基于Kinect的室内场景三维重建方法与流程
本发明属于计算机视觉技术领域,特别涉及一种基于Kinect的室内场景三维重建方法。本发明可用于机器人导航、工业测量、虚拟交互等领域。
背景技术:
三维重建技术是计算机视觉、人工智能、虚拟现实等前沿领域的热点和难点,也是人类在基础研究和应用研究中面临的重大挑战之一,被广泛应用于文物数字化、生物医学成像、动漫制作、工业测量、沉浸式虚拟交互等领域。
三维重建在科研领域已经历了很长研究时间,但由于所需设备的成本较高,目前还没有达到普及的程度。随着微软Kinect体感摄像机的推广使用,成本大大降低,使得普通用户也可以利用三维重建技术来制作模型。
现有的三维重建技术,按照获取深度信息的方式,可分为被动式技术和主动式技术。被动式技术利用自然光反射,一般通过摄像机拍摄图像,然后通过一系列的算法计算得到物体的三维坐标信息。这种被动式方法的计算量大,速度慢。
主动式技术包含一个光源,直接测量物体的深度信息,因而很容易做到实时效果,如Time of Flight技术和结构光技术。其中Time of Flight技术的成本很高,从而极大地限制了该技术的使用场合。Kinect相机使用结构光技术,成本较低,可以满足普通用户的需求,在三维重建中得到了广泛的应用。
针对三维重建,已有相关专利,如《一种基于SIFT和LBP的点云配准的接触网三维重建方法》(公开号:CN104299260A,申请号:201410456796.1,申请日:2014.09.10),该专利提出一种基于SIFT和LBP的接触网三维重建方法。专利《基于Kinect视觉技术的三维空间地图构建方法》(公开号:104794748A,申请号:201510116276.0,申请日:2015.03.17),该专利提出一种基于Kinect视觉技术的三维空间地图构建方法。
文献“Henry P,Krainin M,Herbst E,et al.RGB-D mapping:Using depth cameras for dense 3D modeling of indoor environments[C]//RSS Workshop on RGB-D Cameras.2010.”提出了基于SIFT(尺度不变特征变换)特征匹配定位及TORO(Tree-based Network Optimizer)优化算法的室内场景三维重建系统,此系统利用深度数据和彩色图像数据,使用ICP算法结合彩色图像中的SIFT特征对两帧的点云数据进行配准,同时使用TORO算法—一种针对SLAM的最优化算法得到全局点云数据,对于特征不明显甚至光线昏暗的室内场景,都可以比较准确地进行三维重建,但上述算法的计算复杂,重建速度较慢。
文献“Fioraio N,Konolige K.Realtime visual and point cloud SLAM[C]//RSS Workshop on RGB-D Cameras.2011.”提出了RGBD-SLAM算法,此算法利用RGB-D传感器获取深度数据和彩色图像数据,使用k-d tree或投影法在两帧点云数据中寻找对应点,运用基于对应点的ICP算法实现点云数据的配准,使用g2o—一种高效的非线性最小二乘优化器进行全局优化,要达到较好的重构效果,依然存在计算复杂,重建速度慢的问题。
上述两种算法的计算复杂,配置的要求较高,且点云模型的冗余点多。
技术实现要素:
本发明的目的是针对现有技术中的不足,提供一种配准更精确、速度更快的基于Kinect的室内场景三维重建方法。
本发明是一种基Kinect的室内场景三维重建方法,其特征在于,包括以下步骤:
步骤1.深度数据去噪及降采样:
设定计时器t,开始计时,使用Kinect获取室内场景中物体一帧的深度数据,采用联合双边滤波方法,对此深度数据进行去噪,将彩色图像和深度图像相结合,补全缺失的深度图像,并通过降采样获得多个分辨率的深度数据;
步骤2.获取当前帧点云数据,并计算出该帧内各点的法向量:
根据Kinect的相机参数得到从图像坐标系到相机坐标系的变换矩阵,利用此变换矩阵和多个分辨率的深度数据计算得到室内场景中物体的当前帧点云数据,使用特征值估计(Eigenvalue Estimation)计算出当前帧点云数据各点的法向量;
步骤3.获取当前帧点云数据的全局数据立方体并计算预测点云数据:
利用截断符号距离函数(TSDF,Truncated Signed Distance Function)将当前帧点云数据转换到全局数据立方体(Volume)的体素中,并利用光线投影算法(Ray Casting)结合初始点云配准矩阵,计算得到全局数据立方体的预测点云数据和预测点云各点的法向量,初始点云配准矩阵设定为单位矩阵;
步骤4.两帧点云数据的融合配准:
将两帧点云数据进行融合配准,融合配准需要点云配准矩阵;
4.1移动Kinect,返回执行步骤1—步骤2,再次获取一帧室内场景中物体的点云数据并计算出该帧内各点的法向量,再次获取的这一帧室内场景中物体的点云数据、法向量即为当前帧点云数据、法向量,当前点云配准矩阵为初始点云矩阵;
4.2使用ICP算法结合当前帧获取的点云数据、法向量和上一帧获取的预测点云数据、预测点云各点法向量计算并更新当前点云配准矩阵;
4.3采用TSDF算法进行点云融合,通过当前点云配准矩阵更新全局数据立方体的体素,将当前帧点云数据融合到全局数据立方体中;
4.4利用光线投影算法(Ray Casting)结合当前点云配准矩阵,计算得到全局数据立方体的预测点云数据;
步骤5.多帧点云数据的融合配准:返回步骤4,重复执行步骤4,逐帧获取数据,将新获取的每一帧点云数据融合到全局数据立方体中,直到计时器t达到设定时间,设定时间为1到3分钟,停止获取点云数据,得到配准好的点云数据。
步骤6.配准好的点云数据的渲染:通过等值面提取算法(Marching Cubes)对配准好的点云数据进行渲染,构建出室内场景中物体的三维模型,完成室内场景三维重建。
本发明仅使用深度数据,并通过高度并行的算法在GPU上进行计算,可以达到比较高的实时性,且使用基于TSDF的模型,构建的点云模型冗余点少。采用本发明对室内场景进行扫描重建,成本低,速度快,满足实时性的需求。
本发明与现有技术相比较具有如下的优点:
1.配准时使用多分辨率深度数据,先采用低分辨率的深度数据和预测点云数据初步计算点云配准变换矩阵,由于深度数据的分辨率较低,大大减少了计算量,加快了计算速度,然后利用高分辨率的深度数据和增量的性质计算变换矩阵,从而提高了配准的速度;
2.本发明利用光线投射算法和当前点云配准变换矩阵结合全局数据立方体计算出预测点云数据,和当前时刻获得的点云数据进行配准,因为预测点云数据是由全局数据立方体中计算出的,累积误差更小,因此提高了配准的精度;
3.使用TSDF全局数据立方体来进行点云融合,由于全局数据立方体是由体素组成的,且体素的数目是固定的,因此可以避免造成点云的冗余,且计算过程在GPU中进行,计算速度快,从而可以加速点云的融合。
附图说明
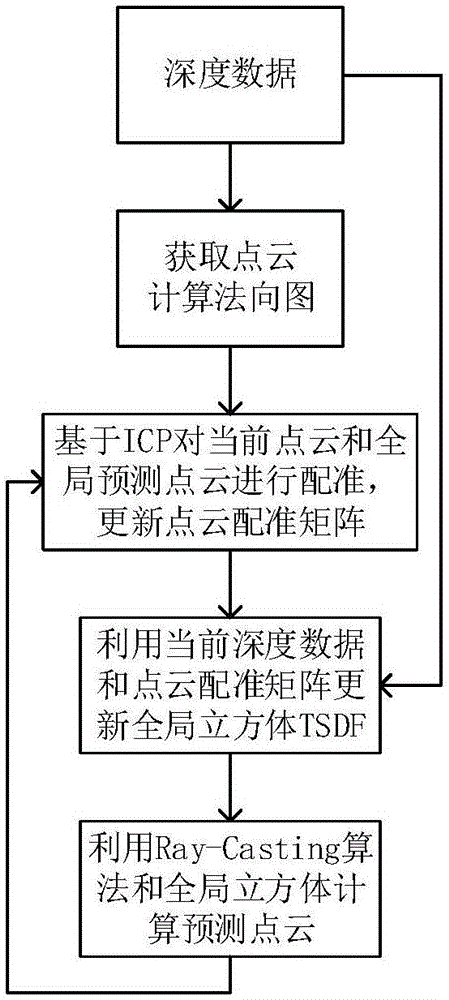
图1是本发明的室内场景三维重建方法流程图;
图2是本发明中点云配准流程图;
图3是本发明实施例6提供的场景深度示意图,图3(a)是滤波前,图3(b)是滤波后;
图4是本发明实施例6提供的场景点云示意图;
图5是本发明实施例6提供的场景渲染效果图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用于解释本发明,并不用于限定本发明。
实施例1
现有的三维重建技术,在机器人导航、工业测量、虚拟交互等领域得到了广泛应用。要达到比较好的效果,现有技术的大部分算法还存在计算量较大,速度慢,存在冗余点等问题。本发明针对此现状展开研究,提出一种基于Kinect的室内场景三维重建方法,参见图1,本发明的室内场景三维重建方法包括以下步骤:
步骤1.深度数据去噪及降采样:首先设定计时器t,开始计时,计时器用于决定何时停止获取点云数据并进行全局点云渲染,计时器可以根据场景大小需要自行选定。使用Kinect相机获取室内场景中物体一帧的深度数据,采用联合双边滤波方法,对Kinect相机获取室内场景中物体一帧深度数据进行去噪,联合双边滤波方法同时利用了深度图像和彩色图像,在保留前景和背景边缘的同时,引入信息完整的彩色图像,去噪的同时也能对深度信息缺失的部分进行修补。本发明对去噪后的深度数据通过降采样获得多个分辨率的深度数据,Kinect获取的原始图像分辨率为640*480,本发明通过降采样得到分辨率为320*240和160*120的深度数据,即构成多分辨率的深度数据;为之后计算点云配准矩阵作准备。
步骤2.获取当前帧点云数据,并计算出该帧内各点的法向量:根据Kinect的相机参数得到从图像坐标系到相机坐标系的变换矩阵,利用相机坐标系的变换矩阵和多个分辨率的深度数据计算得到室内场景中物体的当前帧点云数据,使用特征值估计方法计算出当前帧点云数据各点的法向量。相对于现有技术中使用临近点和向量叉积的方法计算法向量,本发明采用特征值估计的方法计算得更加准确。
步骤3.获取当前帧点云数据的全局数据立方体并计算预测点云数据:利用截断符号距离函数(TSDF,Truncated Signed Distance Function)将当前帧点云数据转换到全局数据立方体(Volume)的体素中,构建全局数据立方体,让不同帧的室内场景中物体的当前帧点云数据在此融合,此全局数据立方体的数据存储在图形处理器GPU的显存中,使用GPU计算并更新数据,由于GPU使用并行计算,计算速度大大提高。然后利用光线投影算法(Ray Casting)结合初始点云配准矩阵,计算得到全局数据立方体的预测点云数据和预测点云各点的法向量。其中提及的初始点云配准矩阵为单位矩阵。
步骤4.两帧点云数据的融合配准:将两帧点云数据进行融合配准,融合配准需要点云配准矩阵。
4.1移动Kinect,返回执行步骤1—步骤2,再次获取一帧室内场景中物体的点云数据并计算出该帧内各点的法向量;再次获取的这一帧室内场景中物体的点云数据、法向量即为当前帧点云数据、法向量,当前点云配准矩阵为初始点云配准矩阵。
4.2使用ICP算法结合当前帧获取的点云数据、法向量和上一帧获取的预测点云数据、预测点云法向量计算并更新当前点云配准矩阵,用于更新全局数据立方体。解释性地说,获取第一帧点云数据后,建立全局数据立方体,此时点云配准矩阵为初始点云配准矩阵,即单位矩阵,使用光线投影算法计算并得到预测点云数据,然后获取第二帧的点云数据,使用ICP算法结合第二帧的点云数据和第一帧的预测点云数据计算并更新点云配准矩阵。
4.3采用TSDF算法进行点云融合,通过当前点云配准矩阵更新全局数据立方体的体素,将当前帧点云数据融合到全局数据立方体中。建立全局数据立方体的目的是将所有获取的点云数据都融合在一起,形成完整的室内场景点云数据。
4.4然后利用光线投影算法(Ray Casting)结合当前点云配准矩阵,计算得到全局数据立方体的预测点云数据;光线投影算法是以当前相机位置为起点发出射线,然后根据当前点云配准矩阵,计算得到当前相机位置下观察到的全局数据立方体的点云数据,即预测点云数据。
步骤5.多帧点云数据的融合配准:返回步骤4,重复执行步骤4,逐帧获取数据,将新获取的每一帧点云数据融合到全局立方体中,直到计时器t达到设定时间,停止获取点云数据得到配准好的点云数据;设定时间为1到3分钟,本例中设定时间为1分钟。在多帧数据融合配准过程中可以通过计算机屏幕实时查看当前的全局点云,如果已经获得足够的点云数据,即使计时器没有达到设定时间,也可以手动停止获取点云数据。如果计时器达到设定时间,但没有获得足够的点云数据,也可以手动继续获取点云数据,本发明也具有一定的适应性,可以按需调整。
步骤6.配准好的点云数据的渲染:通过等值面提取算法(Marching Cubes)对配准好的点云数据进行渲染,构建出室内场景中物体的三维模型,完成室内场景三维重建。
Marching Cubes算法是目前三维数据场等值面生成中最常用的方法。它实际上是一个分而治之的方法,把等值面的抽取分布于每个体素中进行。对于每个被处理的体素,以三角面片逼近其内部的等值面片。
MC算法主要有三步:1.将点云数据转换为体素网格数据;2.使用线性插值对每个体素抽取等值面;3.对等值面进行网格三角化,从而重构出物体的三维模型。
本发明提供的基于Kinect的室内场景三维重建方法,提高了点云配准的速度和精度,对于室内场景的实时三维重建可以达到良好的效果。
实施例2
基于Kinect的室内场景三维重建方法同实施例1,步骤1使用降采样得到的多分辨率深度数据,用于步骤4.2中计算点云配准变换矩阵,具体包括:
4.2.1使用ICP算法,采用最低分辨率的深度数据和预测点云数据,计算得到点云配准矩阵。
4.2.2然后在此点云配准矩阵的基础上,利用更高一级分辨率的深度数据和预测点云数据,逐级计算获得更准确的点云配准变换矩阵,并用于更新当前的点云配准矩阵。
本发明在计算时先使用低分辨率的深度数据,初步计算出点云配准矩阵,然后以此矩阵为基础,使用更高分辨率的深度数据,计算出更准确的点云配准矩阵,直到使用最高分辨率的深度数据计算得到最终的点云配准矩阵。
相对于直接利用原始分辨率数据进行计算,这种采用多分辨率逐步进行计算的方式耗时更少,速度更快。
实施例3
基于Kinect的室内场景三维重建方法同实施例1-2,步骤4.3中采用TSDF算法进行点云融合,包括:
4.3.1采用TSDF算法时,用一个立方体栅格来表示3维空间,立方体中的每一个栅格存放的是该栅格到物体模型表面的距离D和权重W。
本发明采用TSDF算法,此方法的主要思想是在显卡中建立一个虚拟的立方体(Volume),边长为L,本例中虚拟立方体的边长L设定为2米,然后将立方体划分为N×N×N个体素(Voxel),本例中设N为512,每个体素的边长为LN,每个体素保存它到物体最近表面的距离D及它的权重W。本例对室内一个柜子进行三维重建。
4.3.2同时用正负来表示在表面内部和外部,体素中距离为负值表示当前这个体素在物体内部,距离为正值表示当前这个体素在物体外部,距离为0表示是物体的表面。
4.3.3通过此权重W来融合全局数据立方体和当前点云数据。
本例中对点云数据融合过程中,设定时间为2分钟,2分钟后获取足够的点云数据,完成室内柜子场景的三维重建。
使用全局数据立方体来进行点云融合,由于全局数据立方体是由体素组成的,且体素的数目是固定的,因此可以避免造成点云的冗余,且使用GPU进行并行计算,计算速度快,从而可以加速点云的融合。
实施例4
基于Kinect的室内场景三维重建方法同实施例1-3,步骤4.3.1中所述的权重W和距离D,通过如下权重公式和距离公式计算:
Wi(x,y,z)=min(max weight,Wi-1(x,y,z)+1)
其中Wi(x,y,z)为第i帧全局数据立方体中体素的权重,Wi-1(x,y,z)为第i-1帧全局数据立方体中体素的权重,max weight为最大权重,Di(x,y,z)为当前帧全局数据立方体中体素到物体表面的距离,Di-1(x,y,z)为上一帧全局数据立方体中体素到物体表面的距离,di(x,y,z)为根据当前帧深度数据计算得到的全局数据立方体中体素到物体表面的距离。
第i帧体素的权重Wi(x,y,z)为最大权重max weight和第i-1帧体素权重Wi-1(x,y,z)加1的最小值,第i帧体素的距离Di(x,y,z)为第i-1帧体素距离Di-1(x,y,z)和第i帧深度数据计算得到的距离di(x,y,z)按照各自权重融合的结果。
上述两个公式中i的取值范围为i≥2,且i=1时所有体素的权重W1(x,y,z)都为0,所有体素的距离D1(x,y,z)都为1。
针对权重公式,当i=2时,max weight为1,W1(x,y,z)为0,由公式可得W2(x,y,z)为1。
针对距离公式,当i=2时,由已知W1(x,y,z)、W2(x,y,z)、D1(x,y,z)和第1帧测量得到的d1(x,y,z),可以计算出D2(x,y,z),通过D2(x,y,z)可以判断出当前体素是处于物体内侧、外侧还是表面。
本发明使用权重进行全局数据立方体的融合,可以使融合结果更加准确。
实施例5
基于Kinect的室内场景三维重建方法同实施例1-4,步骤4.4中采用光线投射算法获取预测点云数据,包括:
4.4.1利用光线投射算法和当前点云配准矩阵获取全局数据立方体的预测点云数据;光线投射算法的基础是从投射中心投射出一条光线,直到该光线达到阻挡其继续传播的最近物体的表面。
4.4.2预测点云数据和当前帧点云数据进行配准,提高点云配准的精度。在此处利用光线投射算法,结合当前点云配准矩阵可以获取全局数据立方体中距离值为0的体素,从而得到预测点云数据,用于在下一帧更新点云配准矩阵。
许多三维重建算法是采用当前帧点云数据和上一帧点云数据进行配准的,这种方法会使每一帧的误差累积起来,最终导致较差的三维重建效果,而本方法采用预测点云数据进行配准,因为预测点云数据是根据全局数据立方体计算获得的,所以可以极大地降低累积误差,达到更好的重建效果。
下面给出一个完整具体的例子,对本发明进行进一步说明。
实施例6
基于Kinect的室内场景三维重建方法同实施例1-5,参见图1,本发明采用的技术方案是:
1.图像采集与预处理
Kinect通过USB2.0接口与计算机进行连接,计算机CPU为Core i7 4790,显卡为GTX970,操作系统为Windows 7SP1 64位。
首先通过Kinect进行图像采集,获取场景中物体的深度数据和彩色数据,分辨率都是640*480,并使计时器开始计时。其中,Kinect是一种体感外设,共有三个摄像头,中间镜头为RGB彩色摄像机,左右边镜头分别为红外线发射器和红外线CMOS摄像机组成。其中红外线能对空间进行编码,只要在空间中打上这样的结构光,整个空间就都被做了标记,把一个物体放进这个空间,通过物体表面上的散斑图案,就可以确定出物体的位置信息。
由于受到人为扰动、光照、Kinect自身精度的影响,获取的深度数据中存在噪声和空洞,这里采用联合滤波的方法去除深度图像中的噪声,同时对缺失的深度信息进行修补。这种方法同时利用深度图像和彩色图像,利用高斯核函数计算出深度图像空间域权值ws和彩色图像灰度域权值wr,然后使用ws和wr计算得到滤波所需权值w,公式如下所示:
w=ws×wr
其中σs、σr为基于高斯函数的标准差,决定滤波器的性能。G(i,j)为将彩色图像转换为灰度图像后在像素点(i,j)处的灰度值,G(x,y)为深度图像在像素点(x,y)处的灰度值。本例中选取σs=4,σr=4。
滤波前后的深度数据如图3所示,图3(a)是滤波前的深度数据,图3(b)是滤波后的深度数据,可以看出图3(a)中存在较多的噪声和空洞,图3(b)中噪声和空洞大大减少。本发明采用的滤波方法在保留前景和背景边缘的同时,引入信息完整的彩色图像,去噪的同时也能对深度信息缺失的部分进行修补。
然后对深度数据进行降采样,将原始分辨率为640*480的数据降采样得到分辨率为320*240、160*120和80*60的深度数据,构建深度图金字塔,为之后的ICP点云配准做准备。
2.点云获取与计算法向量
根据Kinect相机的参数得到相机变换矩阵,将深度数据由图像坐标系转换到相机坐标系,得到当前视角下的点云数据,这是一幅桌面场景的点云图,如图4所示,并使用特征值估计计算出各点的法向量。具体可以采用点云库PCL中的函数depth2cloud来实现。
3.TSDF全局数据立方体的建立与预测点云的计算
根据截断符号距离函数(Truncated Signed Distance Function),将点云数据转换到全局数据立方体中(Volume)的体素中。本例中将立方体边长设定为3m,划分为512×512×512个体素,初始所有体素的距离值都为1,权重都为0。设定立方体左下角为坐标原点,垂直立方体正面且向立方体内侧的方向为Z轴正方向,水平向右为X轴正方向,水平向上为Y轴正方向,Kinect初始位置坐标为[1.5 1.5-0.3],相机在此位置可以拍摄到大部分地方。
然后使用光线投射算法结合全局数据立方体计算获得预测点云数据。
此步骤仅在第1帧时执行一次,第2帧以后不再执行。
4.基于ICP算法的点云融合
点云融合流程如图2所示。
(1)返回执行步骤1—步骤2,再次获取一帧点云数据并计算法向量,根据ICP算法结合当前帧点云数据和上一帧获取的预测点云数据更新点云配准矩阵,然后通过更新后的点云配准矩阵更新全局数据立方体。
(2)更新全局数据立方体时,遍历全局立方体中所有体素,用当前的点云配准矩阵将其反变换到图像坐标系,然后与当前深度数据进行对比,如果差值在一定阈值内,就更新此体素的距离和权重,本例中阈值设定为10mm。阈值的大小和重建的精度有关,本领域技术人员可以根据需要自行选定。
(3)根据光线投射算法,利用更新后的全局数据立方体和当前点云配准矩阵计算出新的预测点云,用于在下一帧更新点云配准矩阵。
循环执行点云融合的步骤,直到计时器达到设定时间,本例中设定时间为3分钟,停止获取点云数据,得到配准好的点云数据。
5.点云数据的渲染
对配准好的点云数据进行渲染,得到三维物体的网格表示。使用Marching Cube算法对配准好的点云数据进行渲染。对于每个被处理的体素,使用线性插值抽取等值面,然后对等值面进行网格三角化。最终得到物体的三维模型,如图5所示,图中清晰地展示了桌面场景三维重建的效果,场景中的显示器、键盘、鼠标等物体可以清晰地辨认,且物体之间的层次关系相对准确。最后将重建的模型保存为“.ply”格式的模型数据。之后随时可以通过软件MeshLab对模型进行查看和编辑。
简而言之,本发明公开的基于Kinect的室内场景三维重建方法,包括步骤:1.使用Kinect获取物体的深度数据,对深度数据进行去噪并降采样;2.根据Kinect的参数和深度数据得到物体的点云数据,并计算法向量;3.使用TSDF算法建立全局数据立方体,使用光线投射算法计算预测点云数据;4.通过ICP算法和预测点云数据计算点云配准矩阵,将每帧获取的点云数据融合到全局数据立方体中实现点云数据融合配准,逐帧融合点云数据,直至获得较好的融合效果;5.通过等值面提取算法对点云数据进行渲染,构建出物体的三维模型。本发明的优点为:配准时通过多分辨率深度数据,提高配准的速度;利用光线投射算法获得预测点云,和当前帧点云进行配准,提高配准的精度;利用TSDF算法进行点云融合,融合速度快,冗余点少。本发明可以满足室内场景实时重建的需要,用于机器人导航、工业测量、虚拟交互等领域。
- 还没有人留言评论。精彩留言会获得点赞!