一种基于Bagging和离群点的分类结果置信度的度量方法与流程
本发明属于分类结果置信度度量技术领域,特别涉及一种基于Bagging和离群点的分类结果置信度的度量方法。
背景技术:
通过待度量数据来提高模型的准确性是在线学习中重要的部分,而如何保持学习数据的准确性变得尤为重要。分类结果置信度度量的方法是对每次分类后用于衡量分类的结果可信或不可信的方法,这对保持训练集和模型再训练有很重要的意义。传统的对Logistic回归、SVM和朴素贝叶斯等模型分类结果不进行置信度度量,模型再学习时无法避免学习不可信的分类结果对模型的影响。
严云洋和朱全银等人已有的研究基础包括:严云洋,吴茜茵,杜静,周静波,刘以安.基于色彩和闪频特征的视频火焰检测.计算机科学与探索,2014,08(10):1271-1279;S Gao,J Yang,Y Yan.A novel multiphase active contour model for inhomogeneous image segmentation.Multimedia Tools and Applications,2014,72(3):2321-2337;S Gao,J Yang,Y Yan.A local modified chan–vese model for segmenting inhomogeneous multiphase images.International Journal of Imaging Systems and Technology,2012,22(2):103-113;刘金岭,严云洋.基于上下文的短信文本分类方法.计算机工程,2011,37(10):41-43;严云洋,高尚兵,郭志波,盛明超.基于视频图像的火灾自动检测.计算机应用研究,2008,25(4):1075-1078Y Yan,Z Guo,JYang.Fast Feature Value Searching for Face Detection.Computer and Information Science,2008,1(2):120-128;朱全银,潘禄,刘文儒,等.Web科技新闻分类抽取算法[J].淮阴工学院学报,2015,24(5):18-24;李翔,朱全银.联合聚类和评分矩阵共享的协同过滤推荐[J].计算机科学与探索,2014,8(6):751-759;Quanyin Zhu,Sunqun Cao.A Novel Classifier-independent Feature Selection Algorithm for Imbalanced Datasets.2009,p:77-82;Quanyin Zhu,Yunyang Yan,Jin Ding,Jin Qian.The Case Study for Price Extracting of Mobile Phone Sell Online.2011,p:282-285;Quanyin Zhu,Suqun Cao,Pei Zhou,Yunyang Yan,Hong Zhou.Integrated Price Forecast based on Dichotomy Backfilling and Disturbance Factor Algorithm.International Review on Computers and Software,2011,Vol.6(6):1089-1093;朱全银等人申请、公开与授权的相关专利:朱全银,胡蓉静,何苏群,周培等.一种基于线性插补与自适应滑动窗口的商品价格分类方法.中国专利:ZL 201110423015.5,2015.07.01;朱全银,曹苏群,严云洋,胡蓉静等,一种基于二分数据修补与扰乱因子的商品价格分类方法.中国专利:ZL 2011 1 0422274.6,2013.01.02;朱全银,尹永华,严云洋,曹苏群等,一种基于神经网络的多品种商品价格分类的数据预处理方法.中国专利:ZL 2012 1 0325368.6;李翔,朱全银,胡荣林,周泓.一种基于谱聚类的冷链物流配载智能推荐方法.中国专利公开号:CN105654267A,2016.06.08;曹苏群,朱全银,左晓明,高尚兵等人,一种用于模式分类的特征选择方法.中国专利公开号:CN 103425994 A,2013.12.04;朱全银,严云洋,李翔,张永军等人,一种用于文本分类和图像深度挖掘的科技情报获取与推送方法.中国专利公开号:CN 104035997 A,2014.09.10;朱全银,辛诚,李翔,许康等人,一种基于K means和LDA双向验证的网络行为习惯聚类方法.中国专利公开号:CN 106202480 A,2016.12.07。
Bagging(装袋法):
Bagging是一种用来提高学习算法准确度的方法,这种方法通过构造一个分类函数系列,然后以一定的方式将它们组合成一个分类函数。Bagging技术的主要思想是采用重采样技术,从原始数据集中分别独立随机地选取数据,并且将此过程独立进行多次,直到产生很多个独立的数据集。给定一个弱学习算法,可以通过该弱学习算法对产生的多个训练样本集进行学习,得出分类函数序列,将结果进行投票,得票最多的作为最后的结果。
离群点:
离群点检测是数据挖掘中的一个分支,它的任务是识别其数据特征显著不同于其他数据对象的观测值。离群点检测在数据挖掘中非常重要,因为如果异常是由固有数据的变异造成的,那么对它们进行分析可以发现蕴藏在其中更深层次的、潜在的、有价值的信息。因此,离群点检测是一个非常有意义的研究方向。
Logistic回归:
Logistic回归又称logistic回归分析,是一种广义的线性回归分析模型,与线性回归不同,Logistic回归是一种非线性模型,普遍采用的参数估计方法是最大似然估计法。常用于数据挖掘,疾病自动诊断,经济分类等领域。Logistic回归方法能对分类因变量和分类自变量或连续自变量,或混合变量进行回归建模,有一整套成熟的对回归模型和回归参数进行检验的标准,以事件发生概率的形式提供结果。
支持向量机:
支持向量机是Vapnik等人在多年研究统计学习理论基础上对线性分类器提出了另一种设计最佳准则。其原理也从线性可分说起,然后扩展到线性不可分的情况。甚至扩展到使用非线性函数中去,这种分类器被称为支持向量机(Support Vector Machine,简称SVM)。
朴素贝叶斯分类器:
朴素贝叶斯分类器是一种应用基于独立假设的贝叶斯定理的简单概率分类器,更精确的描述这种潜在的概率模型为独立特征模型,贝叶斯分类的基础是概率推理,就是在各种条件的存在不确定,仅知其出现概率的情况下,如何完成推理和决策任务,概率推理是与确定性推理相对应的,而朴素贝叶斯分类器是基于独立假设的,即假设样本每个特征与其他特征都不相关。
欧式距离:
欧几里得度量也称欧氏距离,是一个通常采用的距离定义,指在m维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。在二维和三维空间中的欧氏距离就是两点之间的实际距离。
Logistic回归、支持向量机和朴素贝叶斯在分类时对待置信度度量的数据和分类结果直接加入训练集中,该方法无法避免将不可信的度量数据和分类结果加入到可信数据集中,这使得模型的准确度和稳定性降低。为了能更好的利用以上算法,避免分类数据加入可信数据集时对模型的影响,因此需要找到一种能够对分类结果进行置信度度量的方法,使Logistic回归、支持向量机和朴素贝叶斯等模型避免学习不可信的分类结果对分类模型的影响。
技术实现要素:
发明目的:针对现有技术中存在的问题,本发明提供一种将Bagging和离群点分析结合,对Logistic回归、支持向量机和朴素贝叶斯等模型的分类结果进行置信度度量,进而避免Logistic回归、SVM和朴素贝叶斯等模型在扩充训练数据时因采用了不可信的分类数据对训练模型影响,本发明提出了一种基于Bagging和离群点的分类结果置信度的度量方法。
技术方案:为解决上述技术问题,本发明提供的一种基于Bagging和离群点的分类结果置信度的度量方法,包括如下步骤:
步骤一:对已有可信数据集采用Bagging集成学习方法,即采用Logistic回归、支持向量机和朴素贝叶斯中一个作为基分类器,得到基分类器的分类模型集;
步骤二:通过步骤一得出的基分类器的分类模型集,对待度量置信度数据进行分类,并计算在不同分类中的分类概率,得到待度量置信度数据的分类结果集和待度量置信度数据的分类概率集,再对分类结果集进行统计,得到待度量置信度数据的分类结果;
步骤三:采用离群点分析方法,对待度量置信度数据的分类结果进行置信度度量,得到待度量置信度数据中的可信数据和不可信数据,并将待度量置信度数据中满足置信条件的数据加入已有可信数据集。
进一步的,所述步骤一中得到基分类器的分类模型集的具体方法为:
步骤1.1:定义已有可信数据集的特征和分类属性;
步骤1.2:选择Logistic回归、支持向量机和朴素贝叶斯中一个作为基分类器Function;
步骤1.3:对步骤1.1中定义过的已有可信数据集采用Bagging集成学习方法,以步骤1.2中选择的Function为基分类器,得到Function的分类模型集;
进一步的,所述步骤二中得到待度量置信度数据的分类结果的具体方法为:
步骤2.1:对待度量置信度数据进行分类,并计算不同分类中的分类概率,得到待度量置信度数据的分类结果集Y和待度量置信度数据的分类概率集Cf;
步骤2.2:统计步骤2.1中分类结果集Y中每个类别的个数,得到待度量置信度数据的分类结果py:
进一步的,所述步骤三中采用离群点分析方法对待度量置信度数据的分类结果进行置信度度量的具体方法为:
步骤3.1:设满足Point=Cfpy的点为离群点,将待度量置信度数据的分类概率集Cf中的Cfpy取出,并从概率集Cf中删除Cfpy,得到矩阵P;
步骤3.2:遍历矩阵P中每个分类,计算矩阵P的质心,其公式为:
式中,PLoop为分类概率集中第Loop个分类,Num为当前计算的分类,X为分类个数;
步骤3.3:遍历矩阵P中每个类别与质心的距离和离群点的距离,计算质心的公式为:
计算离群点的公式为:
式中,PNum为分类概率集中第Num个分类,MNum为Num分类对应的质心,α为自定义值;
步骤3.4:执行步骤3.3后,若满足dNum,2>dNum,1,则待度量置信度数据为可信数据,并将其加入到已有可信数据集Train中;否则,待度量置信度数据为不可信数据,不加入已有可信数据集Train中。
与现有技术相比,本发明的优点在于:
本发明方法通过Bagging和离群点分析,能有效的对Logistic回归、支持向量机和朴素贝叶斯等模型的分类结果进行置信度度量,从而避免了模型再学习时因采用了不可信的分类结果对训练模型的影响。此外,本发明创造性地提出了一种分类结果置信度的度量方法,用于对已有可信数据集可信数据的扩充,进而提高学习模型的有效性。
附图说明
图1为本发明的总体流程图;
图2为图1中装袋法模型训练的流程图;
图3为图1中待度量置信度数据分类的流程图;
图4为图1中分类结果置信度度量的流程图。
具体实施方式
下面结合附图和具体实施方式,进一步阐明本发明。
本发明技术方案是对Logistic回归、支持向量机和朴素贝叶斯等模型的分类结果进行置信度度量,首先采用Bagging集成学习方法,即,采用Logistic回归、支持向量机和朴素贝叶斯中的一个作为基分类器,对待度量置信度数据进行分类,并计算在不同分类中的分类概率,得到待度量置信度数据的分类结果集和待度量置信度数据的分类概率集,通过分类结果集得到待度量置信度数据的分类结果,其次,在分类概率集中,将每个分类作为空间中一个点,以分类结果对应分类概率集中的点作为离群点,余下分类对应分类概率集中的点为一个簇,最后,使用欧式距离,比较簇内每个点到簇质心的距离和到离群点的距离,若满足簇内所有点到簇质心的距离小于到离群点的距离,则该分类结果为可信,反之则为不可信,进而实现对分类结果置信度的度量。
具体的,本发明包括如下步骤:
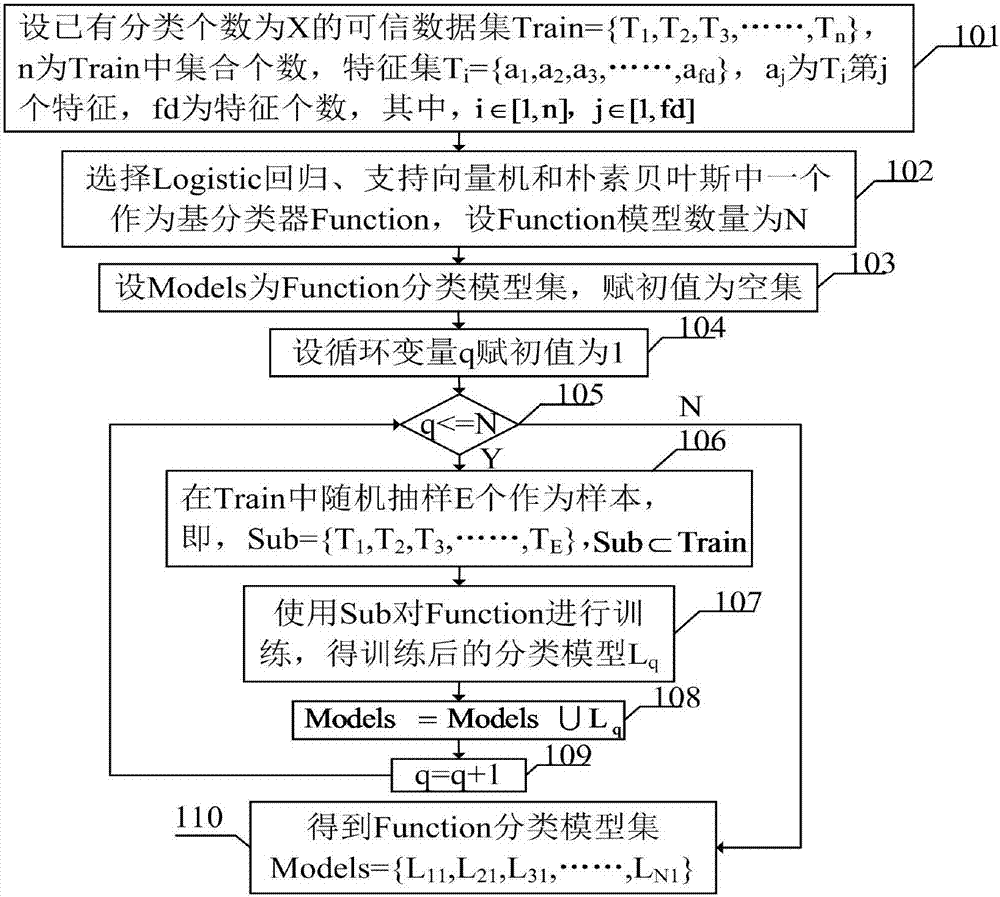
步骤一:对已有可信数据集采用Bagging集成学习方法,即,采用Logistic回归、支持向量机和朴素贝叶斯中一个作为基分类器,得到基分类器的分类模型集,具体的如图2所示;
步骤1.1:设已有分类个数为X的可信数据集Train={T1,T2,T3,……,Tn},n为Train中集合个数,特征集Ti={a1,a2,a3,……,afd},aj为Ti第j个特征,fd为特征个数,其中,i∈[1,n],j∈[1,fd];
步骤1.2:选择Logistic回归、支持向量机和朴素贝叶斯中一个作为基分类器Function,设Function模型数量为N;
步骤1.3:设Models为Function分类模型集,赋初值为空集;
步骤1.4:定义循环变量q赋初值为1;
步骤1.5:当循环变量q<=N时,则执行步骤1.6;否则执行步骤1.10;
步骤1.6:对步骤1.1中的可信数据集Train中随机抽样E个作为样本,即,Sub={T1,T2,T3,……,TE},
步骤1.7:使用Sub对Function进行训练,得训练后的分类模型Lq;
步骤1.8:Models=Models∪Lq;
步骤1.9:循环变量q=q+1;
步骤1.10:得到Function分类模型集Models={L1,L2,L3,……,LN};
步骤二:通过基分类器的分类模型集,对待度量置信度数据进行分类,并计算在不同分类中的分类概率,得到待度量置信度数据的分类结果集和待度量置信度数据的分类概率集,再对分类结果集进行统计,得到待度量置信度数据的分类结果,具体的如图3所示;
步骤2.1:设待度量置信度数据的特征集为Test={b1,b2,b3,……,bgd},其中,bk为Test中第k个数据特征,gd为Test的特征个数;
步骤2.2:采用Models对Test进行分类,得到待度量置信度数据的分类结果集Y={y1,y2,y3,……,yN}和待度量置信度数据的分类概率集Cf={C1,C2,C3,……,CX},其中,ys为第s个基分类器Function模型中待度量数据Test的分类结果;Cr为每个基分类器Function模型对第r个分类的分类概率,Cu={pr1,pr2,pr3,……,prN},prh为第h个基分类器Funtion模型的分类概率值,其中,s,h∈[1,N],u∈[1,X];
步骤2.3:统计步骤2.2中模型的分类结果集Y,设M为统计分类结果集Y中每个分类的个数,在M中选择统计值最大的分类作为待度量置信度数据的分类结果py;
步骤三:采用离群点分析方法,对待度量置信度数据的分类结果进行置信度度量,得到待度量置信度数据中的可信数据和不可信数据,并将待度量置信度数据中满足置信条件的数据加入已有可信数据集,具体的如图4所示;
步骤3.1:设满足Point=Cfpy的点为离群点,将待度量置信度数据的分类概率集Cf中的Cfpy取出,并去除分类概率集Cf中的Cfpy,得到P={C1,C2,C3,……,CX-1},其中,
步骤3.2:设循环变量Num赋初值为1,用于遍历矩阵P的行;
步骤3.3:当循环变量Num<=X-1时,则执行步骤3.4;否则执行步骤3.8;
步骤3.4:计算待度量置信度数据的分类概率集P的质心,其中不包含PNum,得;
步骤3.5:计算PNum与M的欧式距离为:PNum与Point的欧式距离为,其中,α赋值为0.5
步骤3.6:当d1<d2时,则执行步骤3.4;否则执行步骤3.7;
步骤3.7:循环变量Num=Num+1;
步骤3.8:得到待度量置信度数据为不可信数据,Train=Train;
步骤3.10:得到待度量置信度数据为可信数据,并将其加入到已有可信数据集Train中,即,Train=Train∪{Test,py}。
其中,以Bagging集成学习方法,采用基分类器为Logistic回归、支持向量机和朴素贝叶斯中的一个作为基分类器对可信数据训练,通过待度量置信度数据得到的分类概率集,在分类概率集中,将每个分类作为空间中一个点,以分类结果对应分类概率集中的点作为离群点,余下分类对应分类概率集中的点为一个簇,通过欧式距离来判定分类结果的置信度。
其中,步骤1.1是提供模型训练所需初始数据;步骤1.2到步骤1.10是,以Bagging集成学习方法对数据训练,其中以Logistic回归、支持向量机和朴素贝叶斯中的一个为基分类器;步骤2.1到步骤2.3是对待度量置信度的数据进行分类,并计算在不同分类中的概率,得到待度量置信度数据的分类结果集和待度量置信度的数据的分类概率集;步骤3.1到步骤3.10是一种计算对待度量置信度数据的分类结果的置信度度量的方法。
为了更好地说明本方法的有效性,通过已有的Web页面分类数据和UCI官网上公开的Car Evaluation数据集和Letter Recognition数据集作为原始数据集,分别通过Logistic回归模型、SVM模型和朴素贝叶斯模型进行分类,并对分类的结果进行置信度度量。
通过Web页面分类数据4553条数据进行了实验,特征为Web页面中的title字段describe中的keywords,以样本70%作为训练集,30%的作为测试集,通过Logistic回归模型分类,取得90.64%的准确率,其中包含128条错分数据,若通过对分类结果的置信度度量,可从分类结果中选出1092条(占原测试集的80%),该筛选出的子集准确率为98.07%。通过朴素贝叶斯模型分类,取得88.1%的准确率,其中包含162条错分数据,若通过对分类结果的置信度度量,可从分类结果中选出1012条(占原测试集的74.1%),该筛选出的子集准确率为96.93%。通过SVM模型分类,取得88.64%的准确率,其中包含155条错分数据,若通过对分类结果的置信度度量,可从分类结果中选出1004条(占原测试集的73.5%),该筛选出的子集准确率为94.5%。
通过UCI中公开的数据,选用手写字识别的数据Car Evaluation,该数据量为1728条,特征为6个。以样本70%作为训练集,30%的作为测试集,通过Logistic回归模型分类,取得81.3%的准确率,其中包含96条错分数据,若通过对分类结果的置信度度量,可从分类结果中选出407条(占原测试集的78.6%),该筛选出的子集准确率为98.07%。通过朴素贝叶斯模型分类,取得70%的准确率,其中包含155条错分数据,若通过对分类结果的置信度度量,可从分类结果中选出429条(占原测试集的82.8%),该筛选出的子集准确率为78.3%。通过SVM模型分类,取得94.8%的准确率,其中包含27条错分数据,若通过对分类结果的置信度度量,可从分类结果中选出496条(占原测试集的95.8%),该筛选出的子集准确率为97.8%。
选用UCI中公开的Letter Recognition数据集,该数据量为20000条,特征为16个。以样本70%作为训练集,30%的作为测试集,通过Logistic回归模型分类,取得71.3%的准确率,其中包含1722条错分数据,若通过对分类结果的置信度度量,可从分类结果中选出2902条(占原测试集的48.37%),该筛选出的子集准确率为91.42%。通过朴素贝叶斯模型分类,取得54.78%的准确率,其中包含2713条错分数据,若通过对分类结果的置信度度量,可从分类结果中选出2362条(占原测试集的39.37%),该筛选出的子集准确率为79.17%。通过SVM模型分类,取得96.87%的准确率,其中包含187条错分数据,若通过对分类结果的置信度度量,可从分类结果中选出5821条(占原测试集的97%),该筛选出的子集准确率为98.2%。
除了通过Logistic回归、支持向量机和朴素贝叶斯外,还可以对迭代决策树和KNN等支持分类概率输出模型的分类结果进行置信度度量。通过CarEvaluation数据集,对迭代决策树和KNN模型分类结果进行置信度度量,模型准确率分别为98.5%和91.71%,若通过对分类结果的度量,可从分类结果中选出499条(占原测试集的96.3%)和415条(占原测试集的80%),子集准确率为99.8%%和99%。
本发明可与计算机系统结合,从而自动完成对分类结果置信度的度量。
本发明提出的一种基于Bagging和离群点的分类结果置信度的度量方法,以上所述仅为本发明的实施例子而已,并不用于限制本发明。除了对Logistic回归、SVM和朴素贝叶斯等模型的分类结果进行置信度度量外,也可用于对迭代决策树(GBDT)、KNN和BP神经网络等支持分类概率输出的模型。凡在本发明的原则之内,所作的等同替换,均应包含在本发明的保护范围之内。本发明未作详细阐述的内容属于本专业领域技术人员公知的已有技术。
- 还没有人留言评论。精彩留言会获得点赞!