一种基于Hadoop的网络数据挖掘与分析平台及其方法与流程
本发明属于网络数据处理领域,尤其涉及一种基于hadoop的网络数据挖掘与分析平台及其方法。
背景技术:
近年来,“大数据”已经成为科技界和企业界关注的热点,数据已成为与自然资源、人力资源同等重要的战略资源,其所隐含的巨大社会和经济价值已引起科技界和企业也的高度重视。如果有效地组织和使用这些大数据将对社会和经济的发展起到巨大的推动作用。这些急剧增长的数据主要来自于人们的日常生活,特别是互联网已经成为我国最大的公共信息集散地和社会群体平台。与报纸、无线广播和电视等传统的传播媒体相比,网络媒体具有进入门槛低、信息超大规模、信息发布与传播迅速、参与群体庞大、实时交互性强等综合性特点,已经成为社会政治、经济各领域最快速、广泛的信息渠道。而如何从大量的互联网数据中及时发现有用信息成为政府及各行业的关注热点。
网络数据资源的特点是规模大,且来源于世界各地不同站点,分布分散,因此分布式的组织和管理成为一种必要的手段。此外,各类网络用户及网络接入点的迅速增长以及多种新型网络媒体的出现,使得各种非结构化、半结构化网络数据的数据量急剧膨胀,而传统关系型数据管理系统(并行数据库)的扩展性遇到了前所未有的障碍,使得其在处理新型数据方面显得力不从心。由于各行业所产生的数据规模巨大、形态多样、动态变化,若仍沿用传统关系数据库来存储这些非结构化数据,其存储性能和扩展性能都将成为制约数据有效应用的瓶颈。
技术实现要素:
为了解决现有技术的不足,本发明的第一目的提供一种基于hadoop的网络数据挖掘与分析平台。
本发明的一种基于hadoop的网络数据挖掘与分析平台,包括数据采集层、数据存储层、业务应用层和用户层;
所述数据采集层,采用分布式定向采集体系架构且以不同网络中的终端站点作为网络数据采集的一个基本任务单位来对原始网络数据进行采集,并向数据存储层汇聚传输;其中,每个基本任务单位采用独立的采集规则及策略;及
所述数据存储层,用于完成数据的原始网络数据的汇聚、存储及原始处理,并提供不同类型的功能调用服务;所述数据存储层采用hadoop框架实现;及
所述业务应用层,用于调取数据存储层处理后的网络数据并进行分析,来实现公有组件与个性业务应用组件剥离,并将网络数据分析后的结果传送至用户层进行实时展示。
进一步的,所述基本任务单位包括论坛数据采集单元,其用于分别通过动态网页采集方法和网页信息抽取方法对在线论坛及离线论坛内的网络数据进行采集。
本发明通过动态网页高效采集技术和网页信息抽取技术的相互结合,实时、全面、精确地获取到指定论坛网站中指定版块中的帖子及其相关元信息。
进一步的,所述基本任务单位包括博客数据采集单元,其用于负责广度遍历博客站点,目的是获取博客feed地址;对每个feed地址对应的博客进行实时采集,跟踪更新的博客文章,以增量更新方式采集博客信息。
本发明能够实时采集更新的博客数据,使得数据采集实时且准确。
进一步的,所述基本任务单位包括新闻数据采集单元,其用于采用基于行块分布函数的方法抽取新闻网页中的正文文本,进而获取新闻数据。
本发明能够直观高效准确地获取新闻数据。
进一步的,所述hadoop框架由分布式文件系统hdfs和mapreduce组成;hdfs是hadoop的文件系统,用于存储超大文件;mapreduce是hadoop的并行编程模型,用于对hdfs上存储的数据进行深度分析。
本发明的第二目的是提供一种基于所述的hadoop的网络数据挖掘与分析平台的工作方法,
本发明的一种基于hadoop的网络数据挖掘与分析平台的工作方法,包括:
数据采集层采用分布式定向采集体系架构且以不同网络中的终端站点作为网络数据采集的一个基本任务单位来对原始网络数据进行采集,并向数据存储层汇聚传输;
数据存储层完成数据的原始网络数据的汇聚、存储及原始处理,并提供不同类型的功能调用服务;
业务应用层调取数据存储层处理后的网络数据并进行分析,来实现公有组件与个性业务应用组件剥离,并将网络数据分析后的结果传送至用户层进行实时展示。
进一步的,该方法还包括:
在基本任务单位中设置论坛数据采集单元,所述论坛数据采集单元分别通过动态网页采集方法和网页信息抽取方法对在线论坛及离线论坛内的网络数据进行采集。
进一步的,该方法还包括:
在基本任务单位中设置博客数据采集单元,所述博客数据采集单元负责广度遍历博客站点,目的是获取博客feed地址;对每个feed地址对应的博客进行实时采集,跟踪更新的博客文章,以增量更新方式采集博客信息。
进一步的,该方法还包括:
在基本任务单位中设置新闻数据采集单元,所述新闻数据采集单元采用基于行块分布函数的方法抽取新闻网页中的正文文本,进而获取新闻数据。
进一步的,在数据存储层中对原始网络数据的处理过程包括:
首先,根据数据的变化分块数据,将未变化部分数据的模式存入滑窗;其次,分别计算添加和删除部分数据的模式;最后,根据变化部分数据的模式,更新滑窗中所保存的模式。
与现有技术相比,本发明的有益效果是:
(1)当前研究领域通常采用关系数据库或自定义的文件格式存储从不同网络上获取的数据,因此在扩展性、稳定性、易开发性和移植性、通用性等方面容易产生问题。本发明采用分布式hadoop架构作为网络数据的存储平台,根据各类网络数据的特征及其访问特点布置控制节点和存储节点,以提高存取性能,针对不同的网络类型提出适合于相应网络的个性化hadoop存储平台。
(2)本发明在数据存储层内,当数据变化时,通过利用原有数据中的模式,仅计算变化部分数据的模式减少模式计算量,提高算法效率,而且采用窗口技术,包括固定窗口和可变窗口两类技术分别对不同类型用户的需求进行响应,以实现较高性能实时性的网络数据监测。
附图说明
构成本申请的一部分的说明书附图用来提供对本申请的进一步理解,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。
图1是本发明的一种基于hadoop的网络数据挖掘与分析平台结构示意图。
图2是多通道数据采集的逻辑视图。
图3是垂直爬虫的架构示意图。
图4是论坛信息获取过程图。
图5是论坛的论坛的版块页面数据获取流程图。
图6是博客数据采集单元的系统架构图。
图7是博客数据采集单元的功能图。
图8是基于行块分布函数方法的正文抽取框架。
图9是hdfs的框架图。
图10是mapreduce程序的具体执行过程。
图11是mapreduce的工作原理图。
图12是本发明的一种基于hadoop的网络数据挖掘与分析平台的工作方法流程图。
具体实施方式
应该指出,以下详细说明都是例示性的,旨在对本申请提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本申请所属技术领域的普通技术人员通常理解的相同含义。
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本申请的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
图1是本发明的一种基于hadoop的网络数据挖掘与分析平台结构示意图。
如图1所示,本发明的一种基于hadoop的网络数据挖掘与分析平台,包括数据采集层、数据存储层、业务应用层和用户层;
所述数据采集层,采用分布式定向采集体系架构且以不同网络中的终端站点作为网络数据采集的一个基本任务单位来对原始网络数据进行采集,并向数据存储层汇聚传输;其中,每个基本任务单位采用独立的采集规则及策略;及
所述数据存储层,用于完成数据的原始网络数据的汇聚、存储及原始处理,并提供不同类型的功能调用服务;所述数据存储层采用hadoop框架实现;及
所述业务应用层,用于调取数据存储层处理后的网络数据并进行分析,来实现公有组件与个性业务应用组件剥离,并将网络数据分析后的结果传送至用户层进行实时展示。
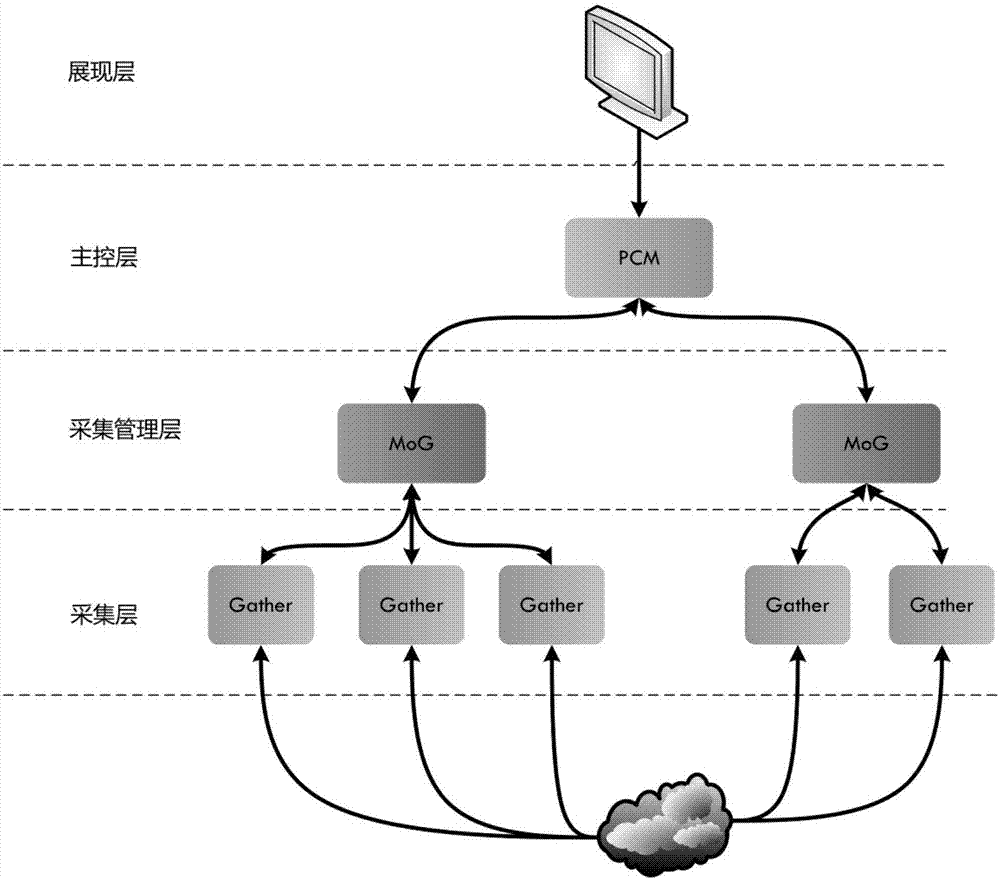
在数据采集层内,针对不同类型网络的特征,本发明采用定向采集的方法,以不同网络中的终端站点为信息采集的基本任务单位,每个采集任务都可以采用独立的采集规则和策略(如深度、采集更新频率、信息抽取模板等)。针对网络数据采集在规模和灵活性等方面的要求,采用“主从分布、自主协同”的分布式定向采集体系架构,从逻辑上划分为四个层次:采集层、采集管理层、主控层、展现层。图2给出了多通道数据采集的逻辑视图。
面对海量的网络信息及其多样化的信息形式,既要准确地识别、提取不同来源和形式的信息,又要高效、全面地采集信息,还要能够及时地跟踪信息的更新,并且尽可能减少维护的工作量。因此,本发明采用最新的垂直搜索模板半自动生成技术、动态页面优化访问技术和智能化的抓取进程调度策略,最大限度保证系统网络信息获取过程的高效性、全面性、及时性,为上层分析处理模块提供全面、稳定、安全的信息来源。垂直爬虫的架构如图3所示。
在具体实施过程中,基本任务单位包括论坛数据采集单元,其用于分别通过动态网页采集方法和网页信息抽取方法对在线论坛及离线论坛内的网络数据进行采集。
本发明通过动态网页高效采集技术和网页信息抽取技术的相互结合,实时、全面、精确地获取到指定论坛网站中指定版块中的帖子及其相关元信息。
论坛信息获取的信息源头是以版块为基本单位的。给定某个版块,对该版块的信息获取主要包括四个阶段(实际运行中可能并行):版块网页获取→版块网页抽取→帖子网页获取→帖子网页抽取。如图4所示。
基于版块入口来采集,可以直接定位所需采集的版块,这与数据的定向获取需求正好是吻合的。通过版块网页获取、版块网页信息提取、帖子网页获取和帖子网页信息提取四个阶段,将网页采集与网页信息提取进行有机结合,有效地解决了传统信息采集技术存在的诸多问题。
论坛的版块页面中有帖子的索引列表,列表中蕴含了丰富的帖子的元信息。列表中的每一行记录了一个帖子的一组元信息,包括帖子的主题、发帖人、发帖时间、点击数、回复数等。这些元信息对于论坛的数据分析是非常重要的。版块页面的组织结构通常比较有规律,基于版块页面可以有效地抽取帖子的元信息。该方法分为两个部分:①从版块页面中抽取出元数据,之所以称为元数据而不是元信息,是因为这些数据的含义(如标题、发帖人等)并不知道;②将元数据集成入库:即识别出元数据的含义(称为对元数据的解析),使元数据成为真正的元信息,保存入库。整个方法的流程如图5所示。
对于元数据的抽取,离线操作包括:用户提供一个版块页面作为样例页面,通过无监督学习方法,为与训练样例同类的版块页面生成一个模板。在线操作包括:根据模板,对新版块页面进行元数据抽取。元数据的抽取基于dom进行操作。抽取过程充分利用版块页面中帖子记录、记录中的属性与dom树中的结点之间的对应关系,以及这些结点在组织结构上的特性。上述抽取方法具有抽取效率高、定位准确、维护代价较低等优点。
在具体实施过程中,基本任务单位还包括博客数据采集单元,其用于负责广度遍历博客站点,目的是获取博客feed地址;对每个feed地址对应的博客进行实时采集,跟踪更新的博客文章,以增量更新方式采集博客信息。
采用如图6所示的系统架构,系统采用分布式设计,有一个feed发现器和多个信息采集器。feed发现模块的目标是旨在尽可能多地发现bsp下面博客的rss或atom地址。通过分析发现每个bsp博客的url地址或者rss地址,发现它们都是有一定规范的,可以通过这个策略来识别一个页面是否是博客页面,然后通过每个博客页面的链接关系去发现更多博客。
采集器负责对博客进行增量的刷新采集,并抽取新发表的博文信息,生成相应的博文信息记录并入库。功能如图7所示:
本发明能够实时采集更新的博客数据,使得数据采集实时且准确。
在具体实施过程中,基本任务单位包括新闻数据采集单元,其用于采用基于行块分布函数的方法抽取新闻网页中的正文文本,进而获取新闻数据。
新闻正文数据抽取的主要工作是从web所包含的无结构或半结构化的信息中识别用户感兴趣的信息并将其转化为结构化强、语意清晰的数据。信息抽取系统的输入是原始文本,输出是固定格式的信息。最后,把抽取出的数据经过清洗和整理后存储到关系数据库中,以供进一步的数据精确查询和模式抽取。
为方便有效的抓取新闻网页中的中文,采用基于行块分布函数的方法抽取网页中的正文文本,获取文档的核心内容。基于行块分布函数方法的正文抽取框架如图8所示。
在html中,正文和标签总掺杂在一起。不可否认,标签对文字的修饰作用在词权确定和排序结果上有很大作用。但是,也正因为html标签和正文互相交织的复杂和不规范,使得通用的正文抽取变得难以实现,最终不得不针对不同网站定义不同规则,时空复杂度也大打折扣。
基于此,本发明提出一种基于行块分布函数的通用方法,可以在线性时间o(n)内抽出正文。提出此方法核心依据有两点:1、正文区的密度,2、行块的长度。
依据1:一个网页的正文区域肯定是文字信息分布最密集的区域之一,这个区域可能最大但不尽然,比如评论信息较长,或者网页正文新闻较短,而又出现大篇紧密导航信息时,也会出现正文的区域不是最大块的可能。
依据2:行块的长度信息可以有效解决上述问题。
依据1和依据2相结合,就能很好的实现正文提取。将依据1和2融合在行块分布函数里。具体如下:
首先将网页html去净标签,只留所有正文,同时留下标签去除后的所有空白位置信息,留下的正文称为ctext。
定义1.行块:
以ctext中的行号为轴,取其周围k行(上下文均可,k<5,这里取k=3,方向向下,k称为行块厚度),合起来称为一个行块cblock,行块i是以ctext中行号i为轴的行块;
定义2.行块长度:
一个cblock,去掉其中的所有空白符(\n,\r,\t等)后的字符总数称为该行块的长度;
定义3.行块分布函数:
以ctext每行为轴,共有linesnum(ctext)-k个cblock,做出以[1,linesnum(ctext)-k]为横轴,以其各自的行块长度为纵轴的分布函数;
行块分布函数可以在o(n)时间求得,在行块分布函数图上可以直观的看出正文所在区域。由上述行块分布函数图可明显看出,正确的文本区域全都是分布函数图上含有最值且连续的一个区域,这个区域往往含有一个骤升点和一个骤降点。
于是,网页正文抽取问题转化为了求行块分布函数上的骤升骤降两个边界点,这两个边界点所含的区域包含了当前网页的行块长度最大值并且是连续的。
求正文区域所在的气势行块号xstart和中指行块号xend(x为行号,y(x)是以x为轴的行块长度),需要满足以下四个条件:
(1)y(xstart)>y(xt)(y(xt)是第一个骤升点,骤升点必须超过某一阈值);
(2)y(xn)≠0(n∈[start+1,start+k],k是行块厚度,紧随骤升点的行块长度不能为0,避免噪声);
(3)y(xm)=0(m∈[end,end+1],骤降点击器尾随的行块长度为0,保证征文结束);
(4)存在x,当取到max(y(x))时,x∈[xstart,xend](保证此区域是渠道行块最大值的区域)。
本发明能够直观高效准确地获取新闻数据。
在具体实施过程中,hadoop框架由分布式文件系统hdfs和mapreduce组成;hdfs是hadoop的文件系统,用于存储超大文件;mapreduce是hadoop的并行编程模型,用于对hdfs上存储的数据进行深度分析。
hadoop实现了一个分布式文件系统(hadoopdistributedfilesystem),简称hdfs。hdfs最开始是作为apachenutch搜索引擎项目的基础架构而开发的。
hdfs主要由client、datanode和namenode组成,其框架如图9所示。一个使用hadoop技术架构的集群中,一般有一到两台主机作为namenode,若干台主机作为datanode。client代表使用hdfs的客户程序;namenode是hadoop集群中的一台主机,负责保存数据节点的信息、计算任务的分发以及最终规约等任务;datanode负责数据存储与处理。为保证数据的安全性,hdfs适度增加了冗余数据。具体的做法是在不同的datanode中保存同一数据的多份拷贝,一般为三份拷贝。
一个客户端创建一个文件的请求并不会立即转发到namenode。实际上,一开始hdfs客户端将文件数据缓存在本地的临时文件中。应用程序的写操作被透明地重定向到这个临时本地文件。当本地文件堆积到一个hdfs块大小的时候,客户端才会通知namenode。namenode将文件名插入到文件系统层次中,然后为它分配一个数据块。namenode构造包括datanodeid(可能是多个,副本数据块存放的节点也有)和目标数据块标识的报文,用它回复客户端的请求。客户端收到后将本地的临时文件刷新到指定的datanode数据块中。
当文件关闭时,本地临时文件中未残留的数据就会被转送到datanode。然后客户端就可以通知namenode文件已经关闭。此时,namenode将文件的创建操作添加到到持久化存储中。假如namenode在文件关闭之前死掉,文件就丢掉了。
当客户端写数据到hdfs文件中时,如上所述,数据首先被写入本地文件中,假设hdfs文件的复制因子是3,当本地文件堆积到一块大小的数据,客户端从namenode获得一个datanode的列表。这个列表也包含存放数据块副本的datanode。当客户端刷新数据块到第一个datanode。第一个datanode开始以4kb为单元接收数据,将每一小块都写到本地库中,同时将每一小块都传送到列表中的第二个datanode。同理,第二个datanode将小块数据写入本地库中同时传给第三个datanode,第三个datanode直接写到本地库中。一个datanode在接前一个节点数据的同时,还可以将数据流水式传递给下一个节点,所以,数据是流水式地从一个datanode传递到下一个。
在数据处理过程中hadoop采用mapreduce技术。mapreduce是一种编程模型,用于大规模数据集(大于1tb)的并行运算。概念“map(映射)”和“reduce(归约)”,和它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。当前的软件实现是指定一个map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
mapreduce程序的具体执行过程如图10所示:首先对数据源进行分块,然后交给多个map任务去执行,map任务执行map函数,根据某种规则对数据分类,写入本地硬盘;map阶段完成后,进入reduce阶段,reduce任务执行reduce函数,具有同样key值的中间结果,从多个map任务所在的节点,被收集到一起(shuffle)进行合并处理,输出结果写入本地硬盘(分布式文件系统)。程序的最终结果可以通过合并所有reduce任务的输出得到。
图11给出了mapreduce的工作原理。一切都是从最上方的userprogram开始的,userprogram链接了mapreduce库,实现了最基本的map函数和reduce函数。
(1)mapreduce库先把userprogram的输入文件划分为m份(m为用户定义),每一份通常有16mb到64mb,如图11左方所示分成了split0~4;然后使用fork将用户进程拷贝到集群内其它机器上。
(2)userprogram的副本中有一个称为master,其余称为worker,master是负责调度的,为空闲worker分配作业(map作业或者reduce作业),worker的数量也是可以由用户指定的。
(3)被分配了map作业的worker,开始读取对应分片的输入数据,map作业数量是由m决定的,和split一一对应;map作业从输入数据中抽取出键值对,每一个键值对都作为参数传递给map函数,map函数产生的中间键值对被缓存在内存中。
(4)缓存的中间键值对会被定期写入本地磁盘,而且被分为r个区,r的大小是由用户定义的,将来每个区会对应一个reduce作业;这些中间键值对的位置会被通报给master,master负责将信息转发给reduceworker。
(5)master通知分配了reduce作业的worker它负责的分区在什么位置(肯定不止一个地方,每个map作业产生的中间键值对都可能映射到所有r个不同分区),当reduceworker把所有它负责的中间键值对都读过来后,先对它们进行排序,使得相同键的键值对聚集在一起。因为不同的键可能会映射到同一个分区也就是同一个reduce作业(谁让分区少呢),所以排序是必须的。
(6)reduceworker遍历排序后的中间键值对,对于每个唯一的键,都将键与关联的值传递给reduce函数,reduce函数产生的输出会添加到这个分区的输出文件中。
(7)当所有的map和reduce作业都完成了,master唤醒正版的userprogram,mapreduce函数调用返回userprogram的代码。
所有执行完毕后,mapreduce输出放在了r个分区的输出文件中(分别对应一个reduce作业)。用户通常并不需要合并这r个文件,而是将其作为输入交给另一个mapreduce程序处理。整个过程中,输入数据是来自底层分布式文件系统(gfs)的,中间数据是放在本地文件系统的,最终输出数据是写入底层分布式文件系统(gfs)的。而且我们要注意map/reduce作业和map/reduce函数的区别:map作业处理一个输入数据的分片,可能需要调用多次map函数来处理每个输入键值对;reduce作业处理一个分区的中间键值对,期间要对每个不同的键调用一次reduce函数,reduce作业最终也对应一个输出文件。
图12是本发明的一种基于所述的hadoop的网络数据挖掘与分析平台的工作方法流程图。
如图12所示,本发明的一种基于hadoop的网络数据挖掘与分析平台的工作方法,包括:
(1)数据采集层采用分布式定向采集体系架构且以不同网络中的终端站点作为网络数据采集的一个基本任务单位来对原始网络数据进行采集,并向数据存储层汇聚传输;
(2)数据存储层完成数据的原始网络数据的汇聚、存储及原始处理,并提供不同类型的功能调用服务;
(3)业务应用层调取数据存储层处理后的网络数据并进行分析,来实现公有组件与个性业务应用组件剥离,并将网络数据分析后的结果传送至用户层进行实时展示。
进一步的,该方法还包括:
在基本任务单位中设置论坛数据采集单元,所述论坛数据采集单元分别通过动态网页采集方法和网页信息抽取方法对在线论坛及离线论坛内的网络数据进行采集。
进一步的,该方法还包括:
在基本任务单位中设置博客数据采集单元,所述博客数据采集单元负责广度遍历博客站点,目的是获取博客feed地址;对每个feed地址对应的博客进行实时采集,跟踪更新的博客文章,以增量更新方式采集博客信息。
进一步的,该方法还包括:
在基本任务单位中设置新闻数据采集单元,所述新闻数据采集单元采用基于行块分布函数的方法抽取新闻网页中的正文文本,进而获取新闻数据。
从网络前端所采集到的数据将放置到分布式阵列中暂存,之后阵列中的数据将被批量写入到hadoop数据存储和处理平台中进行持久化存储,然而hadoop的设计并不适合于用户的交互式查询,因此在实时性方面hadoop很难达到较高的用户满意度。因此,为满足网络数据的实时性检测需求,流数据存储还为用户提供了一种与hadoop中静态数据不同的动态数据形式——流数据。对这些流数据的及时有效处理,对监控的实时性意义重大。因此,针对流数据挖掘与分析算法中的难点,本功能模块采用窗口技术来分块所要处理的数据,主要包括滑动窗口和多窗口两项关键技术。
在滑动窗口上进行数据挖掘最大的困难在于过期数据的移除。随着数据的流入,滑动窗口中最早到达的数据将滑出窗口的范围,算法需要消除这些数据对滑动窗口上的目标计算所造成的影响。解决这个问题的最直接的做法是保存滑动窗口内的所有数据,当某个数据滑出窗口时,根据这个数据的值,将其从计算结果中消除。
为减少滑动窗口内数据所占用的空间,使用小于滑动窗口内数据体积的空间,支持滑动窗口上计算的增量式更新。将数据流划分为小的固定长度的段,对每个段,仅保存段内数据的概要信息。滑动窗口在这些段上滑动。当流入的数据积累成一段时,抽取这一段的概要信息,将其加入滑动窗口,并从滑动窗口中删除最早的段。这样,内存中就只需要保存滑动窗口中多个段的概要信息。此时,滑动窗口的增量式更新粒度由一个数据项增大为一个数据段。
基于滑动窗口的方法一般都要求用户事先指定窗口大小,算法在运行过程中只能给出此滑动窗口上的计算结果。然而当面对用户针对性地提出某个窗口上的挖掘请求时,窗口的大小很难事先确定,而且窗口的终点可能也不是当前时刻。因此,滑动窗口就不能够完全满足用户要求了,为了支持这样的应用需求,本发明使用多窗口方法,支持用户的在线挖掘请求。
多窗口技术将数据流划分为多个固定长度的段,每个段都形成一个窗口。当内存中的窗口数达到一定数目时,就将这多个窗口合并,形成概要层次更高的窗口随着数据流的流入,概要层次不同的多个窗口形成一个层次结构。此时,每个窗口相当于对数据流上两个预定义的时间戳之间数据的一个快照。
与时序相关的流数据,在保持一定稳定性的同时,又具有一定的变化性,部分原有数据将被新的数据所替换,也即删除数据若干元素的同时还需添加新的数据。当前的流数据挖掘算法可以很好地处理单一添加或删除操作的模式挖掘,然而均很难应付添加与删除的同时操作。本发明采用滑窗模型来描述流数据的变化。
如图12所示,第一行为某i时刻两个连续的数据dn和dp。在流数据中,关注的是数据所包含模式的变化,因此假设dn和dp的模式不同。第三行位i+1时刻dn和dp变为两个新的数据newdn和newdp。第二行给出了数据变化情况的说明,其中δn和▽n分别是dn在变为dn时所增加和删除的部分数据。而δp和▽p分别dp在变为newdp时所增加和删除的部分数据。因为dn和dp为两个连续的数据,因此在变化时dn所添加的部分数据与所dp删除的部分数据相同,也即δn=▽p。
使用已有的对比模式算法需要分别对dn和dp以及newdn和newdp的模式进行识别。然而dn在演变为newdn,以及dp在演变为newdp时仍有部分数据是保持稳定的,而已有算法在挖掘新数据模式时无法重用已有数据中的模式,造成在流数据挖掘模式的效率低下。
本发明使用滑窗模型保存原有数据中的模式,仅对δp、▽p和▽n中的模式进行识别,并对δp和▽p以及δn和▽n的不同进行对比,找出模式的变动再对滑窗中所保存的模式进行更新,以减少数据的处理量提高挖掘效率。主要包括以下关键步骤:首先,根据数据的变化分块数据,将未变化部分数据的模式存入滑窗;其次,分别计算添加和删除部分数据的模式;最后,根据变化部分数据的模式,更新滑窗中所保存的模式。
上述虽然结合附图对本发明的具体实施方式进行了描述,但并非对本发明保护范围的限制,所属领域技术人员应该明白,在本发明的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本发明的保护范围以内。
- 还没有人留言评论。精彩留言会获得点赞!