一种基于RDMA注册内存块的数据传输方法和装置与流程
本发明属于高性能通信技术领域,特别是涉及一种基于RDMA注册内存块的数据传输方法和装置。
背景技术:
目前,普通网卡集成了支持硬件校验和的功能,并对软件进行了改进,从而减少了发送数据的拷贝量,但无法减少接收数据的拷贝量,而这部分拷贝量要占用CPU的大量计算周期。普通网卡的工作过程如下:先把收到的数据包缓存到系统上,数据包经过处理后,相应数据被分配到一个TCP连接;然后,接收系统再把主动提供的TCP数据同相应的应用程序联系起来,并将数据从系统缓冲区拷贝到目标存储地址。这样,制约网络速率的因素就出现了:应用通信强度不断增加和主机CPU在内核与应用存储器间处理数据的任务繁重使系统要不断追加主机CPU资源,配置高效的软件并增强系统负荷管理,问题的关键是要消除主机CPU中不必要的频繁数据传输,减少系统间的信息延迟。
RDMA是通过网络把资料直接传入提前注册好的计算机存储区,将数据从一个系统快速移动到远程系统存储器中,而不对操作系统造成任何影响,这样就不需要用到多少计算机的处理功能。它消除了外部存储器复制和文本交换操作,因而能腾出总线空间和CPU周期用于改进应用系统性能。而目前通用的做法需由系统先对传入的信息进行分析与标记,然后再存储到正确的区域。在ceph集群中使用RDMA技术的实现一般有两种选择:其一是基于开源代码accelio类库的实现,不过由于accelio类库代码复杂度较高,且accelio类库本身存在一定的问题,在这些问题未被解决的情况下,不适合应用于生产环境;其二是基于VPI verbs接口自建,实现安全、可控的底层通信架构。使用第二种方式实现RDMA技术在ceph集群中的应用,是目前RDMA技术在存储领域应用的主要方式,其核心之一在于设计基于RDMA高效、稳定、可控的注册内存块管理机制。
为了使RDMA技术在分布式ceph集群中得到应用,需要封装一套通信接口供上层应用调用,开源代码accelio类库实现了基于RDMA技术的通信模型,并实现了应用层的XIO接口,但是accelio类库本身存在一些稳定性的问题,并不能在分布式ceph集群中实现产品化应用。为了实现RDMA技术在分布式ceph集群中的产品化,可以考虑基于Verbs接口自建实现基于RDMA的高性能底层通信模块,而自建的核心之一在于设计一种高效、稳定、可控的注册内存块管理机制。
技术实现要素:
为解决上述问题,本发明提供了一种基于RDMA注册内存块的数据传输方法和装置,能够减少RDMA对内存资源的占用,降低RDMA因计算操作注册内存而占用的系统资源,从而提高数据传输的稳定性,并提高数据传输效率。
本发明提供的一种基于RDMA注册内存块的数据传输方法,包括:
申请大块内存,并将所述大块内存分成多个具有预设大小的内存块;
将所述内存块注册到网卡的发送端和接收端,其中注册到接收端的第一内存块的个数不小于注册到发送端的第二内存块的个数;
获取可用的第二内存块,并装入待发送数据;
利用网卡将待发送数据发送到所述第一内存块中。
优选的,在上述基于RDMA注册内存块的数据传输方法中,
所述将所述内存块注册到网卡的发送端和接收端为:
利用VPI verbs接口ibv_reg_mr将内存块注册到Infiniband网卡的发送端和接收端。
优选的,在上述基于RDMA注册内存块的数据传输方法中,
所述将所述大块内存分成多个具有预设大小的内存块为:
将所述大块内存分成多个大小为8K的内存块。
优选的,在上述基于RDMA注册内存块的数据传输方法中,
所述注册到接收端的第一内存块的个数不小于注册到发送端的第二内存块的个数为:
注册到接收端的第一内存块的个数大于注册到发送端的第二内存块的个数。
优选的,在上述基于RDMA注册内存块的数据传输方法中,
在所述利用网卡将待发送数据发送到所述第一内存块中之后,还包括:
所述接收端通知所述发送端数据传输完成,并将发送端占用的内存块置为可用状态。
本发明提供的一种基于RDMA注册内存块的数据传输装置,包括:
分块单元,用于申请大块内存,并将所述大块内存分成多个具有预设大小的内存块;
注册单元,用于将所述内存块注册到网卡的发送端和接收端,其中注册到接收端的第一内存块的个数不小于注册到发送端的第二内存块的个数;
装入单元,用于获取可用的第二内存块,并装入待发送数据;
发送单元,用于利用网卡将待发送数据发送到所述第一内存块中。
优选的,在上述基于RDMA注册内存块的数据传输装置中,
所述注册单元具体用于利用VPI verbs接口ibv_reg_mr将内存块注册到Infiniband网卡的发送端和接收端。
优选的,在上述基于RDMA注册内存块的数据传输装置中,
所述分块单元具体用于将所述大块内存分成多个大小为8K的内存块。
优选的,在上述基于RDMA注册内存块的数据传输装置中,
所述注册单元具体用于将所述内存块注册到网卡的发送端和接收端,注册到接收端的第一内存块的个数大于注册到发送端的第二内存块的个数。
优选的,在上述基于RDMA注册内存块的数据传输装置中,还包括:
通知单元,用于利用所述接收端通知所述发送端数据传输完成,并将发送端占用的内存块置为可用状态。
通过上述描述可知,本发明提供的上述基于RDMA注册内存块的数据传输方法和装置,由于该方法包括:申请大块内存,并将所述大块内存分成多个具有预设大小的内存块;将所述内存块注册到网卡的发送端和接收端,其中注册到接收端的第一内存块的个数不小于注册到发送端的第二内存块的个数;获取可用的第二内存块,并装入待发送数据;利用网卡将待发送数据发送到所述第一内存块中,因此能够减少RDMA对内存资源的占用,降低RDMA因计算操作注册内存而占用的系统资源,从而提高数据传输的稳定性,并提高数据传输效率。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
图1为本申请实施例提供的第一种基于RDMA注册内存块的数据传输方法的示意图;
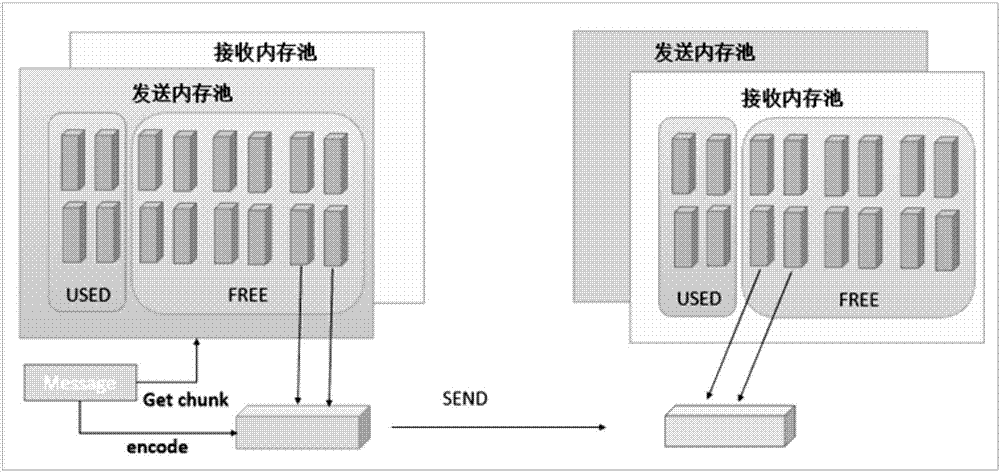
图2为通信内存块的管理机制的原理示意图;
图3为本申请实施例提供的第一种基于RDMA注册内存块的数据传输装置的示意图。
具体实施方式
本发明的核心思想在于提供一种基于RDMA注册内存块的数据传输方法和装置,能够减少RDMA对内存资源的占用,降低RDMA因计算操作注册内存而占用的系统资源,从而提高数据传输的稳定性,并提高数据传输效率。
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本申请实施例提供的第一种基于RDMA注册内存块的数据传输方法如图1所示,图1为本申请实施例提供的第一种基于RDMA注册内存块的数据传输方法的示意图,该方法包括如下步骤:
S1:申请大块内存,并将所述大块内存分成多个具有预设大小的内存块;
需要说明的是,可以将要申请的大块内存打散成8K一个的内存块(chunk)。
S2:将所述内存块注册到网卡的发送端和接收端,其中注册到接收端的第一内存块的个数不小于注册到发送端的第二内存块的个数;
需要说明的是,该网卡可以优选为具有Infiniband构架的网卡,RDMA是实现Infiniband构架的一种主流协议。
S3:获取可用的第二内存块,并装入待发送数据;
S4:利用网卡将待发送数据发送到所述第一内存块中。
具体的,参考图2,图2为通信内存块的管理机制的原理示意图,发送数据之前先从free内存池中获取足够的内存块,当数据被写入到对端内存时,将获取到的内存块放回到free内存池。如果free内存池没有足够的内存块时,遵循有多少内存块发送多少,剩余部分等到free内存池中有内存块时再发送;如果free内存池中没有内存块时,则消息被阻塞住直到free内存池中有内存块后再发送。
通过上述描述可知,本申请实施例提供的上述第一种基于RDMA注册内存块的数据传输方法,由于包括申请大块内存,并将所述大块内存分成多个具有预设大小的内存块;将所述内存块注册到网卡的发送端和接收端,其中注册到接收端的第一内存块的个数不小于注册到发送端的第二内存块的个数;获取可用的第二内存块,并装入待发送数据;利用网卡将待发送数据发送到所述第一内存块中,因此能够减少RDMA对内存资源的占用,降低RDMA因计算操作注册内存而占用的系统资源,从而提高数据传输的稳定性,并提高数据传输效率。
本申请实施例提供的第二种基于RDMA注册内存块的数据传输方法,是在上述第一种基于RDMA注册内存块的数据传输方法的基础上,还包括如下技术特征:
所述将所述内存块注册到网卡的发送端和接收端为:
利用VPI verbs接口ibv_reg_mr将内存块注册到Infiniband网卡的发送端和接收端。
需要说明的是,在RDMA通信过程中,通过这些注册好的内存块,将发送端的内容通过Infiniband网卡传输到接收端,能够减少数据传输对CPU造成的压力。
本申请实施例提供的第三种基于RDMA注册内存块的数据传输方法,是在上述第一种基于RDMA注册内存块的数据传输方法的基础上,还包括如下技术特征:
所述将所述大块内存分成多个具有预设大小的内存块为:
将所述大块内存分成多个大小为8K的内存块。
这里8K只是一个优选值,并不限于这种情况,具体的,分配的大小可以根据传输应用层数据的大小而定,若应用层每次消息内容小于8K,则会造成内存冗余,浪费存储空间,应该配置更小些;若应用层每次消息内容大于8K,则会增减传输次数,增加交互频率,这种情况应该配置大些会好点;也就是说,该内存块大小可以默认为8K,这是根据CEPH集群常规的消息大小取的一个中间值。
本申请实施例提供的第四种基于RDMA注册内存块的数据传输方法,是在上述第一种基于RDMA注册内存块的数据传输方法的基础上,还包括如下技术特征:
所述注册到接收端的第一内存块的个数不小于注册到发送端的第二内存块的个数为:
注册到接收端的第一内存块的个数大于注册到发送端的第二内存块的个数。
举个例子,当发送端注册4500个chunk,接收端注册5000个chunk,这样就能够保证接收端永远有多余的chunk用来接收发送端发来的消息,不会因为接收端的chunk不够而使数据丢失。
本申请实施例提供的第五种基于RDMA注册内存块的数据传输方法,是在上述第一种至第四种基于RDMA注册内存块的数据传输方法中任一种的基础上,还包括如下技术特征:
在所述利用网卡将待发送数据发送到所述第一内存块中之后,还包括:
所述接收端通知所述发送端数据传输完成,并将发送端占用的内存块置为可用状态。
也就是说,Infiniband网卡提供一种ACK机制,当发送端的数据被写入到接收端的注册内存中后,接收端会通知发送端数据传输完成,这个时候发送端占用的chunk被置为可用状态,等待chunk管理器取出使用,这样就能进一步提高数据传输的准确性。
本申请实施例提供的第一种基于RDMA注册内存块的数据传输装置如图3所示,图3为本申请实施例提供的第一种基于RDMA注册内存块的数据传输装置的示意图,该装置包括:
分块单元201,用于申请大块内存,并将所述大块内存分成多个具有预设大小的内存块,需要说明的是,可以将要申请的大块内存打散成8K一个的内存块(chunk);
注册单元202,用于将所述内存块注册到网卡的发送端和接收端,其中注册到接收端的第一内存块的个数不小于注册到发送端的第二内存块的个数,需要说明的是,该网卡可以优选为具有Infiniband构架的网卡,RDMA是实现Infiniband构架的一种主流协议;
装入单元203,用于获取可用的第二内存块,并装入待发送数据;
发送单元204,用于利用网卡将待发送数据发送到所述第一内存块中。
上述装置能够减少RDMA对内存资源的占用,降低RDMA因计算操作注册内存而占用的系统资源,从而提高数据传输的稳定性,并提高数据传输效率。
本申请实施例提供的第二种基于RDMA注册内存块的数据传输装置,是在上述第一种基于RDMA注册内存块的数据传输装置的基础上,还包括如下技术特征:
所述注册单元具体用于利用VPI verbs接口ibv_reg_mr将内存块注册到Infiniband网卡的发送端和接收端。
需要说明的是,在RDMA通信过程中,通过这些注册好的内存块,将发送端的内容通过Infiniband网卡传输到接收端,能够减少数据传输对CPU造成的压力。
本申请实施例提供的第三种基于RDMA注册内存块的数据传输装置,是在上述第一种基于RDMA注册内存块的数据传输装置的基础上,还包括如下技术特征:
所述分块单元具体用于将所述大块内存分成多个大小为8K的内存块。
这里8K只是一个优选值,并不限于这种情况,具体的,分配的大小可以根据传输应用层数据的大小而定,若应用层每次消息内容小于8K,则会造成内存冗余,浪费存储空间,应该配置更小些;若应用层每次消息内容大于8K,则会增减传输次数,增加交互频率,这种情况应该配置大些会好点;也就是说,该内存块大小可以默认为8K,这是根据CEPH集群常规的消息大小取的一个中间值。
本申请实施例提供的第四种基于RDMA注册内存块的数据传输装置,是在上述第一种基于RDMA注册内存块的数据传输装置的基础上,还包括如下技术特征:
所述注册单元具体用于将所述内存块注册到网卡的发送端和接收端,注册到接收端的第一内存块的个数大于注册到发送端的第二内存块的个数。
举个例子,当发送端注册4500个chunk,接收端注册5000个chunk,这样就能够保证接收端永远有多余的chunk用来接收发送端发来的消息,不会因为接收端的chunk不够而使数据丢失,当然,这是根据IB网卡支持chunk注册的性能指标而定的,同时跟系统内存大小有关,IB卡分高低档次,尽量接近设备能承受的上限和系统内存的范围之内。
本申请实施例提供的第五种基于RDMA注册内存块的数据传输装置,是在上述第一种至第四种基于RDMA注册内存块的数据传输装置中任一种的基础上,还包括如下技术特征:
通知单元,用于利用所述接收端通知所述发送端数据传输完成,并将发送端占用的内存块置为可用状态。
也就是说,Infiniband网卡提供一种ACK机制,当发送端的数据被写入到接收端的注册内存中后,接收端会通知发送端数据传输完成,这个时候发送端占用的chunk被置为可用状态,等待chunk管理器取出使用,这样就能进一步提高数据传输的准确性。
综上所述,上述方法和装置管理逻辑简单,使用过程中稳定性好,具有很好的可控性;内存小块分散,使用灵活、效率高,能有效提高RDMA通信的数据传输效率;降低RDMA因计算操作注册内存而占用的系统资源,能有效避免发送端发送内存被踩的问题,提高RDMA通信的稳定性。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!