基于图像的物体识别方法与流程
本发明涉及一种基于图像的物体识别方法。
背景技术:
近些年来,深度卷积神经网络在物体识别,物体定位和图像分割领域已经取得了重大的进展。通过基于深度卷积神经网络的物体识别算法,在个别任务上,机器的识别准确率甚至已经超过了人类。
另外一些算法,在现有技术中公开的r-cnn算法、fasterr-cnn算法、yolo(youonlylookonce)算法、ssd算法以及r-fcn算法在物体定位和图像分割领域也取得很大的成功,得到了较高的准确率。
然而这些方法普遍存在识别物体种类较少(20~80类),以及对于新的物体种类,需要大量带标签的训练集,花费大量时间重新训练神经网络,才能达到识别的效果。此外,绝大部分物体定位和识别算法缺乏对同类物品中不同个体的区分能力。
因此存在对如下的物体识别方法的需求,该方法无需重新训练神经网络,只需通过较为简单的步骤,即可识别新的物体。此外,该方法还需要具有识别精度高,定位准确,扩展性强,可快速扩展物体种类,区分物体个体差异强的特点。
技术实现要素:
本发明的目的旨在解决现有技术中存在的上述问题和缺陷的至少一个方面。
在本发明的一个方面中,提供一种基于图像的物体识别方法,所述方法包括:
训练过程,所述训练过程用于建立第一数据库和第二数据库,所述第一数据库包括用于描述多个物体形状的第一特征向量,所述第二数据库包括用于描述多个物体类别的第二特征向量;以及
识别过程,所述识别过程包括如下的步骤:
s21:将包含物体的图片输入到深度卷积神经网络中;
s22:在图片上生成至少一个候选框,对至少一个候选框中的每个候选框对应的特征映射图进行池化处理以得到用于每个候选框的第三特征向量;
s23:将第三特征向量与第一数据库中的第一特征向量进行比对,计算两个向量之间的相关系数,在相关系数大于或等于特定阈值的情况下,将该第三特征向量所对应的候选框选定为有效候选框;
s24:将有效候选框中的图像输入到分类神经网络中以获取第四特征向量;
s25:基于第四特征向量、第二特征向量和第二数据库,执行k最近邻分类算法(knn)以识别出物体的类别。
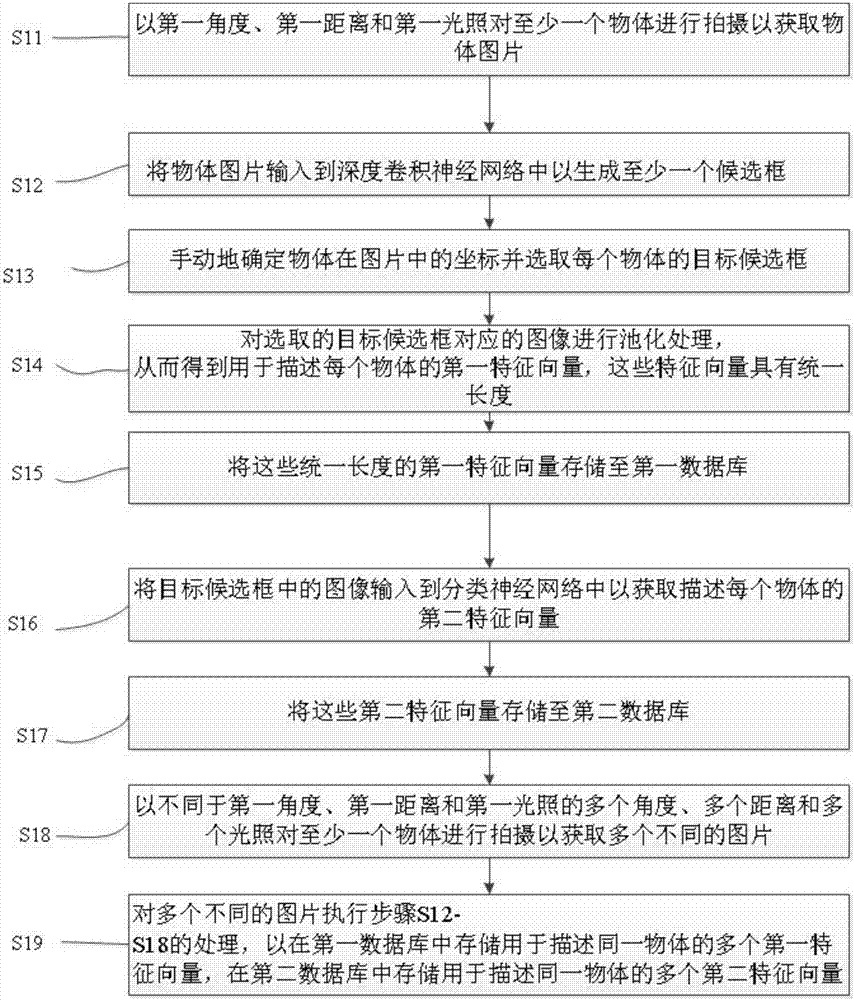
在根据本发明的一个优选实施例中,所述训练过程包括如下的步骤:
s11:以第一角度、第一距离和第一光照对至少一个物体进行拍摄以获取物体图片;
s12:将物体图片输入到深度卷积神经网络中以生成至少一个候选框;
s13:手动地确定物体在图片中的坐标并选取每个物体的目标候选框;
s14:对选取的目标候选框对应的图像进行池化处理,从而得到用于描述每个物体的第一特征向量,这些特征向量具有统一长度;
s15:将这些统一长度的第一特征向量存储至第一数据库;
s16:将目标候选框中的图像输入到分类神经网络中以获取描述每个物体的第二特征向量;
s17:将这些第二特征向量存储至第二数据库;
s18:以不同于第一角度、第一距离和第一光照的多个角度、多个距离和多个光照对至少一个物体进行拍摄以获取多个不同的图片:以及
s19:对多个不同的图片执行步骤s12-s18的处理,以在第一数据库中存储用于描述同一物体的多个第一特征向量,在第二数据库中存储用于描述同一物体的多个第二特征向量。
在根据本发明的一个优选实施例中,在步骤s21中使用的深度卷积神经网络是faster-rcnn网络,在步骤s22中使用区域生成网络(regionproposalnetwork)生成至少一个候选框,进行的池化处理是regionofinterestpooling处理,以及在步骤s24中使用的分类神经网络是卷积神经网络(cnn)。
在根据本发明的一个优选实施例中,在步骤s12中使用的深度卷积神经网络是fast-rcnn网络,在步骤s14中进行的池化处理是regionofinterestpooling处理,以及在步骤s16中使用的分类神经网络是卷积神经网络(cnn)。
在根据本发明的一个优选实施例中,所述方法还包括如下的步骤:在步骤s23之后,执行非极大值抑制算法以进一步筛选有效候选框以将筛选出的有效候选框用在步骤s24中。
在根据本发明的一个优选实施例中,进行非极大值抑制所用的阈值位于0至0.6的范围内。
在根据本发明的一个优选实施例中,所述相关系数是欧式距离、余弦距离或皮尔森相关系数。
在根据本发明的一个优选实施例中,所述特定阈值位于0.5至1的范围之内。
在根据本发明的一个优选实施例中,cnn网络基于squeezenet模型、vgg模型和resnet模型中的任一种。
在根据本发明的一个优选实施例中,k最近邻分类算法是基于投票委员会的k最近邻分类算法。
在根据本发明的物体识别方法中,在识别过程中,首先,通过深度卷积神经网络对图片中的候选框中的图像的特征进行提取,以得到第三特征向量,将该第三特征向量与第一特征向量进行对比,并计算相关系数,通过一阈值来过滤不匹配的目标框,例如从图片中去除表示不具有特定形状的候选框,例如表示图片的背景的候选框,从而初步地筛选出在其中包含了已知形状的物体的候选框,即,有效候选框(boundingbox)。然后,将该有效候选框所对应的图像送入分类神经网络中以进一步得到候选框中的第四特征向量。最后基于第四特征向量和第二数据库(即,分类数据库)来执行第二级分类处理,从而对物体进行类别细分。在该识别过程中,通过初步筛选和第二级分类处理可以进行多级特征分类,从而提高分类和识别精度。
附图说明
图1是根据本发明的示例性实施例的一种物体识别方法的识别过程的流程图。
图2是是根据本发明的示例性实施例的一种物体识别方法的物体训练过程的流程图
具体实施方式
下面通过实施例,并结合附图,对本发明的技术方案作进一步具体的说明。下述参照附图对本发明实施方式的说明旨在对本发明的总体发明构思进行解释,而不应当理解为对本发明的一种限制。
另外,在下面的详细描述中,为便于解释,阐述了许多具体的细节以提供对本披露实施例的全面理解。然而明显地,一个或多个实施例在没有这些具体细节的情况下也可以被实施。
根据本发明的总的发明构思,本发明提供一种基于图像的物体识别方法,所述方法包括:训练过程以及识别过程。所述训练过程用于建立第一数据库和第二数据库,所述第一数据库包括用于描述多个物体形状的第一特征向量,所述第二数据库包括用于描述多个物体类别的第二特征向量。
如图1所示,所述识别过程包括如下的步骤:
s21:将包含物体的图片输入到深度卷积神经网络中;
s22:在图片上生成至少一个候选框,对至少一个候选框中的每个候选框对应的特征映射图进行池化处理以得到用于每个候选框的第三特征向量;
s23:将第三特征向量与第一数据库中的第一特征向量进行比对,计算两个向量之间的相关系数,在相关系数大于或等于特定阈值的情况下,将该第三特征向量所对应的候选框选定为有效候选框;
s24:将有效候选框中的图像输入到分类神经网络中以获取第四特征向量;
s25:基于第四特征向量、第二特征向量和第二数据库,执行k最近邻分类算法(knn)以识别出物体的类别。
在根据本发明的物体识别方法中,同一物体在第一数据库中通过第一特征向量表示,以明确该物体的形状,在第二数据库中通过第二特征向量表示,以明确该物体的具体类别,例如在第一数据库中,某一第一特征向量表示杯子,那么在第二数据库中,某一第二特征向量可以表示具有某种颜色的杯子,归属于某用户的杯子等,因此多个第二特征向量可以表示不同颜色,归属于不同用户的杯子,但是应当理解具体的形状属性和类别属性可以根据实际需要而确定。
在根据本发明的物体识别方法中,在识别过程中,首先,通过深度卷积神经网络对图片中的候选框中的图像的特征进行提取,以得到第三特征向量,将该第三特征向量与第一特征向量进行对比,并计算相关系数,通过一阈值来过滤不匹配的目标框,例如从图片中去除表示不具有特定形状的候选框,例如表示图片的背景的候选框,从而初步地筛选出在其中包含了已知形状的物体的候选框,即,有效候选框(boundingbox)。然后,将该有效候选框所对应的图像送入分类神经网络中以进一步得到候选框中的第四特征向量。最后基于第四特征向量和第二数据库(即,分类数据库)来执行第二级分类处理,从而对物体进行类别细分。在该识别过程中,通过初步筛选和第二级分类处理可以进行多级特征分类,从而提高分类和识别精度。
在本发明的一个示例性实施例中,该相关系数可以是欧式距离、余弦距离或皮尔森相关系数。如上仅仅列举出了相关系数的优选实施例,能够计算相关系数的所有计算方式均应落在本发明的保护范围之内。在本发明的优选实施例中,选用皮尔森相关系数,其计算公式如下:
相关系数的值域为-1到1,正数区间表示正相关,负数区间表示负相关,其绝对值越大表示相关程度越高。在根据本发明的物体识别方法中,对对比得到的相关系数设定一个阈值,低于该阈值的特征向量及其对应的boundingbox将被过滤掉。在本发明的一个示例性实施例中,该阈值一般设定到0.5到1之间。
在对卷积神经网络(cnn)的普遍认知中,训练一个收敛且表现良好的网络需要大量良好的数据对网络进行大量迭代。基于faster-rcnn的设计理念,训练所需的数据集要求标记出训练集图像中所有物体的详细boundingbox信息以及分类信息。这一过程需要消耗大量的人力,且由于网络的复杂度高、迭代次数多的原因,faster-rcnn的训练需要消耗大量的时间,在目前的硬件条件下,消耗的时间需要以天为单位。此外,受限于其设计理念和图像标注方式,faster-rcnn仅仅能对物体的大类进行区分(例如,区分电脑和杯子等具有不同形状的大类),并不具备对物体进行区分描述的能力。可以总结为,faster-rcnn的能力在于检索图像中特定形状的物体,但不能进行细分。
在本发明的一个示例性实施例中,由于认识到faster-rcnn网络在识别特定形状的物体方面具有突出的能力,因此在步骤s21中使用的深度卷积神经网络是faster-rcnn网络,以提取表示物体形状的第三特征向量,以更好地提取出在其中包含特定形状的物体的boundingbox。在步骤s22中,通过faster-rcnn中的区域生成网络(regionproposalnetwork),根据图片的特征空间而生成相应数量的候选框,该网络的优点在本领域中是已知的,在此不再赘述。由于不同的候选框中的特征向量的长度可能不同,因此通过regionofinterestpooling处理,可以得到归一化长度的特征向量。由于卷积神经网络(cnn)可分类的物体种类多,并能达到相对理想的效果,该网络所具备的不仅仅是对原1000类物体进行分类的能力,而是具备对物体进行可区分性描述的能力。根据实际的测试结果表明,通过这种神经网络进行的物体描述,即cnn网络提取的物体图像特征,可以达到在同类物品中区别差异性个体(例如不同形状或颜色的杯子、桌子、书等等)的效果。因此,在步骤s24中,所述分类神经网络是卷积神经网络(cnn)。
考虑到当前的faster-rcnn在训练过程中所耗费的时间之长,根据本发明的物体识别方法提出了如下的训练过程,如图2所示,所述训练过程包括:
s11:以第一角度、第一距离和第一光照对至少一个物体进行拍摄以获取物体图片;
s12:将物体图片输入到深度卷积神经网络中以生成至少一个候选框;
s13:手动地确定物体在图片中的坐标并选取每个物体的目标候选框并且;
s14:对选取的目标候选框对应的图像进行池化处理,从而得到用于描述每个物体的第一特征向量,这些特征向量具有统一长度;
s15:将这些统一长度的第一特征向量存储至第一数据库;
s16:将目标候选框中的图像输入到分类神经网络中以获取描述每个物体的第二特征向量;
s17:将这些第二特征向量存储至第二数据库;
s18:以不同于第一角度、第一距离和第一光照的多个角度、多个距离和多个光照对至少一个物体进行拍摄以获取多个不同的图片:以及
s19:对多个不同的图片执行步骤s12-s18的处理,以在第一数据库中存储用于描述同一物体的多个第一特征向量,在第二数据库中存储用于描述同一物体的多个第二特征向量。
因此,通过如上所述的根据本发明的物体训练过程,可以通过简单的步骤建立物体第一数据库(形状数据库)和第二数据库(分类数据库),并且在这些数据库中,物体特征的可扩展性很强,可以根据用户的需求灵活地设置,并且省去了重新训练神经网络的过程,节省了时间。
由于在训练过程中,手动地选取目标候选框,因此不需要使用区域生成网络(regionproposalnetwork)来根据图片的特征空间而生成相应数量的候选框,并且考虑到fast-rcnn网络识别特定形状的物体方面具有突出的能力,因此在步骤s12中使用的深度卷积神经网络是fast-rcnn网络。但是,在步骤s14中进行的池化处理依旧是regionofinterestpooling处理,以及在步骤s16中使用的分类神经网络依旧是卷积神经网络(cnn)。具体的选择理由如上所述,在此不再赘述。
在步骤s23之后,即使通过相关系数的阈值过滤掉了一部分不匹配的候选框,但是同一个物体还是可能由多个候选框来标注,这些候选框之间存在一定的重叠,且每个候选框具有不同的置信值,因此在根据本发明的一个示例性实施例中,在步骤s23之后,执行非极大值抑制算法以进一步筛选有效候选框以将筛选出的有效候选框用在步骤s24中。在根据本发明的一个示例性实施例中,进行非极大值抑制所用的阈值位于0至0.6的范围内。
在根据本发明的一个示例性实施例中,cnn网络基于squeezenet模型、vgg模型和resnet模型中的任一种。如上仅仅列举出了cnn所采用的分类模型的优选实施例,能够进行分类计算的模型均应落在本发明的保护范围之内。上述两种方案具有相同的特点。squeezenet模型和vgg模型的区别在于计算量具有一定的差距,故此对物体的描述能力有强弱之分。二者相较,squeezenet的计算量级更低,但相比于vgg描述能力相对较弱。在根据本发明的优选实施例中,考虑到计算速度的原因,选取更加经济合算的squeezenet模型。
对于k最近邻分类算法的选择可以采用传统的k最近邻分类算法,其中,传统knn分类方法的做法是,将数据库中不同的类别形成一个特征空间,每个类别的特征向量单独形成一个独立的区域。当希望对表示某种物体的新得到的特征向量进行分类时,需计算新特征向量到每个类别的特征向量组成的区域的距离(设其距离为dmin),当新特征向量到a类别的特征向量组成的区域的距离最小时,将该新特征向量所表述的物体归属于a类别。需要对dmin进行衡量,为此需确定一个阈值,当dmin大于该阈值时,分类结果将被舍弃,即认为新特征向量不属于原数据库中的任何一种类别。
但是,在数据库中类别较多或特征向量的描述性不够强时,利用基于投票委员会的k最近邻分类算法。在基于投票委员会的k最近邻分类算法,使用pearson相关系数对特征向量与分类数据库中的所有特征向量进行比对,在得到若干组相关系数后,对每组中的相关系数进行排序。通常,在每组相关系数中,选取相关系数最高的t个值组成投票委员会,因此得到若干组投票委员会,并分别对每组中的t个值进行加权。加权方式可采用线性加权、指数加权、sigmoid型加权等。
然后,对加权后的值进行归类相加,即把委员会中归属于同一类物体的t个相关系数进行求和得到一个加权和值。此外,设置两个阈值,第一个阈值称为差值阈值,即得分最高的类别的加权和值减去得分次高类别的加权和值的差须大于此阈值,将其设在0.3,但不排除其他值也是可行的。第二个阈值为决定阈值,即最高加权和值必须大于此门限,将其设在2,但不排除其他值也是可行的。当最高加权和值满足此上两个条件时,才认为分类结果真实有效。
本领域的技术人员可以理解,上面所描述的实施例都是示例性的,并且本领域的技术人员可以对其进行改进,各种实施例中所描述的结构在不发生结构或者原理方面的冲突的情况下可以进行自由组合。
虽然结合附图对本发明进行了说明,但是附图中公开的实施例旨在对本发明优选实施方式进行示例性说明,而不能理解为对本发明的一种限制。
虽然本总体发明构思的一些实施例已被显示和说明,本领域普通技术人员将理解,在不背离本总体发明构思的原则和精神的情况下,可对这些实施例做出改变,本发明的范围以权利要求和它们的等同物限定。
应注意,措词“包括”不排除其它元件或步骤,措词“一”或“一个”不排除多个。另外,权利要求的任何元件标号不应理解为限制本发明的范围。
- 还没有人留言评论。精彩留言会获得点赞!