一种云存储中基于KCB树和布隆过滤器的高效密文检索方法与流程
本发明属于云存储中数据安全技术领域,应用于高效检索密文数据。具体地讲,是一种云存储中基于KCB树和布隆过滤器的高效密文检索方法。
背景技术:
云存储是以云计算为基础逐渐发展起来的,通过将加密数据存储在云服务器上而为用户提供更便捷、更高效的访问与管理。因此,云存储被广泛的应用在各个领域,具有十分广阔的市场应用前景,但其中的安全问题也引起了用户的关注。
对于用户而言,云服务器并不是完全可信的。为了保护数据的隐私,用户通常会在数据传输到云服务器之前对重要数据进行加密。这样一来,利用明文的关键字搜索技术就失效了。因此如何对云服务器上存储的密文文件进行关键字检索就成为了一个难题。为了解决这一问题,可搜索加密(Searchable Encryption,SE)技术便应运而生。
SE是一个新的密码学原语,在保护存储在不可信第三方实体上的数据机密性的同时,还能对密文数据进行高效地检索。SE可描述为如下过程:数据拥有者利用关键字集合生成加密关键字索引,并将所有的加密文件和加密关键字索引上传到云服务器;当用户需要检索关键字时,利用陷门函数为关键字生成查询令牌,并发送给云服务器;服务器使用该令牌对加密关键字索引进行检索;服务器将包含该关键字的密文集合返回给用户,用户利用密钥解密返回的密文文件。从安全性而言,利用该技术进行关键字检索,除了会暴露用户的“搜索模式”(即猜测出任意两个搜索语句是否包含相同的关键字)、“访问模式”(即每次检索的结果)、文件密文信息和一些搜索凭证之外,不会暴露任何有关文档和关键字的信息。从访问效率而言,利用SE机制,用户不必检索、下载和解密不包含关键字的密文文件,节约了大量的网络开销和计算开销。
尽管SE机制的出现极大的提高了用户访问效率,但研究表明,不同的SE索引结构也将影响关键字的检索效率。2003年,Goh提出了安全索引的概念,利用布隆过滤器(Bloom Filter,BF)为每个文件构造一个索引。当用户需要对某个关键字进行检索时,将该关键字的陷门发送给云端,再由云服务器利用陷门与每个文件的BF进行匹配。在时间代价上,云服务器逐个检索所有密文文件,关键字查询时间为O(n)(n是文件集合中文件的个数),效率较低。2006年,Curtmola等人改进了Goh的方案,首次采用倒排索引的方法。该方案为每个关键字构造一个关键字链表,每一条链表节点加密的存放文件标识符、下一个节点的指针和下一个节点的解密密钥。在此改进下,关键字搜索时间减少到了O(r)(r是包含该关键字文件的个数),但由于每次访问时都需要对当前节点进行解密计算,因此计算开销较大。
2011年,Chai提出了一种类似于字典树的加密索引结构。在该方案中,关键字查询时间与最长关键字的长度成正比。虽然此方案效率较高,并能够检测服务器的欺骗行为,但不能抵御字典攻击,安全性差。2013年Kamara等人利用关键字红黑树(KRB树)为文件构造加密索引,提出了并行动态对称可搜索加密方案。该方案在p个处理机的情况下,关键字检索时间为O((r/p)logn);当p=logn时,平行关键字检索时间为O(r);当p=r时,关键字检索时间为O(logn),即与r的大小无关。虽然基于KRB树的密文索引结构能够提高了关键字的检索效率,但由于KRB树中所有节点的存储结构均为关键字哈希表,即是通过关键码值(key,value)访问数据的。且每一个节点都存储了两个m比特的向量,空间复杂度至少为O(2m2(2n-1))bits(与mn成正比,其中m为关键字个数,n为文件个数),这无疑增大了云服务器的存储开销。
技术实现要素:
本发明的目的在于结合关键字完全二叉树和布隆过滤器在空间和时间方面的巨大优势,提出一种高效的SE索引结构,在实现关键字高效检索的同时,降低加密索引在服务器上的存储开销。
在描述发明内容之前,我们先定义几个基础的密码学基元:
1.一个确定性伪随机函数:P:{0,1}k×{0,1}n→{0,1}m;
2.y个相互独立的哈希函数:H={hi:{0,1}k×{0,1}n→{1,x}m}(1≤i≤y)。
为了阐明本发明的步骤,首先定义以下四个算法:
(1)、Gen(1k)→K
初始化方案所需的密钥,1k是系统安全参数,作为函数的输入。在安全参数1k下,生成伪随机函数的密钥K1以及对称加密算法的密钥K2。算法输出密钥K=(K1,K2)。
(2)、BuildIndex(F,W,K)→I
1)、构造关键字完全二叉树(Keyword Complete Binary Tree,KCB)
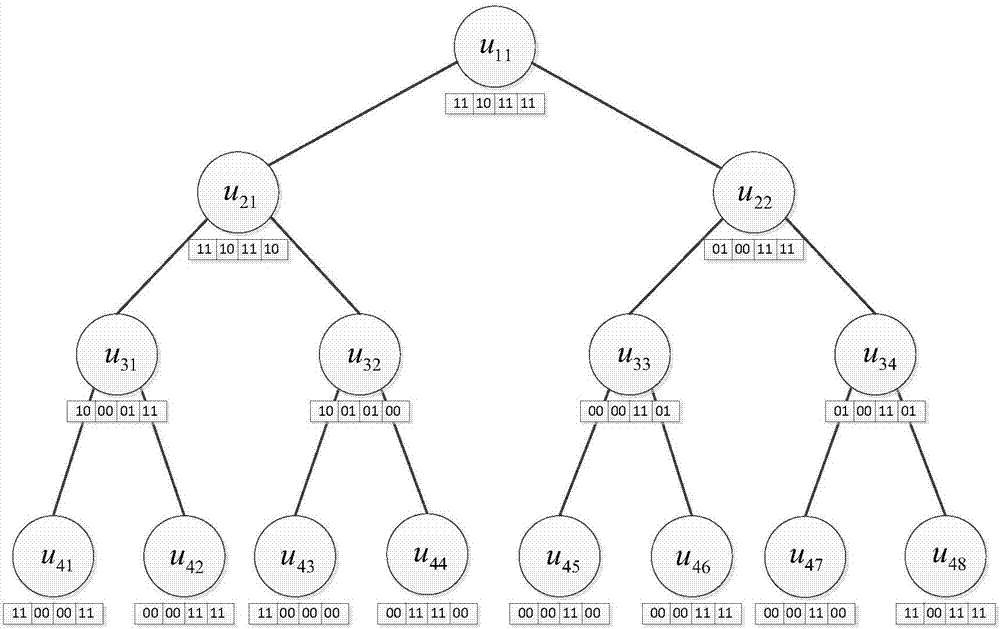
输入明文文件集合F={f1,…,fn}和关键字集合W={w1,w2,…,wm},其中,n是文件集合中文件的个数,m是关键字集合中关键字的个数,n和m的个数均可增减。我们通过如下步骤构造KCB树:
a)KCB树的叶节点对应文件集合F中的所有文件,因此KCB树的层数l可由文件个数n决定,即完全二叉树的叶节点个数为若则用空节点填充剩余叶节点。
b)定义KCB树的节点为uab(1≤a≤l,1≤b≤2(a-1))。其中a为节点uab所在的层数,b为节点uab在第a层的序号。在节点uab上存储二元组(id(uab),dataab)。id(uab)为节点标识符。dataab为一个长度为m的数组。dataab的第i位定义为dataab[i],其中i∈{1,…,m}。
若节点uab是叶子节点:将id(uab)定义为该节点对应的文档fj的文档标识符IDj。定义dataab[i]=11(1≤i≤m),当且仅当文件fj中包含关键字wi;定义dataab[i]=00,当且仅当文件fj中不包含该关键字wi;若该叶节点为填充节点,则设置dataab[i]=10。
若节点uab是非叶子节点:若其左孩子和右孩子都存在包含关键字wi的叶节点,则将该内部节点数组dataab的对应位置dataab[i]置为11;若只有其左孩子存在包含关键字wi的叶节点,则将该内部节点数组dataab的对应位置dataab[i]置为10;若只有其右孩子存在包含关键字wi的叶节点,则将该内部节点数组dataab的对应位置dataab[i]置为01;若其左孩子和右孩子都不存在包含关键字wi的叶节点,则将该内部节点数组dataab的对应位置dataab[i]置为00。
文件索引T实质是一颗未加密的KCB树,完全二叉查找树能保证在最差的情况下操作时间为O(logn)。尽管KCB树高效查找的优势能够实现关键字的快速检索,但若将完全二叉树T的2n-1个节点都存储到云服务器上,又将给服务器带来巨大的存储开销。因此本发明利用布隆过滤器再次对索引结构进行优化,加快关键字的检索效率,降低服务器的存储开销。
2)、由文件索引树T生成加密索引I
利用布隆过滤器将文件索引树T生成加密索引I。输入密钥K,文件集合F={f1,…,fn},文件索引T。之后执行以下步骤:
a)对文件索引树T中所有节点uab(1≤a≤l,1≤b≤2(a-1))以及所有的关键字wi(1≤i≤m),计算并利用y个相互独立的哈希函数映射到布隆过滤器上:
b)为了防止云服务器上数据丢失,将文件索引树T保留在本地服务器。服务器上存储加密索引I。
由于文件索引T采用的是完全二叉树结构,该结构上的每一个节点标识符可以通过计算得到。从u11节点起,服务器能够知道下一个要访问的节点标识符。因此无需上传KCB结构,只需将加密文件和加密索引上传到云端。
当可以承受一些误报时,布隆过滤器拥有很大的空间优势。对于一个有1%误报率的布隆过滤器而言,存储所有元素只需要(9.6m(2n-1))bits(其中m为关键字个数,n为文件个数)。
(3)、SrchToken(K,wi)→τ
使用查询关键字生成搜索令牌。输入密钥K和关键字wi,输出搜索令牌
(4)、Search(C,I,τ)→C(x,y)
服务器接收搜索令牌τ,通过加密索引I对密文文件进行检索,返回满足条件的密文文件集合C(x,y)。
当用户需要对某个关键字进行检索时,通过陷门函数生成该关键字的搜索令牌。从节u11点开始,将节点标识符、搜索令牌和判断符映射到布隆过滤器上。根据判断符的值计算接下来将要检索的节点标识符,接着进行递归检索,直至找到满足搜索条件的加密文件集合。当判断符表明不存在含有关键字wi的文件时,服务器向用户返回没有找到。
本发明的发明目的是这样实现的:
本发明云存储中基于KCB树和布隆过滤器的高效密文检索方法,是一种利用关键字完全二叉树查询时间快和布隆过滤器空间效率高的特点,提出的一种高效SE索引结构。关键字完全二叉树能够将关键字的搜索时间维持在O(logn),与现有的最优的方案效率相当。在此基础上,本发明利用布隆过滤器再次对文件索引树T进行优化,通过将KCB树的所有节点映射到布隆过滤器上,避免将完全二叉树T的2n-1个节点信息都存储到云服务器上。在实现关键字高效检索的同时,降低加密索引在服务器上的存储开销。
附图说明
图1是可搜索加密示意图;
图2是本发明利用关键字红黑树结构构造的文件索引树T;
图3是本发明将文件索引T映射到布隆过滤器的示意图;
图4是本发明是本发明一种云存储中基于KCB树和布隆过滤器的高效密文检索方法的技术方案图,也是本发明的摘要附图;
具体实施方式
下面结合附图对本发明的实施方案进行详细的描述,以便本领域的技术人员能够更好的理解本发明。
本发明利用关键字完全二叉树的结构为文件集合构造文件索引树T,再利用哈希函数将T映射到布隆过滤器上构造加密索引I,具体方案如下:
(1)、首先,利用密钥生成算法Gen,初始化本发明所需的密钥K1和K2。
(2)、数据拥有者对明文文件进行加密,得到密文文件集合C={c1,…,cn}。
(3)、接着利用算法BuildIndex(F,W,K)为明文文件集F={f1,…,fn}构造文件索引T,如图2。将得到的文件索引T的所有节点uab以及所有关键字wi映射到布隆过滤器上。如图3,得到加密索引I。
(4)、当用户需要对关键字进行检索时,利用算法SrchToken生成搜索令牌并发送给云服务器。
(5)、服务器接收搜索令牌τ,利用算法Search对加密关键字索引I进行检索,找到对应的密文文件。
设判断符π1=00、π2=01、π3=10、π4=11。从u11开始,根据命中的判断符的值计算接下来要检索的节点的标识符id(uab),接着进行递归查找,直至找到满足查询条件的密文文件集合。
将标识符id(uab)、和πi(1≤i≤4)做以下运算:
1)、当前检索的是内部节点:
a)若π1命中,表示不存在含有关键字wi的文件。云服务器向用户返回没有找到。
b)若π2命中,表示当前节点的右孩子存在包含关键字wi的文件,计算接下来要检索的节点为u(a+1)(2b)。
c)若π3命中,表示当前节点的左孩子存在包含关键字wi的文件,计算接下来要检索的节点为u(a+1)(2b-1)。
d)若π4命中,表示当前节点的左孩子和右孩子都存在包含关键字wi的文件,计算接下来要检索的节点为u(a+1)(2b-1)和u(a+1)(2b)。
2)、当前检索的是叶子节点:
a)若π1命中,表示文件fj不含关键字wi。
b)若π4命中,表示文件fj含有关键字wi。
c)若π3命中,表示该叶节点为填充节点。
根据以上步骤,从云服务器上找到与搜索令牌对应的密文文件集合C(x,y)。
(6)、解密密文文件集C(x,y),得到对应的明文文件集F(x,y)。
- 还没有人留言评论。精彩留言会获得点赞!