一种基于残差子图像的深度学习超分辨率重建方法与流程
本发明涉及计算机图像处理领域与人工智能技术,尤其涉及一种基于残差子图像的深度学习超分辨率重建方法。
背景技术:
图像超分辨率是利用低分辨率的图像重建出高质量的高分辨率图像的过程,在视频压缩与传输,医学图像辅助诊断,安防监控以及卫星成像等领域有着广泛的应用前景。对于图像超分辨率有两个评价标准:(1)图像的重建效果,其目标是恢复图像的高频信息,提高图像的质量,尽可能地提升重建图像的视觉效果;(2)图像的重建效率,目标就是在保证重建效果的同时,尽可能地提高重建速度。目前主流的方法包括基于插值或者重构的传统方法和基于机器学习的新方法。基于插值或者重构的传统方法设定了固定的参数模型,由于重建速度快而被广泛采用,例如应用在美图秀秀或者Photoshop等商业软件中的超分辨率方法。然而利用这些技术重建的图像会产生锯齿、模糊或者振铃等视觉伪影,图像超分辨率重建的效果不佳。基于机器学习的方法由于能够自适应学习模型参数,具有很强的重建能力,逐渐成为国际上最前沿的图像超分辨率方法。其中基于稀疏模型的字典学习,是最早应用于图像超分辨率的一种机器学习方法,然而字典学习只有线性表示能力,其超分辨率重建效果有限。中国公开专利“一种基于残差的图像超分辨率重建方法”(公开号CN102722876A,公开日为2012.10.10)和专利“基于稀疏表示的图像超分辨率重建方法”(公开号CN102722876A,公开日为2013.10.23)采用了基于稀疏表示的字典学习的方法进行图像超分辨率重建。这种重建方法不仅受限于字典学习的线性表示能力,同时残差图像是基于传统插值方法计算出来的全局残差图像,算法本质上是在传统插值算法的基础上进一步利用字典学习的方法提升重建效果,算法的重建性能会受到传统插值方法的影响。
近年来,基于深度学习的技术得到迅速地发展,它通过利用卷积神经网络的超强非线性特征表示能力,能够很好地提高图像超分辨率的重建效果。经对对现有技术的文献检索发现,中国专利公开号CN105976318A,公开日为2016.09.28,专利名称“一种图像超分辨率重建方法”使用了深度学习的方法来进行超分辨率重建。然而此专利的图像超分辨重建效果一般,重建效率也可以进一步提高,其具体的不足之处是:(1)此专利利用双三次插值作为预处理,实际上是传统方法与机器学习方法的一种结合,重建效果会受到传统的插值方法的影响,例如产生模糊效应。(2)此专利只采用了3层的网络结构,其非线性的特征表示能力和图像重构能力有限。(3)此专利的训练数据是低分率图像和高分辨率图像,高分辨率图像的低频信息也会在网络的训练过程中得到重建,从而没有对图像中高频信息进行特异性重建,图像的超分辨率重建效果不佳。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供一种基于残差子图像的深度学习超分辨率重建方法super-resolution using sub-residual images(SRSRI)。
本发明采用的技术方案是:
一种基于残差子图像的深度学习超分辨率重建方法,其包括以下步骤:
1)训练深度神经网络模型:
1-1)将高分辨图像y分解成s2个子图像ysub;
1-2)计算s2个残差子图像rsub,并与对应的低分辨率图像x形成图像训练集;
1-3)通过图像训练集,采用基于卷积神经网络训练模型训练得到优化的网络模型参数w和b;
2)利用训练完的深度神经网络模型将低分辨率图像xtest重建成高分辨率图像ytest:
2-1)基于训练好的网络模型参数w和b,将低分辨率图像xtest输入卷积神经网络训练模型中,并计算获得对应的s2个残差子图像rtestsub;
2-2)利用残差子图像rtestsub,计算获得s2个子图像ytestsub,并变换各个子图像的空间位置,最终获得高分辨率图像ytest。
所述图像训练集包括低分辨率图像x和对应的残差子图像rsub;
进一步地,步骤1-1)中s是图像的超分辨率放大倍数,子图像按每隔s个像素点在高分辨率图像中进行抽样取值。
进一步地,步骤1-2)残差子图像的计算公式是:rsub=ysub-x,子图像个数为s2。
进一步地,步骤1-3)具体包括以下步骤:
步骤1-3-1)设定卷积神经网络模型的卷积层和激活函数均为L层,采用规整化线性单元函数作为激活函数,
步骤1-3-2)选用图像对(x,r)作为训练集,输入低分辨率图像x和残差子图像r,得到卷积神经网络的训练目标函数是:
其中,f(w,b,x)为神经网络模型的预测结果,w和b分别为神经网络中的卷积模板参数和偏置参数;
每一卷积层的输出可以表示为:
fk(x)=φk(Wk*fk-1(x)+bk),k∈[1,L] (2)
其中фk为激活层的函数,bk是网络模型当中第k层的偏置参数,wk是网络模型当中第k层的卷积模板参数,大小为nk-1*vk*vk*nk,其中nk-1为第k层输入的特征图的数目,nk为第k层输出层的特征图的数目,vk为第k层的卷积核的大小;
步骤1-3-3)采用随机梯度下降法求解神经网络模型的卷积模板参数w和偏置参数b,在每次迭代过程中,计算预测结果误差并反向传播到卷积神经网络模型,计算梯度并更新卷积神经网络模型的参数;
步骤1-3-4)基于卷积神经网络模型中各卷积层的模型参数生成低分辨率图像到高分辨率图像的映射关系并完成神经网络模型的训练。
进一步地,步骤1-3-2)中神经网络模型中每一卷积层包含了卷积运算和非线性激活函数运算。
进一步地,步骤1-3-3)中卷积模板参数w采用高斯分布初始化,偏置参数b初始化为0。
进一步地,步骤2-1)所述残差子图像rtestsub表示在高分辨率图像空间中各个不同方向的高频图像信息,具体包括图像边缘信息和纹理信息。
进一步地,步骤2-2)子图像ytestsub的计算过程为:
ytestsub=xtestsub+rtestsub (3)。
进一步地,步骤2-2)中获得子图像ytestsub后,可以按照步骤1-1)中取子图像的操作,反向把s2个子图像的各个像素还原到高分辨率图像空间相应位置并重建高清图像ytest。
本发明采用以上技术方案,具有如下优点:(1)本发明完全去除了双三次插值的预处理,形成低分辨率图像到高分辨率图像之间端到端的直接映射,从而不会受到传统插值算法的影响。(2)我们的发明中使用了11层的网络结构,使得神经网络结构的表示和重构能力极大地提升,从而能够更好的提高超分辨率重建效果。(3)利用低分辨率图像和残差子图像来训练神经网络。由于残差图像表示图像损失的信息,使得网络更集中地针对损失的高频信息来训练,从而增强了图像的超分辨率重建效果。同时,由于残差图像的稀疏属性,可以提高神经网络模型的训练速度。(4)此外,本发明的另外一个创新点是提出了基于残差子图像的方法,将图像超分辨的计算过程由高分辨空间转移到低分辨率空间进行,在提高超分辨率重建效果的同时,也极大地加快了超分辨率的重建速度。
附图说明
以下结合附图和具体实施方式对本发明做进一步详细说明;
图1为本发明的一种基于残差子图像的深度学习超分辨率重建方法的残差子图像计算过程;
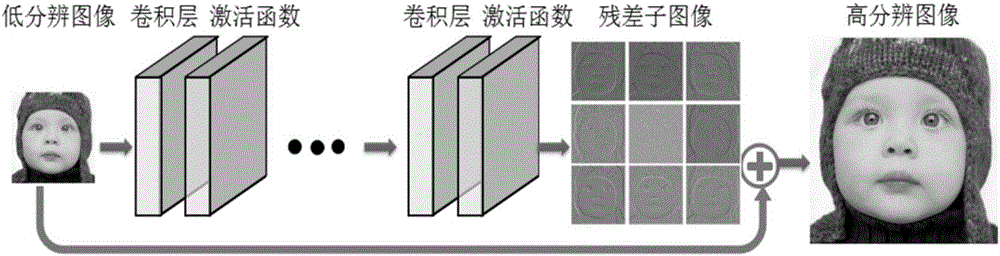
图2为本发明的一种基于残差子图像的深度学习超分辨率重建方法的原理图;
图3为本发明的一种基于残差子图像的深度学习超分辨率重建方法的流程图;
图4为多种算法比较时的输入的低分辨率图像;
图5为采用传统的双三次插值算法的最终效果;
图6为基于字典学习的Aplus算法的最终效果;
图7为基于深度学习的算法SRCNN的最终效果;
图8为本发明的一种基于残差子图像的深度学习超分辨率重建方法SRSRI的最终效果。
具体实施方式
如图1-8之一所示,本发明公开一种基于残差子图像的深度学习超分辨率重建方法,巧妙的结合了残差子图像和基于卷积神经网络的深度学习方法,不仅可以很好的重建高质量的图像或者视频,提供很好的用户观看体验,而且能够快速的重建出高分辨率图像。具体实施流程如图3所示,
其包括以下步骤:
1)训练深度神经网络模型:
1-1)如图1所示,将高分辨图像y分解成s2个子图像ysub;其中s是图像的超分辨率放大倍数。子图像是在高分辨率图像的行列中按每隔s个像素点进行取值。如果输入图像是RGB空间,需要先转换到YCbCr空间,算法只在Y通道进行训练,这是因为人眼对Y通道的变化很敏感,而对Cb和Cr通道的变化不太敏感。
1-2)计算s2个残差子图像rsub,并获取对应的低分辨率图像x形成图像训练集;其中残差子图像的计算公式是:rsub=ysub-x。残差子图像表示低分辨率图像与高分辨率图像中各个方向分量的差异,包含了各个方向所丢失的边缘和纹理等信息。这样神经网络可以针对低分辨率图像所丢失的高频信息来训练,移除了对图像中低频信息的冗余重建过程。
1-3)利用图像训练集,按照图2所示的卷积神经网络训练模型训练得到优化的网络模型参数w和b;
2)利用训练完的神经网络模型将低分辨率图像xtest重建成高分辨率图像ytest:
2-1)基于训练好的网络模型参数w和b,将低分辨率图像xtest输入卷积神经网络训练模型中,并计算获得对应的s2个残差子图像rtestsub;
2-2)利用残差子图像rtestsub,计算获得s2个子图像ytestsub,并变换各个子图像的空间位置,最终获得高分辨率图像ytest。
所述图像训练集包括低分辨率图像x和对应的残差子图像rsub;
进一步地,步骤1-1)中s是图像的超分辨率放大倍数,子图像按每隔s个像素点在高分辨率图像中进行抽样取值。
进一步地,步骤1-2)残差子图像的计算公式是:rsub=ysub-x,子图像个数为s2。
进一步地,步骤1-3)具体包括以下步骤:
步骤1-3-1)设定卷积神经网络模型的卷积层和激活函数均为L层,采用规整化线性单元函数作为激活函数,
步骤1-3-2)选用图像对(x,r)作为训练集,输入低分辨率图像x和残差子图像r,得到卷积神经网络的训练目标函数是:
其中,f(w,b,x)为神经网络模型的预测结果,w和b分别为神经网络中的卷积模板参数和偏置参数;
每一卷积层的输出可以表示为:
fk(x)=φk(Wk*fk-1(x)+bk),k∈[1,L] (2)
其中f0(x)=φk为激活层的函数,bk是网络模型当中第k层的偏置参数,wk是网络模型当中第k层的卷积模板参数,大小为nk-1*vk*vk*nk,其中nk-1为第k层输入的特征图的数目,nk为第k层输出层的特征图的数目,vk为第k层的卷积核的大小;
步骤1-3-3)采用随机梯度下降法求解神经网络模型的卷积模板参数w和偏置参数b,在每次迭代过程中,计算预测结果误差并反向传播到卷积神经网络模型,计算梯度并更新卷积神经网络模型的参数;具体的权重更新公式为:
公式中L为训练的损失误差。m为结合动量,λ为学习率。初始学习率设为0.01,并逐步减小到0.0001,同时采用梯度剪切方法,防止梯度在计算过程中过大。特征图的数目nk设置为64,卷积核的大小设置为3。
步骤1-3-4)基于卷积神经网络模型中各卷积层的模型参数生成低分辨率图像到高分辨率图像的映射关系并完成神经网络模型的训练。
进一步地,步骤1-3-2)中神经网络模型中每一卷积层包含了卷积运算和非线性激活函数运算。
进一步地,步骤1-3-3)中卷积模板参数w采用高斯分布初始化,偏置参数b初始化为0。
进一步地,步骤2-1)所述残差子图像rtestsub表示在高分辨率图像空间中各个不同方向的高频图像信息,具体包括图像边缘信息和纹理信息。
进一步地,步骤2-2)子图像ytestsub的计算过程为:
ytestsub=xtestsub+rtestsub (3)。
进一步地,步骤2-2)中获得子图像ytestsub后,可以按照步骤1-1)中取子图像的操作,反向把s2个子图像的各个像素还原到高分辨率图像空间相应位置并重建高清图像ytest。
为了验证算法的重建效果,在公共测试图像集Set5上测试,并与其它三种算法进行比较。图4-8为本发明与其它几种算法的超分辨率重建实例比较,图4是输入神经网络的低分辨率图像;图5是基于传统的双三次插值算法的高分辨率重建效果图;图6是基于字典学习的Aplus算法的高分辨率重建效果图;图7是基于深度学习技术的SRCNN算法的重建效果图;图8是本发明一种基于残差子图像的深度学习超分辨率重建方法的重建效果图。从图8中可以看到本发明的SRSRI算法重建的高分辨率图像包含了更加丰富的边缘信息和纹理信息,能让观众看到更加清晰的图像,从而获得更好的体验。同时,我们利用英伟达的Titan X的GPU并行处理性能,加速我们的超分辨率重建过程。以放大四倍超分辨为例,本发明所提出的算法在Set5图像集的平均处理时间为20.5ms,基本达到实时处理的要求,极大的提高了超分辨率的重建效率。
- 还没有人留言评论。精彩留言会获得点赞!