一种基于多源正负外部反馈信息的查询扩展方法与流程
本发明属于文字信息处理领域,尤其涉及一种基于多源正负外部反馈信息的查询扩展方法。
背景技术:
社交媒体(例如twitter,facebook,google+)的出现深刻地改变了人们的生产和消费信息的方式,他和主流新闻媒体网站(如cnn或nytimes)最大的不同是社交网络中的人即是信息的消费者也是信息的生产者,由于社交网络中的信息不仅来源多样并且杂乱无章,这增加了用户获取信息的难度。
传统方法查询扩展方法按照扩展源的不同主要分为两种:1)以本地查询文档集为扩展源的本地查询扩展方法2)以外部知识基为扩展源的全局扩展方法。第一种方法多采用文本聚类、潜语义索引(latentsemanticindexing,简称lsi)和相似性词典等方法扩展查询,但由于本地语料集构成相对固定,规模较小,不能很好的反应用户真实查询意图。第二种方法常使用wordnet、wiki-pedia等公共数据资源作为外部扩展源,能更加详尽的表述用户查询,但在引入外部信息的过程中不可避免的会引入歧义错误的信息,增加查询扩展的风险。
技术实现要素:
本发明要解决的技术问题是,提供一种基于多源正负外部反馈信息的查询扩展方法,在融合外部查询信息的过程中通过引入正则约束减少扩展风险,能快速有效构建新的查询,使得检索结果更符合用户需求。
为实现上述目的,本发明采用如下的技术方案:
一种基于多源正负外部反馈信息的查询扩展方法包括以下步骤:
步骤(1)、获取tweets博文
步骤(2)、获得用户兴趣词
步骤(3)、tweets预处理
步骤(4)、构建本地检索引擎
使用apache开源检索框架lucene作为本地检索引擎主程序,以预处理后的tweets博文作为索引内容,tweetsid为索引目标,构建本地搜索引擎;
步骤(5)、扩展查询,其包括以下步骤:
步骤(5.1)使用用户兴趣词得到第一次查询反馈
使用q表示用户查询兴趣词,将q放入本地搜索引擎,得到前100条反馈结果,作为第一次查询反馈,构建词项文档矩阵l,l的行代表词,列代表一条反馈文档,矩阵的值表示词在文档中出现次数;
步骤(5.2)获取外部信息
利用爬虫技术,将q放入多个外部搜索引擎,得到前100条反馈结果作为外部反馈信息可以将每个搜索引擎获取文档集合表示为e1,e2,e3…em,取第n个外部反馈信息的前m条反馈结果作为正向反馈,构建词项文档矩阵pn,取第n个外部反馈信息的前2m~3m条反馈结果作为负向反馈,构建词项文档矩阵nn;其中m和n均为自然整数,取值为1到正无穷;
步骤(5.3)对反馈外部信息聚类
分别将稀疏矩阵l、pn、nn分解为两个稠密矩阵相乘的形式,如公式1所示,其中分解后的矩阵u、an,bn表示反馈结果的分布情况,矩阵u表示用户查询意图;由于期望原始反馈l的分布情况和正向反馈pn的分布尽可能相似,和负向反馈nn的分布尽可能远离,同时在分解过程中使用相同的聚类中心矩阵h对分解过程进行约束,保证分解的稳定性和有效性,因此,多源信息查询扩展建模最终的稀疏学习优化目标为公式(1),其中,αβγ表示对正则项约束程度调节参数。
针对此优化目标应用kkt(karush-kuhn-tucker)条件,在保证矩阵非负的情况下,得到迭代条件如下,公式2-5中,i和j分别代表矩阵的第i行和第j列,
使用nmf一般解法求解优化函数(1),为保证分解过程中公式中各项均为正,采用karush-kuhn-tucker(kkt)condition.得到迭代公式2~5,其中,ktt条件是指在满足在有规则的条件下,一个非线性规划(nonlinearprogramming)问题能有最优化解法的一个必要和充分条件。
步骤(5.4)挑选类中心向量,找出扩展词
设u为根据用户兴趣反馈构建的一个i行*j列的矩阵,将u的每一列表示一个用户查询意图,则挑选其中查询词占比最大的一列作为最终的用户真实查询意图向量;向量中的值表示每个词和用户查询意图的关系。按照从大到小排序,选择前k个作为查询扩展词;
步骤(6)再次检索
将原始查询词和扩展词作为新的检索词,放入本地搜索引擎中检索,返回的结果即为最终检索结果。
作为优选,所述tweets博文由编号和正文两部分组成。
作为优选,所述用户兴趣文件由编号、查询词和兴趣描述三部分组成,从中解析出用户的查询词作为用户兴趣词。
作为优选,步骤(3)tweets预处理包括:
步骤(3.1)滤除非英文tweets和长度小于两个单词的tweets。
步骤(3.2)去除tweets中的标点符号,数字,url,将所有的字母转换为小写;
步骤(3.3)对于tweets基于简单空格进行分词并去除停用词。
本发明的基于多源正负外部反馈信息的查询扩展方法,在融合外部查询信息的过程中通过引入正则约束减少扩展风险。它能快速有效构建新的查询,使得检索结果更符合用户需求。采用本发明的技术方案,与传统的反馈检索方法相比,具有性能明显提升的效果。
附图说明
图1本发明的查询扩展方法的示意图;
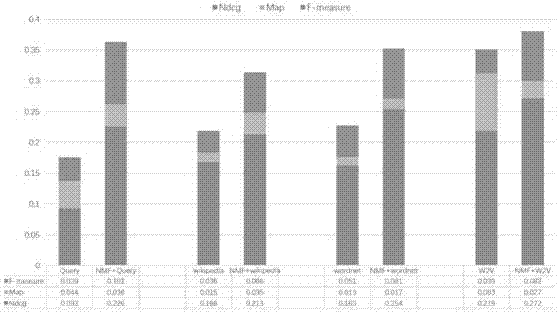
图2不同查询扩展方法比较性能柱状图;
图3不同参数较性能柱状图
具体实施方式
如图1所示,本发明实施例提供一种基于多源正负外部反馈信息的查询扩展方法包括以下步骤:
步骤(1)获取tweets博文
获取tweets博文,博文由编号和正文两部分组成
步骤(2)获得用户兴趣词
用户兴趣文件由编号,查询词,兴趣描述三部分组成,从中解析出用户的查询词作为用户兴趣词。
步骤(3)tweets预处理
步骤(3.1)滤除非英文tweets和长度小于两个单词的tweets。
步骤(3.2)去除tweets中的标点符号,数字,url,将所有的字母转换为小写;
步骤(3.3)对于tweets基于简单空格进行分词并去除停用词,英文的不同词形当成不同的词,例如“organ”和“organs”当成是两个不同的词。
步骤(4)构建本地检索引擎
使用lucene以预处理后的tweets内容为索引内容,tweetsid为索引,使用bm25相似度模型,构建本地搜索引擎。
步骤(5)查询扩展
步骤(5.1)以用户兴趣词为查询语句得到第一次查询反馈
使用q表示用户查询兴趣词,将q放入本地搜索引擎,得到前100条反馈结果,作为第一次查询反馈构建词项文档矩阵l。l的行代表词,列代表一条反馈文档,矩阵的值表示词在文档中出现次数。
步骤(5.2)获取外部信息
利用爬虫技术,将q放入多个外部搜索引擎,得到前100条反馈结果作为外部反馈信息可以将每个搜索引擎获取文档集合表示为e1,e2,e3…en,取第n个外部反馈信息的前m条反馈结果作为正向反馈,构建词项文档矩阵pn,取第n个外部反馈信息的前2m~3m条反馈结果作为负向反馈,构建词项文档矩阵nn;其中,m和n均为自然整数,取值为1到正无穷;
步骤(5.3)对反馈聚类
分别将稀疏矩阵l、pn、nn分解为两个稠密矩阵相乘的形式,如公式1所示,其中分解后的矩阵u、an,bn表示反馈结果的分布情况,矩阵u表示用户查询意图。我们期望原始反馈l的分布情况和正向反馈pn的分布尽可能相似,和负向反馈nn的分布尽可能远离,同时在分解过程中使用相同的聚类中心矩阵h对分解过程进行约束,保证分解的稳定性和有效性。因此,多源信息查询扩展建模最终的稀疏学习优化目标为公式(1),其中,αβγ表示对正则项约束程度调节参数。
针对此优化目标我们应用kkt(karush-kuhn-tucker)条件,在保证矩阵非负的情况下,得到迭代条件如下,公式2-5中,i和j分别代表矩阵的第i行和第j列,
我们使用nmf一般解法求解优化函数(1),为保证分解过程中公式中各项均为正,我们采用karush-kuhn-tucker(kkt)condition.得到迭代公式eq.(2~5).其中,ktt条件是指在满足一些有规则的条件下,一个非线性规划(nonlinearprogramming)问题能有最优化解法的一个必要和充分条件.
步骤(5.4)挑选类中心向量,找出扩展词
因为u为根据用户兴趣反馈构建的一个i行*j列的矩阵,那么我们可以将u的每一列表示一个用户查询意图,则挑选其中查询词占比最大的一列作为最终的用户真实查询意图向量。向量中的值表示每个词和用户查询意图的关系。按照从大到小排序,选择前3个作为查询扩展词
步骤(6)再次检索
将原始查询词和扩展词作为新的检索词,放入本地搜索引擎中检索,返回数据为最终检索结果。图2给出了博文检测指标ndcg、map和f值,从图中可以看出本方法较其他方法性能有很大提升。图3展示了在选取不同扩展源个数不同参数条件下,算法性能比较,可以看出在选择两个扩展源时性能最好,这是因为过多的扩展源会带来更多的噪声,不利于逼近真实用户兴趣。
- 还没有人留言评论。精彩留言会获得点赞!