数字图书馆的实现方法与流程
本发明涉及图书馆领域,特别涉及数字图书馆的实现方法。
背景技术:
数字图书馆是将传统图书馆的书籍、资料数字化以后,通过互联网向读者提供所需要的馆藏图书、期刊,可以向全国乃至全球的读者提供所需要的图书、期刊,随着移动互联网的发展,尤其是国内智能手机、平板电脑的普及以及VR头显的发展,使人们可以随时随地进行图书、期刊的阅读,相比传统图书馆,数字图书馆的服务功能可以扩展到人们生活的各个角落,是传统图书馆无法比拟的;但就目前的情况来看,读者通过数字图书馆网上检索系统查找资料时,查询规则要求严格,当读者无法准确记住某个书名或者作者时,难以查询到所需要的图书、期刊,而对于像教材那种重名很多的书,需要花费较多的时间筛选才能找到合适的图书、期刊,如果只知道某本图书、期刊的大概内容,则在检索的时候无从下手,读者需要阅读某些领域的时,也无从知晓哪些书刊是更合适的。同时,由于知识产权的保护问题,许多书籍不能在网上公开播放,读者需要看书时,需要联系版权方进行租借、购买,而现在的图书馆缺乏这方面的辅助作用。使得现在的数字图书馆检索功能较差,只能进行简单的、被动的检索查找,读者想找到合适的图书、期刊较为费时,遇到版权问题时则更加麻烦,使读者不知道如何租借、购买。
技术实现要素:
本发明提供了一种数字图书馆的实现方法,用以解决的现有的数字图书馆检索功能较差,只能进行简单的、被动的检索查找,读者想找到合适的图书、期刊较为费时,遇到版权问题时则更加麻烦,使读者不知道如何租借、购买的问题。
本发明提供的一种数字图书馆的实现方法,包括:所述数字图书馆包括服务器和客户端,所述服务器包括数据库、身份校验模块、检索模块、信息统计分析模块和推荐模块;所述实现方法包括:
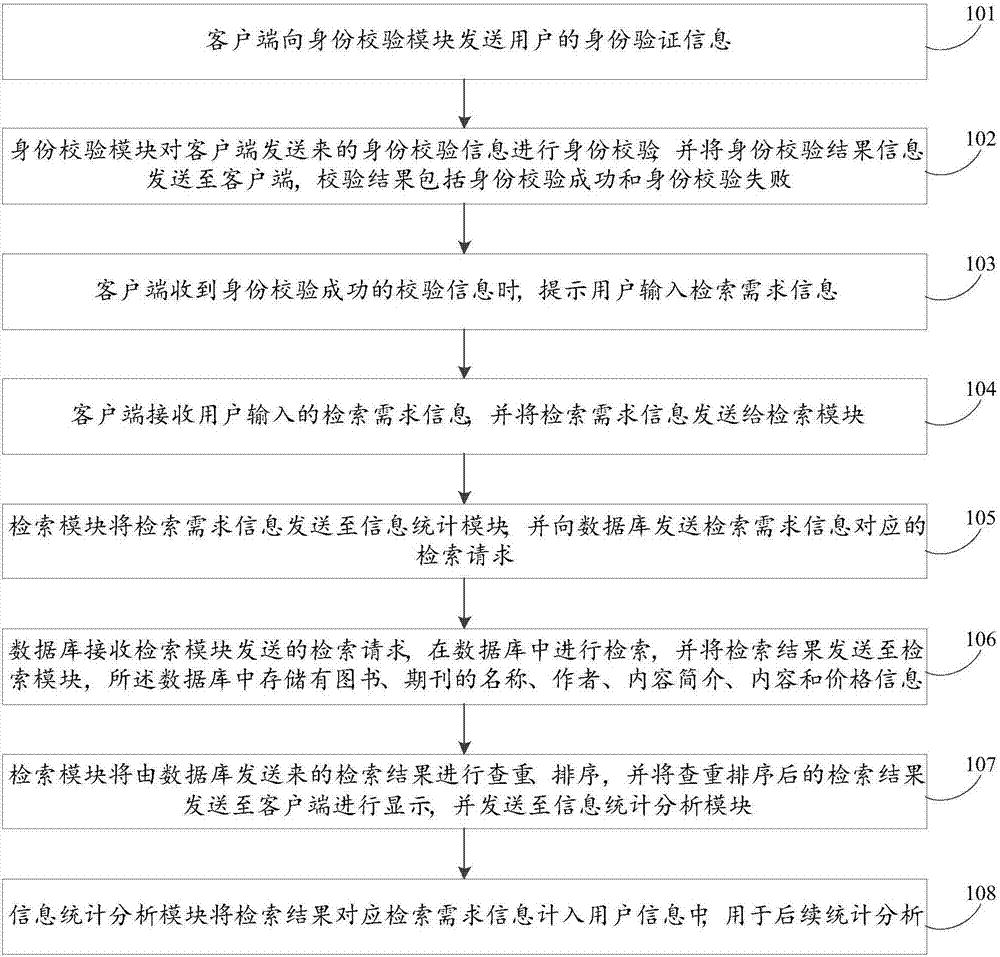
客户端向身份校验模块发送用户的身份验证信息;
身份校验模块对客户端发送来的身份校验信息进行身份校验,并将身份校验结果信息发送至客户端,校验结果包括身份校验成功和身份校验失败;
客户端收到身份校验成功的校验信息时,提示用户输入检索需求信息;
客户端接收用户输入的检索需求信息,并将检索需求信息发送给检索模块;
检索模块将检索需求信息发送至信息统计模块,并向数据库发送检索需求信息对应的检索请求;
数据库接收检索模块发送的检索请求,在数据库中进行检索,并将检索结果发送至检索模块,所述数据库中存储有图书、期刊的名称、作者、内容简介、内容和价格信息。
检索模块将由数据库发送来的检索结果进行查重、排序,并将查重排序后的检索结果发送至客户端进行显示,并发送至信息统计分析模块;
信息统计分析模块将检索结果对应检索需求信息计入用户信息中,用于后续统计分析。
优选的,推荐模块向信息统计分析模块发送推荐需求,推荐需求包括推荐书刊的数量,推荐书刊的信息;
信息统计分析模块接收推荐模块发送来的推荐需求,并向推荐模块反馈适合推荐需求的用户;
推荐模块接收由信息统计分析模块反馈的适合推荐需求的用户信息,并向所述适合推荐需求的用户进行内容推荐。
优选的,所述检索模块将检索需求信息发送至信息统计模块,并向数据库发送检索需求信息对应的检索请求,包括:
检索模块接受由用户端发送的检索需求信息;
检索模块对检索需求信息进行纠错处理得到纠错后的检索词;
检索模块将纠错后的检索词进行分词,得到分词后的检索词;
检索模块将分词后的检索词作为表检索关键词在预置的数据表中进行检索,当未检索到表检索关键词时,将分词后的检索词作为关键词组生成,当检索到表检索关键词时,将在预置的数据表中与表检索关键词位于同一集合内的所有关键词作为关键词组生成;
检索模块将关键词组作为检索关键字向数据库发送检索请求。
优选的,检索模块接收数据库发送来的检索结果;
检索模块对所述检索结果进行判断,当所述检索结果为空时,检索模块从网络侧的多个数据平台中,查询与所述分词后的检索词匹配的目标文件,并查询所述目标文件的版权信息、租借价格和购买价格;
检索模块将所述得到的目标文件的版权信息、租用价格和购买价格排序后发送至客户端,由客户端显示给用户。
优选的,检索模块向客户端发送位置请求信息;
客户端将现在的位置信息反馈给检索模块;
检索模块根据客户端反馈的位置信息搜索客户端所在位置附近的书店、图书馆,并将所述书店、图书馆的信息发送至客户端;
客户端将所述书店、图书馆的信息显示给用户。
优选的,信息统计分析模块从数据库获取用户的检索结果、检索需求信息、购买租借信息;
信息统计分析模块根据获取的用户的检索结果、购买租借信息对用户进行聚类分析,得到用户的分类信息及每类用户的关注信息;
信息统计分析模块将所述用户的分类信息及每类用户的关注信息写入数据库。
优选的,用户通过客户端对借阅、购买的文件进行用户评分;
客户端将所述用户评分的结果发送至所述数据库中存储。
优选的,信息统计分析模块读取数据库中每个文件的用户评分,对用户评分进行归一化后计算其算术平均值,得到每个文件的综合评分;
信息统计分析模块对每类用户的关注信息中的文件依据每个文件的综合评分进行排序,并将排序结果写入数据库中。
优选的,推荐模块读取数据库中由身份校验模块进行身份校验成功的客户端的用户信息;
推荐模块读取数据库中所述用户所在的用户分类信息及该类用户的关注信息;
推荐模块读取该类用户的关注信息中的文件及文件排序;
推荐模块从所述关注信息中的文件及文件排序中排除掉该用户已经购买、租借过的文件,得到待推荐的文件及文件排序,所述用户已经购买、租借过的文件由推荐模块从数据库中读取;
推荐模块将得到的待推荐的文件按照文件排序提取推荐信息,推荐信息包括文件名称,文件作者,文件内容概述,文件评价;
推荐模块将所述推荐信息发送至客户端,由客户端显示给用户。
优选的,所述信息统计分析模块根据获取的用户的检索结果、购买租借信息对用户进行聚类分析,得到用户的分类信息,包括:
所用分类方法为对矩阵A进行奇异值分解,即
A=UΣVT
其中,
aij=10×αijSij+10×βijGij+γijFij
其中,A为用户和图书的关系矩阵;aij表示第i个用户对第j个书刊的阅读偏好;αij、βij、γij为预置的系数,其值介于0-1之间,且0<αij<βij<γij;Sij表示第i个用户是否检索到了第j个书刊,当检索到时,其值为1,否则为0;Gij表示第i个用户是否购买了第j个书刊,当购买了时,其值为1,否则为0;Fij表示第i个用户对第j个书刊的评分,U、Σ、VT为奇异值分解的结果,其中,矩阵U的每一列向量中,数值大于预定阈值的行所对应的用户归为同一用户类别。
本发明的一些有益效果可以包括:本发明降低了用户检索的难度,提高了检索的容错性,使用户可以更方便、准确的检索到所需要的图书、期刊等资料,并且可以检索实体图书馆的藏书便于用户在没有电子版书刊时找到附近的藏有所需要的书刊的图书馆或书店,而且在遇到版权问题时,能够提供版权方联系方式方便用户租借或购买图书、期刊,同时本发明的方法还具有主动给用户推荐图书、期刊的功能,帮助用户进行主动学习。
通过本发明的系统,可以解决目前的数字图书馆检索功能较差,只能进行简单的、被动的检索查找,读者想找到合适的图书、期刊较为费时,遇到版权问题时则更加麻烦,使读者不知道如何租借、购买的问题。
本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
图1为本发明实施例中一种数字图书馆的实现方法的结构示意图;
图2为本发明实施例中一种数字图书馆的实现方法的过程示意图;
具体实施方式
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
在本发明的一个实施例中,如图1所示,为本发明实施例中一种数字图书馆的实现方法的结构示意图,包括:所述数字图书馆包括服务器和客户端,所述服务器包括数据库、身份校验模块、检索模块、信息统计分析模块和推荐模块。如图2所示,为本发明实施例中一种数字图书馆的实现方法的过程示意图,所述实现方法包括:
步骤S101:客户端向身份校验模块发送用户的身份验证信息;
步骤S102:身份校验模块对客户端发送来的身份校验信息进行身份校验,并将身份校验结果信息发送至客户端,校验结果包括身份校验成功和身份校验失败;
步骤S103:客户端收到身份校验成功的校验信息时,提示用户输入检索需求信息;
步骤S104:客户端接收用户输入的检索需求信息,并将检索需求信息发送给检索模块;
步骤S105:检索模块将检索需求信息发送至信息统计模块,并向数据库发送检索需求信息对应的检索请求;
步骤S106:数据库接收检索模块发送的检索请求,在数据库中进行检索,并将检索结果发送至检索模块,所述数据库中存储有图书、期刊的名称、作者、内容简介、内容和价格信息。
步骤S107:检索模块将由数据库发送来的检索结果进行查重、排序,并将查重排序后的检索结果发送至客户端进行显示,并发送至信息统计分析模块;
步骤S108:信息统计分析模块将检索结果对应检索需求信息计入用户信息中,用于后续统计分析。
本发明提供的方法实现了一种数字图书馆的实现方法,提供了用户的检索需求信息的统计,为用户更方便、准确的检索到所需要的图书、期刊等资料打下了基础。
在本发明的一个实施例中,推荐模块向信息统计分析模块发送推荐需求,推荐需求包括推荐书刊的数量,推荐书刊的信息;
信息统计分析模块接收推荐模块发送来的推荐需求,并向推荐模块反馈适合推荐需求的用户;
推荐模块接收由信息统计分析模块反馈的适合推荐需求的用户信息,并向所述适合推荐需求的用户进行内容推荐。
在本发明的一个实施例中,推荐模块向信息统计分析模块发送的推荐需求为“2册物理类图书”;
信息统计分析模块接收推荐模块发送来的推荐需求“2册物理类图书”,并向推荐模块反馈喜爱物理类图书的用户;
推荐模块接收由信息统计分析模块反馈的喜爱物理类图书的用户信息,并向喜爱物理类图书的用户进行内容推荐。通过本发明提供的方法,能够主动给用户推荐图书、期刊,帮助用户进行主动学习。
在本发明的一个实施例中,检索模块将检索需求信息发送至信息统计模块,并向数据库发送检索需求信息对应的检索请求,包括:
检索模块接受由用户端发送的检索需求信息;
检索模块对检索需求信息进行纠错处理得到纠错后的检索词;
检索模块将纠错后的检索词进行分词,得到分词后的检索词;
检索模块将分词后的检索词作为表检索关键词在预置的数据表中进行检索,当未检索到表检索关键词时,将分词后的检索词作为关键词组生成,当检索到表检索关键词时,将在预置的数据表中与表检索关键词位于同一集合内的所有关键词作为关键词组生成;
检索模块将关键词组作为检索关键字向数据库发送检索请求。
在本发明的一个实施例中,检索模块接受由用户端发送的检索需求信息,用户端发送的检索需求信息是:“费慢先生别闹了”;
检索模块对检索需求信息进行纠错处理得到纠错后的检索词:“费曼先生别闹了”;
检索模块将纠错后的检索词进行分词,得到分词后的检索词:“费曼、先生、别闹了”;
检索模块将分词后的检索词“费曼、先生、别闹了”作为表检索关键词在预置的数据表中进行检索,检索到表检索关键词“费曼”时,将在预置的数据表中与表检索关键词位于同一集合内的所有关键词“费曼、费恩曼、Feynman”以及“先生、别闹了”一起与作为关键词组生成;
检索模块将关键词组“费曼、费恩曼、Feynman、先生、Sir、Mr.、别闹了”作为检索关键字向数据库发送检索请求。本发明提供的这种方法提高了检索的容错性、降低了用户检索的难度,使用户可以更方便、准确的检索到所需要的图书、期刊等资料。
在本发明的一个实施例中,检索模块接收数据库发送来的检索结果;
检索模块对所述检索结果进行判断,当所述检索结果为空时,检索模块从网络侧的多个数据平台中,查询与所述分词后的检索词匹配的目标文件,并查询所述目标文件的版权信息、租借价格和购买价格;
检索模块将所述得到的目标文件的版权信息、租用价格和购买价格排序后发送至客户端,由客户端显示给用户。
在本发明的一个实施例中,检索模块接收数据库发送来的检索结果,检索结果为空,检索模块从网络侧的多个数据平台中,查询到与所述分词后的检索词匹配的目标文件《端点位移激励下斜拉索非线性振动计算方法研究》,并查询所述目标文件的版权人为《计算力学学报》,可通过维普网进行购买、购买价格为3元,通过中国知网进行购买,购买价格为4元。
检索模块将得到“《端点位移激励下斜拉索非线性振动计算方法研究》的版权人为《计算力学学报》;可通过维普网进行购买、购买价格为3元;通过中国知网进行购买,购买价格为4元”发送至客户端,由客户端显示给用户,客户可以选择是否购买,以及在哪个平台进行购买。通过本发明提供的方法,在遇到版权问题时,能够提供版权方的提供的购买方式方便用户租借或购买图书、期刊,使用户可以更方便的检索、阅读到所需要的图书、期刊等资料;同时,还科学智能地避免了侵犯版权事件的发生。
在本发明的一个实施例中,检索模块向客户端发送位置请求信息;
客户端将现在的位置信息反馈给检索模块;
检索模块根据客户端反馈的位置信息搜索客户端所在位置附近的书店、图书馆,并将所述书店、图书馆的信息发送至客户端;
客户端将所述书店、图书馆的信息显示给用户。
在本发明的一个实施例中,检索模块向客户端发送位置请求信息;
客户端将现在的位置信息上海市反馈给检索模块;
检索模块根据客户端反馈的位置信息上海市搜索到客户端所在位置附近的上海市中心图书馆,该图书馆藏有“别闹了,费曼先生:科学顽童的故事”共4册,其中2册可借,并将上海市中心图书馆的地址信息“淮海中路1555号”发送至客户端;
客户端将上海市中心图书馆的信息“藏有《别闹了,费曼先生:科学顽童的故事》共4册,其中2册可借,地址为淮海中路1555号”显示给用户。
本发明提供的这种方法,可以检索实体图书馆的藏书便于用户在没有电子版书刊时找到附近的藏有所需要的书刊的图书馆或书店,使用户可以更方便的找到所需要的图书、期刊等资料。
在本发明的一个实施例中,信息统计分析模块从数据库获取用户的检索结果、检索需求信息、购买租借信息;
信息统计分析模块根据获取的用户的检索结果、购买租借信息对用户进行聚类分析,得到用户的分类信息及每类用户的关注信息;
信息统计分析模块将所述用户的分类信息及每类用户的关注信息写入数据库。
在本发明的一个实施例中,信息统计分析模块从数据库获取用户张三的检索结果《别闹了,费曼先生:科学顽童的故事》、检索需求信息“费慢先生别闹了”、并以22元购买了该书的电子版;
信息统计分析模块根据获取的用户的检索结果《别闹了,费曼先生:科学顽童的故事》、检索需求信息“费慢先生别闹了”、并以22元购买了该书的电子版;将该用户进行分类,得到用户的分类为爱好物理名人传记类,该类用户的关注物理名人传记类信息;
信息统计分析模块将所述用户张三的分类信息“爱好物理名人传记类”及该类用户的关注信息“物理名人传记类”写入数据库。通过本发明提供的方法,由于对用户按照其阅读偏好进行了分类,从而能够更准确的检索到用户所需要的图书、期刊等资料,并为主动给用户推荐图书、期刊,帮助用户进行主动学习打下基础。
在本发明的一个实施例中,用户通过客户端对借阅、购买的文件进行用户评分;
客户端将所述用户评分的结果发送至数据库中存储。
在本发明的一个实施例中,用户张三通过客户端对购买的文件《别闹了,费曼先生:科学顽童的故事》进行用户评分,评分为9分;
客户端将9分的用户评分发送至数据库中存储,标记为张三对《别闹了,费曼先生:科学顽童的故事》的评分。通过本发明提供的方法,可以对同类的甚至同名的的图书进行评分,将评分作为检索、推荐的权重可以为用户进行更准确的检索和推荐,降低了用户检索到所需要的图书、期刊等资料的时间,同时为更好的主动给用户推荐图书、期刊,帮助用户进行主动学习打下了基础。
在本发明的一个实施例中,信息统计分析模块读取数据库中每个文件的用户评分,对用户评分进行归一化后计算其算术平均值,得到每个文件的综合评分;
信息统计分析模块对每类用户的关注信息中的文件依据每个文件的综合评分进行排序,并将排序结果写入数据库中。
在本发明的一个实施例中,信息统计分析模块读取数据库中每个文件的用户评分,对用户评分进行归一化后计算其算术平均值,得到每个文件的综合评分;对用户进行归一化仅对有3次及以上评分记录的用户进行,对评分不足3次的用户使用原始分值计算综合评分。对用户评分进行归一化可以概括为:将该用户的所有评分进行线性变换,使该用户所有的评分满足均值为5,标准差为1的分布,当变换后的分数高于10时,令评分为10,当变换后的分数低于0时,令评分为0,由此得到该该用户归一化的评分。对于某个书刊的综合评分,由归一化后的用户评分进行平均值计算得到。
信息统计分析模块对每类用户的关注信息中的文件依据每个文件的综合评分进行排序,并将排序结果写入数据库中。通过本发明提供的方法,可以在对某个书刊进行评分时,不受单独用户打分偏好的影响,可以得到更准确的用户评分值,进而为更准确的检索到用户所需要的图书、期刊等资料和主动给用户推荐图书、期刊,帮助用户进行主动学习打下基础。
在本发明的一个实施例中,推荐模块读取数据库中由身份校验模块进行身份校验成功的客户端的用户信息;
推荐模块读取数据库中所述用户所在的用户分类信息及该类用户的关注信息;
推荐模块读取该类用户的关注信息中的文件及文件排序;
推荐模块从所述关注信息中的文件及文件排序中排除掉该用户已经购买、租借过的文件,得到待推荐的文件及文件排序,所述用户已经购买、租借过的文件由推荐模块从数据库中读取;
推荐模块将得到的待推荐的文件按照文件排序提取推荐信息,推荐信息包括文件名称,文件作者,文件内容概述,文件评价;
推荐模块将所述推荐信息发送至客户端,由客户端显示给用户。
在本发明的一个实施例中,推荐模块读取数据库中由身份校验模块进行身份校验成功的客户端的用户信息为张三;
推荐模块读取数据库中所述用户所在的用户分类信息“爱好物理名人传记类”及该类用户的关注信息“物理名人传记类”;
推荐模块读取“爱好物理名人传记类”张三的关注信息“物理名人传记类”中的文件及文件排序“1、《奥本海默传》,2、《爱因斯坦传》,3、《居里夫人传》,4、《别闹了,费曼先生:科学顽童的故事》,5、《蚕丝——钱学森传》,6、《规范与对称之美——杨振宁传》……”
推荐模块从“物理名人传记类”中的“1、《奥本海默传》,2、《爱因斯坦传》,3、《居里夫人传》,4、《别闹了,费曼先生:科学顽童的故事》,5、《蚕丝——钱学森传》,6、《规范与对称之美——杨振宁传》……”中排除掉张三已经购买、的《别闹了,费曼先生:科学顽童的故事》,得到待推荐的文件及文件排序“1、《奥本海默传》,2、《爱因斯坦传》,3、《居里夫人传》,4、《蚕丝——钱学森传》,5、《规范与对称之美——杨振宁传》……”,张三已经购买、租借过的文件由推荐模块从数据库中读取;
推荐模块将得到的待推荐的文件按照文件排序提取推荐信息,推荐信息包括文件名称《奥本海默传》、《爱因斯坦传》,文件作者凯·伯德/马丁·J.舍温、沃尔特·艾萨克森,文件内容概述和文件评价。
推荐模块将所述推荐信息发送至客户端,由客户端显示给用户。
通过本发明提供的方法,能够主动给用户推荐图书、期刊,帮助用户进行主动学习。
在本发明的一个实施例中,信息统计分析模块根据获取的用户的检索结果、购买租借信息对用户进行聚类分析,得到用户的分类信息,包括:
所用分类方法为对矩阵A进行奇异值分解,即
A=UΣVT
其中,
aij=10×αijSij+10×βijGij+γijFij
其中,A为用户和图书的关系矩阵;aij表示第i个用户对第j个书刊的阅读偏好;αij、βij、γij为预置的系数,其值介于0-1之间,且0<αij<βij<γij;Sij表示第i个用户是否检索到了第j个书刊,当检索到时,其值为1,否则为0;Gij表示第i个用户是否购买了第j个书刊,当购买了时,其值为1,否则为0;Fij表示第i个用户对第j个书刊的评分,U、Σ、VT为奇异值分解的结果,其中,矩阵U的每一列向量中,数值大于预定阈值的行所对应的用户归为同一用户类别。通过本发明提供的方法,对用户进行聚类分析考虑了用户的检索结果、购买租借信息以及评分信息,能够更准确的获取用户的偏好,且使用奇异值分解对用户进行分类,可以避免人工选择的偏好的影响,能够更好的分类,从而能够使用户更准确的检索到所需要的图书、期刊等资料,并且还能更好的给用户推荐图书、期刊,帮助用户进行主动学习。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!