采用觅食机制的人工蜂群优化算法识别关键蛋白质的方法与流程
本发明属于生物信息领域,涉及一种动态蛋白质相互作用网络中关键蛋白质的识别方法,具体涉及采用觅食机制的人工蜂群优化算法识别关键蛋白质的方法。
背景技术:
关键蛋白质是生物体生存和繁殖所必须的蛋白质,关键蛋白质的缺失会导致有关蛋白质复合物功能丧失,并导致生物体无法生存。由于关键蛋白质在生命活动中扮演重要角色,因此对于关键蛋白质的预测与识别成为一项重要研究工作。在生物学上,关键蛋白质的识别主要是依靠生物实验方法,例如单基因挑出和条件性基因剔除等。通过这些实验技术得到的结果虽然是明确和有效的,但代价高,效率低,试用范围有限。因此,利用计算生物学的方法来预测关键蛋白质成为一个新的发展方向。
目前,通过计算方法实现关键蛋白质的识别主要基于两种措施,拓扑中心性方法和异类源融合方法。
2001年提出的“中心性-致死性”法则指出蛋白质的关键性与蛋白质相互作用网络的拓扑结构紧密相关,具体表现为拥有较多相邻结点的蛋白质的缺失更易于影响整个网络的拓扑结构,进而产生致死的效应。也就是说,蛋白质网络中度越高的蛋白质结点越倾向于表现关键性。该理论成为了基于网络拓扑结构的关键蛋白质识别的基础。此后,许多研究人员提出了基于拓扑中心性的关键蛋白质识别方法,其中包括度中心性(Degree Centrality,DC),介数中心性(Betweenness Centrality,BC),紧密度中心性(Closeness Centrality,CC),特征向量中心性(Eigenvector Centrality,EC),信息中心性(Information Centrality,IC),子图中心性(Subgraph Centrality,SC)。通过计算蛋白质相互作用网络中所有蛋白质结点在网络中某个中心性的值的大小来判断其为关键蛋白质的可能性。这些中心性方法高度依赖蛋白质相互作用网络的精确性。但蛋白质相互作用网络是通过高通量生物实验获得,包含了很多假阳性,很大地影响了关键蛋白质识别的准确率。
针对中心性拓扑特征识别关键蛋白质的缺点,研究人员提出一些新的识别方法进一步提高关键蛋白质的识别准确率。如PeC关键蛋白质识别方法将蛋白质相互作用网络与基因表达谱整合起来,ION关键蛋白质识别方法主要结合了蛋白质的同源特性和蛋白质相互作用网络。基于边的聚集系数的关键蛋白质识别方法。通过考虑蛋白质本身及其周围邻居的聚集状况来识别蛋白质。此外,还有一些通过融合其他信息进行关键蛋白质识别的方法,如基于结构域的关键蛋白质识别方法,基于基因共表达的关键蛋白质识别方法等。
近年来,有研究指出生物网络存在显著的模块化特性,在蛋白质网络中表现为存在大量的蛋白质复合物功能模块。Hart等人提出关键性是蛋白质复合物的一种属性,并通过实验数据显示出关键蛋白质往往大量集中在某些复合物中。随后Zotenko等人提出了关键复合物模块的概念,并指出具有相同功能或相近生物功能的高度联通的蛋白质网络功能模块中具有大量关键蛋白质。因此许多研究者提出基于蛋白质复合物及功能模块的关键蛋白质识别方法。
尽管关键蛋白质的识别问题越来越引起人们的关注,但目前结合网络信息的识别方法的准确率依旧较低,而且大多数方法都是孤立或者零碎地使用少数参数或特征分析关键蛋白质,对于结点缺乏从整体和全局上的把握。另外,当前的关键蛋白识别方法大多基于静态的蛋白质相互作用网络识别的,而生物体中蛋白质的活性是随着生物体的生命周期而变化的,因此构建一个更能真实模仿生物体的动态生命的蛋白质相互作用网络能帮助进一步提升关键蛋白质识别准确率。
综合上述关键蛋白质识别方法的缺陷,主要有没考虑蛋白质相互作用网络的动态性,只考虑局部特征而忽视了网络的全局性以及蛋白质相互作用网络数据的假阳性,关键蛋白质识别准确率低。
技术实现要素:
本发明的目的在于克服现有技术的缺点与不足,提供一种采用觅食机制的人工蜂群优化算法识别关键蛋白质的方法,能真实地模拟蛋白质相互作用网络的动态性,关键蛋白质识别准确度高。
为达到上述目的,本发明采用如下技术方案:
采用觅食机制的人工蜂群优化算法识别关键蛋白质的方法,包括以下步骤:
(1)将蛋白质相互作用网络转化为无向图
将蛋白质相互作用网络转化成一个无向图G=(V,E),其中,V={vi,i=1,2,…,n}为结点vi的集合,E为边e的集合,结点vi表示蛋白质,边e表示蛋白质之间的相互作用;
(2)对蛋白质相互作用网络边和结点的预处理
对结点vi预处理:按式(1)计算结点vi的介数中心性:
式中ρ(s,v,t)表示蛋白质相互作用网络中结点s与结点t之间经过结点v的最短路径的条数,ρ(s,t)表示蛋白质相互作用网络中结点s与结点t之间的最短路径的条数;
按式(2)计算边的聚集系数:
式中,Z(vi,vj)表示包含边(vi,vj)的三角形个数,di,dj分别是点vi,vj的度;
按式(3)计算边的皮尔森相关系数:
式中,xi,yi表示蛋白质vx,vy在时间点t时的基因表达值,μ(x),μ(y)是蛋白质vx,vy的平均基因表达值,T为时间点的最大值;
(3)构建动态蛋白质相互作用网络
在时间点t时,蛋白质vi的基因表达值GEit若大于基因表达阈值AT(i),则被认为蛋白质vi在时间点t具有活性;否则认为该结点在时间点t不具有活性;将所有时间点的活性蛋白质组合在一起,对应到原静态蛋白质相互作用网络中形成一个新的蛋白质相互作用网络,即动态蛋白质网络;
GEit为蛋白质vi在时间点t处的基因表达值;
基因表达阈值AT(i)由式(4)得到:
AT(i)=μ(i)+3σ(i)(1-F(i)) 式(4)
式中μ(i)是蛋白质vi平均基因表达值,σ(i)是基因表达值的标准差,F(i)=1/(1+σ2(i))是权函数;
(4)选取已知关键蛋白质作为蜜源
令N为蜜源中包含的已知关键蛋白质的数量,在目前已知的关键蛋白质中随机选取N个关键蛋白质作为先验知识的蜜源;Ep_set表示蜜源包含的蛋白质的集合;iter,maxiter分别表示当前迭代次数和最大迭代次数,iter=1,matxiter∈[100,800];
(5)采蜜蜂搜索蜜源邻域
蜜源的邻域即与蜜源蛋白质有相互作用的蛋白质结点集合niber_set1,每一个邻域结点看作一只采蜜蜂;按照score1(i)=relevant(vi,,Ep_set)确定采蜜蜂当前所在位置的蜜源收益度及该邻域结点成为新蜜源的可能性,式中score1(i)为采蜜蜂当前位置的蜜源收益度,vi是采蜜蜂所代表的蛋白质结点,relevant表示蛋白质结点vi与当前蜜源集合Ep_set之间的关联度;
(6)跟随蜂搜索采蜜蜂邻域
设采蜜蜂vi的邻域即与采蜜蜂所代表的蛋白质有相互作用且不在当前蜜源集合Ep_set内的蛋白质结点集合为niber_set2;跟随蜂接收采蜜蜂的信息并且对采蜜蜂的邻域进行搜索,即跟随蜂根据公式score2(i)=fitness(vi,,niber_set2,Ep_set)确定当前位置成为新蜜源的可能性,式中vi是采蜜蜂所代表的蛋白质结点,niber_set2表示采蜜蜂的邻域蛋白质结点,fitness表示当前位置成为蜜源的适应度;
(7)更新蜜源
对蛋白质结点集合niber_set1中的结点按照其score2得分进行降序排序,将score2的值最高的结点设为最优蜜源位置g_best,将score2第二高的结点作为次优候选蜜源s_best;若score2(g_best)-score2(s_best)>阈值thd,则将g_best作为新蜜源并入到集合Ep_set中,并转向步骤(5);否则转向步骤(8);iter迭代加1;
(8)侦查蜂全局搜索新蜜源
侦查蜂对蛋白质相互作用网络中的除蜜源外的其它蛋白质进行介数中心性计算;然后根据介数中心性的值BC对所有结点进行降序排序,选出介数中心性值最大的结点作为最优蜜源位置g_best;
(9)更新蜜源
将最优蜜源位置g_best作为新蜜源并入到集合Ep_set中;
(10)产生关键蛋白质
若iter的值小于等于maxiter,转向步骤(5);否则,将集合Ep_set中的蛋白质作为关键蛋白质输出。
进一步,步骤(5)中蛋白质结点vi与当前蜜源集合Ep_set之间的关联度relevant由式(5)得到:
式中vj是蜜源集合EP_set里面的蛋白质结点,ECC是结点vi与结点vj之间的边的聚集系数由公式(2)得到,PCC是结点vi与结点vj之间的边的皮尔森聚集系数由公式(3)得到。
进一步,步骤(6)中当前位置成为蜜源的适应度fitness由式(6)得到:
式中,niber_set2表示采蜜蜂vi的邻域蛋白质结点集合,Ep_set表示当前蜜源集合。
本发明与现有的方法相比,具有以下优点:
1、本发明基于部分已知关键蛋白质先验知识,通过采蜜蜂和跟随蜂对当前蜜源关键蛋白质的邻居结点以及邻居结点的邻居结点进行搜索来完成关键蛋白质的局部预测,这种二级搜索不仅考虑到蜜源的局部结点特性,还进一步考虑到了蜜源的邻居结点的邻居的局部特性,能够比当前的一级局部搜索蛋白质复合物识别方法更好地体现出关键蛋白质在蛋白质相互作用网络中的特性。
2、本发明中当采蜜蜂与跟随蜂在局部探索不到最优解关键蛋白质时,使用侦查蜂对全局进行搜索来确定最优解,这样在预测关键蛋白质的过程中不仅考虑到关键蛋白质的局部特性,还综合考虑到了关键蛋白质在网络中的全局特性,解决了当前关键蛋白质预测不能总体考虑网络全局性的缺点。
3、本发明模拟人工蜂群的觅食过程来识别关键蛋白质,综合考虑了蛋白质相互作用网络的拓扑特性和动态性,蛋白质的基因表达值,先验知识,并加入人工蜂群的觅食优化机理,多方面特征的使用使得采用本发明识别出来的关键蛋白质的准确度要比目前采用其他关键蛋白质识别方法识别的准确度高。
4、采用本发明的结果能够有效地识别蛋白质相互作用网络里的关键蛋白质,为研究人员探讨重大疾病的机理、疾病治疗、疾病预防和新药开发提供了理论基础,并能帮助我们理解生命体维持生命活动所需要的基本需求。本发明识别的关键蛋白质能够帮助研究人员从蛋白质组和基因组层次上为生物学和医药学等领域提供重要信息,其研究不仅有助于了解细胞的生长调节过程,而且对于基因疾病的发现及药物靶标的设计有着重要意义。
【附图说明】
图1是本发明实施例1的工艺流程图
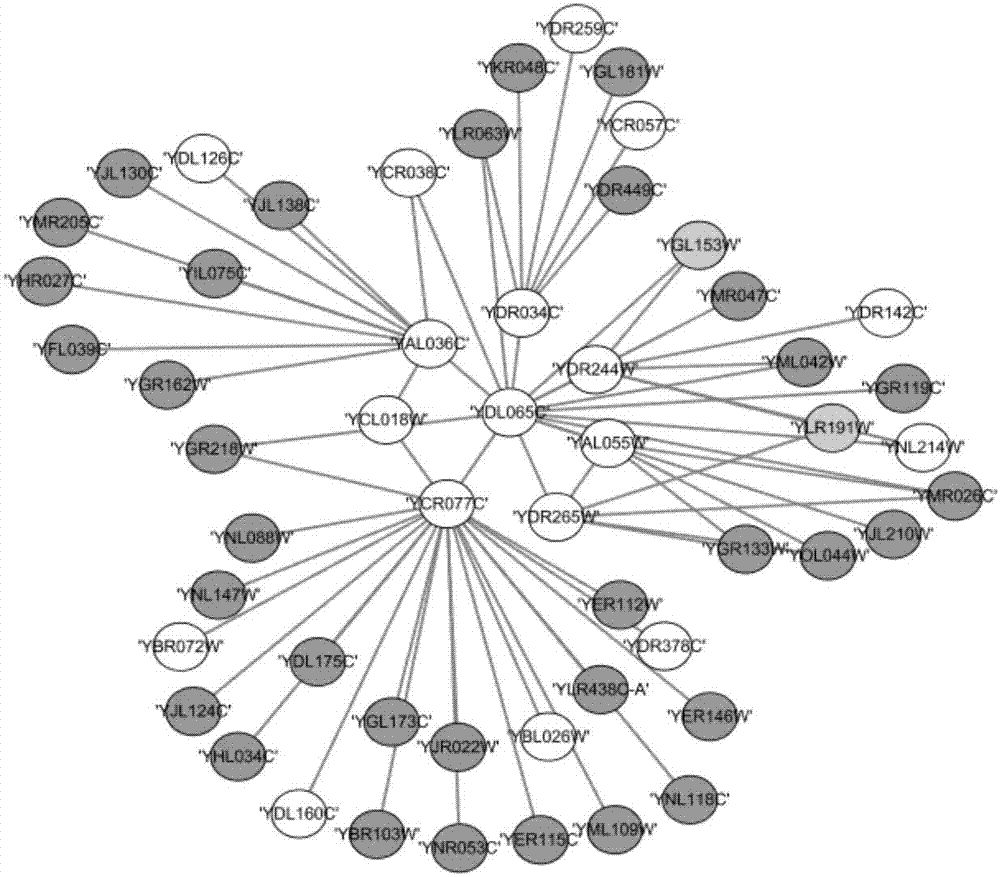
图2是采用实施例1得出的关键蛋白质在整个蛋白质相互作用网络中的部分示意图
图3是图2对应的标准库中关键蛋白质情况
【具体实施方式】
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,本发明采用觅食机制的人工蜂群优化算法识别关键蛋白质的方法,包括以下步骤:
(1)将蛋白质相互作用网络转化为无向图
将蛋白质相互作用网络转化成一个无向图G=(V,E),其中,V={vi,i=1,2,…,n}为结点vi的集合,E为边e的集合,结点vi表示蛋白质,边e表示蛋白质之间的相互作用;
(2)对蛋白质相互作用网络边和结点的预处理
对结点vi预处理:按式(1)计算结点vi的介数中心性:
式中ρ(s,v,t)表示蛋白质相互作用网络中结点s与结点t之间经过结点v的最短路径的条数,ρ(s,t)表示蛋白质相互作用网络中结点s与结点t之间的最短路径的条数;
按式(2)计算边的聚集系数:
式中,Z(vi,vj)表示包含边(vi,vj)的三角形个数,di,dj分别是点vi,vj的度;
按式(3)计算边的皮尔森相关系数:
式中,xi,yi表示蛋白质vx,vy在时间点t时的基因表达值,μ(x),μ(y)是蛋白质vx,vy的平均基因表达值,T为时间点的最大值;
(3)构建动态蛋白质相互作用网络
在时间点t时,蛋白质vi的基因表达值GEit若大于基因表达阈值AT(i),则被认为蛋白质vi在时间点t具有活性;否则认为该结点在时间点t不具有活性;将所有时间点的活性蛋白质组合在一起,对应到原静态蛋白质相互作用网络中形成一个新的蛋白质相互作用网络,即动态蛋白质网络;
GEit为蛋白质vi在时间点t处的基因表达值;
基因表达阈值AT(i)由式(4)得到:
AT(i)=μ(i)+3σ(i)(1-F(i)) 式(4)
式中μ(i)是蛋白质vi平均基因表达值,σ(i)是基因表达值的标准差,F(i)=1/(1+σ2(i))是权函数;
(4)选取已知关键蛋白质作为蜜源
令N为蜜源中包含的已知关键蛋白质的数量,在目前已知的关键蛋白质中随机选取N个关键蛋白质作为先验知识的蜜源;Ep_set表示蜜源包含的蛋白质的集合;iter,maxiter分别表示当前迭代次数和最大迭代次数,iter=1,matxiter∈[100,800];
(5)采蜜蜂搜索蜜源邻域
蜜源的邻域即与蜜源蛋白质有相互作用的蛋白质结点集合niber_set1,每一个邻域结点看作一只采蜜蜂;按照score1(i)=relevant(vi,,Ep_set)确定采蜜蜂当前所在位置的蜜源收益度及该邻域结点成为新蜜源的可能性,式中score1(i)为采蜜蜂当前位置的蜜源收益度,vi是采蜜蜂所代表的蛋白质结点,relevant表示蛋白质结点vi与当前蜜源集合Ep_set之间的关联度;
(6)跟随蜂搜索采蜜蜂邻域
设采蜜蜂vi的邻域即与采蜜蜂所代表的蛋白质有相互作用且不在当前蜜源集合Ep_set内的蛋白质结点集合为niber_set2;跟随蜂接收采蜜蜂的信息并且对采蜜蜂的邻域进行搜索,即跟随蜂根据公式score2(i)=fitness(vi,,niber_set2,Ep_set)确定当前位置成为新蜜源的可能性,式中vi是采蜜蜂所代表的蛋白质结点,niber_set2表示采蜜蜂的邻域蛋白质结点,fitness表示当前位置成为蜜源的适应度;
(7)更新蜜源
对蛋白质结点集合niber_set1中的结点按照其score2得分进行降序排序,将score2的值最高的结点设为最优蜜源位置g_best,将score2第二高的结点作为次优候选蜜源s_best;若score2(g_best)-score2(s_best)>阈值thd,则将g_best作为新蜜源并入到集合Ep_set中,并转向步骤(5);否则转向步骤(8);iter迭代加1;
(8)侦查蜂全局搜索新蜜源
侦查蜂对蛋白质相互作用网络中的除蜜源外的其它蛋白质进行介数中心性计算;然后根据介数中心性的值BC对所有结点进行降序排序,选出介数中心性值最大的结点作为最优蜜源位置g_best;
(9)更新蜜源
将最优蜜源位置g_best作为新蜜源并入到集合Ep_set中;
(10)产生关键蛋白质
若iter的值小于等于maxiter,转向步骤(5);否则,将集合Ep_set中的蛋白质作为关键蛋白质输出。
本发明的步骤(5)中蛋白质结点vi与当前蜜源集合Ep_set之间的关联度relevant由式(5)得到:
式中vj是蜜源集合EP_set里面的蛋白质结点,ECC是结点vi与结点vj之间的边的聚集系数由公式(2)得到,PCC是结点vi与结点vj之间的边的皮尔森聚集系数由公式(3)得到;
本发明的步骤(8)中当前位置成为蜜源的适应度fitness由式(6)得到:
式中,niber_set2表示采蜜蜂vi的邻域蛋白质结点,Ep_set表示当前蜜源。
以下通过具体实施例对本发明进一步详细说明:
实施例1
以蛋白质网络为例一种采用觅食机制的人工蜂群优化算法识别关键蛋白质的方法的步骤如下:
本实施例以采自DIP数据库的酵母数据集(DIP 20140427版)作为仿真数据集,DIP数据包含了4995个蛋白质和21554个相互作用关系。基因表达数据集采自GEO数据库中的酵母新陈代谢表达数据集GSE3431,其中包括6777个基因,3个周期共36个时间点的基因值,覆盖了DIP中的95%的蛋白质。关键蛋白质数据通过整合MIPS、SGD、DEG和SGDP四个数据库中的数据得到,共包含了1167个关键蛋白质。实验平台为Windows 7操作系统,Intel酷睿2双核3.1GHz处理器,4GB物理内存,用Matlab R2010b软件实现本发明的方法。
1、将蛋白质相互作用网络转化为无向图
将包含4995个蛋白质和21554个相互作用关系的蛋白质相互作用网络转化成一个无向图G=(V,E),其中,V={vi,i=1,2,…,4995}为结点vi的集合,E为21554个边e的集合,结点vi表示蛋白质,边e表示蛋白质之间的相互作用。
2、对蛋白质相互作用网络边和结点的预处理
对结点vi预处理:i=1,2,…,4995,每给定一个确定的i,可计算出结点i的介数中心性,按式(1)计算结点vi的介数中心性:
式中ρ(s,v,t)表示蛋白质相互作用网络中结点s与结点t之间经过结点v的最短路径的条数,ρ(s,t)表示蛋白质相互作用网络中结点s与结点t之间的最短路径的条数;按式(2)计算边的聚集系数:
式中,Z(vi,vj)表示包含边(vi,vj)的三角形个数,di,dj分别是点vi,vj的度;按式(3)计算边的皮尔森相关系数:
式中,xi,yi表示蛋白质vx,vy在时间点t时的基因表达值,μ(x),μ(y)是蛋白质vx,vy的平均基因表达值,T为时间点的最大值。
3、构建动态蛋白质相互作用网络
在时间点t时,蛋白质vi的基因表达值GEit若大于基因表达阈值AT(i),则被认为蛋白质vi在时间点t具有活性;否则认为该结点在时间点t不具有活性;基因表达阈值AT(i)由式(4)得到:
AT(i)=μ(i)+3σ(i)(1-F(i)) 式(4)
式中μ(i)是蛋白质vi基因表达值,σ(i)是基因表达值的标准差,F(i)=1/(1+σ2(i))是权函数。通过上述处理,可以得到每个蛋白质结点在每个时间点是否为活性。将所有时间点的活性蛋白质组合在一起,对应到原静态蛋白质相互作用网络中,删除在任何一个时间点都没活性的蛋白质结点以及与之相连接的边,形成一个新的具有3172个蛋白质结点和10234条边的蛋白质相互作用网络,即动态蛋白质网络。
4、选取已知关键蛋白质作为蜜源
令N为蜜源中包含的已知关键蛋白质的数量,在目前已知的1167个关键蛋白质中随机选取N=100个关键蛋白质作为先验知识的蜜源;Ep_set表示蜜源包含的蛋白质的集合,即随机从已知的1167个关键蛋白质结点中选取的100个蛋白质结点;iter,maxiter分别表示当前迭代次数和最大迭代次数,iter=1,matxiter∈[100,1200]。
5、采蜜蜂搜索蜜源邻域
蜜源的邻域即与蜜源蛋白质有相互作用的蛋白质结点集合niber_set1,每一个邻域节点看作一只采蜜蜂;按照score1(i)=relevant(vi,,Ep_set)确定采蜜蜂当前所在位置的蜜源收益度及该邻域结点成为新蜜源的可能性,式中score1(i)为采蜜蜂当前位置的蜜源收益度,vi是采蜜蜂所代表的蛋白质结点,relevant表示蛋白质结点vi与当前蜜源集合Ep_set之间的关联度,关联度由式(5)得到:
式中vj是蜜源集合EP_set里面的蛋白质结点,ECC是结点vi与结点vj之间的边的聚集系数由公式(2)得到,PCC是结点vi与结点vj之间的边的皮尔森相关系数由公式(3)得到。
6、跟随蜂搜索采蜜蜂邻域
设采蜜蜂vi的邻域即与采蜜蜂所代表的蛋白质有相互作用且不在当前蜜源集合Ep_set内的蛋白质结点集合为niber_set2;跟随蜂接收采蜜蜂的信息并且对采蜜蜂的邻域进行搜索,即跟随蜂根据公式score2(i)=fitness(vi,,niber_set2,Ep_set)确定当前位置成为新蜜源的可能性,式中vi是采蜜蜂所代表的蛋白质结点,niber_set2表示采蜜蜂的邻域蛋白质结点,fitness表示当前位置成为蜜源的适应度,由式(6)得到:
式中,niber_set2表示采蜜蜂vi的邻域蛋白质结点,Ep_set表示当前蜜源。
7、更新蜜源
对集合niber_set1中的结点按照其score2得分进行降序排序,将score2的值最高的结点设为最优蜜源位置g_best,将score2第二高的结点作为次优候选蜜源s_best;若score2(g_best)-score2(s_best)>阈值thd,则将g_best作为新蜜源并入到集合Ep_set中,并转向步骤(5);否则转向步骤(8);iter迭代加1。
8、侦查蜂全局搜索新蜜源
侦查蜂对蛋白质相互作用网络中的除蜜源外的其它蛋白质进行介数中心性计算;然后根据由公式(1)得到的介数中心性的值BC对所有结点进行一个降序排序,选出介数中心性值最大的结点作为最优蜜源位置g_best;
9、更新蜜源
将g_best作为新蜜源并入到集合Ep_set中;
10、产生关键蛋白质
若iter的值小于等于maxiter,转向步骤(5);否则,将集合Ep_set中的蛋白质作为关键蛋白质输出。
为了验证本发明的有益效果,发明人采用本发明实施例1人工蜂群优化算法识别关键蛋白质的方法对DIP数据库中的蛋白质网络进行关键蛋白质的识别,对识别的关键蛋白质的前600个关键蛋白质进行分析,结果见表1图2图3,表1显示了与当前其他识别关键蛋白质的方法识别出来的结果进行对比准确率的比较。在图2中显示了本发明识别的部分关键蛋白质在网络中的分布情况,图3显示了图2的对应标准库部分。
表1本发明与其他方法识别的关键蛋白质在准确率上的比较
表2显示了本发明识别出的结果中的前600个关键蛋白质与标准库中关键蛋白质作比较的准确率,以及与当前其他识别关键蛋白质方法识别结果的比较。与传统的6个中心性方法比较时显示本发明识别的前600个关键蛋白质中准确的概率都比六个中心性方法要好,与当前较新的LAC及NC方法相比较时,本发明识别出的结果的前400个关键蛋白质的准确率要远远比当前的新方法的结果准确率高。由表2看出,本发明能有效地识别关键蛋白质,特别是在识别的结果的前部分,有着很高的准确率。图2显示了本发明识别出的部分关键蛋白质在蛋白质相互作用网络中的位置。图2中不带背景颜色的是本发明正确识别出来的关键蛋白质,带深色背景的是非关键蛋白质,带浅色的是错误识别出来的关键蛋白质。图3是图2对应的标准库中的关键蛋白质情况。通过图2和图3的对比可以发现,本发明识别出的错误的蛋白质有“YGL163W”“YLR191W”,漏识别的关键蛋白质有“YBR103W”。若以中心部分为先验知识关键蛋白质,则本发明方法能正确识别出该先验知识周围的大部分关键蛋白质。
以上所述是本发明的优选实施方式,通过上述说明内容,本技术领域的相关工作人员可以在不偏离本发明技术原理的前提下,进行多样的改进和替换,这些改进和替换也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!