一种基于随机投影多核学习的手势识别方法与流程
本发明涉及模式识别技术领域,尤其涉及一种基于随机投影多核学习的手势识别方法。
背景技术:
目前,随着科学技术的不断进步,人机交互得到迅速发展,人机交互成为研究者研究的热点之一。人机交互的目标是实现用户与机器之间的自然交流,为用户提供实时、直观的交互体验。由于人与人之间是通过语言、肢体与表情来传递信息,而手势具有自然、直观等特征,因此基于手势识别的人机交互受到了人们越来越多的关注,并在人机交互领域中发挥着越来越重要的作用。手势识别涉及多个学科,例如计算科学、机器学习、模式识别、图像与视频处理等。
手势识别主要分为两种,一种是基于数据手套的手势识别,另外一种是基于视觉的手势识别。基于数据手套的识别最开始是由AT&T的Geimes使用数据手套来检测人手与其关节的空间信息,Virtual Technologie公司的Cyber Glove手套也得到广泛运用,检测手势运动速度、加速度等手势信息,识别率比较高,且实时性比较好。但是,这种交互方式需要佩戴手套等传感设备,识别的手势较少,同时缺乏手势的自然性。
基于视觉的手势识别,无需穿戴设备,操作方便,用户只需进行手势的自然表达,从而进行人与机器的交流,实现了人机交互的直观表示。基于视觉的手势识别主要利用摄像头采集手势的图像视频数据,传输给计算机,通过使用计算机视觉技术进行图像处理,对其中的手势进行识别。但是目前基于视觉的手势识别面临着诸多难点,例如复杂背景、光照等因素的影响,因此设计出简单、实时、有效、方便的手势识别系统是研究者研究的热点问题,也是手势识别发展的必然趋势。
手势识别过程主要包括:手势数据采集、手势分割、特征提取和手势识别等步骤。比较常用的特征有sift(Scale-invariant feature transform)特征、傅里叶描述子、Hu矩和HOG(Histogram of Oriented Gradient)特征等。采用单一的特征,往往存在局限性(参见文献“张汗灵,李红英,周敏.融合多特征和压缩感知的手势识别[J].湖南大学学报(自科版),2013,40(3):87-92.”和“翁汉良,战荫伟.基于视觉的多特征手势识别[J].计算机工程与科学,2012,34(2):123-127.”)。
基于稀疏表示的手势识别算法(参见文献“张勤,赵健,孙道达,等.一种基于稀疏表示的手势识别算法[J].西北大学学报自然科学版,2013,43(6):881-884.”和“宁亚楠,李定主,韩燮,等.基于稀疏表示的手势识别方法[J].计算机工程与设计,2016(9):2548-2552.”)构建稀疏冗余字典,根据最小残差实现手势识别,相对速度慢,往往不能够达到实时性的效果,同时稀疏编码往往忽视局部信息。
采用传统的支持向量机的方法进行识别,由于每个特征对于最终的识别结果产生的影响不同;如果采用单一的核矩阵进行识别,往往忽视了特征之间的区分性。同时使用核函数往往采用经验法,缺乏统一的标准,得到的结果往往不一致。
技术实现要素:
为了克服现有技术存在的缺点与不足,本发明提供一种基于随机投影多核学习的手势识别方法,解决目前传统的手势识别方法中存在的背景干扰、复杂度较高、耗时长和识别率低等问题。
为解决上述技术问题,本发明提供如下技术方案:一种基于随机投影多核学习的手势识别方法,包括如下步骤:
S1、采集手势图像,并对图像进行预处理,预处理包括手势定位和手势分割;
S2、对预处理分割后的手势提取sift特征;
S3、采用k-means算法训练学习字典,然后使用迭代字典更新算法更新字典;
S4、对手势图像进行空间金字塔划分,并对在每层空间金字塔中对手势图像的sift特征,根据训练得到的字典进行编码,得到特征向量,并对特征向量进行级联,接着使用随机投影进行对特征向量降维;
S5、对每层金字塔降维后的特征向量学习核矩阵,学习核矩阵方法采用多核模型学习算法进行分类学习,得到最优核矩阵组合系数。
进一步地,所述步骤S1中预处理,具体为:
S11、采用Grayworld光线补偿算法,降低光照环境对于后续手势分割的影响;
S12、采用HSV和Ycbcr混合空间模型方法进行肤色检测,进一步定位手势区域,在手势区域内提取手势的最小外接矩形;
S13、在最小外接矩形中,采用形态学的膨胀与腐蚀操作,对手势进行分割处理以及平滑手势的边缘;最后在最小外接矩形内提取手势;
进一步地,所述步骤S11中Grayworld光线补偿算法具体为:
分别计算手势图像R、G、B颜色分量的平均值ravg、gavg、bavg,定义图像平均灰度值为grayavg=(ravg+gavg+bavg)/3,并定义R、G、B三个通道的增益系数ar、gr、br为:
ar=grayavg/ravg
gr=grayavg/gavg
br=grayavg/bavg
调整每个像素点c的R、G、B颜色分量为:
c(R)=c(R)*ar
c(G)=c(G)*ag
c(B)=c(B)*ab
最终将R、G、B颜色分量调整到可视范围内。
进一步地,所述步骤S2,具体为:
S21、对分割后的手势生成尺度空间,寻找空间尺度极值,并定位特征点;
S22、利用特征点周围像素梯度m(x,y)和方向θ(x,y),为每一个特征点赋值方向,然后计算其sift特征:
θ(x,y)=arctan((L(x,y+1)-L(x,y-1))/(L(x+1,y)-L(x-1,y)))
最后,得到的特征为X=[x1,...,xM]T∈RM×D,xi∈R1×D,M为特征点的个数,D为sift特征的维数。
进一步地,所述步骤S3具体为:
S31、采用k-means算法,生成得到字典B=[b1,b2,...,bN]∈RD×N,字典大小为D,视觉词汇个数为N;
S32、使用迭代字典更新算法,使用局部约束线性编码准则,每次加载训练集中的部分特征描述符不断更新字典。
进一步地,所述步骤S4具体为:
S41、对手势图像进行空间金字塔划分,并在每层空间金字塔中对手势图像的特征,根据训练得到的字典进行编码,得到特征向量;
S42、将得到的特征向量进行级联,并采用随机投影,使得每层特征向量与字典大小保持一致。
进一步地,所述步骤S41具体为:
对分割后的手势图像进行空间金字塔划分,按照手势图像两个坐标方向的2指数倍进行划分,分为L层,其中l=0,...L,第l=0层是将手势图像水平方向分为2l=20=1块,竖直方向分为2l=20=1块,最终第l=0层手势图像被划分为2l*2l=1块,其他层数以此类推;
对每层的每块图像块进行局部约束线性编码,公式为:
其中,ci是sift特征描述符xi的编码;⊙为逐元素相乘;表示分配的自由度与sift特征描述符的每个基向量的相似性成正比的局部适配器,其中dist(xi,B)=[dist(xi,b1),...,dist(xi,bM)]T,dist(xi,bj)表示xi与bj之间的欧式距离;参数σ控制局部适配器权重衰减的速度,同时从dist(xi,B)减去max(dist(xi,B)),将di标准化到范围(0,1]间;约束项1Tci=1确保局部约束线性编码的平移不变性。
进一步地,所述步骤S5具体为:
S51、采用非线性径向基核函数Kl(xi,xj)=exp(-γlf(xi,xj)),其中γl取所有训练数据距离的平均值,是第l层空间金字塔的特征向量xi和xj映射到φ特征空间后向量的点积,即对每层金字塔学习一个核矩阵;
S52、根据核矩阵,采用多核模型学习算法得到最优核矩阵组合系数,并得到最终分类的核矩阵在支持向量机的基础上,利用训练集学习得到最优的核矩阵系数,目标函数定义为:
s.t.yi(wtφ(xi)+b)≥1-ξi,ξ≥0,d≥0,Ad≥p
其中,C为惩罚项,Ad≥p为限制项,此时将核矩阵改写为:
采用投影梯度法求解最小的T(d),即的求解是这个优化问题的关键,因此将问题进行转化求解,得到其对偶式为:
s.t.0≤α≤C,1tYα=0
其中,Y是标记训练数据类别的对角矩阵,Kl为核矩阵K的第l列,α与支持向量有关;根据强对偶的原理,对于任意系数d,都有T(d)=W(d),记W取最大值时,α的值为α*,并且具有唯一性;由于核矩阵都是严格可微的,因此W取取最大值时也是可微的,因此有:
最终得到系数d,再根据训练的数据求解分类器参数a和b,得到多核模型分类器
采用上述技术方案后,本发明至少具有如下有益效果:
(1)本发明采用混合空间模型进行肤色检测以及形态学处理,降低了背景对于手势分割的影响;同时使用两阶段字典训练方法,先使用k-means算法训练字典,然后使用迭代字典更新算法,使用局部约束线性编码准则,进一步提高识别效率;
(2)本发明采用空间金字塔划分技术,加入空间信息,使用局部约束线性编码,避免了稀疏编码对于局部信息的忽视,同时对高层的金字塔特征进行随机投影,降低了计算的复杂度;使用多核学习,优化多核参数,得到分类能力最强的核矩阵,提高手势识别的效率。
附图说明
图1是本发明一种基于随机投影多核学习手势识别方法流程图;
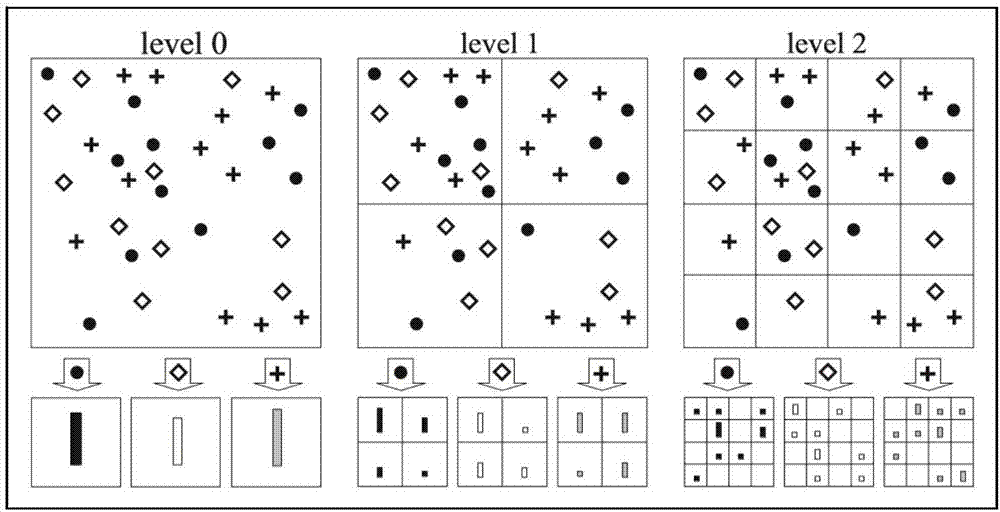
图2是本发明一种基于随机投影多核学习手势识别方法的图像空间金字塔划分方法示意图;
图3是本发明一种基于随机投影多核学习手势识别方法的局部约束线性编码示意图。
具体实施方式
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互结合,下面结合附图和具体实施例对本申请作进一步详细说明。
如图1所示,本实例给出了一种基于随机投影多核学习的手势识别方法,主要包括以下步骤:
S1采集手势图像,并对图像进行预处理,预处理包括手势定位和手势分割,具体过程如下所示,具体过程如下所示:
S1.1采用Grayworld光线补偿算法,降低光照环境对于后续手势分割的影响;分别计算手势图像三个颜色分量的平均值ravg,gavg,bavg,定义图像平均灰度值为grayavg=(ravg+gavg+bavg)/3,并定义R、G、B三个通道的增益系数ar、gr、br为调整每个像素点c的R、G、B分量分别为最终将三者调整到可视范围内。
S1.2采用HSV和Ycbcr混合空间模型来进行肤色检测,手势定位,由于肤色具有分布聚类性,范围紧密,首先将RGB图像分别转换到HSV空间和Ycbcr空间,通过实验对比,本发明设定的HSV空间和Ycbcr空间阈值范围是H∈[0.75,1),S∈[0.1,0.7],V∈[0.4,1),cb∈[90,140],cr∈[130,255]。肤色检测后对手势进行定位,由于存在背景噪声等因素的影响,采用形态化预处理,消除满足阈值条件的小面积对象,本发明设置删除在8邻域小于1000的面积对象,降低噪声的影响。同时提取手势的最小外接矩阵,扫描整个二值化图像,找到满足条件的横坐标与纵坐标的最大与最小值xmin,xmax,ymin,ymax,分别向四个方向扩展20个像素值,即xmin-20,xmax+20,ymin-20,ymax+20,可得到手势的最小外接矩阵。最小外接矩形为后续的特征提取,编码,识别等提供了依据。
S1.3由于粗分割,再利用形态学的膨胀与腐蚀操作,对手势进行进一步分割;平滑手势的边缘。最后在最小外接矩形内提取手势。
S2提取分割后手势的sift特征,具体过程如下所示:
S2.1提取sift特征。对分割后的手势生成尺度空间,建立图像高斯金字塔,比较每个像素点与其所有相邻点,是否比其图像域和尺度域相邻点的大或者小,寻找空间尺度极值,并定位特征点,去除其中不稳定边缘点与低对比度的关键点;
S2.2利用特征点周围像素梯度m(x,y)和方向θ(x,y),为每一个特征点赋值方向,然后计算其sift特征;
θ(x,y)=arctan((L(x,y+1)-L(x,y-1))/(L(x+1,y)-L(x-1,y)))
最后,得到的特征为X=[x1,...,xM]T∈RM×D,xi∈R1×D,M为特征点的个数,D为sift特征的维数。
S3采用k-means算法训练学习字典,然后使用迭代字典更新算法更新字典,具体过程如下所示:
S3.1使用k-means算法,生成得到字典B=[b1,b2,...,bN]∈RD×N,字典大小为D,视觉词汇个数为N;
S3.2使用迭代字典更新算法,使用局部约束线性编码准则,每次加载训练集中的部分特征描述符不断更新字典。根据公式
由步骤S3.1得到的字典B,考虑到所有的训练描述符的数量比较多,因此每次迭代时,遍历所有的训练描述符,只取其中小部分描述符,求解上述公式,利用当前的字典B,进行特征选择,获取相应的局部约束线性编码ci。每次只保留字典的一组基B,并且其对应权重大于事先定义的常量,同时根据无局部性受限参数,重新拟合。最后将单位圆外的字典基投影到单位圆上,接着使用梯度下降方法更新字典中保留的基B。
S4对手势图像进行空间金字塔划分,并在每层空间金字塔中对手势图像的特征,根据训练得到的字典进行编码,得到特征向量,并对特征向量进行级联,接着使用随机投影进行降维,具体过程如下所示:
S4.1对分割后的手势图像进行金字塔划分,如图2所示,按照手势图像两个坐标方向的2指数倍进行划分,分为L层,其中l=0,...L,第l=0层是将手势图像水平方向分为2l=20=1块,竖直方向分为2l=20=1块,最终第l=0层手势图像被划分为2l*2l=1块,后面以此类推,第l=1层分为4块,第l=2层取16块。本发明共取L=3层。然后对每块图像块进行局部约束线性编码,如图3所示,其目标函数定义为:
其中ci是sift特征描述符xi的编码,⊙表示逐元素相乘,表示分配的自由度与sift特征描述符的每个基向量的相似性成正比的局部适配器,dist(xi,B)=[dist(xi,b1),...,dist(xi,bM)]T。dist(xi,bj)表示xi与bj之间的欧式距离,参数σ控制局部适配器权重衰减的速度。同时从dist(xi,B)减去max(dist(xi,B)),将di标准化到范围(0,1]间。约束项1Tci=1确保局部约束线性编码的平移不变性。上式中的局部约束线性编码在l0范数下不满足稀疏性,但是求得的解中只有少部分的显著值,因此可以通过设置阈值,使得编码满足稀疏性。
局部约束线性编码学习得到的系数,有着较好的区分度。系数的相似性与输入向量的相似性成正比,输入向量相似度越高,学习得到的系数就越相似,输入向量相似度越低,学习得到的系数相似度就越低。因此可以得到识别性能更好的编码效果。
S4.2将每层的图像块进行局部约束线性编码后得到的特征向量进行级联,那么每层的特征转化为一个向量表示,由于金字塔第l=1层和第l=2层,相对第l=0层的维度较高,为了降低后续计算的复杂度,在本发明中采用随机投影,使得金字塔第l=1层和第l=2层特征向量与训练字典大小保持一致,即与第l=0层特征向量的维度保持一致;随机矩阵独立于训练样本,将向量空间的点从高维映射到随机选择的低维空间中,则向量空间之间点的距离保持不变,有效的降低特征维度,也不会造成特征的曲解。若金字塔每层得到的特征向量为使用随机投影后,使用公式
将高维的特征映射到低维空间,可以得最终的特征随机矩阵R受限满足等距属性(restrictedisometry,RIP)。随机投影由Johnson-Lindenstrauss引理首次提出,认为将向量空间的点从高维映射到随机选择的低维空间中,则向量空间之间点的距离保持不变。本发明采用随机高斯矩阵,矩阵元素ri,j=N(0,1),并将各个行变量分别进行标准正交化以及归一化。
S5对每层金字塔最终的特征向量学习核矩阵,采用多核模型学习算法进行分类学习,得到最优核矩阵组合系数,具体过程如下所示:
S5.1使用多核学习方法,采用非线性径向基核函数Kl(xi,xj)=exp(-γlf(xi,xj)),其中γl取所有训练数据距离的平均值,是第l层空间金字塔的特征向量xi和xj映射到φ特征空间后向量的点积,即对每层金字塔学习一个核矩阵。由于每个核矩阵的区分能力不同,因而需要在求解传统的支持向量机问题上,优化学习系数,得到最终分类器的核矩阵使得识别能力达到最优状态。
S5.2采用通用多核学习算法学习得到最优核矩阵组合系数,得到最终分类的核矩阵在支持向量机的基础上,利用训练集学习得到最优的核矩阵系数,目标函数定义为
s.t.yi(wtφ(xi)+b)≥1-ξi,ξ≥0,d≥0,Ad≥p
其中,C为惩罚项,Ad≥p为限制项,此时将核矩阵改写为
采用投影梯度法求解最小的T(d),即的求解是这个优化问题的关键,因此将问题进行转化求解,得到其对偶式为
s.t.0≤α≤C,1tYα=0
其中Y是标记训练数据类别的对角矩阵,Kl为核矩阵K的第l列,α与支持向量有关。根据强对偶的原理,对于任意系数d,都有T(d)=W(d)。记W取最大值时,α的值为α*,并且具有唯一性。由于核矩阵都是严格可微的,因此W取最大值时也是可微的。因此有
最终可以得到系数d,再根据训练的数据求解分类器参数a和b,得到多核模型分类器
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解的是,在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种等效的变化、修改、替换和变型,本发明的范围由所附权利要求及其等同范围限定。
- 还没有人留言评论。精彩留言会获得点赞!