面向非规则数据密集应用的群组式线程预取方法与流程
本发明涉及高性能计算的技术领域,具体涉及一种面向非规则数据密集应用的群组式线程预取方法,面向非规则数据密集应用基于共享缓存实现线程数据的存取。
背景技术:
现有的数据预取方法都依赖于密集数据访问的规律性。面向非规则数据密集应用的群组式线程预取(Group Thread Prefetching,GTP)方法设计的主要目的是为复杂的非规律密集数据访问提供一种有效的数据预取策略,广泛地应用于高性能计算与分布式计算领域,如信号处理程序、流体力学计算、生物信息计算、社会学统筹问题计算等。简单地说,GTP方法通过在线剖析技术为非规则数据密集应用在多核处理器环境下分析出访存和计算延迟特征,该特征决定了辅助线程能够隐藏的访存延迟比例。根据访存延迟比例分配预取数据群组,避免无用数据预取和缓存污染。
非规则数据密集应用中通常采用复杂的数据存储结构,例如链式数据存储结构。一方面,复杂的数据存储结构使得数据访问不具备时间局部性特征和空间局部性特征,传统的硬件预取技术无法准确预测预取数据地址,其有效性难以保证。另一方面,复杂的数据存储结构中,数据间常存在依赖和约束关系,传统的软件预取技术无法提前发出数据预取请求,难以做到及时预取。面向非规则数据密集应用的预取技术能够有效解除数据间的依赖和约束关系,达到有效地预取。
线程预取技术是用来隐藏多核平台中访存延迟的有效方法,目前已经在数据密集应用程序中得到了广泛应用。线程预取技术使用一个专门线程辅助主线程提前把数据取到高速缓存中。目前,辅助线程预取技术以提高预取准确率和时效性为目的,研究的着重点主要集中在辅助线程构造、辅助线程启动和触发、辅助线程与主线程间的同步机制几个方面。在面向非规则数据密集应用时,辅助线程不能总是领先于主线程执行或辅助线程领先于主线程执行的太多,导致辅助线程不能及时地给主线程提供有用的数据。GTP方法根据辅助线程能够隐藏的访存延迟比例分配预取数据群组,达到尽早发出预取请求、避免无用数据预取和提高预取时效性的目的。
鉴于目前研究的线程预取技术,其辅助线程构造方式不适合用于访问依赖的非规则数据密集应用,在现有的技术中还没有面向非规则数据密集应用的群组式线程预取方法。
技术实现要素:
为了解决现有非规则数据密集应用中数据间的依赖性和约束性,本发明提出一种面向非规则数据密集应用的群组式线程预取方法,基于共享缓存为非规则数据密集应用构建群组式预取线程,保障数据预取的有效性。
为了解决上述技术问题,本发明的技术方案是:一种面向非规则数据密集应用的群组式线程预取方法,采用在线剖析技术获取非规则数据密集应用的执行时特征,确定合理的预取率构建群组式预取线程实现有效数据预取,其步骤如下:包括非规则数据访存特征剖析、群组式预取线程构建及线程预取中同步机制的确立;
所述非规则数据访存特征剖析包括:
A)使用VTUNE性能分析器获取非规则数据密集应用的执行行为特征;
B)使用VTUNE性能分析器获取热点循环相对延迟的计算延迟TC、循环依赖数据访问延迟Tdm和非循环依赖数据访问延迟Tim值;
所述群组式预取线程构建包括:
C) 判断计算延迟TC和循环依赖数据访问延迟与非循环依赖数据访问延迟之和(Tdm+Tim) 的关系;
D) 当TC<(Tdm+Tim)时,基于理想情况下确定合理的预取率R=(TC+Tim -Tdm)/2;当TC≥(Tdm+Tim)时,预取率R 值等于1;
E) 利用切片技术基于预取率R 构建群组式预取线程;
所述线程预取中同步机制的确立包括:
F) 在主线程热点循环入口处设置标志位flag为1,向预取线程发出信号,通知预取线程开始预取工作;在主线程热点循环出口处设置标志位flag为0,向预取线程发送暂停信号,通知预取线程暂停预取,等待下一次预取信号。
所述执行行为特征包括频繁发生共享缓存L2 Cache失效行为的各个热点循环所在的函数名称、各热点循环的CPU时钟消耗情况、共享缓存L2 Cache失效情况和预取平台访存情况。
所述使用VTUNE性能分析器获取热点循环相对延迟的计算延迟TC、循环依赖数据访问延迟Tdm和非循环依赖数据访问延迟Tim值的方法是:VTUNE性能分析器分析程序源代码,找出频繁发生缓存失效行为的热点循环,并分析热点循环执行的访存计算延迟特征,获得评估测试程序的热点循环相对延迟的循环依赖数据访问延迟Tdm、非循环依赖数据访问延迟Tim与计算延迟TC的值。
所述获得评估测试程序的热点循环相对延迟的循环依赖数据访问延迟Tdm、非循环依赖数据访问延迟Tim与计算延迟TC的值的方法步骤为:VTUNE性能分析器测试程序中热点循环的执行行为,得到行为事件CPU_CLK_UNHALTED.CORE和MEM_LOAD_RETIRED.L2_MISS的值和其在测试程序热点循环中的分布情况,其中,事件CPU_CLK_UNHALTED.CORE的值为程序执行时非停机状态花费的机器周期CLKT,事件MEM_LOAD_RETIRED.L2_MISS的值为程序执行访存行为时共享缓存L2 Cache 缺失次数;VTUNE性能分析器识别热点循环中的循环依赖数据访问操作和非循环依赖数据访问操作,分辨事件CPU_CLK_UNHALTED.CORE和事件MEM_LOAD_RETIRED.L2_MISS对应语句执行的是访存操作还是非访存操作;累加执行非访存操作语句的CPU_CLK_UNHALTED.CORE的百分比,得到所有非访存操作消耗的CPU_CLK_UNHALTED.CORE百分比,其与CLKT的积为计算延迟TC的值;累加循环依赖数据访问语句和非循环依赖数据访问语句的CPU_CLK_UNHALTED.CORE百分比,所有循环依赖数据访问操作消耗的CPU_CLK_UNHALTED.CORE百分比与CLKT的积为循环依赖数据访问延迟Tdm,所有非循环依赖数据访问操作消耗的CPU_CLK_UNHALTED.CORE百分比与CLKT的积为非循环依赖数据访问延迟Tim的值。
一种面向非规则数据密集应用的群组式线程预取系统,包括预取率确定模块、群组式预取线程构建模块、预取同步机制选取模块和有效预取距离选取模块,预取率确定模块、有效预取距离选取模块分别与群组式预取线程构建模块相连接,群组式预取线程构建模块与预取同步机制选取模块相连接。
所述预取率确定模块利用VTUNE性能分析器分析程序源代码,找出频繁发生缓存失效行为的热点循环,并分析热点循环执行的访存计算延迟特征,获取计算延迟TC、循环依赖数据访问延迟Tdm和非循环依赖数据访问延迟Tim的值,从而确定预取率R;群组式预取线程构建模块:根据预取率R,利用切片技术基于预取率构建群组式预取线程;预取同步机制选取模块:在主线程热点循环入口处设置标志位flag为1,向预取线程发出信号,通知预取线程开始预取工作;在主线程热点循环出口处设置标志位flag为0,向预取线程发送暂停信号,通知预取线程暂停预取,等待下一次预取信号;有效预取距离选取模块基于热点循环访存计算延迟特征为群组式预取策略选取有效预取距离,控制预取请求的发出时机。
本发明的有益效果:本发明使用在线分析器获取非规则数据密集应用的执行行为特征;基于非规则数据密集应用的执行延迟特征确定合理的预取率,并利用切片技术基于预取率构建群组式预取线程;通过标志位向预取线程发出预取开始信号和预取停止信号。本发明基于片上多核处理器环境中面向非规则数据密集应用执行数据预取,能确保及时准确地发出预取请求,减少无用数据预取和线程之间的共享资源竞争,预取线程构建能量消耗较低,并具有较好的实用性和灵活性。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明的原理框图。
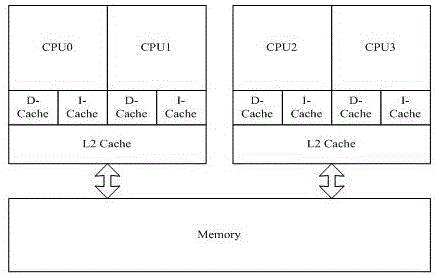
图2为本发明平台处理器的结构图。
图3为本发明测试程序MST热点循环执行的行为特征。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有付出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
一种面向非规则数据密集应用的群组式线程预取方法,采用在线剖析技术和多线程技术实现群组式预取,适应于非规则数据密集应用的特点。本发明在辅助线程构建前在线剖析非规则数据密集应用的访存和计算延迟的特征,且标识出循环依赖数据访问和非循环依赖数据访问,实现了基于访存延迟比例的群组式预取。
本发明是基于并行多线程理论提出的,其理论基础概述如下:
一. 基于片上多核处理器的多线程技术
片上多核处理器CMP(Chip Multi-Processor)最初是由斯坦福大学的研究人员在20世纪90年代提出的,其主要思想是利用丰富的晶体管资源在单个芯片上集成多个处理器核,通过多核并行执行的方式开发指令级和线程级的并行度,提高程序的性能。CMP挖掘了指令级和线程级的并行性,使得处理器性能显著提高。
基于CMP的辅助线程数据预取方法通过把主线程与辅助线程绑定到同一个处理器上的相邻CPU核上运行,使辅助线程提前把主线程所需数据预取到共享低级缓存中,隐藏主线程的防存延迟。由于同一个处理器的不同CPU核拥有各自的执行单元和L1 Cache,而辅助线程和主线程各自运行在独立的CPU核上,因此,辅助线程对主线程的负面影响很小。
对于片上多核处理器的多线程技术可以定义以下难解问题:
1)线程构建问题。在选择代码片断构建并行线程时都参照一些准则。
2)线程的触发和启动问题。线程构建后,还需要选择合适的触发点以便在适当的时机触发和启动线程进行执行。
3)线程间的同步机制问题。并行线程一旦被触发和启动,执行时必须保持同步。
二.非规则数据访存特征剖析
Intel VTune性能分析器是专门为Intel x86 和Intel x64系列处理器定制的软件性能在线分析器。Intel VTune性能分析器可以进行多方面的代码剖析,剖析结果可以显示如“访存储访问所消耗的时间”这样的细节数据,并且可以将剖析数据定位到特定的指令行上。
对于非规则数据访存特征剖析定义以下术语:
定义1. 循环依赖数据访问延迟Tdm是热点循环中循环依赖数据的平均访存延迟。
定义2. 非循环依赖数据访问延迟Tim是热点循环中非循环依赖数据的平均访存延迟。
定义3. 计算延迟TC是单次热点循环中的平均计算延迟。
定义4. 预取率R 是辅助线程访存操作占总访存操作的比率。
在线剖析技术先使用VTune性能分析器获取非规则数据密集应用的执行时特征,包括频繁发生共享缓存L2 Cache失效行为的各个热点循环所在的函数名称、各热点循环的CPU时钟消耗情况、共享缓存L2 Cache失效情况和访存情况,然后选择共享缓存L2 Cache失效情况严重的热点循环作为进一步分析的目标,再利用VTune性能分析器获取其热点循环的相对延迟信息,包括计算延迟TC、循环依赖数据访问延迟Tdm和非循环依赖数据访问延迟Tim。
三. 群组式预取线程构建
群组式预取线程的构建目标是辅助线程的预取操作能与主线程的访存操作或计算操作完全并行地执行、互不干扰,且辅助线程预取的数据都恰好被主线程需要,则主线程将获得最大的性能收益。理论上,当辅助线程的执行延迟占热点循环执行总延迟的一半时,辅助线程与主线程达到最大程度的并行执行,主线程的性能得到最大限度地提高。根据定义1和定义3,热点循环执行总延迟为(TC+Tdm+Tim),其中,计算操作的计算延迟TC由主线程执行。当辅助线程与主线程并行执行时,辅助线程的访存操作不仅可以与主线程的计算操作重叠,还可以与主线程的访存操作重叠。辅助线程与主线程并行执行可分两种情况:
1)当0≤TC /(Tdm+Tim)<1,即TC<(Tdm+Tim)时,辅助线程的访存操作一部分与主线程的计算操作重叠,另一部分与主线程的访存操作重叠。理想状态下,辅助线程与主线程的执行完全并行,其执行延迟各为热点循环总执行延迟的一半,即(TC+Tdm+Tim)/2。实际执行过程中,主线程的执行延迟为TC+(1-R)*Tim,相应地辅助线程的执行延迟为Tdm+R*Tim。因此,可得到如下等式:
TC+(1-R)*Tim= Tdm+ R *Tim = (TC+Tdm+Tim)/2 (1)
计算后可得预取率:
R=(TC+Tim -Tdm)/2 (2)
可以通过剖析程序热点循环得到循环依赖数据访问延迟Tdm、非循环依赖数据访问延迟Tim与计算延迟TC的值,从而确定合理的预取率R 的值。尽管等式(2)是基于理想情况下的预取率R 确定,但仍为我们合理地选择预取率R 的值提供了理论依据。理想情况下,具有相等工作量的辅助线程与主线程可以完全重叠执行,源程序热点循环的执行时间将减少至原来的一半;而实际应用中即使辅助线程与主线程的工作量等同,由于系统资源控制的复杂性,辅助线程与主线程也不可能完全重叠执行。
2)当TC /(Tdm+Tim)≥1时,程序热点循环的访存延迟占其总执行延迟的一小部分,通过线程级并行执行,其访存操作与计算操作能达到完全重叠。即使辅助线程选取应用程序热点循环中频繁发生缓存失效的所有取数指令作为预取对象,预取的时效性也能得到保证。因此预取率R =1,辅助线程的预取操作与主线程的计算操作并行执行,主线程的性能达到最优。
四. 线程同步机制的确立
在辅助线程数据预取中,通常采用线程间同步机制来控制辅助线程与主线程在执行过程中的一致性,保证辅助线程的有效性。辅助线程与主线程间的同步机制也会给主线程带来一些负面影响。一方面,如果同步的频率过低,辅助线程执行的指令区间离主线程正在执行的指令区间太远,不仅会造成大量无用的预取,还会引起缓存污染。另一方面,如果同步的频率过高,同步的开销总和超出了辅助线程数据预取的性能收益,那么,程序的实际执行性能将会下降。群组式预取方法中,主线程热点循环入口处设置标志位flag为1,向预取线程发出信号,通知预取线程开始预取工作;在主线程热点循环出口处设置标志位flag为0,向预取线程发送暂停信号,通知预取线程暂停预取,等待下一次预取信号。
一种面向非规则数据密集应用的群组式线程预取方法,采用在线剖析技术获取非规则数据密集应用的执行时特征,确定合理的预取率构建群组式预取线程实现有效数据预取,如图1所示,其实施步骤如下:包括非规则数据访存特征剖析、群组式预取线程构建及线程同步机制的确立;
所述非规则数据访存特征剖析包括:
A)使用VTUNE性能分析器获取非规则数据密集应用的执行行为特征。
图2显示的是Intel Core2 Quad Q6600处理器结构图。该CMP处理器芯片上共有4个CPU核,8个L1 Cache和2个L2 Cache。每个CPU核独享一个指令Cache(I-Cache)和一个数据Cache(D-Cache),两个CPU核共享一个数据和指令统一缓存L2 Cache。L2 Cache通过总线和主存储器相联。执行行为特征包括频繁发生共享缓存L2 Cache失效行为的各个热点循环所在的函数名称、各热点循环的CPU时钟消耗情况、共享缓存L2 Cache失效情况和预取平台访存情况。
B)获取热点循环相对延迟的计算延迟TC、循环依赖数据访问延迟Tdm和非循环依赖数据访问延迟Tim值。
数据预取具有一定的投机性,无用的数据预取将造成总线带宽的额外占用,因此,预取对象的选择影响预取性能。利用VTUNE性能分析器分析程序源代码,找出频繁发生缓存失效行为的热点循环,并分析热点循环执行的访存计算延迟特征,在此基础上确定预取率R。热点循环为原始程序中造成共享缓存L2 Cache失效的主要循环代码区域。
使用VTUNE性能分析器获得评估测试程序的热点循环相对延迟的循环依赖数据访问延迟Tdm、非循环依赖数据访问延迟Tim与计算延迟TC的值。现以基准测试程序MST为例说明Tdm、Tim和TC的获取过程,VTUNE性能分析器分析后的MST热点循环执行的行为特征,如图3所示。
首先,VTUNE性能分析器测试MST热点循环的执行行为,得到行为事件CPU_CLK_UNHALTED.CORE和MEM_LOAD_RETIRED.L2_MISS的值和其在MST热点循环中的分布情况。其中,事件CPU_CLK_UNHALTED.CORE的值为程序执行时非停机状态花费的机器周期CLKT,事件MEM_LOAD_RETIRED.L2_MISS的值为程序执行访存行为时共享缓存L2 Cache 缺失次数。
其次,分辨事件CPU_CLK_UNHALTED.CORE和事件MEM_LOAD_RETIRED.L2_MISS对应语句执行的是访存操作还是非访存操作,例如,语句“ent &&”是MEM_LOAD_RETIRED.L2_MISS事件高发语句,占整个测试程序的81.7%。很显然“ent &&”语句执行的是访存操作,而且该语句的CPU_CLK_UNHALTED.CORE占整个测试程序的74.52%。对于从语义上难以分辨其执行行为的语句,紧随其后的汇编代码可以帮助分辨它执行的是访存操作还是非访存操作。
接着,累加执行非访存操作语句的CPU_CLK_UNHALTED.CORE的百分比,得到所有非访存操作消耗的CPU_CLK_UNHALTED.CORE百分比,即得到计算延迟TC的值。计算延迟TC的值为所有非访存操作消耗的CPU_CLK_UNHALTED.CORE百分比与CLKT的乘积。
然后,VTUNE性能分析器识别热点循环中的循环依赖数据访问操作和非循环依赖数据访问操作。同上,分别累加循环依赖数据访问语句和非循环依赖数据访问语句的CPU_CLK_UNHALTED.CORE百分比,得到所有循环依赖数据访问操作消耗的CPU_CLK_UNHALTED.CORE百分比和所有非循环依赖数据访问操作消耗的CPU_CLK_UNHALTED.CORE百分比,分别求其与CLKT的积得到循环依赖数据访问延迟Tdm和非循环依赖数据访问延迟Tim的值。
所述群组式预取线程构建包括:
C) 判断计算延迟TC和循环依赖数据访问延迟与非循环依赖数据访问延迟之和(Tdm+Tim) 的关系;
D) 当TC<(Tdm+Tim)时,基于理想情况下确定合理的预取率R=(TC+Tim -Tdm)/2;当TC≥(Tdm+Tim)时,预取率R 值等于1;
E) 利用切片技术基于预取率R 构建群组式预取线程。
确定热点循环后,编译器还需要识别哪些指令必须在辅助线程中执行,这一过程称为代码切片。首先使用程序profile工具VTUNE性能分析器在运行时测试代码的长延迟的访存指令,并以profile文件的形式保存下来;其次,编译器根据profile文件信息和选定的循环区域将要预取的关键指令抽取出来(即根据预取率只选择部分循环依赖取数指令),并保留对循环结构有影响的代码,删除其它非关键的代码,完成切片形成辅助线程的代码块;最后,将切片后的代码移植到辅助线程中,在主线程中插入辅助线程触发指令,并在辅助线程和主线程中插入同步代码块,保证帮助线程正常而有效的执行。
所述线程同步机制的确立包括:
F) 在主线程热点循环入口处设置标志位flag为1,向预取线程发出信号,通知预取线程开始预取工作;在主线程热点循环出口处设置标志位flag为0,向预取线程发送暂停信号,通知预取线程暂停预取,等待下一次预取信号。
在构建群组式预取线程时,在原主线程的热点循环入口处设置标志位flag为1,程序执行到热点循环时自动触发辅助线程执行,在原主线程的热点循环的出口处设置标志位flag为0,程序执行到热点循环末尾时自动停止辅助线程执行。当flag为0时,辅助线程循环等待,直至flag=1开始执行辅助线程。
一种面向非规则数据密集应用的群组式线程预取系统,包括:预取率确定模块、群组式预取线程构建模块、预取同步机制选取模块和有效预取距离选取模块,预取率确定模块、有效预取距离选取模块分别与群组式预取线程构建模块相连接,群组式预取线程构建模块与预取同步机制选取模块相连接。预取率确定模块利用VTUNE性能分析器分析程序源代码,找出频繁发生缓存失效行为的热点循环,并分析热点循环执行的访存计算延迟特征,获取计算延迟TC、循环依赖数据访问延迟Tdm和非循环依赖数据访问延迟Tim的值,从而确定预取率R;群组式预取线程构建模块:根据预取率R ,利用切片技术基于预取率构建群组式预取线程;预取同步机制选取模块:在主线程热点循环入口处设置标志位flag为1,向预取线程发出信号,通知预取线程开始预取工作;在主线程热点循环出口处设置标志位flag为0,向预取线程发送暂停信号,通知预取线程暂停预取,等待下一次预取信号。有效预取距离选取模块:基于热点循环访存计算延迟特征为群组式预取策略选取有效预取距离,控制预取请求的发出时机。预取距离的取值决定着预取请求发出的时机。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!