基于有向无环图的大数据作业调度系统的制作方法
本发明涉及一种大数据作业调度系统,尤其涉及一种基于有向无环图的大数据作业调度系统。
背景技术:
随着业务指标的迭代,而使大数据作业日趋复杂化的时候,任务的运行情况的监控,异常问题的排查,变得更复杂,而大数据生态圈组件丰富,产生出很多不同类型的程序(任务)运行在大数据平台之上,如:MapReduce、Hive、Pig、Spark、Java、Shell、Python等。这些组件的任务需要不同的运行环境,并且除了定时运行,各种类型之间的任务存在依赖关系,普遍各业务的数据任务基本都是靠Crontab定时调度,各个任务之间的依赖仅靠简单的串行来实现,这样做的问题:1、很容易造成前面的任务未结束或者失败,后面的任务也运行起来,最终跑出错误的分析结果2、任务不能并发执行,增加任务执行的整体时间窗口3、任务管理和维护很不方便,不好统计任务的执行时间及运行日志4、缺乏及时有效的告警。
通常业内采用Oozie和阿里的Zeus大数据调度系统来解决上述问题。Oozie是一个基于工作流引擎的开源框架,是由Cloudera公司贡献给Apache的,它能够提供对Hadoop MapReduce和Pig Jobs的任务调度与协调,Oozie需要部署到Java Servlet容器中运行,Oozie工作流定义,同JBoss jBPM提供的jPDL一样,也提供了类似的流程定义语言hPDL,通过XML文件格式来实现流程的定义。Zeus从Hadoop任务的调试运行,到生产任务的周期调度,Zeus支持任务的整个生命周期,从功能上来说,支持:1、Hadoop MapReduce任务的调试运行;2、Hive任务的调试运行;3、Shell任务的运行;4、Hive元数据的可视化查询与数据预览;5、Hadoop任务的自动调度。
但是,Oozie和Zeus都存在不足的地方,Oozie的缺点在于,1、Oozie调度的Workflow只能使用XML文件配置;2、启动调度只能通过命令行;3、无法通过Oozie界面调试调度脚本;4、Oozie无法可视化调试脚本时候;5、支持调度的大数据组件少。Zeus的缺点在于,1、长期缺少人维护;2、支持的是Hadoop1.X;3、支持调度的大数据组件少。
因此,为了支持大数据生态圈的组件调度,并且具有扩展性,向后兼容新生组件的调度,需要开发一种大数据作业调度系统。
技术实现要素:
本发明所要解决的技术问题是提供一种基于有向无环图的大数据作业调度系统,支持大数据生态圈之间组件的任务调度及其监控,满足未来扩展组件的需要,并且具有活跃的管理模块和备用的管理模块两套管理模块,实现调度系统的高可用。
本发明为解决上述技术问题而采用的技术方案是提供一种基于有向无环图的大数据作业调度系统,包括数据库,所述数据库用于存储作业任务和业务节点的所有信息,其中,所述大数据作业调度系统还包括:
数据库管理模块,与所述数据库连接,所述数据库管理模块用于操作所述数据库;
DAG算法模块,与所述数据库管理模块连接,所述DAG算法模块用于通过所述数据库管理模块获取所述数据库中的所有的作业任务,确定作业任务和业务之间的对应关系,并生成相应的业务节点,然后使用拓扑算法,遍历所有作业任务,根据业务依赖关系确定所有作业任务的先后执行顺序和串并行执行顺序,将所有的业务节点组合在一起形成树状业务作业图,根据树状业务作业图确定下一个或多个需要执行的作业任务,并根据调度模块的执行结果更新当前业务节点;
调度模块,与所述DAG算法模块和所述作业任务连接,所述调度模块用于询问所述DAG算法模块,以获取需要调度的所述作业任务,识别记录串行或并行作业任务的调度,并根据监听模块的反馈信息判断作业任务的执行结果;
监听模块,与所述调度模块和所述作业任务连接,所述监听模块用于监听所有运行的作业任务反馈的信息,并将所述作业任务反馈的信息传递给所述调度模块。
优选地,所述业务节点保存所有的所述作业任务的信息和所述业务节点自身的状态信息,并且所述业务节点通知所述数据库管理模块进行所述作业任务的信息更新。
优选地,所述识别记录串行或并行作业任务的调度,包括当所述DAG算法模块中生成的树状业务作业图中的作业任务的顺序为先后顺序,则识别记录所述作业任务为串行调度,当所述DAG算法模块中生成的树状业务作业图中的作业任务的顺序为平行顺序,则识别记录所述作业任务为并行调度。
优选地,所述调度模块中识别记录串行或并行作业任务的调度,包括将作业任务压缩生成Java压缩包并存放在服务器上,然后通过脚本调用向所述服务器发送执行命令。
优选地,所述调度模块还用于根据所述监听模块传递的所述作业任务反馈的信息,判断是否需要向所述DAG算法模块询问获取下一层作业任务的调度顺序。
优选地,所述调度模块还用于根据监听模块的反馈信息判断所述作业任务是否超过失败次数,若所述作业任务超过失败次数且失败原因不可修复,则反馈给所述DAG算法模块进行所述业务节点更新。
优选地,所述大数据作业调度系统还包括:监控模块,与所述业务节点连接,所述监控模块用于根据所述业务节点的信息,判断是否需要向所述DAG算法模块询问流程无法继续,并判断是否需要发送警告信息。
优选地,所述作业任务包括作业任务报告单元和作业任务监控单元,所述作业任务报告单元用于与所述监听模块通信,反馈所述作业任务的运行情况和心跳信息,所述作业任务监控单元用于搜集所述作业任务运行产生的所有监控信息并反馈给所述作业任务报告单元。
优选地,所述大数据作业调度系统还包括客户端模块,与所述业务节点连接,所述客户端模块用于获取所述业务节点的信息。
优选地,所述大数据作业调度系统还包括备用管理模块以及心跳保持模块,所述心跳保持模块和所述客户端模块连接,所述客户端模块将所述业务节点的信息传送给所述心跳保持模块,所述备用管理模块和所述客户端模块以及所述数据库连接,所述备用管理模块监听所述业务节点的信息,如果判断所述业务节点的信息异常,则将所述备用管理模块切换为活跃的数据库管理模块。
本发明提出的基于有向无环图的大数据作业调度系统,通过DAG算法模块,将所有的业务节点组合在一起形成树状业务作业图,根据树状业务作业图确定下一个或多个需要执行的作业任务,并根据调度模块的执行结果更新当前业务节点;从而支持大数据生态圈之间组件的任务调度,满足未来扩展组件的需要;由于DAG算法模块负责作业任务的流程走向形成有向无环图,因此易于设置具有活跃的管理模块和备用的管理模块两套管理模块,实现调度系统的高可用。
附图说明
图1是本发明实施例中的基于有向无环图的大数据作业调度系统模块图;
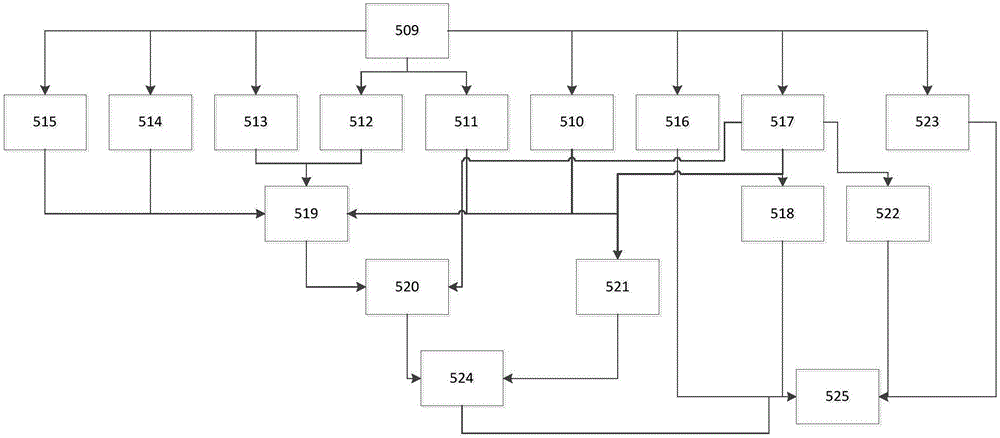
图2是本发明实施例中的基于有向无环图的大数据作业调度系统中的作业任务的作业图。
具体实施方式
本发明实施例中,基于有向无环图的大数据作业调度系统支持大数据生态圈之间组件的任务调度及其监控,满足未来扩展组件的需要,并且具有活跃的管理模块和备用的管理模块两套管理模块,实现调度系统的高可用。
为使本发明的上述目的、特征和有益效果能够更为明显易懂,下面结合附图对本发明的具体实施例做详细的说明。
图1是本发明实施例中的基于有向无环图的大数据作业调度系统模块图。
如图1所示,本发明提供的基于有向无环图的大数据作业调度系统,包括数据库11,所述数据库用于存储作业任务和业务节点的所有信息,所述大数据作业调度系统还包括:数据库管理模块171,与所述数据库11连接,所述数据库管理模块171用于操作所述数据库11;DAG(Directed Acyclical Graphs)算法模块178,与所述数据库管理模块171连接,所述DAG算法模块178用于通过所述数据库管理模块171获取所述数据库11中的所有的作业任务14、15、16,确定作业任务14、15、16和业务之间的对应关系,并生成相应的业务节点175、176,然后使用拓扑算法,遍历所有作业任务14、15、16,根据业务依赖关系确定所有作业任务14、15、16的先后执行顺序和串并行执行顺序,将所有的业务节点175、176组合在一起形成树状业务作业图,根据树状业务作业图确定下一个或多个需要执行的作业任务14、15、16,并根据调度模块174的执行结果更新当前业务节点175、176;调度模块174,与所述DAG算法模块178和所述作业任务连接,所述调度模块用于询问所述DAG算法模块,以获取需要调度的所述作业任务14、15、16,识别记录串行或并行作业任务的调度,并根据监听模块173的反馈信息判断作业任务14、15、16的执行结果;监听模块173,与所述调度模块174和所述作业任务14、15、16连接,所述监听模块173用于监听所有运行的作业任务14、15、16反馈的信息,并将所述作业任务14、15、16反馈的信息传递给所述调度模块174。
所述作业任务,是指可以统一抽象成采集、计算、入库的作业,视为一个个作业任务,调度系统根据数据库的任务信息,发起作业任务,监控其运行状况,控制作业流程的走向。其中,所述业务节点175、176保存所有的所述作业任务的信息和所述业务节点自身的状态信息,并且所述业务节点175、176通知所述数据库管理模块171进行所述作业任务14、15、16的信息更新。
在具体实施中,所述识别记录串行或并行所述作业任务的调度,包括当所述DAG算法模块178中生成的树状业务作业图中的作业任务的顺序为先后顺序,则识别记录所述作业任务为串行调度,当所述DAG算法模块178中生成的树状业务作业图中的作业任务的顺序为平行顺序,则识别记录所述作业任务为并行调度。
本系统的元数据,是业务的相关信息,如:第几层的作业,执行依赖哪些业务,业务类型等,所有的元数据信息,都存储在数据库中,并统一由DbUser模块来进行读写,DbUser模块采用面向接口编程,减少耦合性。元数据的生成,可以通过直接写入数据库的方法,添加业务,也可以通过web页面,通过拖拽的方式,进行业务类的增加。
通常作业与作业间可以并行执行,也会要等待多个任务完成时,才能执行下个任务,因为随着时间的发展,业务流程图会越来越复杂,从而导致监控与任务间的协调工作的难度成几何级增加。
DAG数据结构跟踪基本块中值和变量的计算和赋值;块中使用的来自别处的值表示为叶子结点;值上的操作表示为内部结点;新值的赋值表示为将目标变量或临时变量的名字附加到表示赋值的结点上。
本调度系统采用DAG算法,来描述业务与业务之间的关系,把每个业务看做一个节点(业务),通过里面配置信息,由DAG算法模块178,负责生成一个有向无环图,如图2所示,共有作业任务509~525,作业任务509为起始业务节点;515、514、513、512、511、510、516、517和523为第二层作业任务,且作业任务511和512为并行任务;519、518和522为第三层作业任务,520和521为第四层作业任务,524和525为第五层作业任务。通过遍历该图,可知哪些作业能并行执行,哪些业务需要等待多个上级任务才能开始执行,并记录作业的运行情况,把下一个或多个需要执行的业务,通知调度模块174,进行调度,并根据反馈回来的信息,更新有向无环图中的当前的业务节点,从而进一步判断下个任务的调度。
其中,调度由调度模块174实现,所述调度模块中174识别记录串行或并行作业任务的调度,包括将作业任务14、15、16压缩生成Java压缩包并存放在服务器上,然后通过脚本调用向所述服务器发送执行命令,执行java-cp类参数或通过sh计算.sh参数。每个业务类型,实现统一的接口,具体的业务,由具体的业务所需的组件,进行具体的实现,这样,就可以扩展增加以后大数据生态圈的新增的组件,调度方式因组件不同而不同,如:MapReduce,Spark,通过向大数据平台,如:Hadoop,提交任务,由此减少代码入侵到Spark和Hadoop的源码,如果调用组件是采集,如:flume,则会通过远程ssh,定位到对应的机子,调用对应的启动脚本,进行组件的启动。
在具体实施中,所述调度模块174还用于根据所述监听模块173传递的所述作业任务14、15、16反馈的信息,判断是否需要向所述DAG算法模块178询问获取下一层作业任务的调度顺序。
所述调度模块174还用于根据监听模块的反馈信息判断所述作业任务14、15、16是否超过失败次数,若所述作业任务14、15、16超过失败次数且失败原因不可修复,则反馈给所述DAG算法模块178进行所述业务节点更新。任务会因网络原因,机器故障等原因,而执行失败,当调度模块174从监听模块173得知某个业务执行失败时,会进行判断,如果是可修复错误,则重启任务,如:采集flume组件启动失败,则在另一台服务器上,启动flume,并通过脚本,远程杀死对应的任务,如果失败次数超过元数据配置的错误次数,则判断任务执行错误,并通知DAG算法模块178,进行对应任务的状态设置为失败,如果是不可修复错误,则立即通知DAG算法模块178,进行对应任务的状态设置为失败。
在具体实施中,所述大数据作业调度系统还包括:监控模块177,与所述业务节点175、176连接,所述监控模块177用于根据所述业务节点175、176的信息,判断是否需要向所述DAG算法模块178询问流程无法继续,并判断是否需要发送警告信息。通过调度模块174,告知对应的业务的失败,会把对应的业务节点状态设置为失败,通知监控模块177,进行相关的告警,告警方式通过工厂模式选择,在业务业务节点上配置好,如:邮件告警,而依赖该失败作业的下层任务,则不会再被调度,其余不依赖该失败作业的流程,则正常进行调度。
其中,所述作业任务14、15、16包括作业任务报告单元141和作业任务监控单元142,所述作业任务报告单元141用于与所述监听模块173通信,反馈所述作业任务14、15、16的运行情况和心跳信息,所述作业任务监控单元142用于搜集所述作业任务14、15、16运行产生的所有监控信息并反馈给所述作业任务报告单元141。作业任务监控单元142负责监控作业的完成情况,也是实现统一的接口,具体的业务,由具体的业务所需的组件,进行具体的实现,并且把这些信息,交给作业任务报告单元141,由作业任务报告单元141通过RPC机制,进行反馈。作业任务报告单元141,还有一个责任,就是定时向调度系统发送心跳,如果超时没有发送心跳,则判断该业务执行失败,调度系统监听模块173,就是负责监听各个业务反馈回来的信息和心跳,并把任务信息反馈给调度模块174。
在具体实施中,所述大数据作业调度系统还包括客户端模块172,与所述业务节点175、176连接,所述客户端模块172用于获取所述业务节点的信息。
在具体实施中,所述大数据作业调度系统还包括备用管理模块12以及心跳保持模块13,所述心跳保持模块13和所述客户端模块172连接,所述客户端模块172将所述业务节点175、176的信息传送给所述保持模块13,所述备用管理模块12和所述客户端模块172以及所述数据库11连接,所述备用管理模块12监听所述业务节点175、176的信息,如果判断所述业务节点175、176的信息异常,则将所述备用管理模12块切换为活跃的数据库管理模块。其中,客户端模块172实时把任务运行更新到心跳保持模块13,让备用管理模块12实时更新任务信息,调度系统通过心跳保持模块13实现心跳机制,当活跃的调度系统因为服务器故障、网络断开等原因,就可以将备用管理模块12切换为活跃的管理模块,继续提供服务。调度系统是部署在一台服务器上,会因为服务器的宕机,网络断开等原因,导致面临调度系统的服务暂停的风险,为了解决这个问题,通过引入保持模块13和备用管理模块12,保持模块13负责将节点业务状态信息的更新,实时写入保持模块13,备用管理模块12则把更新信息读取,并更新自身的业务节点的状态,活跃的调度系统需要定时向保持模块13发送心跳信息,如果超时没发送,则判断活跃的调度系统故障失败,就会远程调用脚本杀死该进程,然后备用管理模块12切换成活跃状态,继续调度监控服务。
随着时间的推移,免不了修改现有业务的流程,或者增加新的业务流程进来,这时,也是通过SQL语句,或者web页面,进行元数据的修改,DAG算法模块178会定期查询数据库,检索元数据是否被修改,如果发现现有业务的元数据被修改了,则会在该业务流程的最后一步,停止下一次的调度,并根据新的元数据,更新现有业务的有向无环图,更新完毕后,则开始进行调度,如果发现有新的业务添加进来,不会停止现有业务的调度,会把新的业务的元数据读取进来,生成对应的有向无环图,然后开始调度。
本发明提出的基于有向无环图的大数据作业调度系统包括DAG算法模块,与所述数据库管理模块连接,所述DAG算法模块用于通过所述数据库管理模块获取所述数据库中的所有的所述作业任务,生成相应的所述业务节点,使用拓扑算法,遍历所述作业任务,生成所述作业任务的顺序序列后,响应回答所有的所述作业任务序列的问题,并将更新后的信息传递给所述业务节点;调度模块,与所述DAG算法模块和所述作业任务连接,所述调度模块用于询问所述DAG算法模块,以获取需要调度的所述作业任务,识别记录串行或并行所述作业任务的调度;从而所述大数据作业调度系统支持大数据生态圈之间组件的任务调度,并支持未来扩展组件的需要。
进一步地,所述大数据作业调度系统还包括备用管理模块以及保持模块,所述保持模块和所述客户端模块连接,所述客户端模块将所述业务节点的信息传送给所述保持模块,所述备用管理模块和所述客户端模块以及所述数据库连接,所述备用模块监听所述业务节点的信息,判断所述业务节点的信息异常,则所述备用管理模块切换为活跃的管理模块,从而所述大数据作业调度系统具有活跃的管理模块和备用的管理模块两套管理模块,实现调度系统的高可用。
进一步地,所述作业任务包括作业任务报告单元和作业任务监控单元,所述作业任务报告单元用于与所述监听模块通信,反馈所述作业任务的运行情况和心跳信息,所述作业任务监控单元用于搜集所述作业任务运行产生的所有监控信息并反馈给所述作业任务报告单元,从而所述大数据作业调度系统支持监听不同大数据生态圈组件的任务的运行情况,并进行实时告警。
本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序可以存储于计算机可读存储介质中,存储介质可以包括:ROM、RAM、磁盘或光盘等。
虽然本发明已以较佳实施例揭示如上,然其并非用以限定本发明,任何本领域技术人员,在不脱离本发明的精神和范围内,当可作些许的修改和完善,因此本发明的保护范围当以权利要求书所界定的为准。
- 还没有人留言评论。精彩留言会获得点赞!