云环境下MapReduce结果正确性保障机制的制作方法
本发明属于系统安全技术领域,尤其涉及一种云环境下MapReduce结果正确性保障机制。
背景技术:
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。在Google,MapReduce用在非常广泛的应用程序中,包括"分布grep,分布排序,web连接图反转,每台机器的词矢量,web访问日志分析,反向索引构建,文档聚类,机器学习,基于统计的机器翻译等。然而,在开放系统中,MapReduce面临着数据处理服务诚信问题,因为服务提供商可能来自不同的管理域,他们并不总是可信的。目前,已经有很多恶意工作者检测技术被用于MapReduce并行计算模型中。但是,这些恶意工作者检测技术可以有效地检测懒惰或者非勾结恶意工作者,对于相互勾结的恶意工作者的检测效率却相对较低。云环境提供了一个全方位的,高效的并且检测能力极强的安全防护系统,利用云环境中的并行处理、海量数据存储、分布式计算技术,完成恶意工作者的检测。借助大量的冗余计算资源,利用多次复制任务分配给不同工作者的方法,或引入可信工作者,通过概率性的验证,从而找出恶意工作者,保证工作者集群模块的良性运行,提高整个系统的安全性与效率。现有的恶意工作者检测方式主要有两种:一种是利用大量的冗余资源进行多副本任务分别进行,然后根据投票的方法与思想,将返回结果相同的工作者归为一组,最后选取工作者数量最多的组所返回的结果作为可信结果。这种方式不但占用系统大量的计算资源和系统存储空间,影响工作者集群模块处理其他任务的速度与效率,还造成了极大的系统开销,不能识别出恶意工作者,并且对于工作者集群模块中恶意工作者比例较高的情况很可能会出现判断出错的情况;另一种是检查点协议验证,其主要形式如水印或探针等。根据用户提交任务的特征、类型等相关信息,在任务数据中以一定比例添加工作者无法区分或识别的水印或者探针,根据工作者所返回的结果中水印是否完整或探针数量是否正确来判断工作者任务处理的正确性,但是添加水印或探针并恢复需要增加系统额外的开销,同时只有特定的数据类型才能添加水印或探针,因此,该方法并不具有普适性。同时,随着全球信息产业在不断融合发展,网络资源与数据规模也在不断增长,开放式海量数据处理的计算正确性已经越来约受到重视,所接触的两种恶意工作者检测方式已经无法满足当前密集型海量数据处理的需求,数据处理的类型也有一定局限性,尤其是在云计算与大数据高速发展的今天,迫切需要提出一种高效地云环境下MapReduce结果正确性保障机制来应对更加强大的敌手。
综上所述,现有技术存在的问题是:现有技术的敌手模型已经不能满足当今时代的背景,且由于现有的利用多副本检测恶意工作者技术,其主机不能直接判断任务结果的正确性,所以需要多次重复计算同一任务,造成极大的系统开销且影响工作者集群模块处理其他任务的速度与效率,而且不能确定地识别出恶意工作者,容易判断出错;而添加水印或探针技术,虽然可以判断出恶意工作者,但是添加水印或探针需要增加系统额外的开销,同时只有特定的数据类型才能添加水印或探针,因此,并不能广泛地应用。
技术实现要素:
针对现有技术存在的问题,本发明提供了一种云环境下MapReduce结果正确性保障机制。
本发明是这样实现的,一种云环境下MapReduce结果正确性保障机制,所述云环境下MapReduce结果正确性保障机制包括:
用户端,用于将本地数据文件上传到分布式文件存储管理模块,并且将数据处理任务递交给系统主机,同时得到任务处理结果;
分布式文件存储管理模块,与用户端,系统主机和工作者集群模块连接,用于提供数据分布式存储服务,并且代替用户存储和管理数据,同时为系统主机提供数据的分块与调度服务;
系统主机,与用户端,分布式文件存储管理模块和工作者集群模块连接,用于采用恶意工作者检测技术,剔除恶意工作者并更新工作者集群模块;
工作者集群模块,与系统主机和分布式文件存储管理模块连接,用于为分布式文件存储管理模块提供存储资源,同时为系统主机提供计算服务。
进一步,所述用户端分别将文件数据与处理任务递交到分布式文件存储管理模块和系统主机,工作者集群模块中的工作者在执行任务时只能接收到相应的任务与数据位置,无法获取整个任务信息和文件数据。
进一步,所述分布式文件存储管理模块将工作者集群模块提供的存储资源划分成固定大小的存储块,同时将用户上传数据的位置信息递交给系统主机。
进一步,所述系统主机将每个任务分配到两个不同的工作者进行处理,并将结果进行比较分析,定位恶意工作者。
进一步,所述工作者集群模块并行高效的执行系统主机分配的任务,拥有巨量的冗余计算资源。
本发明的另一目的在于提供一种所述云环境下MapReduce结果正确性保障机制的云环境下MapReduce结果正确性保障方法,所述云环境下MapReduce结果正确性保障方法包括以下步骤:
步骤一,用户将本地数据文件上传到分布式文件存储管理模块,并且将数据处理任务递交给系统主机,分布式文件存储管理模块将数据文件存入工作者集群模块提供的存储块中并将数据存储位置递交给系统主机,系统主机初始时根据用户递交的任务随机选取两个工作者并将任务及数据位置分别发送给这两个工作者;
步骤二,工作者执行完任务后,将结果存入本地磁盘并将结果的哈希值递交给系统主机,系统主机比较两个工作者返回的哈希值,如果结果一致,则暂时信任该结果,如果结果不一致,则重新选取两个工作者执行此任务;
步骤三,系统主机更新每个工作者的可信值与两个工作者间的权重值,利用正确性证明图定位恶意工作者,同时根据可信值对工作者进行排序并划分为可信组与不可信组;
步骤四,系统主机分别在可信组与不可信组中选取一个工作者执行相同的任务,重复步骤二,三直至用户所有任务完成。
进一步,工作者集群模块提供恶意工作者检测服务,然后恶意工作者检测实施的步骤为:
步骤一,一对工作者执行完一个任务时,系统主机比较返回的结果并记录是否一致,然后建立工作者集群模块的正确性证明图G,每个顶点代表一个工作者Vi并赋有初始值为1的可信值Ti,可信值Ti是工作者Vi与集群中所有工作者返回结果一致的次数占它所完成任务次数的比例,顶点间的边代表相互间的一致关系并赋有初始值为-1的权重Wi,j,权重值Wi,j是工作者Vi与Vj之间返回结果一致的次数占它们共同完成任务次数的比例;
步骤二,在正确性证明图G中,所有顶点个数不少于2且顶点间边的权重值为1的完全子图构成一个一致团;
步骤三,假设工作者集群模块中共有N个工作者M个恶意工作者且恶意工作者的数量少于诚实工作者,经过K轮随机选取工作者后计算新的Ti与Wi,j并更新图G,删除所有权重值Wi,j小于1的边后将所有孤立的工作者确定为恶意工作者并移出集群;
步骤四,利用Bron-Kerbosch算法寻找图G中所有工作者数量大于F的一致团,由于我们假设可靠工作者的数量大于恶意工作者,F可暂时设定为然后将不属于任何规模大于F一致团的工作者判定为恶意工作者并移出集群。
进一步,工作者选取方法,然后工作者选取实施的步骤为:
步骤一,根据K轮随机选取工作者后更新的Ti对工作者由高到低排名,将前个工作者划分到可信组R中,剩下的工作者划分到不可信组UR中;
步骤二,选取工作者对时先在不可信组UR中随机选取一个工作者Vi,然后在可信组R中选取另一个工作者;
步骤三,若可信组R中存在与工作者Vi之间边的权重值Wi,*为-1的工作者,即未与Vi一同执行过任务,从中随机选取一个与Vi执行任务;
步骤四,若可信组R中不存在与工作者Vi之间边的权重值Wi,*为-1的工作者,即均与Vi一同执行过任务,此时,若存在与工作者Vi之间边的权重值Wi,*为1的工作者,从中随机选取一个与Vi执行任务,否则,重新在不可信组UR中随机选取另一个工作者Vj并重复以上步骤。
本发明的优点及积极效果为:首先在恶意工作者检测技术方面,我们采用基于带权重正确性证明图的寻找一致团方法,区别于传统的概率性检测方法,利用工作者处理任务的历史日志,在不增加额外开销的情况下,以完全确定地方式快速准确定位出恶意工作者;然后为了提高定位恶意工作者地速度,我们将工作者集群划分可信与不可信组,利用将双副本任务分别分配给其中可能存在不一致关系的工作者的分配策略,提高检测到工作者间不一致关系的概率;最后,我们将确定性的一致团检测技术与概率性提高检测到不一致关系的分配策略有机地结合起来,从而提高恶意工作者的检测效率,保证用户任务的正确执行。
附图说明
图1是本发明实施例提供的云环境下MapReduce结果正确性保障机制结构示意图;
图中:1、用户端;2、分布式文件存储管理模块;3、系统主机;4、工作者集群模块。
图2是本发明实施例提供的云环境下MapReduce结果正确性保障方法流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
下面结合附图对本发明的应用原理作详细的描述。
如图1所示,本发明实施例提供的云环境下MapReduce结果正确性保障机制包括:用户端1、分布式文件存储管理模块2、系统主机3、工作者集群模块4。
用户端1,要将将本地数据文件上传到分布式文件存储管理模块2,将数据处理任务递交给系统主机3,同时此后能接收任务处理结果的实体。
分布式文件存储管理模块2,与用户端1、系统主机3和工作者集群模块4连接,提供数据分布式存储服务,并且代替用户端1存储和管理数据,同时为系统主机3提供数据的分块与调度服务。理论上讲,为了提高用户数据安全性,分布式文件存储管理模块2管理工作者集群模块4的存储资源,同时控制数据的访问权限。
系统主机3,与用户端1、分布式文件存储管理模块2和工作者集群模块4连接,用于采用恶意工作者检测技术,剔除恶意工作者并更新工作者集群模块。为了提高准确性和检测速度,利用正确性证明图寻找一致团与双副本任务分配相结合的方法,快速准确地定位恶意工作者。
工作者集群模块4,与分布式文件存储管理模块2和系统主机3连接,用于为分布式文件存储管理模块2提供存储资源,同时为系统主机3提供计算服务。为了适应大数据任务的需求,集群中巨量工作者是来自不同区域的服务器。
如图2所示,本发明实施例提供的云环境下MapReduce结果正确性保障方法包括以下步骤:
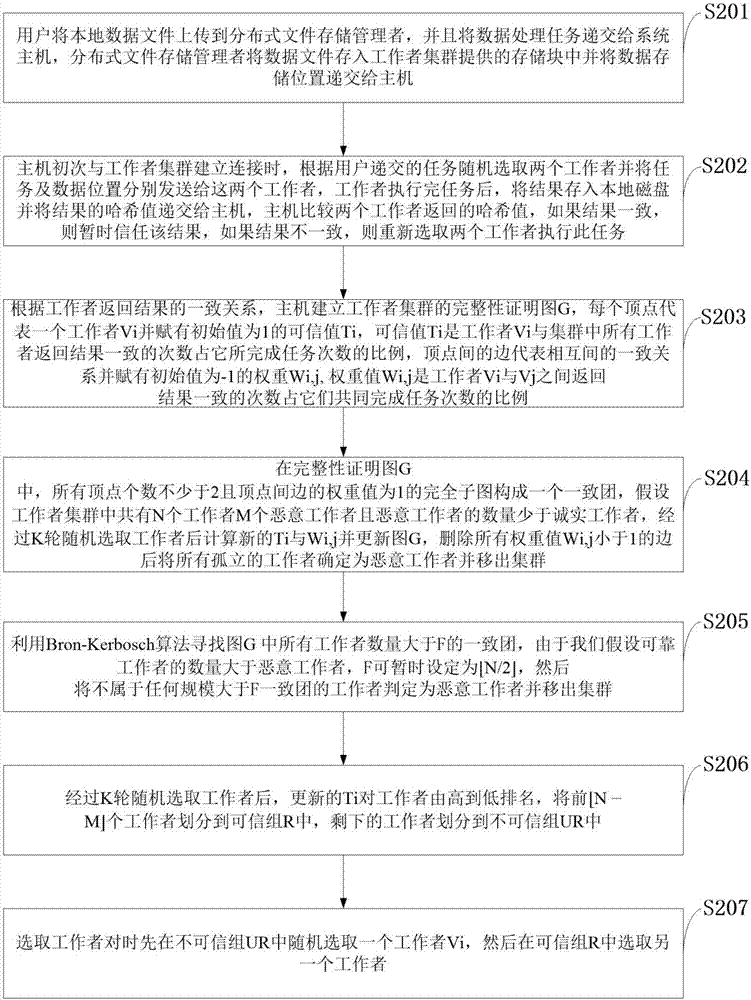
S201:用户将本地数据文件上传到分布式文件存储管理模块,并且将数据处理任务递交给系统主机,分布式文件存储管理模块将数据文件存入工作者集群模块提供的存储块中并将数据存储位置递交给系统主机;
S202:系统主机初次与工作者集群模块建立连接时,根据用户递交的任务随机选取两个工作者并将任务及数据位置分别发送给这两个工作者,工作者执行完任务后,将结果存入本地磁盘并将结果的哈希值递交给系统主机,系统主机比较两个工作者返回的哈希值,如果结果一致,则暂时信任该结果,如果结果不一致,则重新选取两个工作者执行此任务;
S203:根据工作者返回结果的一致关系,系统主机建立工作者集群模块的正确性证明图G,每个顶点代表一个工作者Vi并赋有初始值为1的可信值Ti,可信值Ti是工作者Vi与集群中所有工作者返回结果一致的次数占它所完成任务次数的比例,顶点间的边代表相互间的一致关系并赋有初始值为-1的权重Wi,j,权重值Wi,j是工作者Vi与Vj之间返回结果一致的次数占它们共同完成任务次数的比例;
S204:在正确性证明图G中,所有顶点个数不少于2且顶点间边的权重值为1的完全子图构成一个一致团,假设工作者集群模块中共有N个工作者M个恶意工作者且恶意工作者的数量少于诚实工作者,经过K轮随机选取工作者后计算新的Ti与Wi,j并更新图G,删除所有权重值Wi,j小于1的边后将所有孤立的工作者确定为恶意工作者并移出集群;
S205:利用Bron-Kerbosch算法寻找图G中所有工作者数量大于F的一致团,由于我们假设可靠工作者的数量大于恶意工作者,F可暂时设定为然后将不属于任何规模大于F一致团的工作者判定为恶意工作者并移出集群;
S206:经过K轮随机选取工作者后,更新的Ti对工作者由高到低排名,将前个工作者划分到可信组R中,剩下的工作者划分到不可信组UR中;
S207:选取工作者对时先在不可信组UR中随机选取一个工作者Vi,然后在可信组R中选取另一个工作者;
如果可信组R中存在与工作者Vi之间边的权重值Wi,*为-1的工作者,即未与Vi一同执行过任务,从中随机选取一个与Vi执行任务;
如果可信组R中不存在与工作者Vi之间边的权重值Wi,*为-1的工作者,即均与Vi一同执行过任务,此时,若存在与工作者Vi之间边的权重值Wi,*为1的工作者,从中随机选取一个与Vi执行任务,否则,重新在不可信组UR中随机选取另一个工作者Vj并重复该步骤。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!