一种社交网络信息传播检测节点的选择方法与流程
本发明涉及信息传播检测方法,特别涉及一种社交网络信息传播检测节点的选择方法。
背景技术:
社会网络(socialnetwork)是指社会个体之间通过社会关系结成的复杂网络体系,它由社会中的个体以及个体之间的关系组成。近几年,以twitter、facebook、微博、微信等为代表的在线社会网络迅速发展,基于社会网络的信息传播(informationdiffusion)也越来越深入和广泛,传播对象包括新闻事件、社会热点、时尚潮流,或者新发明、新创造、新思想,也有可能是网络谣言等等。社会网络中的信息传播与传统媒介中的信息传播相比,呈现出大规模性、多模态性、实时性、快速性等特点,其对经济社会和国家公共安全的影响越来越深入。在2011年爆发的“埃及革命”中,不法分子利用twitter和facebook等社会网络或媒体大肆造谣,煽动民意,传播恶意信息并组织犯罪活动,在社交媒体的推波助澜下,骚乱被极度放大并快速演变。在2013年4月四川“雅安地震”爆发后,微博成为最有力的信息传播媒体,各类政务微博、意见领袖、草根账号等充分利用微博的信息扩散能力,发布地震救援提示,为抗震救灾发挥积极作用.但是另一方面,也有不法分子利用微博传播谣言,欺骗公众,造成社会不安和民众恐慌,带来极坏的后果.对于社会网络中的信息传播,如何快速获取其中的信息传播态势,及时发现当前流行的热点事件或不良社会思潮,成为亟待解决的问题,这对于舆情监控和维护国家公共安全具有重要意义。对于大规模社会网络和海量数据信息,为了降低检测成本的同时保证检测效果通常会选取传播网络中有限的节点作为观察节点,通过跟踪这些观察节点的状态变化或分析其发布的信息来检测整个网络中的信息传播态势。
在本发明作出之前,近几年,有些研究学者已经对信息传播检测方法进行了研究,如:文献physicalreviewletters,2012,109(6)中刊登的“locatingthesourceofdiffusioniniargescalenetwork”对网络中如何确定信息传播源进行了研究,通过在网络中稀疏地布置传感器,获得观察节点感染信息的不同时间,文章给出一个有效算法,对任意树状传播网络可以在o(n)时间内,对于任意传播图可以在o(n3)时间内以一定的精度确定信息传播源。proceedingsofthe10thacmconferenceonelectroniccommerce刊登的“a.socialinfluenceandthediffusionofusercreatedcontent”对信息传播的早期接受者(earlyadopter)研究表明,这些人通常不具有很多的关注者(节点入度较小),他们的社交网络在线时间也低于平均在线时间.the18thacmsigkddinternationalconferenceonknowledgediscoveryanddatamining刊登的“”研究了趋势发起者(trendsetter)的特点,趋势发起者是网络中出现的热点趋势的早期接受者和传播者,文章结合时间演化因素,基于pagerank思想,给出了一个挖掘不同话题领域趋势发起者的算法.the13thacmsigkddinternationalconferenceonknowledgediscoveryanddatamining上刊登的“costeffectiveoutbreakdetectioninnetworks”针对博客网络中信息暴发检测(outbreakdetection)提出了基于次模特性(submodularity)的贪心算法celf。文章将信息检测问题抽象为一组需要最大化的目标函数r(a),a表示需要部署传感器的观察节点集合。r(a)可以是由k个节点检测到的信息传播级联的数量,或者由此带来的信息传播感染人数的减少量.文章证明了r(a)具有次模特性,基于此提出一个启发式贪心算法celf.chinesejournalofcomputers上刊登的“anovelalgorithmforinformationdiffusiondetectioninsocialnetwork”提出一种传播能力排序算法diffrank,根据算法结果选取传播能力最强的k个节点作为观察节点来检测整体网络信息传播态势,
在现有的相关研究中,大部分算法以对社会网络中的关系结构为出发点,忽略了交互结构,无法达到令人满意的效果。
技术实现要素:
本发明的目的就在于克服上述缺陷,提供一种社交网络信息传播检测节点的选择方法。
本发明的技术方案是:
一种社交网络信息传播检测节点的选择方法,其主要技术特征是:
4)定义话题相似性,关键词相似性,并建立“用户-话题-关键词”三个层次的用户话题兴趣偏好模型;
5)融合节点关系和节点话题偏好的社会网络中用户节点的相似性计算方法;
6)基于随机游走策略的社会网络信息传播检测节点排序方法。
所述建立“用户-话题-关键词”三个层次的用户话题兴趣偏好模型,其步骤:
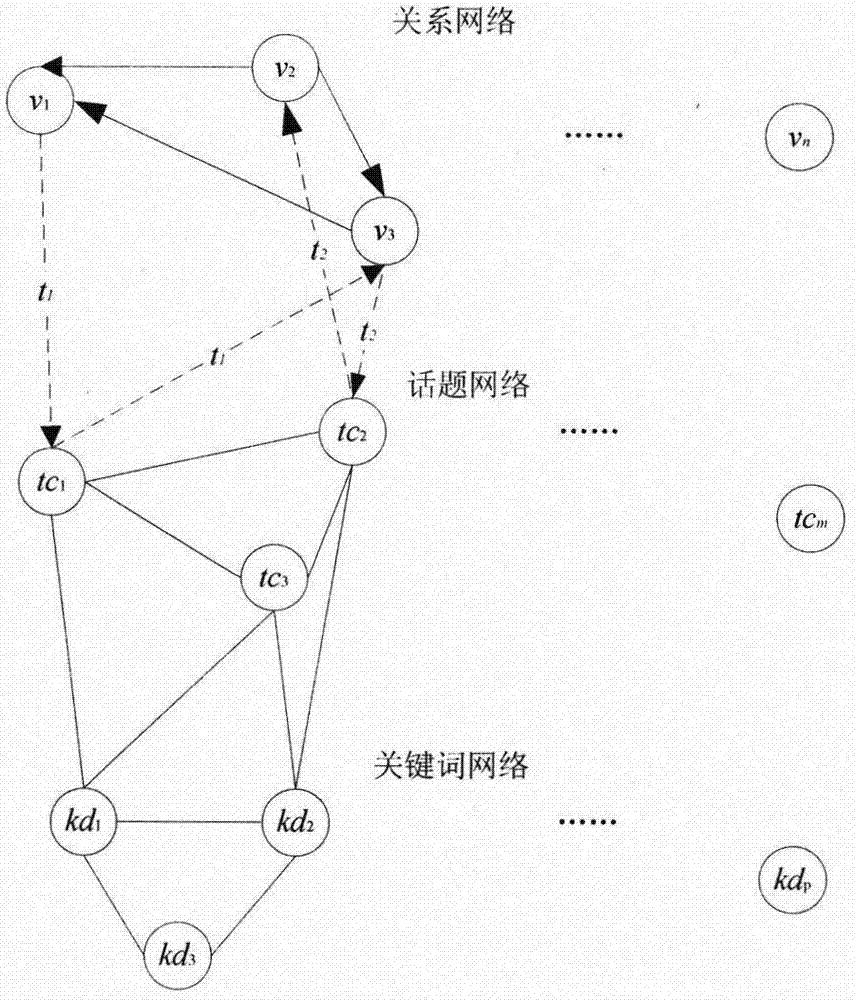
1)从社会网络的日志文件中获得每个用户发布和接收的话题信息;
2)如果两个用户之间进行了通信,则产生一条从发送用户到被发送用户的有向边;
3)当话题中包含一个关键词时,则从主题到该关键词产生一条无向边;
4)用户发布一个主题,则从用户到话题建立一条有向连边,如果用户接收一个话题,则从话题到用户建立一条有向连边;
5)定义话题的相似性,如果两个话题的相似性超过阈值则以这两个主题为端点,建立一条无向边;
6)定义关键词的相似性,如果两个关键词的相似性超过阈值则以这两个关键词为端点,建立一条无向边。
所述融合节点关系和节点话题偏好的社会网络中用户节点的相似性计算方法步骤是:
1)给出用户结构相似性的计算方法;
2)给出用户话题偏好相似性的计算方法;
3)给出融合用户结构相似性和用户话题偏好相似性的社会网络用户节点的相似性计算方法。
所述基于随机游走策略的社会网络信息传播检测节点排序方法,具体包括步骤:
1)给出信息传播概率的定义和计算公式;
2)结合用户节点相似度和节点间传播概率生成传播概率图及转移概率矩阵;
3)在传播概率图上进行有偏随机游走,得到每个节点的传播能力度量。
针对以上情况,本发明从社会网络信息传播的角度出发,提出一种融合节点结构关系和节点话题偏好的用户节点重要性排序方法。
本发明的优点在于:社会网络信息传播检测节点的选择综合考虑了用户结构相似性和用户话题偏好相似性,可以根据不同的社会网络动态的调整平衡参数,具有更好的检测效率,并从社会网络中的关系结构和交互结构共同促进网络演化方面为基础,从更深层次考虑社会网络关系结构和交互结构的关系问题,取得了比较满意的效果。
附图说明
图1——本发明流程示意图。
图2——本发明建立用户话题偏好模型示意图。
具体实施方式
本发明的技术思路是:
1998提出了著名的pagerank算法,该算法用于对网络页面节点的重要性进行排序,并成功应用该算法创立了google搜索引擎。该算法主要利用了马尔可夫随机游走模型,为了将网页与该随机游走模型对应,将网页与模型中的粒子对应,将网页的有向链接结构与粒子前进对应,这样网页的链接跳转概率就被成功地转换为了粒子前进的概率转移。因为不同的网页节点具有不同的中心度和影响力,因此网页节点在马尔可夫随机游走模型下获得的点击概率也可能不同,依据不同的点击概率来对网页节点进行排名是pagerank的主要思想。研究表明具有较高节点入度的节点并不一定具有很大的影响力。通过这些方法通常找到的是网络中的核心节点,或是某领域的“意见领袖”。社会网络中的信息传播受节点影响力的影响,但是影响力最大并不一定就表示传播能力最强,因为影响力分析算法没有考虑节点对各种信息流的参与程度及发布文章或传播信息的规模等因素。现有的算法对社会网络中的关系结构和交互结构共同促进网络演化方面考虑不足,没有从更深层次考虑社会网络关系结构和交互结构的关系问题。
本发明的主要技术特征体现在:
1)建立“用户-话题-关键词”三个层次的用户话题兴趣偏好模型
具体技术路线是:1.用户、话题和关键词的相互关联关系在它们之间建立边;2.通过“用户-话题-关键词”三个层次的用户话题兴趣偏好模型可以完整地保存用户的所有信息,为后续分析提供了基础。
2)设计融合节点关系和节点话题偏好的社会网络中用户节点的相似性计算方法。
具体技术路线:1.定义用户结构相似性的计算公式;2.定义用户话题偏好相似性的计算公式;3.设定权衡参数来定义融合用户结构相似性和用户话题偏好相似性的社会网络用户节点的相似性计算方法。
下面具体说明本发明,其流程如“图1——本发明流程示意图”所示。
1)定义主题相似性,关键词相似性,并建立“用户-话题-关键词”三个层次的用户话题兴趣偏好模型
用户信息传播分析建立在一个用户话题兴趣偏好模型中,然后利用网络分析方法对其进行分析,具体的建立“用户-话题-关键词”三个层次用户话题兴趣偏好模型的方法步骤如下:
●从社会网络网站的日志文件中获取每个用户的活动信息,包括:通信信息、发送和接收话题信息等;
●建立一个三个层次的网络模型,网络中的节点包括:用户、话题和关键词,示意图如“图2——本发明建立用户话题偏好模型示意图”所示。
●节点之间的连接包括以下几种情况:a)如果两个用户之间进行了通信,则产生一条从发送用户到被发送用户的有向边;b)当话题中包含一个关键词时,则从话题到该关键词产生一条无向边;c)用户发布一个话题,则从用户到主题建立一条有向连边,如果用户接收一个话题,则从主题到用户建立一条有向连边。d)定义话题的相似性,第i个主题和第j个主题的相似性计算公式为:
2)设计融合节点关系和节点话题偏好的社会网络中用户节点的相似性计算方法。
“物以类聚”的现象在社会网络中广泛存在,研究表明:节点之间的相似度与节点之间的影响力存在正相关关系,也是影响信息传播的主要因素之一。节点vi和vj之间的相似度用sim(vi,vj)表示,本专利选取节点的结构相似度和用户话题偏好相似性两个维度来衡量节点的相似性。融合节点关系和节点话题偏好的社会网络中用户节点的相似性计算方法:
●用户结构相似性使用公式
●用户话题偏好相似性通过计算两个用户话题偏好向量的内积得到,
●融合节点关系和节点话题偏好的社会网络中用户节点的相似性计算方。sims(vi,vj)=b×sims(vi,vj)+(1-b)×simt(vi,vj),其中参数b∈[0,1]用来权衡用户结构相似和用户话题偏好所占的比例。
3)基于随机游走策略的社会网络信息传播检测节点排序方法。
具体实现如下:
●首先给出传播概率p(vi,vj)的计算公式:
定义1:在图gr=(v,e)中,对于信息级联c,若节点vi∈c,并且
将c中所有信息级联c进行分解,每个级联都分解为l(c)个单步(vi→vj,ti),最后获取gr=(v,e)中各边对应的总传输次数nij。传播概率高的节点之间通常会表现出更多的传播次数,因此p(vi,vj)与vi到vj之间的传播次数成正比,选取指数关系模型。因此有
●结合用户节点相似度和节点间传播概率可以生成基于gr=(v,e)的传播概率图,其邻接矩阵用an×n表示,
●在传播概率图上进行有偏随机游走,随机游走的每一步按照公式r=d×qr+(1-d)×e迭代进行,其中r是一个n维向量,每个分量r(i)代表随机游走结束后对应节点vi的被访问概率,很多粒子同时在传播概率图上游走,每个节点都是一个“吸引子”,其吸引力代表节点的传播能力,游走过程分为两部,第1部分按概率d游走到节点的邻居节点;第2部分按照概率(1-d)随机跳跃到网络中的任意节点,各节点被随机访问的概率由向量e决定,有偏的随机游走通过对向量e的各个分量赋予不同的值,来表示离子随机跳转到各个节点的不同偏好,也就是各个“吸引子”的吸引力不同。对于信息传播级联c中的节点,其接收到消息越早,位置约靠近c的前端,表示其传播力越强,对应的e(i)的取值也越大。根据e(i)的取值进行排序得到的结果即为基于随机游走策略的社会网络信息传播检测节点的最终排序。
- 还没有人留言评论。精彩留言会获得点赞!