一种基于全记忆事件序列挖掘模型的用药分析方法与流程
本发明属于数据挖掘、医疗信息和大数据技术领域,具体涉及一种基于全记忆事件序列挖掘模型的用药分析方法。
背景技术:
有效的用药方案对于患者获取最佳治疗是非常重要的。利用已经积累的大规模的患者临床用药历史数据进行分析建模,有助于医生对患者下一步用药提供决策支持。数据挖掘方法已经被用于用药分析,传统的用药数据挖掘方法采用频繁模式挖掘发现频繁出现的用药组合,推断药物之间的关联。然而,一方面,不考虑用药顺序的频繁模式挖掘忽略了疾病演变的特征对用药的影响;另一方面,虽然已有考虑“序”和时间特征的频繁序列模式挖掘方法被使用,然而,大量冗余的结果模式和关联规则限制了方法的实际应用。更重要的是,患者的用药并不是简单的考虑先后关系,还需要考虑在治疗过程中前序不同时间点的用药对目标时间点的用药的影响的差异。
本发明针对患者用药历史数据,提出一种基于全记忆事件序列挖掘模型的用药分析方法。首先,采用事件序列形式建模表示用药历史数据,即形成用药事件序列;然后,针对患者疾病随时间的变化,以及用药受不同阶段用药情况的影响,将需要预测事件的时间节点前的所有事件看作为预测事件的记忆,对预测事件记忆加权构成事件记忆特征表示,并构建训练数据集;再构建训练模型,设置损失函数,求解参数;最后,对于待预测用药事件序列实现事件预测。该方法不仅考虑了时间顺序,以及不同阶段患者用药的影响差异,而且对比以往的一阶或高阶事件序列分析方法,能够利用尽可能多的数据来用于决策,从而减少决策的失误。
技术实现要素:
本发明的主要目的是提供一种基于用药记录数据的用药分析方法,能够使用患者周期内所有历史用药事件记忆来帮助预测下一个用药事件的发生。
本发明提供了一种基于全记忆事件序列挖掘模型的用药分析方法,事件序列的记忆是以预测事件的时间节点为前提定义的,在预测事件的时间节点前的所有事件被看作为预测事件的记忆。本发明的主要思想是:将原始用药数据转换成类别型的用药事件发生序列,把所有类别型用药事件序列的每个用药事件节点转换为欧式空间的多维向量表示,此基础上,根据要预测的用药事件的前一个节点(称为当前事件)来对所有历史记录的事件(预测事件的记忆,设置一个特定的记忆长度阈值,选择高于该阈值的序列用于构造训练数据集)加权求和,形成预测事件的记忆的特征表示,作为预测下一个事件向量的分类器的标准输入,把要预测的事件的多维向量表示作为输出,训练一个预测模型,再把欧式空间的多维向量映射回原来的类别型空间,使用所有用药事件序列训练;最后,对于新的用药事件序列,输入训练好的模型,用于预测未来事件。该方法不仅考虑了时间顺序,以及不同阶段患者用药的影响差异,而且对比以往的一阶或高阶事件序列分析方法,能够利用尽可能多的数据来用于决策,从而减少决策的失误
本发明提供的基于全记忆事件序列挖掘模型的用药分析方法,其流程如图1所示,具体步骤如下:
(1)首先,对患者历史用药数据进行预处理,即采集用药事件序列的原始数据,将原始用药数据转换成用药事件发生序列;然后,对用药事件序列数据进行处理,将序列中的每个事件都用一个或多个类别型的变量进行表示;
(2)对于已经处理好的类别型变量表示的事件序列,设置一个特定的记忆长度阈值,选择高于该阈值的序列用于构造训练数据集;
(3)采用基于全记忆事件序列方法构建训练预测模型;
(4)对于新的用药事件序列,输入预测模型实现对未来时间节点的用药事件进行预测。
本发明步骤(1)中,患者历史用药数据的事件序列的转化表示,将患者历史用药记录表示为事件,每个事件用一个或多个类别型变量表示。
本发明步骤(2)中,将患者用药的历史事件作为记忆序列,形成记忆特征表示。
本发明步骤(4)中,把新的用药事件序列作为训练好的预测模型的输入,使用模型输出预测结果
本发明步骤(2)中,构造训练数据集方法的具体步骤为:
(1)设置一个特定的记忆长度阈值M,要高于这个阈值的序列才用于构造训练数据集合;
(2)对于每个事件序列,从第M+1个事件节点开始设置预测节点,采集训练集;预测节点的每个类别变量作为模型的输出,当前节点之前的所有节点作为模型的输入;预测节点不断向右移动,每移动一个时间节点就形成一个或多个新的训练数据。如图2所示。
本发明步骤(3)中,构建训练模型方法的具体步骤为:
(1)设置一个最大记忆数量T,使用的记忆数量不能超过这个数量,通常设置大于数据中大部分序列的长度;
(2)初始化变换矩阵A,把预测事件的前一个事件投影到多维连续空间中的向量,并求和形成一个向量q;
(3)初次化变换矩阵B、C,把预测事件之前的所有事件(前一个事件除外)分别投影到多维连续空间中的多个向量,这些称为记忆向量,表示预测事件的所有记忆;
(4)使用向量q和经过B投影矩阵变换后的向量做内积,形成权重向量,再使用这些权重向量和经过C投影矩阵变换后的记忆向量加权求和,形成最终的一个记忆向量表示m;
(5)向量m和向量q相加,作为预测分类器的输入,并使用一个变换矩阵W,投影到原始的离散事件空间,再使用softmax函数,得到下一个预测事件的每一项的概率;
(6)使用交叉熵损失函数作为目标函数,使用梯度下降的方法求参数,即求得参数A、B、C和W。
这里,变换矩阵A、B、C可以是随机投影矩阵(或其它离散变量的嵌入式方法embedding matrix)。
本发明方法可根据患者用药记录数据来对患者用药情况进行数据分析,并对患者后期用药情况和疾病或并发症进行推断。
本发明方法对事件序列进行预测,对比以往的一阶或高阶事件序列分析方法,能够利用尽可能多的数据来用于决策,从而减少决策的失误。
附图说明
图1为本发明的挖掘方法流程示意图。
图2为本发明方法中构造训练集的方法示例图。
图3为发明方法的具体实施方式示例图。
具体实施方式:
下面给出该方法的具体实施方式,如图3所示。
(1)用药事件序列生成:统计所有用药事件序列中的出现的用药事件内容,用离散变量的集合表示用药事件序列中的每个用药事件,例如,(1,3,5)-(6,7)-(8)是一个长度为3的用药事件序列,每个用药事件序列的节点用离散变量的集合表示。例如,上面的用药事件序列中假设一共有8种药物,每种药物对应的离散变量表示为1~8,那么上述序列表示患者第一次用了1,3,5这三个编号的药物,第二次用了6,7这两个编号的药物,第三次使用了8这个编号的药物。
(2)训练数据集构造:使用上述生成的用药事件离散序列来构建训练数据集(X,Y),其中,X是分类器的输入,Y是分类器的输出。根据预先指定的最短记忆长度M,把一个N个事件的用药事件序列分为|N-M|个训练数据集合,每个训练数据集合的形式分别是(X=x1,x2,x3,…,xT,y), 其中y是原始序列中xT的下一个事件,也就是xT+1。例如,对于上例中的用药事件序列,如果指定最短历史记忆长度为2(即M=2),那么,该序列可以作为其中一个训练数据集,X=[x1,x2]=[(1,3,5),(6,7)],y=(8),其中x1=(1,3,5),x2=(6,7)。
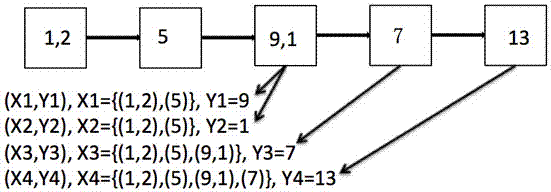
例如:在图2中,假设其中一个事件序列数据样本为(1,2)-(5)-(9,1)-(7)-(13),如果设置最短记忆长度为2,则可以形成以下4个训练样本:第1和第2个训练样本是以第3个时间节点的事件为预测事件,标签分别为9和1,输入为(1,2)-5。第2个训练样本以第4个时间节点的事件为预测事件,标签为7,输入为(1,2)-(5)-(9,1)。第4个样本以第5个时间节点的事件为预测事件,标签为13,输入为(1,2)-(5)-(9,1)-(7)。
(3)使用一个随机投影矩阵C(或其它离散变量的嵌入式方法embedding matrix),把输入变量x中的前T-1个离散变量集合序列[x1,x2,…,xT-2,xT-1]转变成一个欧氏空间的多维连续向量序列[xc1,xc2,…,xcT-2,xcT-1],其中,每个xci是一个多维连续向量。实现的方法是把每个离散变量用C矩阵的对应的列表示,然后,一个时间节点上的事件的所有离散变量对应的多维连续变量相加,形成表示一个事件的多维向量,例如,在上面的例子中,x1=(1,3,5),xc1=(C~1+C~3+C~5)是矩阵C的对应第1,3,5这三列相加,使用数学表达式的方法就是把一个事件里的每个离散变量使用one-hot方法表示,即xi1=0000010…00,那么xci=C*xi1+C*xi2+C*xi3。
(4)使用另一个随机投影矩阵B(或其它离散变量嵌入式方法),把[x1,x2,…,xT-2,xT-1]用欧氏空间的多维连续向量表示为[xb1,xb2,…,xbT-2,xbT-1]。其中每个事件xbi是一个多维连续向量。实现的方法和上面的步骤相同,只是投影矩阵不同。其中B、C矩阵和下面提到的A矩阵都可以看做是特征矩阵,也可以看做是模型的参数,作用在于把离散事件序列的输入转换为多维度欧式空间的特征。
(5)使用第三个随机投影矩阵A把当前事件集合[xT]用一个欧式空间的高维连续向量表示[xq]。在上面的例子中,x2=xT=(6,7),那么xq=A~6+B~7,也就是把矩阵A的第6列和第7列相加,来表示xq这个欧式空间的多维向量。
(6)把xq分别和[xb1,xb2,…,xbT-2,xbT-1]做向量内积,得到一个权重向量P=(p1,p2,…,pT-1)。
(7)把权重向量p1,p2,…,pT-1分别乘以xb1,xb2,…,xbT-2,xbT-1,再求和,得到输出记忆向量O=p1*xb1+…+pT-1*xbT-1。
(8)把xq和O相加,得到分类器的输入向量。
(9)分类器的输出设置为:y=softmax(W(xq+O)),其中,y是输出的离散变量。W是D*|V|的矩阵,其中D是提前设置的多维向量的维度,|V|是所有出现的用药事件内容的个数。
(10)设置交叉熵损失函数,作为训练这个预测模型的目标函数。其中yik=1,表示一个训练样本的输出为离散索引k(表示药物标号),yik-就是预测的概率取值,取值为0~1之间,由上一步的softmax函数得到。
(11)训练模型,即求解参数A、B、C和W,这里使用梯度下降方法求解。
(12)预测:对于一个序列[x1,x2,…,xT],要预测xT+1,按照前面(1)~(9)步骤,得到要输出的事件的类别型变量表示,再根据事件的内容编码解释数据的内容。例如,如果模型的输出结果是5,那么对应的预测结果就是5所对应的药物。
(13)例如:在图3中,当一个训练样本为(1,2)-(5)-(9,1)-(7)-(13),其中标签为(13),输入为(1,2)-(5)-(9,1)-(7),根据步骤(3)~(10),事件变量(7)和(1,2)-(5)-(9,1)分别形成最后的多维欧式空间中的向量q和m,然后相加作为分类器的输入,使用W矩阵和softmax函数形成最后的输出,并和真实标签共同计算交叉熵损失函数。
- 还没有人留言评论。精彩留言会获得点赞!