一种面向流计算系统异常感知的容错方法及系统与流程
本发明属于大数据分布式计算领域,具体涉及流计算系统中的一种容错方法。
背景技术:
流计算(Stream Computing)是近年来在大数据处理领域尤其受到重视的一项核心技术,同时流计算服务也是云计算体系PaaS中一项重要的平台能力,它的主要计算特征是可以连续处理各种网络实体所生成的实时动态数据流。不同于Mapreduce和Pregel等大数据批处理系统,它可以使公共服务系统,企业运营系统,以及客户系统获得在线实时的高性能、海量吞吐等大数据应用的多种关键能力。此类系统在各类国际顶级学术会议中获得高度关注,例如SIGMOD、SIGKDD、VDSL、NSDI等等;从生产应用方面来看,流计算已经初步走入大型电信系统,大型互联网数据处理,电力电网系统,银行金融交易系统等关系到国计民生的重要应用领域。
分布式的流计算系统处理的是实时性的大数据流(流式大数据)。流式大数据具有实时性、易失性、突发性、无序性和无限性。基于以上特性,流计算系统必须长期处于计算状态且计算负载的浮动较大,系统较不稳定。所以,流计算系统有较高的故障率。容错机制是可信的流计算系统不可或缺的一部分。并且,流计算系统是一个实时计算系统,复杂且低效的容错机制会对流计算系统的计算效率造成很大的影响。总的来说,高效的容错机制是流计算系统可信且高效的保证之一。
在流计算系统中,现有容错方法的主要思想是对计算元组及算子状态的周期性上游备份。具体来说,高可用性方法(Precise Recovery、Rollback Recovery和Gap Recovery)就是应用该思想的典型容错方法。其中,Precise Recovery具有最强的错误恢复保证;Gap Recovery是会丢失一部分状态的;Rollback Recovery在这两者中间。在高可用性算法的基础上,有一种基于Passive Standby和Active Standby混合的容错方法。当系统发生错误后用Active Standby方法进行容错,因为Active Standby方法相对更加高效;当系统没发生错误时用Passive Standby方法进行状态备份,因为Passive Standby方法相对有较低的I/O消耗。此外,还有一种多窗口的上游备份容错方法,上游节点会备份下游节点的状态并且一直更新,发生错误的节点会向上游节点请求最新的备份状态,并且上游节点会重放已经丢失的元组。值得注意的是,该方法把节点的状态分为多个窗口,通过对各个窗口状态的异步备份来提高流计算系统的计算效率。但上述的方法都有一定的缺点。这些方法都是当系统发生错误并且这些错误被检测到以后才进行错误恢复,这使得系统的错误恢复时间比较长。并且,系统在对算子的状态进行上游备份时,为了保证算子状态的一致性,必须冻结当前算子,这也对系统的计算效率造成了一定的影响。
技术实现要素:
针对现有的容错机制的不足,本发明提出了基于错误预处理的容错方法——一种面向流计算系统异常感知的容错方法及系统。这种方法能够对流计算系统中的错误做一定的预先处理,来提高系统的错误恢复效率。
为了实现上述目的本发明提供一种面向流计算系统异常感知的容错系统:一种面向流计算系统异常感知的容错系统,其特征在于:包括计算模块、系统监控模块、动态扩展模块、错误恢复模块和计算资源池模块;其中所述系统监控模块和动态扩展模块部署在管理节点上,计算模块和错误恢复模块部署在所有的工作节点上。
所述计算模块,用于执行流计算系统中的查询任务;是流计算系统的核心部分,也是流计算系统最容易出错的地方。
所述系统监控模块,用于周期性的监控各个工作节点的状态,并向动态扩展模块和错误恢复模块发送指令,来应对不同的状态以保障系统高效可靠的运行。主要监控的信息包括集群中各个工作节点的心跳包、CPU利用率等。
所述动态扩展模块,用于为处于警告状态的工作节点动态的扩展一个容错节点;以便系统进行进一步的错误恢复工作;同时当工作节点的计算能力不够时,可以为计算能力不足的工作节点动态的扩展若干节点,来提高系统的计算效率。首先,把工作节点内部的路由状态和输出队列的状态备份到它的上游节点中。当系统的拓扑不发生变化时,工作节点的路由状态和输出队列状态是不会发生变化的。只有当系统的拓扑发生变化以后,如某个工作节点因为计算能力不足而发生动态扩展以后,相关工作节点的路由状态和输出队列状态就会发生相应的变化。这时,存储在上游节点中的相关状态就必须要更新。如果某个算子需要动态扩展,只需要将上游备份的相关状态平滑的迁移到新的节点上就可以完成动态扩展。
所述错误恢复模块,用于对发生错误的工作节点进行容错处理;本发明的容错处理是建立在上游备份基础上的。当上游节点把相关元组(流计算系统中数据的最小单元)发送到当前节点以后,这些元组不会在上游节点的输出队列中删除,而是继续存储在它的输出队列里面。只有当前节点计算完这些元组,并且把计算结果发送到下游节点以后,上游节点才会把输出队列中的相关元组删除。当节点发生错误以后,只要上游节点重放没有被删除的元组,重新计算这些元组就可以实现流计算系统的错误恢复。
所述计算资源池模块,用于为动态扩展模块提供节点资源;在该计算资源池模块中预先配置一定数量节点,当系统需要动态扩展时,动态扩展模块直接在计算资源池模块中调用新节点。这样可以提高系统动态扩展的效率。
当系统出现错误以后再处理错误的方法显得过于被动。本发明还提供一种面向流计算系统异常感知的容错方法,包括以下步骤:
系统监控模块周期性的监控流计算系统中各个节点状态;当发现有工作节点处于警告状态时,通知动态扩展模块和错误恢复模块对处于警告状态的节点进行预防性的错误恢复。
动态扩展模块为处于警告状态的节点动态性的扩展一个容错节点。
系统监控模块进一步监控处于警告状态的节点,如果该节点的状态由警告转为错误,则通知错误恢复模块,错误恢复模块直接用容错节点代替该节点,完成系统的错误恢复;完成错误恢复以后,容错节点将成为系统中的一个工作节点,而被替换掉的处于错误状态的工作节点将会从系统的工作节点中删除。如果该节点的状态由警告转为正常,则通知错误恢复模块停止对该节点的预防性错误恢复;但是,错误恢复模块并不会马上删除相关的容错节点,如果在接下来的连续的m个周期里面该工作节点一直处于正常状态,则相关的容错节点会被删除。如果该节点的状态由警告转为异常,则通知错误恢复模块,错误恢复模块一直对比处于异常状态的工作节点和容错点的计算进度,当检测到容错节点的计算进度快于处于异常状态的节点以后,用容错节点代替处于异常状态的节点,而处于异常状态的工作节点将会被系统删除。
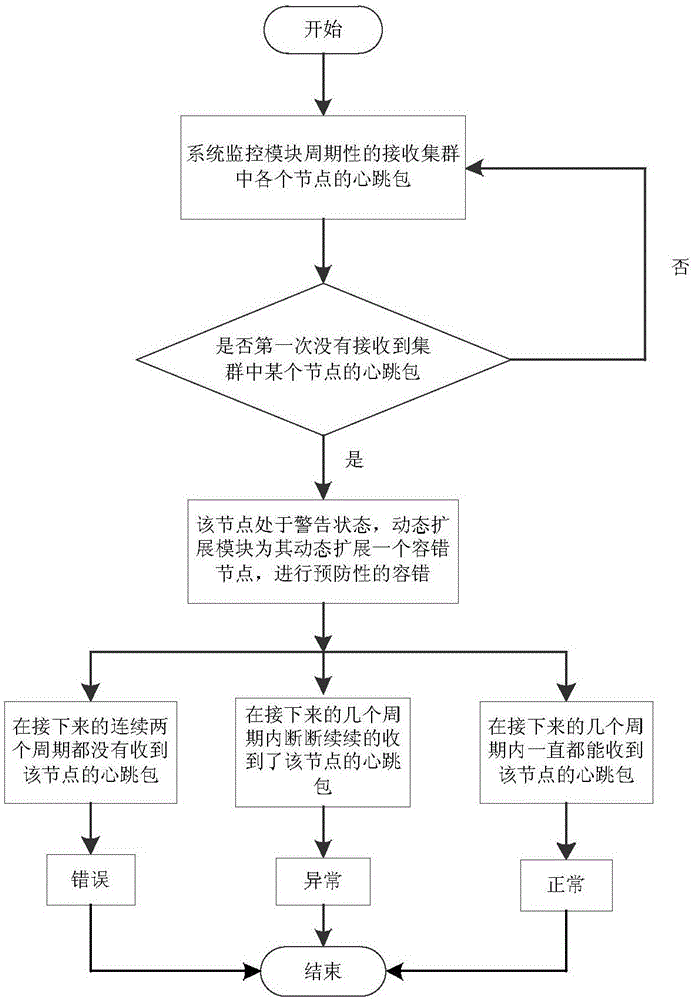
在上述方法中,判断工作节点处于警告状态的方法为:当系统监控模块在周期性接收工作节点心跳包的过程中,若第一次未接收到任意一个工作节点的心跳包,则该节点的状态为警告状态。
在上述方法中,系统监控模块进一步监控处于警告状态的节点判断该节点状态包括:
(1)当系统监控模块检测到工作节点处于警告状态以后,系统监控模块在连续的n个周期都没有接收到该处于警告状态的工作节点的心跳包,其中n>1,则该工作节点的状态由警告转为错误;
(2)当系统监控模块检测到工作节点处于警告状态以后,在接下来的连续m个周期里面,系统监控模块都收到了该工作节点的心跳包,则系统监控模块把该工作节点的状态由警告转为正常,其中m>n;
(3)当系统监控模块检测到工作节点处于警告状态以后,在接下来的连续k个周期里面,处于警告状态的工作节点的状态既没有从警告转为错误也没有从警告转变为正常,则系统监控模块把该工作节点的状态由警告转变为异常,其中k>m。
进一步,错误恢复模块用容错节点代替错误状态节点的过程为:错误状态节点不接受任何信息,错误状态节点的上游节点把储存在它的输出队列中的已经计算过且没有被删除的元组发送到容错节点上,容错节点重新计算这些元组并把计算结果发送到下游节点,然后上游节点从输出队列中删除相关的元组。
所述对比处于异常状态的工作节点和容错点的计算进度的方法为:错误恢复模块根据处于异常状态的工作节点和该节点的容错节点向上游节点发送的确认消息的时间戳信息的前后关系判断节点的计算进度;是基于输出队列中的每一个元组都是按时间戳有序的发送到下游工作节点中的,每个工作节点收到上游节点发送来的元组以后,都会向相关的上游节点发送一个包含时间戳信息的等级为0的确认消息,所以通过实践戳信息判断节点的计算进度。
与现有的方法相比,本发明具有以下的优点:
1、动态扩展模块和错误恢复模块的结合;
本发明的容错过程是动态扩展模块和错误恢复模块相互配合的过程。动态扩展和上游备份的结合对提高系统的计算效率有很大的帮助。上游备份方法极大的减少了系统对节点的相关状态的上游备份次数,因为,在对节点相关状态上游备份的过程中,为了保证状态的一致性,必须冻结节点使其停止当前的计算,这极大的影响了流计算系统的计算效率。所以,减少节点相关状态的上游备份次数就是提高系统的计算效率。另外,当集群中节点发生错误以后,系统会通知动态扩展模块为其动态扩展一个容错节点来完成系统容错。而不是事先就为每个节点分配一个容错节点,当错误发生以后用容错节点代替原节点实现容错。这极大的节约了硬件资源,降低了部署集群时的硬件资源限制,提高了流计算系统的可部署性。
2、基于系统监控的异常感知策略;
在流计算系统中,现有的容错方法大多都是被动式的容错即当错误发生以后才会触发系统的容错机制。本发明提供了一种面向流计算异常感知的容错方法,当感知到系统要出现错误时,系统就会为该节点进行预防性的错误恢复。当该节点的状态从警告变成错误以后,系统会在预防性容错的基础上进行节点的错误恢复。而预防性的容错可以有效的减少节点错误恢复的时间,提高系统的容错效率。即使处于警告状态的节点最后没有发生错误,本发明的一系列策略也会对提高系统的计算效率提供一定的帮助。
附图说明
图1为本发明一种面向流计算异常感知的容错系统的框架图;
图2为本发明中异常感知流程图;
图3为本发明中动态扩展算法的时序图;
图4为本发明中错误恢复算法的时序图;
图5为本发明一种面向流计算的错误预处理方法的流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加明了,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
如图1所示,本发明提供了一种面向流计算的带预防属性的容错系统,所述系统包括计算模块、系统监控模块、动态扩展模块、错误恢复模块和计算资源池模块。
在本系统中,计算模块负责系统的查询任务。当系统的监控到计算模块的错误或者警告以后,系统监控模块就会通知动态扩展模块为处于错误或者警告状态的节点动态的扩展一个容错节点。对于发生错误的节点,在容错节点上执行本发明中的错误恢复方法;而对于发生警告的节点,在容错节点上执行本发明中的异常感知方法。当错误恢复完成以后,用容错节点代替错误或者警告节点。并把容错节点加入到计算模块为整个系统提供计算服务。
下面就上述模块进行详细说明:本发明的系统监控模块会监控整个集群中各个工作节点的状态,当检测到某个节点处于警告状态时,系统监控模块会通知动态扩展模块和错误恢复模块对该节点进行预防性的错误恢复。预防性的错误恢复过程,对处于警告状态的节点仍然会处于计算状态,计算它本来的查询任务,而新的容错节点的计算结果不会发送到下游节点。当警告节点错误以后,会在预防性错误恢复的基础上进行系统容错;如果警告节点长时间处于警告状态但未发生错误,则处于警告状态的节点的计算效率会比较慢,经过一定的时间以后,容错节点的计算进度会快于警告节点,这时直接用容错节点代替处于警告状态的工作节点,而警告节点会被系统回收;如果警告节点结果较短的时间以后,警告状态解除且经过一定的时间仍然处于正常状态,则停止对该节点的预防性容错,在这种情况下,预防性的容错机制对系统的计算效率造成的影响是有限的。
系统监控模块主要是通过监控整个集群中工作节点的相关信息来判断集群的状态,如图2所示。集群中的各个节点会周期性的向系统监控模块发送心跳包,心跳包是节点在系统中正常运行的标志。如果系统的监控模块第一次在一个周期内没有接受到某个工作节点的心跳包,则系统认为该节点处于警告状态,处于警告状态的工作节点极有可能发生错误。当工作节点处于警告状态以后,系统会持续监控该节点。如果系统监控模块在接下来的n个连续的周期里面都没有接受到该节点的心跳包,则系统认为该节点是一个错误节点,其中n>1;如果在接下来的m个连续的周期内系统监控模块都收到了该节点的心跳包,则系统认为该节点是一个正常节点,其中m>n;如果在接下来的k个周期内,系统的监控模块断断续续的收到了该节点的系统包,也就是说,即不满足错误的条件也不满足正常的条件,系统则认为该节点是一个异常节点,其中k>m。根据系统监控模块对集群中节点状态的判断,系统中的动态扩展模块和错误恢复会做出不同的处理。接下来,会重点描述。
动态扩展模块负责为错误或者警告节点动态性的扩展一个容错节点。具体的过程如图3所示,其中O表示发生了错误或者警告的节点,Oui存储着该节点的内部状态是该节点的一个上游节点。当系统监控模块第一次未收到节点O的心跳包时,系统就认为节点O是警告节点,应该对其进行预防性的容错。系统的监控模块会通知动态扩展模块为其动态的扩展一个容错节点。在具体扩展的过程中,节点O向上游备份节点Oui发生请求,上游备份节点Oui会把备份的节点O的相关状态通过状态获取单元返回给节点O,并由节点O通过状态设置单元平滑的把相关状态迁移到节点O的容错节点oi上,最后通过状态清除单元删除已经重复的计算结果。至此,为警告节点O动态扩展容错节点的相关工作就全部完成。
错误恢复模块是整个流计算系统中实现系统容错的核心模块,本发明中利用对相关元组的上游备份来实现系统容错。如图4所示,当节点Nu的输出队列向他的下游节点N发送相关元组以后,节点N会向节点Nu发送等级为0的确定消息,节点Nu收到ack_0表明相关元组已经被接受,然后它会将相关元组储存在它的输出队列中。图4只表示出了一次上述操作,其实上述操作会在节点N和节点Nu进行无数次循环,直到系统完成所有的数据计算。同理,节点N和节点Nd也会进行相同的操作,在实际中,节点Nu和节点N之间的上述操作相对于节点N和节点Nd而言没有严格的先后次序,图4这样表示是为了让算法的逻辑更加清晰。当节点N收到下游节点Nd发送的ack_0消息后,它会向它的上游节点Nu发送一个等级为1的ack_1消息,节点Nu会根据ack_1中的相关消息删除存储在它的输出队列中的相关元组,因为它收到等级为1的ack_1消息表明下游节点的回复已经不需要这些元组,所以这些元组会被清除。以上就上游备份算法的整个过程。当节点N发生错误以后,只要在它的容错节点上重新计算在上游节点Nu中备份的相关元组即可以实现系统的错误恢复。
本发明一种面向流计算异常感知的容错方法及系统是在以上各个模块相互配合的前提下实现的。如图5所示,系统监控模块周期性的监控系统中各个节点状态。当发现有工作节点处于警告状态时,就会通知动态扩展模块和错误恢复模块,通过这两个模块的配合对处于警告状态的节点进行预防性的错误恢复。并且进一步监控处于警告状态的节点。通过对处于警告状态的节点的进一步监控,如果节点的状态由警告转为错误,则直接用容错节点代替处于错误状态的节点,完成系统的错误恢复;如果节点的状态由警告转为正常,则系统会停止对该节点的预防性容错;如果节点的状态由警告转为异常,则当系统检测到容错节点的计算进度快于处于异常状态的节点以后,用容错节点代替处于危险状态的节点完成系统接下来的计算。需要说明的是,处于异常状态的节点是一种极不稳定的状态,处于这种状态下的节点虽然还没有发生错误,但其计算效率会非常的低,所以经过一定的时间,容错节点的计算进度一定会超过处于危险状态的节点。
- 还没有人留言评论。精彩留言会获得点赞!