一种基于国产申威26010处理器的稀疏矩阵向量乘异构众核实现方法与流程
本发明涉及一种稀疏矩阵的核心计算稀疏矩阵向量乘SpMV(Sparse Matrix-VectorMultiplication)在国产申威众核处理器上的实现方法,属于高性能数值计算技术领域,主要用于气象、湍流模拟、天体物理、油藏模拟等科学计算和实际应用中。
背景技术:
稀疏矩阵向量乘(SpMV)y=A*x是科学与工程计算中一个非常重要的计算内核,其性能往往对应用整体性能有着很大的影响。SpMV是属于访存密集型的,算法中的浮点计算与存储访问的比率很低,且稀疏矩阵非零元素分布很不规则。传统的CSR(Compressed Sparse Row)格式的SpMV实现中向量x为间接访问且访问不规则,可重用性差,给SpMV的高效实现带来很大挑战。
目前超级计算机的体系结构已经从多核向众核乃至异构众核发展,然而访存墙问题却越来越突出,带宽受限型操作的峰值性能也越来越低,并且实现难度逐步增大。由我国国家并行计算机工程技术研究中心研制的新一代申威异构众核处理器已经面世,其峰值性能为3TFlops/s,聚合访存带宽为130GB/s,相比计算能力,其访存能力偏弱,给稀疏矩阵向量乘的高效实现带来了巨大的挑战。稀疏矩阵向量乘作为迭代解法器的核心计算如果能够提高运行速度,整个计算的运行效率将会大大改善,在实际应用中有着十分重要的作用。
稀疏矩阵是指矩阵A的元素大部分是零,而非零元素所占比例非常小,往往小于总数的1%。通过只存储和操作这些非零元,可以减少存储的内存,并大幅减少乘法次数,进而提高整体性能。稀疏矩阵存储时,除了存储非零元外,还要记录非零元在矩阵中所占的位置。CSR格式是目前使用最广泛的一种存储格式。CSR格式需要存储稀疏矩阵A的每个非零元素的值,非零元所在的列和每行第1个非零元的索引,即需要3个数组(其中矩阵A是m×n矩阵,有nz个非零元),如下所示:
·val[nz],记录每个非零元的值;
·col[nz],记录每个非零元所在的列;
·ptr[m+1],记录每行的第1个非零元在数组val[nz]、col[nz]中的索引,其中ptr[m]=nz。
稀疏矩阵向量乘的形式为y=Ax,其中A为稀疏矩阵,x,y为稠密向量。CSR矩阵存储格式的SpMV核心代码见图1,从图1中可以看出,矩阵A中每个元素都要跟x中相应元素相乘,x的访问是间接的和不规则的,所以运行效率很低。
稀疏矩阵向量乘在异构众核平台的实现难度很大,一般会面临核间负载均衡、x访存开销太大、不同稀疏矩阵访存行为差异很大、带宽利用率很差等问题。在SpMV的异构众核实现及优化方面,前人已经做了很多的工作,但主要集中在商用的GPU和MIC处理器。从2008年开始,基于GPU的SpMV工作大量涌现,这些工作主要通过存储格式、重排、压缩、自适应调优等技术解决带宽利用率、负载均衡、并行度等问题。先后提出了HYB、ELLPACK-R、sliced-ELLPACK、blocked ELLPACK、BRC、BCCOO等新型存储格式;研究了稀疏矩阵的重排技术及压缩格式,以减少访存开销;研究了GPU平台体系结构特征、稀疏矩阵存储格式、稀疏矩阵集之间的关系,并给出自动选择模型;另外还研究了自动调优技术,以根据稀疏矩阵的特征选择最优参数并获取较优的性能。
2011年Intel公司的异构众核处理器Xeon Phi发布,随后Liu等人提出了新的ESB格式,该格式可有效改善Xeon Phi上SpMV向量化性能,并能减少访存开销,另外还提出了混合的动态调度器以改善并行任务的负载均衡性;Tang等人通过新的存储格式VHCC、二维不规则任务划分、自动调优技术等优化了一类scale-free稀疏矩阵SpMV的性能。
另外还有一类工作涉及到多个异构众核处理器,Kreutzer等人主要从改善向量化性能的角度提出新的存储格式SELL-C-σ;Liu等人提出了CSR5存储格式用于改善不规则稀疏矩阵SpMV的性能,在多个异构众核处理器上实现并与现有最优工作进行了对比。
由我国国家并行计算机工程技术研究中心研制的新一代申威异构众核处理器已经面世,其是一款具有自主知识产权的处理器,与目前现有的商用众核处理器均不同。每个核组由控制核心(Management Processing Element,MPE,又称主核)、计算核心簇(Computing Processing Elements clusters,CPE cluster,又称从核)(采用8*8mesh结构)、协议处理部件(PPU)和存储控制器(Memory Controller,MC)组成。平均每个核组的访存带宽为32.5GB/s,实测带宽为27.5GB/s。每个从核拥有64KB的缓存空间LDM(Local Direct Memory),可以通过DMA(Direct Memory Access)实现主存和LDM间的高速传输。目前该处理器刚刚发布,还未出现基于该处理器的SpMV异构众核并行的相关工作,也没有相似报道本发明主要是填补这个空白。
技术实现要素:
本发明解决的技术问题是:针对全新的具有自主知识产权的国产申威处理器,提出一种基于国产申威26010处理器的稀疏矩阵向量乘(SpMV)异构众核实现方法,解决了CSR格式SpMV计算时从核之间任务的负载不均衡、访存带宽利用率、不同类型稀疏矩阵的自适应性能优化等问题,从而整体提升了稀疏矩阵向量乘的性能。
本发明的技术方案为,一种基于国产申威26010处理器的SpMV异构众核实现方法,包括:自适应优化、任务划分和向量x访存三个步骤,首先针对输入的稀疏矩阵进行SpMV计算时的三个参数,即调度方式、向量x的最优静态缓冲区大小、向量x静态缓冲区读取的起始位置进行自适应优化,从而获得该稀疏矩阵的SpMV最优性能;然后根据优化后的调度方式进行任务划分;最后基于优化后的调度方式、向量x的最优静态缓冲区大小、向量x静态缓冲区读取的起始位置三个参数进行从核计算,每个从核计算时对向量x访存采用动静态的访存机制,从而实现基于国产申威26010处理器的SpMV异构众核的过程。
(1)任务划分方法
申威26010众核处理器每个核组包括1个主核和64个从核,为了充分利用从核核组的计算资源,将计算任务尽可能的分给从核,主核主要负责前处理和控制。
对于稀疏矩阵而言,任务划分方法有两种:一维划分和二维划分。二维划分时多个从核会同时更新y向量的一部分,需要加锁处理,从而导致额外的开销。对规则稀疏矩阵而言,每行的非零元个数较少,LDM可以容纳至少一行计算所需的元素,所以我们采用一维的任务划分方法。如果稀疏矩阵一行的非零元太多,导致LDM空间不能一次容纳一行的元素进行计算,那么将采用主核进行计算。
一维划分方式又有两种:
静态任务划分。将稀疏矩阵按行等分,每个从核计算m/64行,从核内部循环执行,每次只计算稀疏矩阵的srow行,其中srow为当前申威26010众核处理器一个从核的LDM可以容纳的最多稀疏行大小。
动态任务划分。将稀疏矩阵srow行的计算视为一个子任务,形成任务池。每个从核一次只负责一个子任务,执行结束后再取下一个子任务进行计算。
静态任务划分方式每个从核执行的稀疏矩阵行数基本相同,动态任务划分方式时每个从核执行的稀疏矩阵行数根据当前从核的执行情况动态调整,总稀疏矩阵行数可能大不相同。这两种方式分别适用于不同类型的稀疏矩阵。
基于这两种任务划分方式,设计了两种任务调度方式:静态调度和动态调度。其中动态调度方式需要各个从核间协同,开销比较大,所以对其进行了优化,只在第一次运行SpMV时采用动态调度,并记录每个计算核心所分配的任务,在以后的执行过程中,均按照这种方式来进行任务分配,将其称为动-静态任务调度。
这种调度方式是指第一次运行SpMV采用动态调度,并记录每个从核负责的任务,在第二次及以后的执行中,直接按照第一次的任务分配方式进行处理。所以称为动-静态任务调度。
(2)x访存机制
稀疏矩阵向量乘中x是间接访存,访存行为很不规则,在申威众核处理器上,x的访存是优化的重点,直接对其最终性能起到决定性的影响。本发明采用动静态缓存方式。设置向量x的两块缓存区,分别为动态的和静态的,静态缓存区加载一次重复运行,动态缓存区根据实际运行情况多次加载,具体见图3。另外加载静态缓存区的初始位置,对SpMV的性能也有一些影响。初始位置有两种选择:1)从当前从核计算的行块的起始位置读取,记为start-x-row;2)从当前从核计算行块所需的第一个x处读取,记为start-x-current。
(3)自适应优化
由于实际应用中稀疏矩阵千差万别,非零元的分布方式各不相同。对每一个稀疏矩阵而言,任务分配方式、静态缓存大小、静态缓存加载的起始位置等均对其性能有着很大的影响,有必要针对该稀疏矩阵选择最优的参数组合。可选的参数如下:
●调度方式。有两种选择:静态调度和动静态结合的调度方式。
●静态缓冲区读取的起始位置。
●静态缓冲区的大小,其最大值受LDM限制,每个矩阵均不同,初始值选为128,每128递增。
为了减少搜索开销,本发明对Matrix Market矩阵集中57个不同类型的稀疏矩阵选择不同参数的性能结果进行分析,发现任务调度方式、静态缓存区读取的起始位置均与静态缓存区的大小关系不大,据此本发明确定了如图4的搜索顺序。
该搜索过程需要大约3-22个SpMV的时间,但是对于实际应用来说,这个过程可以预先进行,以便于在以后的迭代过程中选用性能最高的SpMV实现。
本发明与现有技术相比的有益效果:
(1)对不同的稀疏矩阵采用不同的任务划分和分配方式。这样可根据稀疏矩阵特点选用更合适的任务划分和分配方式,从而提升整体性能。
(2)SpMV操作中对向量x的访存是不连续的,而且从核直接访问主存的开销很大,约需200多拍,这给申威处理器的SpMV异构众核高效实现带来了巨大的挑战。为了能够提升访存带宽利用率,减少向量x的总访存量,本发明利用了稀疏矩阵的局部性特征设计了动静态的x缓存机制,大幅减少了总访存量,提升了性能。
(3)对SpMV实现设置3个可调参数,对输入稀疏矩阵开展自适应优化,以选取最优的执行参数,进而提升SpMV性能。
(4)由于动态调度方式的开销较大,本发明并未直接使用,而是对其进行了优化,设计了一种新的动-静态的调度方式,既可以实现从核间的负载均衡,又减少了调度开销。
附图说明
图1主核版SpMV实现示意图;
图2为本发明提出的从核版SpMV实现示意图;
图3为本发明中向量x的动静态缓冲区加载流程示意图;
图4为本发明中自适应调优时最优参数搜索顺序图;
图5从核核组SpMV性能。
具体实施方式
下面结合实施例对本发明进行详细说明。
如图1所示,主核版SpMV实现过程如下:
(1)对稀疏矩阵每行进行循环计算,首先获得当前行号并判断,如果当前行号小于稀疏矩阵总行数,则进行下一步;
(2)对每行稀疏的所有非零元进行遍历,通过数组访问获得当前非零元的值信息以及列下标信息,并根据列下标信息得到向量x的值,二者相乘后并累加,即可得当前行的计算结果;
(3)将计算结果赋值给向量y。
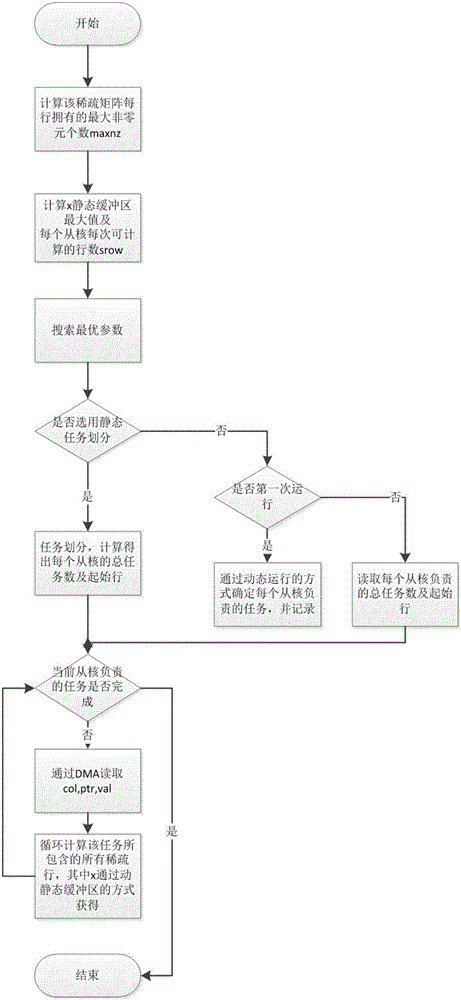
如图2所示,本发明的SpMV具体实现如下:
(1)计算该稀疏矩阵每行拥有的最大非零元个数maxnz。
(2)计算每个从核每次可计算的行数srow及x静态缓冲区最大值max_x_size。每个从核64KB空间分配如下:其中24KB用于存储x,y,ptr和其他局部变量,40KB用于存放val和col,由于val为双精度数据类型,col为整型数据类型,共占12字节,所以40KB空间最多只能存储40*1024/12个val和col元素,即3413个。那么srow=3413/maxnz,其中maxnz为该稀疏矩阵每行最大的非零元个数。通过公式(24*1024-32*8-srow*8-(srow+1)*8-2048)/8计算max_x_size。
(3)搜索最优参数。对每个测试矩阵,采用图4所示的搜索技术搜索该矩阵的最优执行参数,包括任务划分方式、x静态缓冲区最优大小、向量x静态缓冲区读取的起始位置。
(4)任务调度。如果选用静态任务调度,直接通过矩阵总行数和当前计算的总从核数进行任务划分,每个从核计算其中一部分,并行计算任务按照从核号顺序排列。如果选用动-静态任务调度,在第一次调用SpMV函数时,将稀疏矩阵所有行按照srow行为一组进行划分,每组为一个计算任务,形成任务池。每个从核从任务池中取任务进行计算,当且仅当当前任务计算完成时再读取下一块任务,具体任务分派的方式动态决定,且每个从核记录自己负责的每个任务的起始行数以及总任务数。在第二次以后调用SpMV函数时,每个从核读取之前记录的每个任务进行计算。
(5)计算。每个从核循环计算自己所负责的任务。对于每个子任务,首先通过DMA从内存读取数组col,ptr,val的元素到LDM空间,并通过图3所示方法加载x进行计算。计算结束后,将结果y通过DMA传回主存。
其中步骤(5)的向量x元素加载方法如图3所示,具体如下:
1)通过col数组得到当前所需x的下标。
2)判断当前所需x是否位于静态缓冲区,如果是,直接读取并进行计算。
3)如果不是,则判断x的动态缓冲区是否加载。如果已经加载,判断当前所需x是否位于动态缓冲区中,如果是,直接读取并进行计算。如果不是,从当前所需x处加载动态缓冲区,所需x即为该动态缓冲区的第一个元素,读取并计算。
其中步骤(3)的自适应搜索方法如图4所示,具体如下:
1)搜索x最优静态缓冲区大小。初始值为128,最大为max_x_size,每128递增。通过比较静态缓冲区大小为上述值时SpMV的运行时间,选取最小运行时间对应的静态缓冲区大小即为x最优静态缓冲区大小。
2)搜索读取x的最优起始位置。起始位置有两种选择,分别设置并运行,选取运行时间最短的起始位置。
3)搜索最优任务划分方法。分别设置静态和动态任务划分方法,并比较二者的运行时间,选择最小运行时间对应的方法。
采用以上介绍的技术,用神威太湖之光测试平台进行验证。
测试平台信息如下:申威26010异构众核处理器,主从架构,从核组为8*8的mesh结构,LDM空间为64KB,采用sw5cc编译器进行编译。
测试矩阵集采用国际上著名的Matrix Market稀疏矩阵集中的矩阵进行测试,本发明选取了16个测试矩阵,其矩阵信息见表1:
表1矩阵信息表
分别实现了CSR格式在主核MPE和从核组CPE的SpMV操作,并进行了性能对比,结果见表2和图5,从中可以看出测试的矩阵相对主核版均有不同程度的性能提升,最高可达10倍多,最低也有4倍多,平均加速比为6.51倍。
表2从核核组SpMV性能结果
总之,本发明设计了静态、动态两种不同的任务划分方法,以适应不同的稀疏矩阵;提出了一套动静态的缓存机制,以提升向量x的访存命中率;提出了一套自适应的优化方法,针对输入的稀疏矩阵,可以动态选出最优的执行参数,以提升其运行性能。本发明采用Matrix Market矩阵集中的16个稀疏矩阵进行测试,相比国产申威处理器单主核运行版SpMV最高有10倍左右加速,平均加速比为6.51。
本发明说明书中未作详细描述的内容属于本领域专业技术人员公知的现有技术。
提供以上实施例仅仅是为了描述本发明的目的,而并非要限制本发明的范围。本发明的范围由所附权利要求限定。不脱离本发明的精神和原理而做出的各种等同替换和修改,均应涵盖在本发明的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!