基于国产申威26010处理器的基2一维FFT的高性能实现方法与流程
本发明属于傅里叶变换领域,具体涉及基于国产申威26010处理器的基2一维fft的高性能实现方法。
背景技术:
快速傅里叶变换(fastfouriertransform,fft)是离散傅里叶变换的快速计算方法。离散傅里叶变换(discretefouriertransform,dft)是指傅里叶变换在时域和频域都表示为离散状态,将信号的时域采样变换为离散时间傅里叶变换的频域采样。dft将自然科学与工程技术中连续而复杂的问题转换为离散而简单的运算。对于数据规模为n的一维输入序列,dft计算公式如下:
其中,ωn为旋转因子(twiddlefactor)序列,ωn=e-i2π/n,eix=cosx+isinx,
fft主要利用ωn的对称性和周期性,将dft分解为若干有规律的矩阵向量乘,使得dft的浮点运算量减少到o(nlogn)。fft算法种类繁多,变换形式复杂,主要处理对象有基2变换规模和非基2变换规模以及合数变换规模和素数变换规模,数据类型有单精度复数、双精度复数、单精度实数与双精度实数。本发明中,处理对象为基2一维fft,数据类型为双精度复数。
国产申威26010处理器是江南计算技术研究所自主研制的高性能计算平台,该平台是1个主核与64个从核组成单个核组、并由4个核组组成单个cpu的众核平台。平台使用扩展的alpha架构指令集,支持从核核组寄存器通信机制、访存指令和计算指令同步发射机制以及256位simd向量化运算。该高性能计算平台性能优越,越来越多的科学计算与工业应用运行于该平台,然而目前开源fftw函数库直接应用于该平台的计算性能较差,因此针对该申威平台开发fft函数库是必需的。
技术实现要素:
本发明技术解决问题:克服现有技术的基于开源fftw函数库直接应用于本平台性能较低的问题,提供一种基于国产申威26010处理器的基2一维快速傅里叶变换的高性能实现方法,设计多种高性能优化手段,并且提出两层分解的fft算法结构,有效应用于基2一维fft计算,充分提高fft函数库性能。
传统fft算法并行度有限且访存局部性低,在申威众核平台上难以充分利用众多计算资源。依据众核计算平台的核间拓扑结构和存储层次特点,本发明基于国产申威26010处理的一个核组,设计接口层、主核层、从核层和核心层的四层结构框架进行fft处理。一个核组由一个主核与64个从核组成;接口层和主核层为主核上操作,且操作输入输出数据存储于主核内存,从核层和核心层为从核上操作,且操作输入输出数据存储于从核局存ldm,即localdirectmemory。具体实现如下:
(1)接口层建立输入数据的描述符;所述描述符设置fft计算的基本信息,所述基本信息包括fft计算中输入序列的数据维度、数据规模、数据精度以及变换类型;所述数据维度为一维,所述数据规模为2的幂,所述数据精度包括64位双精度数据与32位单精度数据,所述变换类型为复数到复数的变换,即输入输出数据皆为复数;本发明所述数据皆默认为双精度复数数据,若操作单精度复数数据,下文无特殊说明时,所述数据规模乘2即可;
(2)基于(1)所述描述符信息,当输入数据规模n小于等于256时,主核层直接对输入序列进行fft计算;当输入数据规模n大于等于512时,主核层设计基于两层分解的算法结构对输入序列进行分解,分解结果为多个小因子序列,小因子数据规模小于等于32,则输入序列的fft计算转化为多个小因子序列的fft计算,小因子序列的fft计算在从核上执行;此外,不计输入数据规模n的大小,主核层负责fft计算过程中所必需的旋转因子序列ωn的计算,
(3)主核上操作完毕之后,从核层发起dma,即直接内存访问directmemoryaccess,读取主核内存数据至从核ldm中,然后从核对ldm数据进行小因子序列的fft计算,最后dma将从核ldm内的fft计算结果写入主核内存;
(4)根据(3)所述的从核对ldm数据进行小因子序列的fft计算,此计算操作由核心层完成,核心层基于256位simd进行向量化运算的小因子优化函数进行小因子序列的fft计算;simd为单指令流多数据流,256位simd表示一条指令同时处理256位数据,即fft计算粒度为256位向量数据;此外,各从核分别进行小因子序列的fft计算,计算结果存储于各自的ldm中。
步骤(2)中当输入数据规模n大于等于512时,主核层设计基于两层分解的算法结构对输入序列进行分解,该基于两层分解的算法基于迭代的stockham计算框架,将输入序列分解为一系列的小因子序列,分解规则为库利-图基即cooley-turkey算法;stockham计算框架首先基于n=n1*...*ni*...*nm的分解模式使用迭代的方法进行分解,其中i=1,2,...,m,之后对数据ni的处理分为两种情况:
1)当数据规模ni为小因子数据规模时,则不再进行分解,即只进行一层分解;
2)当数据规模ni大于小因子数据规模时,则递归地基于ni=f1*...*fk*...的分解模式进行二层分解,其中k=1,2,...,且分解时确保fk为小因子数据规模,则输入序列被分解为多个小因子序列。
步骤(3)所述的从核层发起dma,读取主核内存数据至从核ldm中的具体情况如下:
1)从核层发起dma读取主核内存数据时,数据传输的起始地址满足128字节对齐且传输量至少为256字节的倍数;
2)从核层读取数据至从核ldm时,依据主核输入数据规模,当输入数据规模n大于等于512且小于等于2048时,8个从核ldm均匀分担dma读取的主核内存数据;当输入数据规模n大于等于4096时,64个从核ldm均匀分担dma读取的主核内存数据。
步骤(3)所述的从核对ldm数据进行小因子序列的fft计算,具体情况为:从核层以v*ni为工作集,其中,ni为基于n=n1*...*ni*...*nm分解模式进行分解后的数据规模,大于等于小因子数据规模,即ni大于等于32,i=1,2,...,m;v表示每次调用核心层优化函数进行小因子序列fft计算的个数,即调用核心层优化函数一次,则进行v个小因子序列的fft计算,v≥16,若数据精度为8位单精度数据,v≥32;
1)当512≤v*ni≤2048时,数据规模为v*ni的fft计算由一行8个从核共同完成计算,进一步分解ni=f1*f2,f1与f2为小因子数据规模;在核心层进行v个数据规模为f1的小因子序列的fft计算之后,以从核的寄存器通信机制对从核上计算结果进行重新排布,随后于核心层进行v个数据规模为f2的小因子序列的fft计算;
2)v*ni大于等于4096时,数据规模为v*ni的fft计算由64个从核共同完成计算,进一步分解ni=f1*f2*...,以fk代表f1,f2,...其中之一,fk为小因子数据规模;各个数据规模为fk的小因子序列的fft计算之间,需以从核的行寄存器通信或列寄存器通信重新排布从核数据。
步骤(3)所述的从核层发起dma,读取主核内存数据以及从核进行小因子数据的fft计算,有下面特殊情况:受限于64个从核的ldm空间,当数据规模n大于等于65536时,需进行多次dma访存操作,即读取和写入操作,因此设计从核层基于访存-计算重叠的双缓冲机制同时进行dma访存操作与小因子数据的fft计算操作,即以dma访存时间覆盖fft计算时间。
与开源fftw技术相比:
(1)本发明基于国产申威26010处理器,提出基于两层分解的stockhamfft计算框架进行fft计算,有效应用于基2一维fft计算,充分提高fft函数库性能。
(2)本发明设计从核内行或列寄存器通信机制、访存-计算重叠的双缓冲机制和256位simd向量化运算等多种优化技术,有效解决fft计算的访存带宽受限问题,提升基2一维fft运算性能。
(3)以每秒浮点运算次数即gflops表示fft计算性能为例,本发明基2一维fft计算性能相比于fftw中基2一维fft计算性能的平均加速比为34.4,最高加速比高达50.3。
附图说明
图1为基于申威平台的fft四层结构框架,包含接口层、主核层、从核层和核心层;
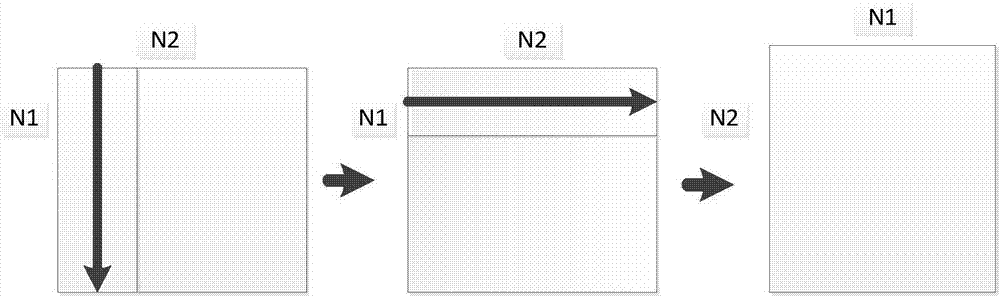
图2为以n=n1*n2分解模式的fft计算流程;
图3为数据规模为64,以8*8的分解模式进行分解时,dma对数据的读取与写入方式,以及行寄存器通信机制对各从核ldm数据的调整;其中,(a)为数据规模为64时,数据序列于主核内存上的存储格式;(b)为dma读取主核数据至8个从核之后,各从核ldm数据的存储格式;(c)为对8个从核ldm的数据经行寄存器通信之后,各从核ldm数据的分配格式;(d)为dma将ldm数据写入至主核之后,数据序列于主核内存上的存储格式。
具体实施方式
如图1所示,本发明是基于国产申威26010处理器的基2一维fft的高性能实现方法,设计框架包含四层:接口层、主核层、从核层、核心层,调用关系为接口层-主核层-从核层-核心层,从核层多次调用核心层。接口层建立包含输入数据规模、数据维度等信息的描述符;主核层基于描述符信息,当输入数据规模大于等于512时,对输入序列进行分解,当输入数据规模小于等于256时,直接于主核上进行fft计算;从核层依据主核层的数据分解结果,负责主存数据与局存数据的读取与存储,以及数据于64个从核上的分配模式;核心层负责小因子序列的fft计算。
四层设计框架具体实施方式如下:
1.接口层:描述符操作
(1)接口层首先建立描述符,设置fft计算所需的数据精度、数据维度、数据规模等基本信息;
(2)提交描述符至主核层,主核层进行fft计算所需的运算;
(3)调用从核接口传输数据至从核;
(4)主从核上fft计算结束后,释放描述符。
fft计算调用从核接口时,有两种接口类型,分别为正变换接口与逆变换接口。fft正逆变换算法相同,逆变换主要用于判断fft算法的正确性,输入数据x经正变换得到输出数据y,而后输出数据y经逆变换得到输出数据z,通过比较输入数据x与输出数据z,即以x与z的2范数与某一阈值进行比较,确定fft算法的正确性。
2.主核层:
本发明中,fft是基于两层分解的算法结构,算法基于迭代的stockham计算框架,将大规模fft计算分解为一系列小规模计算,分解规则为cooley-tukey算法。对于输入数据规模n的一维fft计算,分为两种情况:
(1)若输入数据规模n小于等于256时,主核层直接进行输入序列的fft计算;
(2)若输入数据规模n大于等于512时,将数据序列均匀分布到8个或64个从核中进行计算。对于输入序列,stockhamfft计算框架基于n=n1*...*ni*...*nm(i=1,2,...,m)的分解模式使用迭代方法将输入数据规模为n的一维fft计算任务转化为一系列数据规模为ni的fft计算,而后根据数据规模ni,分为两种情况:
1)若数据规模ni为小因子数据规模,即数据规模小于等于32,则ni不再进行分解,直接调用核心层的小因子优化函数进行小因子序列的fft计算;
2)若数据规模ni大于小因子数据规模,则对ni递归地应用cooley-tukey算法进行二层分解,分解模式为ni=f1*,...,*fk*...(k=1,2,...),fk为小因子数据规模,则fk直接调用核心层的小因子优化函数进行小因子序列的fft计算。
此外,主核层负责fft计算过程中所必需的旋转因子序列ωn的计算,
基于cooley-tukey算法,假设输入数据规模为n的序列分解为n=n1*n2,则输入序列按行优先方式映射为二维数组,具体计算步骤如图2,其表述如下:
(1)n2个数据规模为n1的一维fft计算,每个fft计算的输入序列为x[*,l](0≤l<n2);
(2)fft后每个数据乘旋转因子:
(3)n1个数据规模为n2的一维fft计算,每个fft计算的输入序列为x[j,*](0≤j<n1);
(4)fft后的二维数组转置:x[j,l]→x[l,j],得到n点一维fft计算结果。
严格依照上面4个步骤执行fft计算时,当数据规模n大于片上存储规模nr时,需对片下内存数组读写4次,则总访存量为8n。因此,具体实现时,通常将步骤(2)的乘旋转因子合并到步骤(1)中,将步骤(4)的数据转置合并到步骤(3)中,则访存量降低为4n。与输入输出数据访存量相比,旋转因子产生访存量极低,因此忽略旋转因子访存量。
3.从核层:从核核组对各种规模fft的计算方案
该平台上,通过dma实现主存与ldm之间数据的快速交换。数据规模为ni的一维fft计算包含三个步骤:dma传输输入数据至ldm;于从核ldm上发起数据规模为ni的一维fft;dma将计算结果存入内存。
从算法设计和访存带宽利用角度出发,同时计算v个数据规模为ni的一维fft计算,即核组每次计算的工作集为v*ni,v表示每次调用核心层优化函数进行小因子序列fft计算的个数,即调用核心层优化函数一次,则进行v个小因子序列的fft计算,v≥16,若数据精度为单精度复数,v≥32。依据从核间通信特征,数据规模为ni的fft计算有三种方案:
(1)仅由1个从核完成,没有从核间通信,数据v*ni分布在单个从核ldm中,直接进行v个数据规模为ni的基2一维fft;
(2)由一行(列)8个从核共同完成计算,仅涉及从核的行寄存器通信,单个从核ldm中分布数据为v*(ni/8),ni进行二次分解ni=f1*f2;
(3)由整个从核即64个从核共同完成计算,包含从核的行寄存器通信与列寄存器通信,单个从核ldm中分布数据为v*(ni/64),ni进行二次分解ni=f1*f2*f3,通常f3=8。
由于方案(1)中每次计算的分量较小,于内存数组的遍历次数较多,实际情况中,本方案使用概率极少。
对于方案(2),由于ldm容量限制,工作集v*ni无法完全加载到同一从核,故而由一行上8个从核协同计算。如图3所示,ni=64,分解为ni=f1*f2=8*8进行计算,计算结果以f2*f1的维度写入片下内存。该方案由图3中4个步骤组成。
1)基于cooley-tukey分解规则,f1点fft计算所需数据在片下内存中不连续分布,如图3中的(a)所示,通过适当的dma传输方式,将f1点数据加载到同一从核中,如图3中的(b)所示;
2)在8个从核上分别进行v个f1点fft计算,与分解ni=f1*f2产生的旋转因子相乘;
3)基于从核的行寄存器通信机制,将f2点fft计算所需数据加载到同一从核中,而后于8个从核上分别进行v个f2点fft计算,如图3中(c)所示;
4)通过dma将计算结果以f2*f1的方式写入片下内存中,如图3中(d)所示。
ni为本方案其他规模时,计算方式类似,不再详述。
对于方案(3),工作集v*ni由64个从核协同计算,ni=f1*f2*f3,分为ni=f12*f3和f12=f1*f2两步进行计算。基于cooley-tukey算法,依次完成f1、f2和f3点fft计算,计算结果以f3*f2*f1的维度写入片下内存。该方案由5个步骤组成:
1)f1点fft计算所需数据在片下内存中不连续分布,通过适当的dma传输方式,将f1维度上相应数据加载到同一ldm中;
2)在64个从核上分别进行v个f1点fft计算,与f12=f1*f2分解产生的旋转因子相乘;
3)基于从核的行寄存器通信机制,将f2维度上相应数据加载到同一从核中,而后于64个从核上分别进行v个f2点fft计算,与ni=f12*f3分解产生的旋转因子相乘;
4)基于从核的列寄存器通信机制,将f3维度上相应数据加载到同一从核中,而后于64个从核上分别进行v个f3点fft计算;
5)通过dma将计算结果以f3*f2*f1的方式写入片下内存中。
ni为本方案其他规模时,计算方式类似,不再详述。
当输入数据规模n大于64个从核协同计算的数据规模nr时,dma需对主存数据进行多次读写。基于访存-计算重叠的双缓冲机制,当从核对dma当次读入ldm的数据进行fft计算时,dma进行下次fft计算所需数据的读取以及当次fft计算结果向主核内存的写入。输入数据规模n越大,双缓冲效用越明显,有效提升fft计算性能。
4.核心层:进行小因子序列的fft计算
当输入数据规模n划分到小因子数据规模fk或ni时,直接调用小因子优化函数完成小因子序列的fft计算。小因子序列的fft计算是基于256位simd进行的向量化运算,即运算粒度为256位向量数据,即4个64位双精度数据。simd指单指令流多数据流singleinstructionmultipledata,一条simd指令同时处理256位数据。因此,相对于运算粒度为单个64位双精度数据的计算,基于256位simd的高效率计算,若单从核工作集为v*fk,即v个fk点fft计算,则v次fk点fft计算有效转化为v/4次fk点fft计算。
本发明基于申威26010平台,设计两层分解的fft计算框架、寄存器通信机制、访存计算重叠的双缓冲机制以及simd向量化运算等与计算平台相关的优化手段,有效提高fft计算性能。表1统计了数据类型为双精度复数时,基于本平台的基2一维fft的性能数据与开源fftw的基2一维fft的性能数据,其中,数据规模取16384、32768、65536、131072、262144、524288、4194304,由表1得知,基2一维fft平均加速比为34.4,最高加速比达到50.3。
表1基2一维fft性能
注:上述以xmath-fft表示基于国产申威26010处理器的fft。
提供以上实施例仅仅是为了描述本发明的目的,而并非要限制本发明的范围。本发明的范围由所附权利要求限定。不脱离本发明的精神和原理而做出的各种等同替换和修改,均应涵盖在本发明的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!