一种计算人群在空间中噪声叠加结果的预测方法与流程
本发明涉及计算人群在空间中噪声叠加结果的预测方法,涉及噪声预测领域。
背景技术:
疏散一直是关系到群众人身财产安全的重要主题,在突发情况下疏散中的人群会互相交流和呼救,产生很大的背景噪声,既影响人群之间的互相交流,也影响疏散广播的清晰度,从而降低疏散效率,产生不必要的损失。而且疏散人数越多,产生的总体噪声会非线性的增加,这种现象被称为“鸡尾酒会效应”。在这种情况下如何预测人群产生的噪声水平成为重要的研究项目。
人群噪声预测的传统的技术方法为室内声压级计算公式计算和计算机仿真软件模拟。公式计算的缺点在于计算不精确,此公式基于扩散声场假设,主要应用于空间较小的房间内,例如教室和工业厂房,在较大的空间中,扩散声场假设明显不成立,因此此公式的精确度具有天然缺陷。而计算机仿真模拟基于每个声源的计算结果叠加,一般适用于单一声源或个数较少的声源,通常软件支持的声源个数不超过200个,此数值以上的声源需要耗费巨量的计算时间甚至根本无法计算。
空间中需要计算人群噪声的疏散人群个数通常在一百人以上,甚至存在上万人同时处于一个疏散空间中的情况,这就需要新的技术手段来预测如此巨量人群产生的噪声水平。
技术实现要素:
本发明是为了解决公式计算方法精度低和仿真计算方法工作量大的问题,而提出的一种计算人群在空间中噪声叠加结果的预测方法。
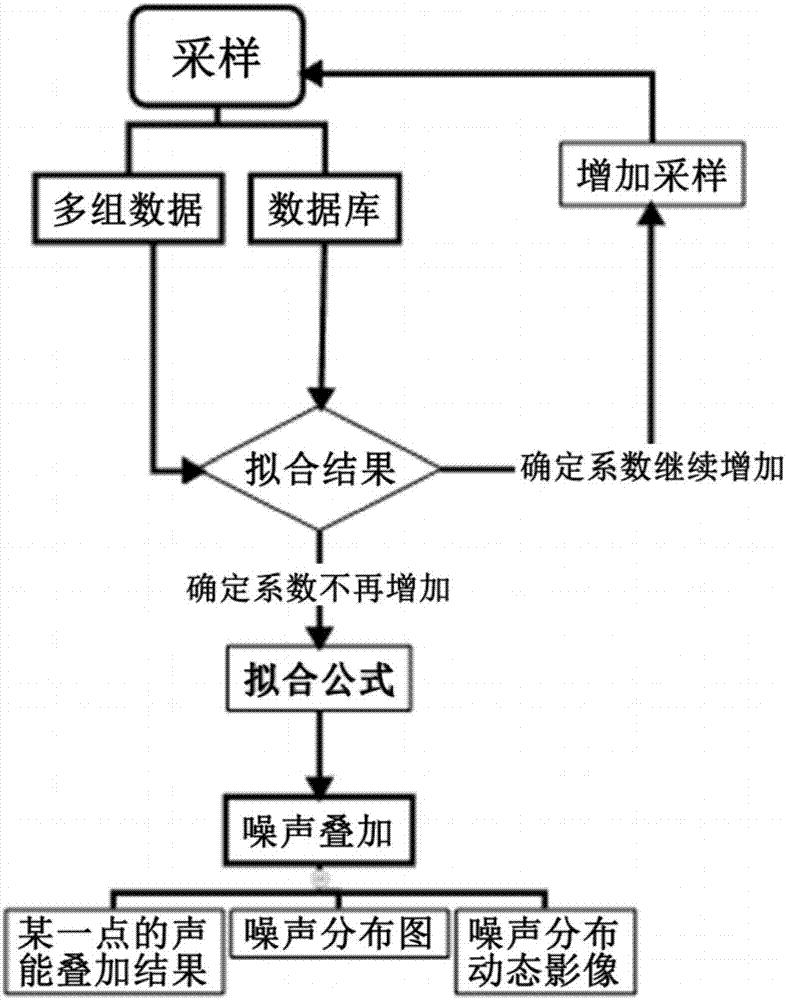
一种计算人群在空间中噪声叠加结果的预测方法按以下步骤实现:
步骤一:对空间中的人群进行采样,并得到距离-声压级数据对;
步骤二:根据步骤一中得到的距离-声压级数据对拟合噪声声能随距离衰减曲线;
步骤三:根据步骤二拟合噪声声能随距离衰减曲线进行噪声声能叠加;
步骤四:根据步骤三中噪声声能叠加的结果,得到噪声分布图。
发明效果:
本发明针对现有技术中公式计算精度低以及仿真计算难度工作量大的问题,通过有限个数点的模拟或者实地测试,得出个声源点在空间中的衰减规律,进而通过此规律预测较大数目的声源产生的噪声叠加效果,与室内声压级计算公式直接计算的方法相比,大幅度提高了计算精确度,根据实测数据,其计算精度从3db提高到1db,与单纯计算机模拟相比大幅度降低测试或者仿真工作量,降低仿真工作量的幅度为人群数与取样点数之比,通常在10倍至1000倍之间。计算的结果可作为大空间(根据国内外文献,通常单边长度大于50m的空间可以被称为大空间)中电声设计、疏散引导系统、紧急报警系统等方面的设计依据。
附图说明
图1为本发明预测方法示意图;
图2为本发明流程图;
图3为拟合曲线和拟合公式示意图;
图4为初始时刻人员分布状态图;
图5为t时刻人员分布状态图;
图6为t+120s时人员分布状态图;
图7为t+240s时人员分布状态图;
图8为t时刻的噪声分布图;
图9为t+120秒时刻的噪声分布图;
图10为t+240秒时刻的噪声分布图。
具体实施方式
具体实施方式一:如图1和图2所示,一种计算人群在空间中噪声叠加结果的预测方法包括以下步骤:
步骤一:对空间中的人群进行采样,并得到距离-声压级数据对;
步骤二:根据步骤一中得到的距离-声压级数据对拟合噪声声能随距离衰减曲线;
步骤三:根据步骤二拟合噪声声能随距离衰减曲线进行噪声声能叠加;
步骤四:根据步骤三中噪声声能叠加的结果,得到噪声分布图。
本发明的适用范围:
(1)要求人群个数足够多以致可以忽略单个声源指向性差异,一般认为应在50人以上。
(2)较大空间:空间平面最大尺寸之比不超过1:3的较大空间。
最终计算结果
(1)可以如公式(1)所示的计算结果;
(2)也可以是某一点的噪声数值;
(3)也可以是如图4中a所示的噪声分布图;
(4)也可以是图4中a、b、c不同时刻连续求解得出的随时间变化的噪声动态影像;
(5)以及在以上四者基础上衍生出的其他表现形式。
可将本发明计算过程(2)中确定系数的最终数值视为可信度检验结果,如果确定系数在0.9以上,则可认为计算结果具有合理的可信度。
具体实施方式二:本实施方式与具体实施方式一不同的是:所述步骤一中采样的方式为实地测试或者计算机仿真,采样个数为m个,m为大于8的偶数,将每个采样点设置为采样声源点。
采样过程为首先在空间中的大量人群中均匀采样m个(m推荐为大于8个以上的偶数),是否需要补充采样声源数目由后续计算结果确定。
其它步骤及参数与具体实施方式一相同。
具体实施方式三:本实施方式与具体实施方式一或二不同的是:所述步骤一中得到距离-声压级数据对的具体过程为:
在空间中均匀设置测试点,任意相邻两个测试点之间的距离小于等于5米,在每个采样声源点设置单个无指向声源依次发声,在每个声源单独发声时,记录所有测试点的声压级和每个测试点与发声声源之间的距离,得到m组距离-声压级数据对。
将空间中均匀布置测试点,保证各测试点之间间隔不超过5m。在每一个采样声源点设置单个无指向声源逐一发声,在每个声源单独发声时,记录所有测试点的声压级和此测试点与发声声源之间的距离。(可以使用声压级或者a声级等噪声声能评价参数,本发明中以声压级为例说明)。得到采样声源个数组“距离-声压级”数据对。
其它步骤及参数与具体实施方式一或二相同。
具体实施方式四:本实施方式与具体实施方式一至三之一不同的是:所述步骤二中拟合噪声声能随距离衰减曲线的具体过程为:
从m组距离-声压级数据对中取出p组距离-声压级数据对,p取m/2及m/2±1,将选出的p组距离-声压级数据对合并到数据库k内,并对其进行拟合,得到拟合公式:
y=aln(x)+b(1)
其中y为声压级,x为测试点距声源距离,a、b为拟合公式的确定系数;
将剩余的m-p组数据依次加入数据库k内,并将每次求出的确定系数与前一次的确定系数比较,直至确定系数无增加为止;
若m-p组数据均被加入到数据库k内,最后一次得到的确定系数与前一次比较,若有增加,则重新执行步骤一,获得距离-声压级数据对,依次加入数据库k并计算,直至确定系数无增加为止,最后一次拟合的公式即为求得的拟合公式。如图3所示,图中r2即为确定系数。
其它步骤及参数与具体实施方式一至三之一相同。
具体实施方式五:本实施方式与具体实施方式一至四之一不同的是:所述步骤三中进行噪声声能叠加的具体过程为:
将空间三维坐标化,设空间中的测试点的坐标值为(rx,ry,rz),每一个发声声源位置坐标为(sx,sy,sz),则测试点距声源的距离为:
将公式(2)中得到的测试点距声源的距离,带入拟合公式(1)中,求得每个声源在此测试点的声压级;设有n个声源点,每个声源点的声压级为spl1~spln,则所有声源在此测试点的总声压级,即空间中所有声源在此接受点的噪声声能叠加为:
公式(3)也可以表示为:
spltotal=10log10(10^(spl1/10)+10^(spl2/10)+…+10^(spln/10))
其它步骤及参数与具体实施方式一至四之一相同。
具体实施方式六:本实施方式与具体实施方式一至五之一不同的是:所述步骤四中得到噪声分布图的具体过程为:
根据公式(3)求得的空间中各测试点的噪声声能叠加结果,利用差值算法,求出空间中的噪声分布等高线图;
若声源随时间波动,则求出每个时间点的噪声声能叠加结果,生成时间连续的噪声分布变化动态图。由于人群发声特点,不同时间其声源是变化的,不会静止不变的。
其它步骤及参数与具体实施方式一至五之一相同。
实施例一:
本算例将模拟疏散进行过程中,空间内所有人员同时发声时的声场情况。最初空间内有10000人,随着人员人数的减少,空间内声场不断发生着变化。首先,运用疏散模拟软件模拟出不同时刻的人员位置。将初始人员数量、位置输入人员疏散模拟软件simulex,对哈尔某铁路客站候车大厅进行人员疏散运动模拟。该大厅中共36个出口,其中东西两侧检票闸口18个,南向出站口8个,北向出站口10个。红色圆点表示参加疏散的人员,人员构成中男性53.2%、女性41.5%、老人3.6%、儿童1.2%。闸机宽度0.6m,无障碍闸机一侧一个,宽度为0.9m。0s时即疏散的初始时刻,检票区人员密度为1.67人/m2,座椅区和大厅中间疏散通道人员密度0.5人/m2,各区域均匀分布。本次模拟结果得出了哈尔滨某铁路客站高架候车层疏散过程中不同时刻人员分布状态如图4-图7所示。
图4-图7所示,模拟结果得出疏散进行过程中的人员位置坐标,假定空间中布置120个接收点,分别计算每个人与这120个接收点的距离。根据公式(1)(2),就可以计算出1个人发声,这120个接收点分别接收到的声压级。为计算最不利情况,本文假定所有人都发声,其声压级为90db。将10000个人同时发声,到达120个接收点的声压级累积,根据公式(3),得出整个声场的情况。本实施例相对于单纯的仿真模拟,在保证合理精确度的情况下降低了仿真工作量,降低幅度为原有计算工作量的83.3倍。相对于传统公式计算,根据实测数据,其计算精度从3db提高到1db。
分别对疏散的初始时间和疏散进行到t时刻的人员噪声进行计算,将所得数据导入等高线软件surfer中。得出疏散进行过程中的噪声图,见图8-图10。
- 还没有人留言评论。精彩留言会获得点赞!