一种基于并行环路检测的虚开增值税专用发票检测方法与流程
本发明属于计算机技术领域,具体涉及一种基于并行环路检测的虚开增值税专用发票检测方法。
背景技术:
在公司交易间,在开具增值税发票后,会有相对应的资金交易,以表明该笔交易是真实存在的,开具的税票是对应了真实的业务往来;但是实际上该笔资金,会经过多个账号后,重新回到起点账户,并没有实际的业务往来,即交易是虚假的,这种行为即虚开增值税专用发票。
增值税是我国1994年开始全面实施的新税种,它对于减少税收环节,合理征税,促进税收具有十分重要的意义。而虚开增值税专用发票行为违反了发票管理制度,同时虚开增值税专用发票可以抵扣大量税款,造成国家税款的大量流失,也严重地破坏了社会主义经济秩序。
由于近年来,虚开增值税专用发票的犯罪活动十分猖獗,审判实践中,对虚开增值税专用发票罪的认定存在诸多问题。同时,以往通过人工手动查找虚开增值税专用发票也是为虚开增值税专用发票罪的认定带来了很大的困难,费时费力。
从上述的描述中,可以发现,虚开增值税专用发票行为中资金会经过多个账号后重新回到起点账户,所以将账号抽象为点,账户间的资金流转行为抽象为边,虚开增值税专用发票行为的资金流转会形成一个环路,所以通过环路检测的方式可以适应虚开增值税专用发票的自动查找。但是,在银行开户的企业数目十分巨大,也就带来了大量的原始数据,而传统的环路检测方法的计算效率较为低下,当计算数据过大时耗时会十分长。而本专利提出的并行环路检测方法在传统的环路检测的基础上在效率上进行了改进,可以较好地适应大数据的计算。
近几年,随着计算机行业的蓬勃发展,计算机技术取得了巨大的进步与突破,同时,随着信息数字化的发展,数据的爆炸式增长也是对传统的算法带来了极大的挑战。一些对于数据量较小时计算能力效果较好的传统算法,可能就无法适应如今大数据时代的要求。
就虚开增值税这个问题而言,检测遇到的主要问题就是在于时间上,也可以说是算法的计算效率。传统的检测算法一般采用深度优先遍历的方式遍历图中所有的点来探测是否存在环路,以深度优先遍历o(n^2)的时间复杂度而言,当数据量比较小时,还可以适应当前的计算,而当数据量增长到一定地步时,它的效率会急剧下降,在一些对计算效率要求较高的环境中,可能就无法适应。而要对虚开增值税专用发票行为进行检测,就要对银行中所有开户的企业节点进行遍历,若是使用传统深度优先遍历的环路检测方法而言,肯定是无法达到需要的效率。
在以往的虚开增值税专用发票检测中,往往采用人工手动比对资金流转进行查找,这个过程往往费时费力,而且人工手动的存在,无法避免可能存在一些漏洞。
技术实现要素:
为了克服上述现有技术的不足,本发明的目的是提供一种基于并行环路检测的虚开增值税专用发票检测方法,通过环路检测的方法来进行虚开增值税专用发票检测,并且对环路检测进行了改进,通过分布式并行计算方法,将计算任务分配给分布式集群中的多台计算机中,大大提高了计算效率。
为了实现上述目的,本发明采用的技术方案是:
一种基于并行环路检测的虚开增值税专用发票检测方法,包括以下步骤:
1)构建数据结构来对图数据进行存储;
2)采用了bsp(bulksynchronousparallel,总体同步并行计算)模型思想作为算法的主体;
3)数据存储单元会将图数据分布式的保存在各个计算节点中,在每个超级步中,集群中的各个进程,也就是processors会提取数据存储单元中的数据来进行计算;每一个超级步中包含计算主要可以分成3各部分,分别为vprog(点初始化),sendmsg(分发信息),mergemsg(结合信息);所述的vprog(点初始化)表示将设定的初始化程序运行在每一个顶点中,负责接收进来的信息,计算新的顶点信息,并将满足条件的点进行激活;所述的sendmsg(分发信息)是指被激活的点会向它的下一个节点进行信息传递,由于分布式计算,sendmsg传来的信息往往会有多条;所述的mergemsg(结合信息)则负责将这些多条信息安装一定的规则整合到一起,再交给vprog;
4)vprog(点初始化)负责在每个超级步的初始阶段,对每个顶点的信息进行初始化以及更新;
5)sendmsg(分发信息)模块负责生成路由信息同时检测环路,对各类的情况进行分析设计,顶点的数据结构定义为(intvertexid,(stringroute,intround,intflag)),同时已知flag为点属性中保存标志位信息,且数值0表示该点从来没有被激活过,1表示该点被激活,2表示改点曾经被激活过但现在处于未激活状态,所以在sendmsg阶段,就需要通过标志位信息调用不同的send方法;在进行sendmsg(分发信息)时,源节点一定处于激活状态;
6)mergemsg(结合信息)是这个算法主体的最后一个部分,mergemsg(结合信息)会将sendmsg暂存的信息以设定的方法,将信息结合到一起,并赋给newmsg,mergemsg模块主要分成2类情况来进行分析;
a更新节点的节点信息都是来自上一层节点;
b更新节点的信息除了来自上层节点外,自身也会传来“过时”的节点信息,这种情况的产生较为特别,即这个节点在上个超级步中也是处于激活状态,它的信息往下一层传递后,它自身要消去激活状态,所以,在迭代器中,也会保存它自身“过时”的信息。
进一步,构建数据结构来对图数据进行存储,使用vertex来存储点信息,属性包括id和点属性,这其中,用户可以自定义点属性包含的信息,同时,使用edge来存储边信息,属性包括三个部分,源顶点的id,目标顶点的id,边属性,同样边属性的内容可由用户进行设计,在算法的实现过程中,edge的边属性只需要保存点的连通方向,所以在边属性中保存了点之间的距离,用(intsourceid,intdestinationid,intdistance)表示,sourecid表示为源顶点的id,destinationid为目标顶点的id,而distance则表示2个顶点之间的距离,具体表示从源顶点指向目标顶点,且距离为distance值,而vertex中所需要保存的信息会相对较多,主要将各个点的路由,标志位,超级步这三类信息保存在点属性中,具体的数据结构使用(intvertexid,(stringroute,intround,intflag)),vertexid表示点的id信息,route表示点的当前超级步更新的路由,round表示当前进入第几个超级步,flag值为标志位,其中,0表示该点没有被激活,1表示该点被激活,2表示改点曾经被激活过,但现在处于未激活状态。
进一步,bsp模型可以由以下几个方面来描述:
a、processors,指的是集群中的可以进行并行计算的进程,一个集群中往往会包含多个processors计算进程;
b、localcomputation,指单个processors的计算,即每个processors进行的本地计算;
c、communication,指各个processors间的通讯,各个并行计算的进程通过信息交互来实现同步;
d、superstep,叫做超级步,指bsp的一次计算迭代,一个算法往往由许多的超级步构成,一个超级步相当于一个集群一次总体的分布式计算;
e、barriersynchronization,叫做障碍同步或者栅栏同步,每一次同步就是一个超步的完成以及下一个超步的开始;
f、程序什么时候结束,一般由程序的主节点master,master在若干个超步后,发现所有的进程的计算都已经结束且再没有新的计算任务,即通知所有的processors结束并退出任务。
进一步,vprog负责在每个超级步的初始阶段,对点信息进行初始化以及更新,分为2个方面:
a、当第一次运行该算法时,图信息的初始化;
b、该算法以及运行了若干个超级步后,图信息的更新。
进一步,在进行sendmsg时,源节点一定处于激活状态,由flag的状态分类可知,flag可以分成以下3种情况:
a、situation1对应它的源节点处于激活状态,而它的目标节点处于非激活状态,且从未被访问过。所以取源节点中的route信息,更新目标节点的route信息,源节点的route信息可能保存不只一条路径,即当源节点的上层节点有多个节点同时指向它时或者它的上层节点内本身就保存了多条路由时,这个路由情况就会继承下来,它也会保存多条路由,这种情况的产生会在mergemsg模块进行解释,所以每一条路由信息都要更新到目标节点中,在更新完路由信息后,还需将目标节点激活,并在目标节点的round中记录当前超级步阶段,再把源节点转换为非激活状态,除此之外,sendmsg模块会将所有的信息先暂存在迭代器iterator中,信息的整合将在mergemsg模块进行;
b、situation2对应它的源节点处于激活状态,目标节点处于非激活状态,但目标节点曾经被访问过,在这种情况下,除了像situation1一样需要将路由情况更新到目标节点中外,还需要判断是否以及形成环路,假如没有形成环路,则不需要进行特别的处理;假如形成了环路,还要分成3种情况进行分析,第1种就是源节点的route里只保存了一条路径,那么假如这条路径与目标节点形成环路,那么将环路输出,且不需要再对目标节点进行激活;第2种情况就是源节点的route里保存了多条路径,且至少有一条路径与目标节点形成环,但没有全部路径都形成环路,那么将形成环路的节点输出,在更新目标节点的route时,去掉以及形成环路的路径,保存还没有形成环路的路径,再更新目标节点的round值并激活目标节点;第3种情况与第1中情况类似,源节点的route里保存了多条路径,但每条路径都与目标节点构成了环路,那么也将形成环路的路径输出,也不必对目标节点进行激活,最后,再将源节点的激活状态转化成非激活状态,与situation1,这些输出会都先暂存在迭代器iterator中;
c、situation3,的路由情况为源节点处于激活状态,而其目标节点也处于激活状态,目标节点是否处于激活状态对sendmsg并不会造成影响,它提供的有用的信息就是它的目标节点曾经被访问过,也就是situation2这种情况,sendmsg更新的信息是先暂存在迭代器iterator中,直到mergemsg模块,再将这个超级步中所有的运行结果更新。
更进一步,对于第一种情况,需要考虑的节点的前驱,即上层有多个的情况,也就是这个原因,造成了上文sendmsg模块中situation1的节点的route中保存了多条路径,需要将他们所有的route信息都要结合到一起形成newmsg,同时,使用“;”来进行分隔多条路径,对于第二种情况,使用到点属性中的round属性值,也就是通过round值来区分是第一类情况还是第二类情况。round值记录了改点被激活时的超级步的阶段,假如取出2个迭代器中的round相同,则表明这是第一种情况,而假如取出2个迭代器中的round有大小只差,则表明round值较小的是“过时”的,即可去掉,保存round值较大的值即可。
本发明的有益效果是:
1)创新性地使用了环路检测的方式来解决查找虚开增值税专用发票的问题;
2)创新性地在环路检测过程中引入了并发,可以将分布在众多计算机中的大量数据资源和处理器资源整合在一起协同工作,具有很好的现实意义和使用价值。在算法的主体设计中创新性地采用了bsp(bulksynchronousparallel,总体同步并行计算)模型思想。bsp是一种良好的具有可扩展并行性能软件开发的理论模型,为现在和未来可能出现的各种并行体系结构提供了一种独立具体的体系结构;
3)通过自动化的方式可以大量地减少人力消耗;
4)自动化的方式可以节省大量的时间;
5)计算机计算可以完全达到公正公平;
所以可见,本专利的目的还是在于通过计算机自动化检测的方式,更好地辅助虚开增值税专用发票的检测,严厉打击虚开增值税专用发票这种违法行为。
附图说明
图1为bsp模型结构图;
图2为计算流程示意图;
图3为算法流程图;
图4为vprog伪代码示意图;
图5为situation1伪代码示意图;
图6为situation2伪代码示意图;
图7为situation3伪代码示意图;
图8为mergemsg模块伪代码示意图。
具体实施方式
以下结合附图对本发明进一步叙述。
一种基于并行环路检测的虚开增值税专用发票检测方法,包括以下步骤:
1)构建数据结构来对图数据进行存储,如图1所示;
2)采用了bsp(bulksynchronousparallel,总体同步并行计算)模型思想作为算法的主体;
3)数据存储单元会将图数据分布式的保存在各个计算节点中,在每个超级步中,集群中的各个进程,也就是processors会提取数据存储单元中的数据来进行计算;每一个超级步中包含计算主要可以分成3各部分,分别为vprog(点初始化),sendmsg(分发信息),mergemsg(结合信息);所述的vprog(点初始化)表示将设定的初始化程序运行在每一个顶点中,负责接收进来的信息,计算新的顶点信息,并将满足条件的点进行激活;所述的sendmsg(分发信息)是指被激活的点会向它的下一个节点进行信息传递,由于分布式计算,sendmsg传来的信息往往会有多条;所述的mergemsg(结合信息)则负责将这些多条信息安装一定的规则整合到一起,再交给vprog,如图2所示;
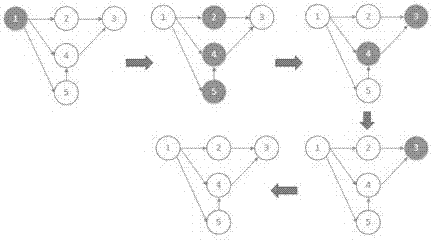
在第一个超级步中,1号节点通过vprog被激活,在图中,蓝色表示该点被激活,白色表示改点处于非激活状态。1号节点则通过sendmsg将自己的路由信息传给它的目标节点,即2,4,5节点。2,4,5号在接收到1号节点传来的路由信息后,通过mergemsg将更新信息。再在下一个超级步中,vprog将更新的信息更新到2,4,5号节点中,同时2,4,5号节点被激活,按同样的方式向目标节点传递节点。至到图中所有的节点都处于非激活状态,算法结束。所以,这个算法的流程如图3所示;
4)vprog(点初始化)负责在每个超级步的初始阶段,对每个顶点的信息进行初始化以及更新;
5)sendmsg(分发信息)模块负责生成路由信息同时检测环路,对各类的情况进行分析设计,顶点的数据结构定义为(intvertexid,(stringroute,intround,intflag)),同时已知flag为点属性中保存标志位信息,且数值0表示该点从来没有被激活过,1表示该点被激活,2表示改点曾经被激活过但现在处于未激活状态,所以在sendmsg阶段,就需要通过标志位信息调用不同的send方法;在进行sendmsg(分发信息)时,源节点一定处于激活状态;
6)mergemsg(结合信息)是这个算法主体的最后一个部分,mergemsg(结合信息)会将sendmsg暂存的信息以设定的方法,将信息结合到一起,并赋给newmsg,mergemsg模块主要分成2类情况来进行分析;
a更新节点的节点信息都是来自上一层节点;
b更新节点的信息除了来自上层节点外,自身也会传来“过时”的节点信息,这种情况的产生较为特别,即这个节点在上个超级步中也是处于激活状态,它的信息往下一层传递后,它自身要消去激活状态,所以,在迭代器中,也会保存它自身“过时”的信息。
进一步,构建数据结构来对图数据进行存储,使用vertex来存储点信息,属性包括id和点属性,这其中,用户可以自定义点属性包含的信息,同时,使用edge来存储边信息,属性包括三个部分,源顶点的id,目标顶点的id,边属性,同样边属性的内容可由用户进行设计,在算法的实现过程中,edge的边属性只需要保存点的连通方向,所以在边属性中保存了点之间的距离,用(intsourceid,intdestinationid,intdistance)表示,sourecid表示为源顶点的id,destinationid为目标顶点的id,而distance则表示2个顶点之间的距离,具体表示从源顶点指向目标顶点,且距离为distance值,而vertex中所需要保存的信息会相对较多,主要将各个点的路由,标志位,超级步这三类信息保存在点属性中,具体的数据结构使用(intvertexid,(stringroute,intround,intflag)),vertexid表示点的id信息,route表示点的当前超级步更新的路由,round表示当前进入第几个超级步,flag值为标志位,其中,0表示该点没有被激活,1表示该点被激活,2表示改点曾经被激活过,但现在处于未激活状态。
进一步,bsp模型可以由以下几个方面来描述:
a、processors,指的是集群中的可以进行并行计算的进程,一个集群中往往会包含多个processors计算进程;
b、localcomputation,指单个processors的计算,即每个processors进行的本地计算;
c、communication,指各个processors间的通讯,各个并行计算的进程通过信息交互来实现同步;
d、superstep,叫做超级步,指bsp的一次计算迭代,一个算法往往由许多的超级步构成,一个超级步相当于一个集群一次总体的分布式计算;
e、barriersynchronization,叫做障碍同步或者栅栏同步,每一次同步就是一个超步的完成以及下一个超步的开始;
f、程序什么时候结束,一般由程序的主节点master,master在若干个超步后,发现所有的进程的计算都已经结束且再没有新的计算任务,即通知所有的processors结束并退出任务。
进一步,vprog负责在每个超级步的初始阶段,对点信息进行初始化以及更新,所以,其伪代码如图4所示,这其中,msg表示节点本身保存的信息,newmsg表示节点更新的信息,由mergemsg整合生成,分为2个方面:
a、当第一次运行该算法时,图信息的初始化;
b、该算法以及运行了若干个超级步后,图信息的更新。
进一步,在进行sendmsg时,源节点一定处于激活状态,由flag的状态分类可知,flag可以分成以下3种情况:
a、situation1对应它的源节点处于激活状态,而它的目标节点处于非激活状态,且从未被访问过。所以取源节点中的route信息,更新目标节点的route信息,源节点的route信息可能保存不只一条路径,即当源节点的上层节点有多个节点同时指向它时或者它的上层节点内本身就保存了多条路由时,这个路由情况就会继承下来,它也会保存多条路由,这种情况的产生会在mergemsg模块进行解释,所以每一条路由信息都要更新到目标节点中,在更新完路由信息后,还需将目标节点激活,并在目标节点的round中记录当前超级步阶段,再把源节点转换为非激活状态,除此之外,sendmsg模块会将所有的信息先暂存在迭代器iterator中,信息的整合将在mergemsg模块进行;这种情况下的伪代码如图5所示;
b、situation2对应它的源节点处于激活状态,目标节点处于非激活状态,但目标节点曾经被访问过,在这种情况下,除了像situation1一样需要将路由情况更新到目标节点中外,还需要判断是否以及形成环路,假如没有形成环路,则不需要进行特别的处理;假如形成了环路,还要分成3种情况进行分析,第1种就是源节点的route里只保存了一条路径,那么假如这条路径与目标节点形成环路,那么将环路输出,且不需要再对目标节点进行激活;第2种情况就是源节点的route里保存了多条路径,且至少有一条路径与目标节点形成环,但没有全部路径都形成环路,那么将形成环路的节点输出,在更新目标节点的route时,去掉以及形成环路的路径,保存还没有形成环路的路径,再更新目标节点的round值并激活目标节点;第3种情况与第1中情况类似,源节点的route里保存了多条路径,但每条路径都与目标节点构成了环路,那么也将形成环路的路径输出,也不必对目标节点进行激活,最后,再将源节点的激活状态转化成非激活状态,与situation1,这些输出会都先暂存在迭代器iterator中,所以,这种情况下的伪代码如图6所示;
c、situation3,的路由情况为源节点处于激活状态,而其目标节点也处于激活状态,目标节点是否处于激活状态对sendmsg并不会造成影响,它提供的有用的信息就是它的目标节点曾经被访问过,也就是situation2这种情况,sendmsg更新的信息是先暂存在迭代器iterator中,直到mergemsg模块,再将这个超级步中所有的运行结果更新,所以伪代码如图7所示;
更进一步,对于第一种情况,需要考虑的节点的前驱,即上层有多个的情况,也就是这个原因,造成了上文sendmsg模块中situation1的节点的route中保存了多条路径,需要将他们所有的route信息都要结合到一起形成newmsg,同时,使用“;”来进行分隔多条路径,对于第二种情况,使用到点属性中的round属性值,也就是通过round值来区分是第一类情况还是第二类情况。round值记录了改点被激活时的超级步的阶段,假如取出2个迭代器中的round相同,则表明这是第一种情况,而假如取出2个迭代器中的round有大小只差,则表明round值较小的是“过时”的,即可去掉,保存round值较大的值即可,mergemsg模块的伪代码即如图8所示。
实施例
对于一个完整的计算任务而言,该算法的输入为一个文本文档(.txt),其中记录了图中所有点的连接关系,一般形式为(1号顶点2号顶点2个顶点的距离),默认指向为由1号顶点指向2号顶点。当程序接收到对应文档后,会自动解析文本并提取相应的信息,并将其转化为设计的数据格式。然后再加载计算模块,将计算任务分配给分布式集群中的计算机。最后,算法会将图中所有的环路进行输出。实验测试了500个点,在5s内找出了所有的环路。
- 还没有人留言评论。精彩留言会获得点赞!