在应用中获得更多青睐,同时也得到许多研究者的关注。其核心思想是基于用户-项目评分数据集,筛出与目标用户兴趣相似的用户作为最近邻居集,通过最近邻居对各项目的综合评分信息对目标用户对各项目的评分作出预测,从而为目标用户生成相应的推荐列表。其优点在于不需要分析项目的各维度特征,可以更加便利地处理非结构化信息。然而,随着电子商务平台用户和商品数量的不断增加,传统方法仅考虑共同评分项,而忽略时间对兴趣变化的影响,尤其在实际系统中存在用户评分数据稀疏的问题。导致传统的相似度计算方法对真实用户相似度评估误差较大,从而影响最近邻居集的准确选取。
技术实现要素:
本发明的目的是提供一种协同过滤推荐系统中能够更准确把握用户兴趣喜好,提高相似度值可靠性的用户相似度计算方法。本发明提供的是一种基于遗忘特性的用户相似度计算方法,基于人脑遗忘特性曲线,将信息遗忘的过程当作信息价值衰减的过程,即信息在相似度计算中的可参考价值的衰减,也代表着用户兴趣的衰退变化,可以更准确的把握用户的兴趣喜好,提高相似度值的可靠性,一定程度上解决数据稀疏带来的问题。本发明采用如下的技术方案:
协同过滤推荐系统中基于遗忘特性的用户相似度计算方法,包括下列步骤:
(1)构建用户-项目评分矩阵;
(2)构建用户-项目时间矩阵;
(3)计算用户遗忘周期:求取所有用户的相邻时间评分项目的评分时间间隔均值,得到用户遗忘周期
(4)构造遗忘指数函数:设定遗忘函数的1/4衰减截止期T0,当时长t小于T0时,遗忘指数函数按指数衰减,衰减因子;λ=(ln0.25)/T0;当时长t等于或小于T0时,遗忘指数函数恒为0.25;
(5)构造改进的遗忘指数函数:结合用户遗忘周期,使得改进的遗忘指数函数在每个遗忘周期窗内的数值不变,将遗忘指数函数改进为针对每个用户的梯度指数衰减函数;
(6)计算改进后的各用户项目评分和各用户的平均评分,改进后的用户项目评分为项目的原始评分与对应的遗忘函数值的乘积,改进后的用户平均评分为用户所有改进后的项目评分的平均值;
(7)计算基于遗忘特性的用户相似度。
附图说明
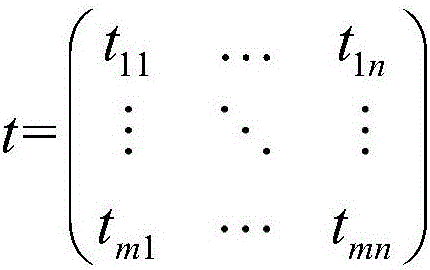
图1是用户-项目评分矩阵。
图2是用户-项目时间矩阵。
图3是基于遗忘特性的相似度计算流程图。
具体实施方式
本发明的具体实施方式是:
(1)首先采集数据,数据可以从推荐系统的数据库中获取,接着构建如图1、2所示的用户-项目评分矩阵和用户-项目时间矩阵。设用户总数为m,项目总数为n,Rij为用户i对项目j的评分,评分越高,则表示用户i对项目j的喜欢程度越大。
(2)计算用户遗忘周期:
其中,Ia表示用户a评价过的项目个数,ta(i+1)、tai表示用户a对项目i+1、i评分距当前的时长,求所有用户的相邻时间评分项目的评分时间间隔均值,即各用户的遗忘周期。
(3)构造遗忘指数函数,首先输入遗忘函数的1/4衰减截止期T0,遗忘函数构造为:
f(t)=eλ×t,t<=T0
f(t)=0.25,t>T0
其中λ为衰减因子,计算公式为:
λ=(ln0.25)/T0
即当时间t小于T0时,f(t)按指数衰减,当时间t等于T0时,f(t)为0.25,当时间t大于T0时,f(t)恒为0.25。
(4)构造改进的遗忘指数函数,计算如下:
f(t)a=0.25,t>T0
其中,表示对取整,即将原来的遗忘函数改进为针对每个用户的梯度指数衰减函数,f(t)为[0.25,1]之间的值。
(5)改进后的用户项目评分计算如下:
Rfai=Rai×f(tai)a
改进后的用户平均评分计算如下:
(6)基于遗忘特性的相似度计算
以传统相似度计算方法为基础,可以采用经典的皮尔森相似度计算方法,代入改进后的用户项目评分和平均评分,计算基于遗忘特性的相似度。
本实施例的计算公式如下:
其中,a和b代表两个用户,simf(a,b)表示用户a和b之间基于遗忘特性的相似度,Rfai表示用户a对项目i改进的评分,Iab表示两个用户的共同评分项集,表示用户a改进的评分均值。
- 还没有人留言评论。精彩留言会获得点赞!