一种基于尺度变换激活函数的超限学习机的改进方法与流程
本发明涉及一种改进的超限学习机算法,尤其是一种基于尺度变换激活函数的超限学习机的改进方法,属于人工智能的技术领域。
背景技术:
超限学习机(extremelearningmachine,elm)是一种单隐含层前馈神经网络(single-hiddenlayerfeedforwardneuralnetworks,slfns),仅有一个隐含层。相比较于传统的bp神经网络需要多次迭代进行参数的调整,训练速度慢,容易陷入局部极小值,无法达到全局最小等缺点,elm算法随机产生输入层与隐含层的连接权值与偏置,且在训练过程中无需进行隐层参数迭代调整,只需要设置隐含层神经元的个数以及激活函数,便可以通过最小化平方损失函数得到输出权值。此时,这个问题转化为一个最小二乘问题,最终化为求解一个矩阵的moore-penrose问题。即:对于给定的一个训练的数据集{(xi,ti)|xi∈rd,ti∈rm,i=1,2,...,n},其中xi是训练数据向量;ti是每一个样本的目标;d是每一个输入样本的特征向量维数;m是总共的类数。elm的目标就是达到最小的训练误差,即
这里,h是隐藏层的输出矩阵,可以表示成
此外,β是输出权重矩阵,t是训练样本的目标矩阵,可表示为
其中,
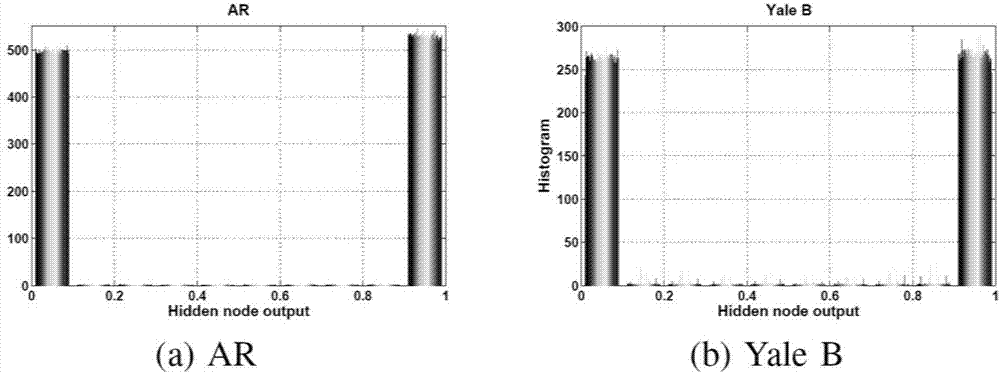
近十年来,elm已经吸引了大量的关注。但是仍然存在一个现实的问题:对于固定的隐藏层的激活函数,随机生成的未经调整的隐藏层参数可能导致许多经过隐藏层参数作用后的数据落入激活函数的饱和区域(远离原点的区域)或者原点附近的单调区域(近似一个线性函数),从而使得泛化性能变差。其原因是对输入数据进行变换v=w·x+b后,v的值集中在激活函数的饱和区域或者原点附近(接近于线性函数)。以两个基准图像识别数据集(ar人脸数据集和扩展yaleb数据集)为例,使用sigmoid函数
因此,如何能够较好地克服上述问题,提高elm的稳健性和泛化能力显得非常重要。
技术实现要素:
本发明为了克服上述存在的传统的超限学习机技术中的不足,提出了一种基于尺度变换激活函数的超限学习机的改进方法(selm)。这个改进的超限学习机(即selm)使用了一种基于尺度变换的激活函数,能够根据输入数据的分布以及随机生成的隐藏层参数值,自适应地调节缩放和平移参数,使隐藏层数据经过尺度变换激活函数的映射后,在输出区间上能够服从均匀分布,从而使得信息熵达到最大,即能够从数据中得到更多信息,具有更稳健的泛化性能。
按照本发明提供的技术方案,提出了一种基于尺度变换激活函数的超限学习机的改进方法,包括如下步骤:
步骤1、随机产生隐藏层节点参数(w,b),
其中,wi是连接第i个隐藏层节点和输入神经元的输入权重,bi是第i个隐藏层节点的偏差,l是隐藏层节点个数。
步骤2、给定一个训练的数据集{(xi,ti)|xi∈rd,ti∈rm,i=1,2,...,n},其中,xi是训练数据向量;ti是每一个样本的目标;d是每一个输入样本的特征向量维数;m是输出向量的维数。
经过隐藏层节点参数(w,b),变换所得隐藏层数据矩阵v:
步骤3、将隐藏层数据矩阵v中的n×l个元素按照从小到大的顺序排列成n×l维向量vasc,即:
vasc=[v1,…,vk,…,vn×l]t公式3
步骤4、给定一个激活函数g(·),并确定隐藏层的期望输出区间为
步骤5、将区间
步骤6、计算尺度变换参数s和t,用来调整向量vasc,使得调整后的向量经过激活函数g(·)映射后的数据在隐藏层的期望的输出区间
通过计算
步骤7、以尺度变换激活函数g(v,s,t)求其隐藏层的输出矩阵h,
并求得输出权重
步骤8、对于未知的测试样本xp,可得到h=g(w·xp+b,s,t),进而求得输出
所述步骤5中,隐藏层的期望输出区间为
所述步骤6中,
6-1.首先确定下采样向量的维度nd,求得下采样率为
6-2.定义最大迭代步数κ和一个较小的度量误差ε>0。
6-3.随机定义s和t的值,通过误差函数
6-4.由定义的s和t以及计算求得的ε,根据s和t的梯度解析形式求解对应的
6-5.通过公式9逼近s和t的目标值:
其中η为步长。
6-6.每循环一次,迭代步数κ增加一次,ε的值也更新一次。如果迭代步数小于最大迭代步数:κ<κ,或误差函数值大于度量误差:ε>ε则继续重复进行步骤6-3到步骤6-5,直到跳出循环,得到参数s和t的目标值,进而得到尺度变换激活函数g(s,v,t)。
本发明有益效果如下:
这种基于尺度变换激活函数的改进超限学习机能够根据输入数据分布和随机生成的隐藏层参数,自适应调整缩放和平移参数,最后通过尺度变换激活函数映射后,能够使隐藏层输出均匀的分布在期望的输出区间内,这样,不仅避免了未经调整的隐藏层参数可能导致数据坠入激活函数饱和区域的问题,而且相比于非均匀分布的传统超限学习机,能从数据中得到更多信息,具有更稳健的泛化性能。
附图说明
图1为极限学习机原理图;
图2为selm的训练及测试效果图。
图3为本发明流程图。
具体实施方式:
下面结合具体实施例对本发明作进一步说明。以下描述仅作为示范和解释,并不对本发明作任何形式上的限制。
如图1-3所示,一种基于尺度变换激活函数的超限学习机的改进方法,实现的过程如下:
(1)选取任意一个训练数据集,首先由随机函数随机产生隐藏层节点参数(w,b),
将v中的(n×l)个元素以上升序列排列成(n×l)维隐藏层数据向量vasc,
且vasc=[v1,…,vk,…,vn×l]t
并对其均匀下采样,下采样向量的维度为nd,得到新的向量:
(2)给定一个激活函数g(·),隐藏层的期望输出区间为
(3)以尺度变换激活函数g(s·v+t)求其隐藏层的输出矩阵h,
并求得输出权重
(4)测试过程,对于未知的测试样本xp,可得到h=g(w·xp+b,s,t),进而求得输出
- 还没有人留言评论。精彩留言会获得点赞!