基于流行度对用户兴趣的影响机制分析及其在推荐算法中应用的方法与流程
本发明涉及一种基于流行度对用户兴趣的影响机制分析及其在推荐算法中应用的方法。
背景技术:
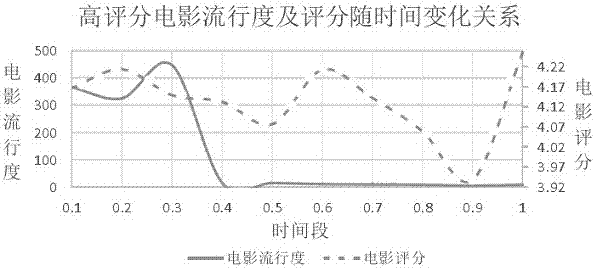
:随着互联网技术的发展和普及,人们越来越依赖网络进行各种活动。但是,当今互联网应用和服务不断增加,丰富的信息资源给用户选择带来一定的困难。在这一背景下,个性化推荐方法已经成为互联网应用的一个重要组成部分。对于推荐算法,能否准确地预测用户兴趣,将最有可能感兴趣的事物推荐给用户,从而提高用户点击率或购买量是衡量一个推荐算法效果的基本标准。目前的协同过滤推荐算法仅仅根据用户过去的浏览历史行为或评分来预测用户将来的兴趣,算法中没有考虑环境或群体行为对个体用户评分和选择行为的影响。而根据社会心理学研究的相关理论,用户兴趣是不断变化的,同时也非常容易受到外界环境和群体行为的影响而发生改变。技术实现要素:本发明的目的在于针对目前的协同过滤推荐算法推荐不佳的情况下,提高推荐准确度和用户满意度,为此提供了一种基于流行度对用户兴趣的影响机制分析及其在推荐算法中应用的方法。该方法以从众心理等社会心理学现象和理论为依据,研究流行度对用户兴趣的影响,得出项目流行度随着时间的增加,先升高再降低。对于流行度比较高的项目,评分差异较小,这也主要是由于个体的从众心理,项目越流行,评分越趋于一致;越不流行,用户的观点就越很少受到其他用户的影响,根据自己的喜好进行评判,用户评分将比较分散。该方法提出一种推荐优化算法,考虑了流行度的因素,得出项目的预测推荐评分更加符合真实评分,提高了推荐的准确性。该方法对传统的推荐排序算法进行改进,通过设置权重因子,衡量传统推荐标准和流行度因素对用户兴趣的影响。为达到上述目的,本发明的构思是:首先分析项目流行度与用户评分之间的关系,以流行度对用户评分的影响作用原理为基础,在推荐算法中根据项目流行度及评分的变化关系对预测评分进行调整,以提高推荐算法预测的准确性。融合传统推荐标准和项目流行度两个指标进行推荐排序,避免只根据用户过去历史记录或项目流行度分别产生的兴趣预测误差或推荐的非个性化等缺陷。提高推荐的点击率和准确度。根据上述发明构思,本发明采用如下技术方案:一种基于流行度对用户兴趣的影响机制分析及其在推荐算法中应用的方法,包括以下步骤:步骤一,提出流行度与用户兴趣的一般原理:以社会心理学现象和理论为依据,研究流行度对用户兴趣的影响,分析用户兴趣变化与群体意志之间的关系,归纳总结流行度在推荐中的一般原理;步骤二,提出一种基于流行度的预测评分调整方法:以流行度对用户评分的影响作用原理为基础,在推荐算法中根据项目流行度及评分的变化关系对预测评分进行调整,以提高推荐算法预测的准确性;步骤三,提出一种基于流行度的推荐排序方法:该方法融合传统推荐标准和项目流行度两个指标进行推荐排序,避免只根据用户过去历史记录或项目流行度分别产生的兴趣预测误差或推荐的非个性化等缺陷。所述步骤二的基于流行度的预测评分调整方法,其中,流行度是指某一项目所获得的用户关注程度,指衡量一段时间内媒体文件受欢迎的程度,它反映了流媒体文件在某一时刻被客户请求的概率,通常流行度被定义成在一段时间间隔内,媒体文件被点播的次数,能够拟合出流行度随时间变化的函数h。所述步骤二包括如下步骤:步骤二十一:使用用户的协同过滤算法挖掘兴趣相似用户,基于用户的协同过滤推荐主要分为3个阶段:数据表示;发现最近邻居;产生推荐项目集:数据表示采用用户-项目评分矩阵来表示获取的显式数据;发现最近邻居就是评分行为与当前用户最相似的若干用户,寻找最近邻居是协同过滤推荐算法的核心部分,最近邻居的准确性直接关系到推荐算法的推荐效果,在协同过滤推荐算法中一般通过计算用户之间的相似性来判断是否近邻;产生推荐项目集根据邻居用户对待推荐项目的评分,通过评分计算公式求得目标用户对待推荐系统的预测打分,然后选择评分较高的项目进行推荐,一般采用top-n推荐算法;在协同过滤算法中经常使用评分预测的方式进行推荐,即选择n个预测评分较高的项目推荐给目标用户;评分预测公式一般定义为:其中,pi,t表示用户i对项目t的预测评分,n为相似邻居的个数,sim(i,j)为用户i和用户j的相似度,rj,t是用户j对项目t的评分,为用户j对所有项目的平均评分,为所有已评分用户对项目t的平均评分。步骤二十二:预测评分调整,基于流行度预测评分调整的协同过滤算法的预测评分,预测评分公式为p’=p+t*f((h-h’)/t),其中p表示项目依据历史评分的邻居预测评分,p’表示项目的预测真实评分,h表示项目当前流行度,f表示流行度变化与评分变化的关系,h’表示项目的预测流行度,t表示距离当前时间的时间间隔,该公式考虑了项目的流行度因素的影响,预测时根据项目所处阶段流行度的变化趋势来调整预测评分;步骤二十三:比较两种方法预测评分的准确性,比较传统协同过滤算法与基于流行度预测评分调整的协同过滤算法的预测评分mae。所述步骤三的基于流行度的推荐排序方法,其中包括:热项目集:项目流行度大于整个数据集的平均流行度的项目集;冷项目集:项目流行度小于整个数据集的平均流行度的项目集;推荐排序:推荐排序的综合指标函数r=α*generalrank+(1-α)*popularity,其中α为权重因子,generalrank为传统推荐项目选择标准,popularity为目标项目的流行度;该公式是对两个兴趣影响因子的融合,对于不同的推荐算法,各个标准所占的权重或许不一样,α的取值需要进行相应地调整,通过比较推荐效率来确定不同项目的α值。所述步骤三包括如下步骤:步骤三十一:以传统协同过滤算法为基础,设计一个新的推荐排序标准,即融合项目预测评分和项目流行度的综合标准对待测项目进行排序,建立推荐排序综合指标函数;步骤三十二:通过调整权重因子α进行试验对比,以发现促进冷、热项目集推荐结果的最优α。本发明的基于流行度对用户兴趣的影响机制分析及其在推荐算法中应用的方法,与现有技术相比,具有以下突破性和显著优点:本发明方法根据用户兴趣随流行度变化的普遍现象和规律,提出基于流行度的预测评分调整推荐算法和基于传统推荐指标与流行度因素相结合的推荐排序方法,并基于协同过滤算法实现两个方面的改进,通过实验验证了改进算法的有效性。本发明主要基于影响用户兴趣的流行度因素进行研究分析,以心理学为基础预测用户兴趣的变化趋势。在从众心理等因素的影响下,越热门的项目越能吸引较多的用户,尽管该项目可能评分较低,因此一般推荐算法仅仅根据用户历史记录(例如用户评分、浏览项目)进行推荐是不准确的,对于新用户来说,该算法也能更好地解决普遍存在的冷启动问题;此外,用户对热门物品的评分也随着流行度的变化趋势发生相应地改变,本文主要对项目流行度初期阶段进行研究,根据流行度的变化对预测评分进行调整,预测准确率得到提高。附图说明图1为本发明方法的流程图。图2为高评分电影流行度及评分随时间变化关系。图3为中评分电影流行度及评分随时间变化关系。图4为低评分电影流行度及评分随时间变化关系。图5为不同流行度电影评分状况。图6为传统cf与基于流行度调整cf评分预测准确性比较。图7为基于热项目的不同权重因子的f值变化情况图。图8为基于冷项目的不同权重因子的f值变化情况图。具体实施方式以下结合附图对本发明的优选实施例进一步详细说明。如图1所示,本实施例中,本发明的基于流行度对用户兴趣的影响机制分析及其在推荐算法中应用的方法,主要针对movielens数据集进行实验。movielens数据集收集了在2000年6040个用户对3900部电影的1000209个评估值,用户评分是从1到5的整数,数值越高表明用户对该电影的兴趣越大。评分数据主要包括代表用户编号userid、表示电影编号movieid、表示用户对电影的评分rating、用户对电影评分的时间timestamp四项,即如下表所示:useridmovieidratingtimestamp1~60401~39001~5956703932~1046454590步骤一,提出流行度与用户兴趣的一般原理,以从众心理等社会心理学现象和理论为依据,研究流行度对用户兴趣的影响,分析用户兴趣变化与群体意志之间的关系,并基于实验分析流行度对用户评分和行为的影响作用,归纳总结流行度在推荐中的一般原理;步骤二,提出一种基于流行度的预测评分调整方法。以流行度对用户评分的影响作用原理为基础,在推荐算法中根据项目流行度及评分的变化关系对预测评分进行调整,以提高推荐算法预测的准确性。基于movielens数据集进行了对比实验,实验结果表明改进的推荐算法较传统方法更准确;步骤三,提出一种基于流行度的推荐排序方法。该方法融合传统推荐标准和项目流行度两个指标进行推荐排序,避免只根据用户过去历史记录或项目流行度分别产生的兴趣预测误差或推荐的非个性化等缺陷。实验结果表明改进的推荐算法有效地提高了推荐的点击率和准确度。所述步骤一包括:步骤十一,主要针对movielens数据集进行实验,采用数学中样本估计总体的统计分析方法,从数据集中随机抽取样本,分别计算在各时间段内样本的平均流行度和平均评分,将评分数据分为三组,即高(rating4-5)、中(rating3-4)、低评分(rating0-3)。步骤十二,对实验结果分析,参照图2,3,4,5,在三组评分中,电影流行度随时间的变化趋势基本一致,电影流行度随着时间的增加,先升高再降低。对于流行度比较高的电影,评分差异较小,这也主要是由于个体的从众心理,电影越流行,评分越趋于一致;越不流行,用户的观点就越很少受到其他用户的影响,根据自己的喜好进行评判,电影评分将比较分散。所述步骤二包括:步骤二十一:使用用户的协同过滤算法挖掘兴趣相似用户,基于用户的协同过滤推荐主要分为3个阶段:数据表示;发现最近邻居;产生推荐项目集。数据表示采用用户-项目评分矩阵来表示获取的显式数据;发现最近邻居就是评分行为与当前用户最相似的若干用户,寻找最近邻居是协同过滤推荐算法的核心部分,最近邻居的准确性直接关系到推荐算法的推荐效果。在协同过滤推荐算法中一般通过计算用户之间的相似性来判断是否近邻。目前计算相似度的方法主要有:余弦相似性、修正余弦相似性及皮尔逊相关系数等度量方法;产生推荐项目集根据邻居用户对待推荐项目的评分,通过评分计算公式求得目标用户对待推荐系统的预测打分,然后选择评分较高的项目进行推荐,一般采用top-n推荐算法。在协同过滤算法中经常使用评分预测的方式进行推荐,即选择n个预测评分较高的项目推荐给目标用户。评分预测公式一般定义为:其中,pi,t表示用户i对项目t的预测评分,n为相似邻居的个数,sim(i,j)为用户i和用户j的相似度,rj,t是用户j对项目t的评分,为用户j对所有项目的平均评分,为所有已评分用户对项目t的平均评分。步骤二十二:预测评分调整,基于流行度预测评分调整的协同过滤算法(pcf)的预测评分,预测评分公式p’=p+t*f((h-h’)/t),p表示项目依据历史评分的邻居预测评分,p’表示项目的预测真实评分,f表示流行度变化与评分变化的关系,h表示项目当前流行度,h’表示项目的预测流行度,t表示距离当前时间的时间间隔。该公式考虑了项目的流行度因素的影响,预测时根据项目所处阶段流行度的变化趋势来调整预测评分。其中,流行度:指某一项目所获得的用户关注程度,指衡量一段时间内媒体文件受欢迎的程度,它反映了流媒体文件在某一时刻被客户请求的概率,通常流行度被定义成在一段时间间隔内,媒体文件被点播的次数。通过分析试验数据可以拟合出流行度随时间变化的函数。高分电影的流行度变化拟合公式为:h=-13.05*ln(δt)+51.543;中分电影的流行度变化拟合公式为:h=-12.95*ln(δt)+51.762;低分电影的流行度变化拟合公式为:h=-16.854*ln(δt)+80.534.步骤二十三:比较两种方法预测评分的准确性,比较传统协同过滤算法(gcf)与基于流行度预测评分调整的协同过滤算法(pcf)的预测评分mae。参考图6,基于流行度预测评分调整的协同过滤算法(pcf)的预测评分的准确性比传统协同过滤算法(gcf)更高。所述步骤三包括:步骤三十一:以传统协同过滤算法为基础,设计一个新的推荐排序标准,即融合项目预测评分和项目流行度的综合标准对待测项目进行排序,建立推荐排序综合指标函数。步骤三十二:通过调整权重因子α进行试验对比,以发现促进冷、热项目集推荐结果的最优α。其中,热项目集:项目流行度大于整个数据集的平均流行度的项目集。冷项目集:项目流行度小于整个数据集的平均流行度的项目集。推荐排序综合指标函数:推荐排序的综合指标函数r=α*generalrank+(1-α)*popularity,α为权重因子,generalrank为传统推荐项目选择标准,popularity为目标项目的流行度。该公式是对两个兴趣影响因子的融合。对于不同的推荐算法,各个标准所占的权重可能不一样,α的取值需要进行相应地调整,通过比较推荐效率来确定不同项目的α值。参照图7和图8,在推荐时加入流行度因子的推荐度大于单独使用评分进行推荐的准确度。当α=0时,表示推荐指标完全以流行度值作为标准进行推荐,α=1时,表示推荐指标完全以预测评分作为标准进行推荐,等同于传统的协同过滤算法。完全基于流行度的推荐效率大于完全基于预测评分的推荐效率。因此,完全以评分来判断用户是否对此感兴趣而产生进一步的行为是片面的。但是,虽然完全基于流行度的点击率高,也不能采用该方法。因为该方法只是盲目的向用户推送内容,并没有考虑用户的喜好,会加大用户处理信息的困难程度。但是,基于流行度的方法能够更好地处理新用户所带来的冷启动问题。因此,结合流行度和预测评分两个因素对用户进行推荐是最好的策略。此外,对于热项目集来说,随着评分权重α的增加,f值(评价推荐结果)呈现下降的趋势,表示在项目流行阶段,项目的受欢迎程度是主导用户选择影片的主要作用。图7中,对于热项目集,当α在0.3~0.4时,f值最高,推荐效果最好,即对流行项目的推荐,项目流行度占70%~60%左右的权重,说明在流行阶段流行度对项目的推荐具有重要的作用。而对于冷项目来说,图8中,表明随着α的增加,f值的波动范围比较大,当α较小时,即表示项目流行度占的权重较大,推荐效果却很低,因为对于冷项目,人们就不会再受从众心理的影响去选择兴趣对象,而是根据自己的兴趣去选择。当α在0.4~0.6之间时,推荐效果较好。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1