一种基于Spark的链式多路空间连接查询处理算法的制作方法
本发明涉及空间数据查询处理技术领域,具体的说是涉及一种基于Spark的链式多路空间连接查询处理算法。
背景技术:
空间连接查询是一种重要的空间数据查询类型,广泛存在于空间数据管理中,空间连接查询处理技术也一直是空间数据库管理领域的研究热点。多路空间连接查询是一种常用的空间连接操作,它是从多个空间数据集合中检索出所有满足某一空间谓词(如相交、包含等)的空间对象,是最耗时的空间操作之一,其复杂性和重要性使之成为决定空间数据管理系统整体性能的重要因素之一,因此提高多路空间连接查询处理效率就一直成为学术界的研究热点问题。特别是近年来,随着物联网技术、对地观测技术和基于位置的服务技术的快速发展和广泛应用,使得空间数据规模急剧增加,已经成为一类重要的大数据。如何对这类空间大数据进行高效的多路空间连接查询处理,已成为当前空间数据管理领域所面临的重要挑战。传统的基于空间数据库的处理技术存在者扩展性弱的问题,因而难以满足空间大数据快速查询处理的要求,而Spark作为一种新型的超大规模数据分布式并行处理平台而受到人们的广泛重视,也是目前大数据处理的关键技术。因此结合Spark分布式并行处理平台所提供的大规模数据处理能力,来深入研究空间大数据的高效多路空间连接查询处理方法,已经成为解决上述挑战的重要手段。
在多路空间连接查询处理中,现有的方法主要存在的以下问题:(1)传统的基于空间数据库的多路连接处理方法,主要采用集中式的处理方式,其扩展性差,难以满足空间大数据快速查询处理的要求;(2)现有的一些流行算法,如动态规划算法、混合连接算法等多是集中式构建索引,对于海量的数据连接查询,效率比较低;(3)现有的分布式处理方法主要基于Hadoop平台,并聚焦于通用多路连接查询处理优化方面,存在的数据复制过多、过滤能力弱的问题,从而影响了查询处理的效率;(4)目前最新的分布式多路空间连接算法就是Gupta等人提出了两种基于MapReduce的多路空间连接查询处理算法Controlled-Replicate和ε-Controlled-Replicate。Controlled-Replicate将各类连接数据集中的空间对象划分并复制到第四象限中的所有网格单元,再进行多路连接运算。显然这种方法造成了大量空间对象的复制,影响连接处理效率。为此作者又提出了改进的多路空间连接查询处理算法ε-Controlled-Replicate,该算法在一定程度上减少了数据复制,提高了查询处理效率,但是还存在着数据复制过多的问题。对于Spark平台来说,数据复制量过多,会造成一次性加载到内存中的数据量太大,不能很好的发挥Spark的基于内存计算的优势,也会导致查询效率低下等问题。
对上述问题进行深入研究,并提出相应的解决方法后,可将其应用到空间大数据的连接查询处理等相关应用领域。为此,本发明提出了一种Spark平台下的空间多路连接查询处理算法,该算法主要针对链式多路空间连接查询,采用基于网格的数据空间划方法,并结合Z-order编码来实现数据的划分和编码,按照数据对象所在空间位置来进行数据投影和复制。在连接过程中,该算法采用边界过滤方法来减少无用连接数据,从而减少后续连接的多余计算,以及连接对象的多余投影与复制。并采用重复避免策略来减少重复结果的输出,从而全面减少后续连接计算的代价,提高多路连接查询处理的效率。
技术实现要素:
鉴于已有技术存在的缺陷,本发明的目的是要提供一种基于Spark的链式多路空间连接查询处理算法,该算法主要聚焦于链式多路空间连接查询处理问题,重点在于减少过滤阶段的空间数据复制和计算量,从而减少后续的连接计算代价,提高查询处理效率,该算法并具有良好的适应性和扩展性。
为了实现上述目的,本发明的技术方案:
一种基于Spark的链式多路空间连接查询处理算法,包括如下步骤:
步骤1:利用网格划分方法,将整个数据空间划分成许多大小相同的网格单元,并采用Z-order填充曲线技术对每个网格单元进行编码;
步骤2:将m(m>2)路空间连接数据集R1,R2,…,Rm中的每个空间对象根据其在数据空间中的位置投影到相应的网格单元,并形成一系列键值对,将投影结果分别存放到弹性分布式数据集RDD1,RDD2,…,RDDm中,设定循环变量i=2,中间结果数据集RDDresultnew=RDD1;
步骤3:如果满足条件i<m,则对两个数据集RDDresultnew,RDDi执行空间连接运算Overlap(RDDresultnew,RDDi)。计算过程中,依次进行数据聚集、边界过滤、空间连接计算、重复避免和数据复制等操作,最终形成中间结果数据集RDDresultnew,即RDDresultnew=Overlap(RDDresultnew,RDDi);
步骤4:i=i+1,执行步骤3直到条件i<m不满足为止;
步骤5:执行最后一次空间连接运算Overlap(RDDresultnew,RDDm),计算过程中,依次进行数据聚集、边界过滤、空间连接计算,并将结果直接输出,形成最终空间连接结果集合,并保存到HDFS文件系统。
进一步的,所述数据划分和编码方法为:采用基于网格的划分方法将整个数据空间划分成n个大小相等的网格单元,采用Z-order填充曲线对网格单元进行编码,空间数据对象根据其位置被投影到各个网格单元,并采用Hash方式将所有网格单元映射给多个Executor执行单元,使得整个处理任务被划分成多个并行的处理任务。
进一步的,所述空间对象投影为:将空间数据对象根据其所在位置映射到相应的网格单元中,设C=(c1,c2,…,cn)代表一个数据空间划分,ci代表每一个网格单元;设R为一类待连接处理的空间对象集合,若一个空间对象u∈R,其MBR与网格单元ci有交叠,所述ci为网格单元的Z-order编码,则将对象u映射到网格单元ci中,并生成相应键值对(ci,u),如果一个空间对象与多个网格单元有交叠,则相应的会生成多个键值对。
进一步的,步骤3具体包括以下步骤:
步骤3-1:计算Overlap(RDDresultnew,RDDi),即对RDDresultnew,RDDi按照Key值执行Cogroup操作,即将RDDresultnew和RDDi中的数据根据Key值聚集到一起得到RDDnew;
步骤3-2:利用过滤策略对RDDnew进行过滤,去掉不可能有结果的数据对,然后进行实际空间连接运算;
步骤3-3:执行重复避免策略,形成连接中间结果,并对连接中间结果执行数据复制操作,最终形成新的中间连接结果数据集RDDresultnew。
进一步的,步骤5包括以下步骤:
步骤5-1:计算Overlap(RDDresultnew,RDDi),即对RDDresultnew,RDDi按照Key值执行Cogroup操作,即将RDDresultnew和RDDi中的数据根据Key值聚集到一起得到RDDnew;
步骤5-2:利用过滤策略对RDDnew进行过滤,去掉不可能有结果的数据对,然后进行实际空间连接运算;
步骤5-3:执行重复避免策略,形成由元组对构成的最终连接结果数据集RDDresultnew,并保存到HDFS文件系统。
进一步的,所述数据复制操作为:对于当前网格单元上的最近一次空间连接运算所生成的中间连接结果集合T中的任一元组t,若t.s为与下一次空间连接运算相关的空间对象,则若t.s与某一网格单元ci存在交叠,则将元组t复制到网格单元ci,并生成相应的键值对(ci,t)。
进一步的,所述过滤策略为:在并行执行连接运算的过程中,采用相应过滤策略,去掉不可能产生连接结果的元组,并仅对可能产生连接结果的元组进行复制。
进一步的,所述过滤策略包括两部分:
边界过滤,所述边界过滤为:在进行连接运算之前,首先统计已经完成的连接中间结果中与后续空间连接相关的空间对象的边界MBR,并利用该MBR来过滤掉后续要连接数据集中与该MBR不相交的空间对象,从而减少后续连接计算代价;
复制阶段过滤,所述复制阶段过滤为:在多路连结查询处理过程中,需要对前几路连接处理之后的中间结果进行数据复制操作,仅将其复制到可能会产生连接结果的其他网格单元中,从而避免连接结果的丢失,在对中间连接结果复制中,仅对包含跨网格连接对象的中间结果进行复制。
进一步的,所述重复避免策略为:在两个跨多个网格单元的空间对象进行连接时,仅让这两个相交叠而形成的新的对象的左下角交点所在的网格单元负责输出结果。
与现有技术相比,本发明的有益效果:本发明是一种基于Spark的链式多路空间连接查询处理算法,采用网格划分方法对数据空间进行划分,并基于空间对象所在的位置来进行数据投影和复制,计算过程中采用边界过滤方式,来过滤掉无用的连接对象,并通过缩小复制范围,减少数据复制,在处理效率和减少计算代价方面都有了显著的提高,并具有良好的适应性和扩展性。
附图说明
图1为本发明具体实施方式中Z-order曲线编码的示例图;
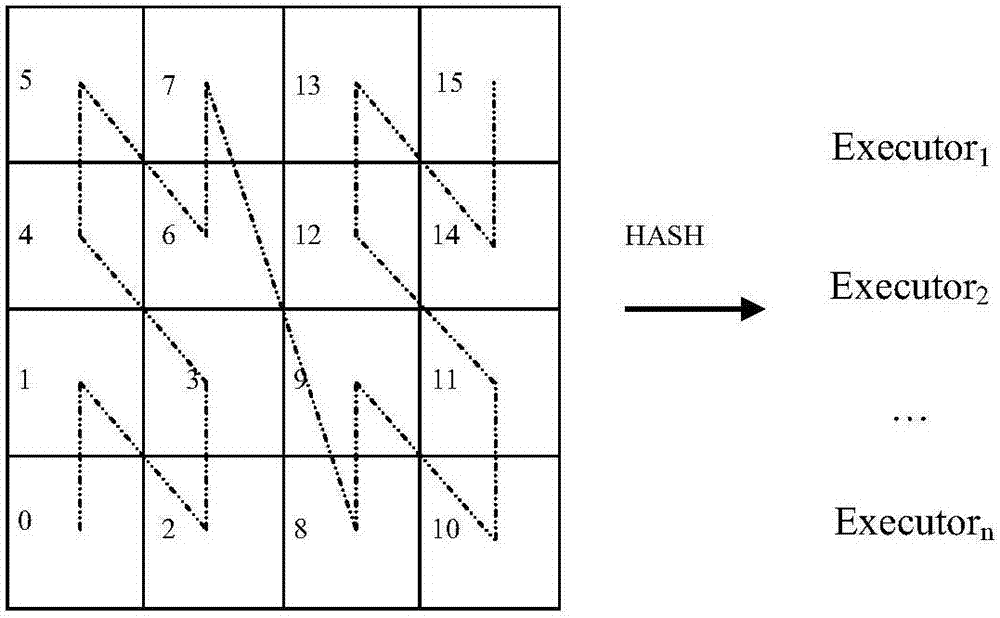
图2为本发明具体实施方式中的对数据进行划分和任务映射的示意图;
图3为本发明具体实施方式中的对数据进行投影与复制操作的示例图;
图4为本发明具体实施方式中所述的边界过滤的示例图;
图5为本发明具体实施方式中所述的重复避免的示例图;
图6为本发明具体实施方式中的基于Spark的链式多路空间连接查询处理算法的处理流程示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图,对本发明进行进一步详细说明。
本发明提出的一种基于Spark的链式多路空间连接查询处理算法,该算法主要聚焦于链式多路空间连接查询处理问题,重点在于减少过滤阶段的空间数据复制和计算量,从而减少后续的连接计算代价,提高查询处理效率,该算法并具有良好的适应性和扩展性。
实施例1:
一种基于Spark的链式多路空间连接查询处理算法,关键技术主要包括以下几个部分:
1)数据空间划分和编码:采用网格划分方法将整个空间划分成n个大小相等的网格单元,采用Z-order填充曲线对网格单元进行编码,空间数据对象根据其位置被投影到各个网格单元,并采用Hash方式将所有网格单元映射给多个Executor执行单元,使得整个处理任务划分成多个并行的计算任务,从而以并行的方式提升整个算法的执行性能。
如图1所示,为了保持空间对象间的空间关系,采用空间填充曲线对网格单元进行编码,图1为位(bit)数为1、2时的Z-order曲线。Z-order曲线是一种空间填充曲线。Z-order(z-排序)技术是利用bit位来表示空间对象的属性信息,然后利用循环的方法将数据空间分解,划分后的子空间会得到一组数字,被称为该子空间的z-排序值,并作为该子空间数据对象的Key值。
如图2所示为任务划分映射示例,从图中可以看出被划分后的各个网格单元与划分到其上的数据集通过Hash映射方式分配给Spark平台中的n个Executor执行单元来并行执行。
2)空间对象投影:就是将空间数据对象根据其所在位置映射到相应的网格单元中。设C=(c1,c2,…,cn)代表一个数据空间划分,ci代表每一个网格单元;设R为一类待连接处理的空间对象集合,若一个空间对象u∈R,其MBR与网格单元ci(ci为网格单元的Z-order编码)有交叠,则将对象u映射到网格单元ci中,并生成相应键值对(ci,u),如果一个空间对象和多个网格单元有交叠,则相应的会形成多个键值对。投影操作可以表示为:
3)数据复制:在多路连结查询处理中,需要多个数据集之间进行多次连接运算,数据复制则是将当前网格单元上的最近一次空间连接的中间结果复制到相关的其他网格单元,从而进行后续的连接操作,其结果与投影操作类似,会生成一系列的键值对。若t∈T为连接中间结果中的元组,t.s为将要进行后续空间连接的对象,则若t.s与某一网格单元ci存在交叠,则将元组t复制到网格单元ci,并生成相应的键值对(ci,t)。复制操作可表示为:
图3为数据投影与复制操作的例子,从中可以看出,空间对象被投影到了与之交叠的网格单元。对象r1被投影到6和12号网格单元,r2被投影到9和12号单元,r3则被投影到9和11号单元,即Project(r1,C)={(6,r1),(12,r1)},Project(r2,C)={(9,r2),(12,r2)},Project(r3,C)={(9,r2),(11,r2)}。当执行r1,r2和r3依次进行多路连接时,由于r2和网格单元9有交叠,因此网格单元12中r1和r2的连接中间结果(r1,r2)要被复制到网格单元9中,形成键值对(9,(r1,r2)),从而实现与网格单元9中的空间对象r3后续连接操作,避免了连接结果的丢失。
4)过滤策略:在并行执行连接运算的过程中,采用边界过滤策略,去掉不可能产生连接结果的元组,并仅对可能有结果的元组进行复制,大大减少存储和后续计算的代价。具体包括以下两种过滤策略:
A:边界过滤:首先统计前面几次已完成连接结果中相关连接对象的边界MBR,并利用该MBR来过滤掉后续要连接数据集中与该MBR不相交的空间对象,从而减少后续连接计算代价:
图4为一个边界过滤的例子,图中三个数据集R、S和T依次进行三路连接运算投影到网格单元3中的空间对象如图所示,的结果分别为(r1,s1),(r1,s2),(r1,s3),可以得到前一次连接结果集中的对应S集合中的对象为s1、s2和s3,其边界MBR为图中虚线所示,在与数据集T中对象进行连接运算时,可以直接过滤掉投影到网格单元3中的与该MBR不相交的空间对象t1、t4和t5,避免了这些空间对象分别与s1、s2和s3进行连接运算,从而大幅减少了后续计算的代价。
B:复制阶段过滤:在多路连结查询处理过程中,需要对前几路连接处理之后的中间结果进行数据复制操作,将其复制到其他可能会产生连接结果的网格单元中,执行后续连接操作,避免丢失连接结果。在对中间连接结果复制中,仅对涉及跨网格连接对象的中间结果进行复制,从而避免了多余复制。
5)重复避免策略:在两个跨多个网格单元的空间对象进行连接时,仅让这两个相交叠而形成的新的对象的左下角交点所在的网格单元负责输出结果,也就是仅让一个网格单元来负责输出结果,这样就避免了结果的重复输出,减少了处理代价。
图5所示为重复避免的一个例子,其中S集合中的对象s1被投影到其所交叠的网格单元2、3、6、8、9、12,R集合中的对象r1则被投影到网格单元3、6、9、12,r2对象被投影到了8、9、10、11四个网格单元,如果不进行重复避免,在进行连接处理中,网格单元3、6、9、12就会输出相同的连接结果(r1,s1),而网格单元8和9也会输出相同连接结果(r2,s1),显然出现了重复。根据所提出的重复避免策略,如图5中所示,对象交叠部分所形成的对象的左下角(图中P和Q点所示)所在的网格单元负责输出结果,即由网格单元3负责处理输出r1和s1的连接结果(r1,s1),网格单元8负责处理输出r2和s1的连接结果(r2,s1),该策略避免了重复处理和结果的重复输出,降低了后续处理代价。
链式多路空间连接查询Qm=Overlap(R1,R2,R3,...,Rm),根据其定义,可以表示为Qm=Overlap(…Overlap(Overlap(R1,R2),R3),…,Rm),本发明提出的基于Spark的链式多路空间连接查询处理算法的处理流程如图6所示,主要包括以下几个步骤:
A:根据网格划分编码方法对多路连接数据集R1,R2,R3,…,Rm进行投影,并将编码值作为Key值,将每个空间对象的标识及其MBR等属性信息作为Value值,形成一系列的键值对,并分别将数据集R1,R2,R3,…,Rm的投影结果放到弹性分布式数据集RDD1,RDD2,RDD3,…,RDDm中;
B:计算Overlap(R1,R2),即对RDD1和RDD2执行Cogroup操作,将RDD1和RDD2中的数据根据Key值聚集到一起得到RDDnew,利用边界过滤策略对RDDnew进行过滤,去掉不可能有结果的数据对象,然后进行实际空间连接运算,执行重复避免策略,并形成连接中间结果;对连接中间结果执行数据复制操作,形成中间结果数据集RDDresultnew;
C:按照与步骤B相同的计算方法计算RDDresultnew和RDD3之间的连接运算,得到最新的R1,R2,R3的连接中间结果RDDresultnew。采取相同的计算过方法,依次循环计算RDDresultnew与RDD4,与RDD5,…,与RDDm-1的连接运算,最终得到数据集R1,R2,R3,…,Rm-1的连接中间结果数据集RDDresultnew;
D:RDDresultnew与RDDm执行Cogroup操作,生成新的RDDnew,在此基础上进行边界过滤、连接运算处理,并将结果直接输出,形成数据集R1,R2,R3,…,Rm的最终空间连接数据集RDDresultnew,并将结果保存到HDFS文件系统.由于是最后一次空间连接操作,故不再需要进行复制操作。
实施例2:
一种基于Spark的链式多路空间连接查询处理算法,包括如下步骤:步骤1:将整个数据空间划分成许多大小相同的网格单元,并采用Z-order填充曲线技术对每个网格单元进行编码;步骤2:将m(m>2)路空间连接数据集R1,R2,…,Rm中的每个空间对象根据其在数据空间中的位置投影到相应的网格单元,并将投影结果存放到弹性分布式数据集RDD1,RDD2,…,RDDm中。设定循环变量i=2,中间结果数据集RDDresultnew=RDD1;步骤3:如果满足条件i<m,则对两个数据集RDDresultnew,RDDi执行空间连接运算Overlap(RDDresultnew,RDDi),计算过程中,依次进行数据聚集、边界过滤、空间连接计算、重复避免和数据复制等操作,最终形成新的中间结果数据集RDDresultnew,RDDresultnew=Overlap(RDDresultnew,RDDi);步骤4:i=i+1,执行步骤3直到条件i<m不满足为止;步骤5:执行最后一次空间连接运算Overlap(RDDresultnew,RDDm),计算过程中,依次进行数据聚集、边界过滤、空间连接计算,并将结果直接输出,形成最终空间连接结果集合,并保存到HDFS文件系统。本发明是一种基于Spark的链式多路空间连接查询处理算法,在处理效率和减少计算代价方面都有了显著的提高,并具有良好的适应性和扩展性。
实施例3:
一种基于Spark的链式多路空间连接查询处理算法,包括如下步骤:
步骤1:利用网格划分方法,将整个数据空间划分成许多大小相同的网格单元,并采用Z-order填充曲线技术对每个网格单元进行编码;
步骤2:将m(m>2)路空间连接数据集R1,R2,…,Rm中的每个空间对象根据其在数据空间中的位置投影到相应的网格单元,并形成一系列键值对,将投影结果分别存放到弹性分布式数据集RDD1,RDD2,…,RDDm中,设定循环变量i=2,中间结果数据集RDDresultnew=RDD1;
步骤3:如果满足条件i<m,则对两个数据集RDDresultnew,RDDi执行空间连接运算Overlap(RDDresultnew,RDDi)。计算过程中,依次进行数据聚集、边界过滤、空间连接计算、重复避免和数据复制等操作,最终形成中间结果数据集RDDresultnew,即RDDresultnew=Overlap(RDDresultnew,RDDi);
步骤4:i=i+1,执行步骤3直到条件i<m不满足为止;
步骤5:执行最后一次空间连接运算Overlap(RDDresultnew,RDDm),计算过程中,依次进行数据聚集、边界过滤、空间连接计算,并将结果直接输出,形成最终空间连接结果集合,并保存到HDFS文件系统。
进一步的,所述数据划分和编码方法为:采用基于网格的划分方法将整个数据空间划分成n个大小相等的网格单元,采用Z-order填充曲线对网格单元进行编码,空间数据对象根据其位置被投影到各个网格单元,并采用Hash方式将所有网格单元映射给多个Executor执行单元,使得整个处理任务被划分成多个并行的处理任务。
进一步的,所述空间对象投影为:将空间数据对象根据其所在位置映射到相应的网格单元中,设C=(c1,c2,…,cn)代表一个数据空间划分,ci代表每一个网格单元;设R为一类待连接处理的空间对象集合,若一个空间对象u∈R,其MBR与网格单元ci有交叠,所述ci为网格单元的Z-order编码,则将对象u映射到网格单元ci中,并生成相应键值对(ci,u),如果一个空间对象与多个网格单元有交叠,则相应的会生成多个键值对。
进一步的,步骤3具体包括以下步骤:
步骤3-1:计算Overlap(RDDresultnew,RDDi),即对RDDresultnew,RDDi按照Key值执行Cogroup操作,即将RDDresultnew和RDDi中的数据根据Key值聚集到一起得到RDDnew;
步骤3-2:利用过滤策略对RDDnew进行过滤,去掉不可能有结果的数据对,然后进行实际空间连接运算;
步骤3-3:执行重复避免策略,形成连接中间结果,并对连接中间结果执行数据复制操作,最终形成新的中间连接结果数据集RDDresultnew。
进一步的,步骤5包括以下步骤:
步骤5-1:计算Overlap(RDDresultnew,RDDi),即对RDDresultnew,RDDi按照Key值执行Cogroup操作,即将RDDresultnew和RDDi中的数据根据Key值聚集到一起得到RDDnew;
步骤5-2:利用过滤策略对RDDnew进行过滤,去掉不可能有结果的数据对,然后进行实际空间连接运算;
步骤5-3:执行重复避免策略,形成由元组对构成的最终连接结果数据集RDDresultnew,并保存到HDFS文件系统。
进一步的,所述数据复制操作为:对于当前网格单元上的最近一次空间连接运算所生成的中间连接结果集合T中的任一元组t,若t.s为与下一次空间连接运算相关的空间对象,则若t.s与某一网格单元ci存在交叠,则将元组t复制到网格单元ci,并生成相应的键值对(ci,t)。
进一步的,所述过滤策略为:在并行执行连接运算的过程中,采用相应过滤策略,去掉不可能产生连接结果的元组,并仅对可能产生连接结果的元组进行复制。
进一步的,所述过滤策略包括两部分:
边界过滤,所述边界过滤为:在进行连接运算之前,首先统计已经完成的连接中间结果中与后续空间连接相关的空间对象的边界MBR,并利用该MBR来过滤掉后续要连接数据集中与该MBR不相交的空间对象,从而减少后续连接计算代价;
复制阶段过滤,所述复制阶段过滤为:在多路连结查询处理过程中,需要对前几路连接处理之后的中间结果进行数据复制操作,仅将其复制到可能会产生连接结果的其他网格单元中,从而避免连接结果的丢失,在对中间连接结果复制中,仅对包含跨网格连接对象的中间结果进行复制。
进一步的,所述重复避免策略为:在两个跨多个网格单元的空间对象进行连接时,仅让这两个相交叠而形成的新的对象的左下角交点所在的网格单元负责输出结果。
虽然以上描述了本发明的具体实施方式,但是熟悉本领域的研究人员应当理解,这些仅是举例说明,本发明是一种基于Spark的链式多路空间连接查询处理算法,因此举例说明仅仅是为了说明过滤策略、重复避免策略、连接处理流程等的核心思想。在之后可以进行更大规模的实验,并进一步改进相关算法,提高数据投影、复制以及过滤的效果,同时也可以考虑结合索引技术来进一步提高算法的性能,而不背离本发明的原理和实质。本发明的范围仅由所附权利要求书限定。
- 还没有人留言评论。精彩留言会获得点赞!