基于网格划分的快速轨迹索引更新方法与流程
一、
技术领域:
本发明是移动对象数据库中索引更新的技术,主要用于移动对象轨迹数据的索引的快速更新。二、
背景技术:
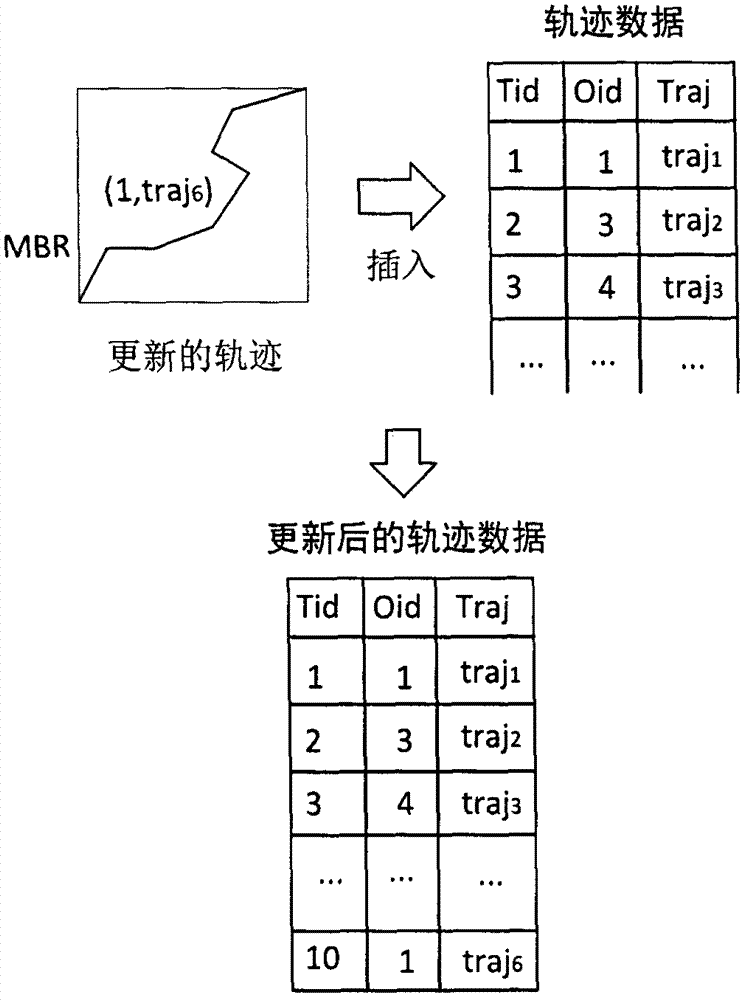
:随着移动对象的数据不断更新,需要将移动对象的数据添加到数据库中,同时更新移动对象轨迹的3dr-tree索引。移动对象的轨迹需要添加到数据库中原有移动对象轨迹数据中,并且更新轨迹的索引,使得更新后的移动对象数据与原有移动对象数据保持格式的一致,并且能够实现高效的移动对象连续距离查询。r-tree更新的主要方法有逐个更新和批处理更新,其中逐个更新的方法每次插入移动对象轨迹的索引项时,需要访问多次磁盘,因此效率低;而批处理更新方法中,目前有基于z曲线或者hilbert曲线排序的批处理更新,然而,这两种方法都需要对插入到r-tree中更新的索引项进行空间的排序,至少需要花费o(nlogn)的排序时间,其中n为需要插入更新的索引项的数量。对于本发明中的基于网格划分的快速轨迹索引更新方法,具有更好的r-tree批处理更新效率。三、技术实现要素:【发明目的】为了提高轨迹索引更新的效率,以及更新后移动对象数据库的连续距离查询效率不会降低,本发明提供了一种基于网格划分的快速轨迹索引更新方法,以解决现有轨迹索引更新的效率问题。【技术方案】本发明所述的基于网格划分的快速轨迹索引更新方法,是对需要更新的移动对象轨迹数据进行预处理,通过批处理方法建立轨迹索引的3dr-tree索引子树,然后将索引子树插入到原有轨迹索引的3dr-tree中,得到更新轨迹索引后的3dr-tree索引结构,主要包括轨迹数据预处理、建立轨迹索引子树和轨迹索引合并三个主要步骤。(1)轨迹数据预处理对于新添加的移动对象轨迹数据,需要保持与数据库中相同的格式,包括轨迹数据的存储格式,轨迹的存储长度,对轨迹数据进行格式化,通过批处理的方式。将轨迹数据分割成较小的轨迹段,添加到已有的数据库中。对新插入的数据进行轨迹分割处理并插入到原有数据表中。轨迹分割的大小与原数据库中的轨迹分割大小一致,以保持数据的一致。(2)建立索引子树建立索引子树,通过批处理的方式,将空间相近的轨迹数据的索引项添加到相同的叶子节点中。对于新插入的轨迹数据,使用批处理生成新的轨迹数据的3dr-tree索引子树。批处理方式建立3dr-tree将时空相近的轨迹组合成一个索引节点,将所有的轨迹数据组合成所有3dr-tree的叶子节点。在这些叶子节点上,将时空相近的叶子节点组合成内部节点,并且将所有的叶子节点组合成内部节点。以此类推,最后的节点组合得到一个3dr-tree根节点。通过这个根节点,可以索引到所有的轨迹数据。(3)索引结构合并生成的索引子树,需要插入到原有轨迹索引中,形成一个索引结构。将新生成的3dr-tree索引子树插入到数据库中原有3dr-tree索引中。判断索引子树的根节点的索引项数量,当索引项数量小于3dr-tree内部节点的最小索引项数量的时候,索引子树的根节点不能作为一个内部节点插入到数据库中原有3dr-tree中,此时需要将此索引子树的根节点的所有索引项分别插入到数据库中原有3dr-tree中。在插入的过程中,采用自顶向下搜索,找到最合适的插入节点,将索引项插入到该节点中,并且自底向上更新该节点及其父节点索引项的最小边框矩形(mbr)值。合并后得到的索引结构即是轨迹索引插入更新后的索引结构。【有益效果】本发明所述的基于网格划分的快速轨迹索引更新方法用于快速更新轨迹的数据及其3dr-tree索引,使更新后的轨迹数据及索引依然支持高速的移动对象连续距离查询。与现有技术相比,基于网格划分的快速轨迹索引更新方法的有益效果表现在轨迹索引的更新效率方面。在intel(r)、core(tm)、cpu为i3-2120、主频2.5ghz、内存4gb、ubuntu14.0464位操作系统、c++语言编程环境下测试,测试数据为北京出租车轨迹数据和模拟地铁轨迹数据,如表1所示。在不同数据规模下,基于网格划分的快速轨迹索引更新方法与基于z曲线排序更新方法进行比较,基于网格划分的快速轨迹索引更新方法具有更高的更新效率,如表2所示。由表2可以看出,基于网格划分的轨迹索引更新方法的效率比基于z曲线排序的方法具有更好的效率。表3显示了不同方法更新后,对查询性能的影响。由表3可以看出,基于网格划分的方法更新后的查询效率比基于z曲线排序方法更新后的查询效率更好。表1数据名称移动对象数量单元轨迹数量tdrives10,35715,000,012trains56251,544trains15126,45011,597,400表2表3因此,基于网格划分的轨迹索引更新方法具有较好的更新效率,并且更新后所支持的轨迹的连续距离查询效率比基于z曲线排序的轨迹更新方法的查询效率更好。四、附图说明图1轨迹数据及索引更新图2轨迹数据更新图3自底向上生成3dr-tree图4轨迹数据在网格中的位置图5节点层结构图6空间网格合并图73dr-tree索引合并五、具体实施方式下面结合附图对本发明进一步说明。本发明所述的基于网格划分的快速轨迹索引更新方法,对新添加的移动对象轨迹数据进行预处理,通过批处理方法建立轨迹索引的3dr-tree索引子树,然后将索引子树插入到原有轨迹索引的3dr-tree中,得到更新轨迹索引后的3dr-tree索引结构,并依然支持高效地连续距离查询,如图1所示,具体按以下步骤实施。(1)轨迹数据预处理对新加入的轨迹数据,添加到数据库中原有轨迹数据的表中。对于较长的轨迹,通过将轨迹分割成若干个较短的轨迹,分别添加到数据库中。如图2所示,新加入的轨迹数据包括对象标识oid,以及轨迹数据,将这些数据作为一个元组,插入到表中,得到该记录在表中的位置tid。例如图2中的(1,traj6)插入到轨迹数据表中,得到在轨迹数据表中的tid为10。将tid与轨迹mbr组合而成的3dr-tree索引项,作为下一步的输入,插入到3dr-tree中。(2)基于网格划分方式批处理生成3dr-tree索引子树在建立r-tree索引的方法中,批处理、自底向上建立r-tree索引的方式极为有效,建立r-tree所花费的时间短,且保持了r-tree的高效的空间索引能力。所有的轨迹索引项包含了轨迹在数据库中所在的位置和轨迹的时空范围mbr。这些轨迹的索引项插入到叶子节点层,当叶子节点层中的索引项的数量达到能组成一个叶子节点的最大索引项数量时,将叶子节点层中这些索引项组成一个3dr-tree的叶子节点,并且保存到3dr-tree索引文件中。将叶子节点在3dr-tree中所在的位置以及叶子节点的mbr组成一个3dr-tree内部节点的索引项,插入到上一层的内部节点层,如图3所示。同样,在内部节点层,当内部节点的索引项达到组成一个内部节点的最大索引项的数量的时候,将这些内部节点的索引项组成一个内部节点,保存到3dr-tree索引文件中。将内部节点在3dr-tree中所在的位置以及内部节点的mbr组成一个3dr-tree内部节点的索引项,插入到上一层的内部节点层。直到所有的轨迹数据索引项插入完毕,最后生成一个3dr-tree根节点,这个根节点即为3dr-tree索引子树的根节点。在每一个节点层,为了能够使时空距离相近的索引项组合在一起,形成一个3dr-tree节点,将所有的时空距离比较相近的索引项保存在相同的节点中。因此将时间和空间分为大小相同的网格,位置在网格中的索引项,加入到相同的索引节点中,能够尽量将时空相近的索引项加入到同一个节点中。如图4所示,根据轨迹traj的mbr在时间空间里的位置,将轨迹traj添加到最近的网格索引节点中。每一个节点层的结构如图5所示,这里以二维空间为例。将空间分割为固定大小的网格,网格中存储了一个指针,指向一个桶的数据结构,这个桶中存放了索引项。在叶子节点层中,桶中存放轨迹数据的索引项,而在内部节点层中,桶中存放子节点的索引项。插入到该节点层的索引项数据包括(id,mbr),在叶子节点层,插入索引项中的id为轨迹在数据库中关系表中的存储位置,mbr是轨迹数据的时空范围的最小边框矩形。而在内部节点层中,id为下层子节点在r-tree中的存储位置,mbr为下层子节点的最小边框矩形。当节点层中插入一个索引项时,通过索引项中的mbr计算该索引项的插入位置。将索引项添加到对应网格的索引项桶中。当桶中的数量达到r-tree节点的最大索引项数量时,将桶中的索引项插入到新的节点中,并保存到r-tree中。而新节点在r-tree中的位置,以及节点的mbr则作为新的索引项,插入到当前节点层的上一个节点层中。如算法1所示,将一个索引项entry插入到r-tree节点层rtreelevel,首先找到索引项entry.mbr最靠近的网格,将entry插入到网格对应的索引项桶中。当索引项桶中的数量大于等于r-tree节点的最大索引项数量的时候,将索引项桶中的索引项组成r-tree节点node,并保存到r-tree中。将node.mbr与node保存到r-tree中的位置rid组成newentry,并插入到当前r-tree节点层的上层节点层中。算法1.insertentry(rtreelevel,entry)输入:r-tree节点层rtreelevel索引项entry输出:r-tree节点层rtreelevel1.获取entry.mbr所在空间网格的索引项桶;2.将entry插入到索引项桶中;3.if索引项桶中的索引项数量大于等于节点最大索引项数量4.将索引项桶中的索引项组成一个r-tree节点node,并清空索引项桶中的索引项;5.newentry.mbr←node.mbr;6.将node保存到r-tree中,并且的到node在r-tree中的位置rid;7.newentry.rid←rid;8.insertentry(rtreelevel.nextlevel,newentry);9.endif10.returnrtreelevel;当所有的轨迹数据的索引项插入完毕,此时,节点层中还剩下索引项未能组合索引节点保存到r-tree中。在接下来的处理中,需要从下至上,将所有节点层中的索引项组合成节点,保存到r-tree中,并将该节点所生成的索引项插入到上一个节点层中。如图6所示,将空间网格的大小扩大,由原先的2n个网格组成一个更大的网格,其中n为网格的空间维度,在2dr-tree中,n的值为2,在3dr-tree中,n的值为3。将这些网格中的索引项插入到新索引项桶中。同样,当新的索引项桶中索引项的数量达到r-tree节点的最大索引项的数量的时候,将桶中的索引项插入到新的节点中,并保存到r-tree中,并将该节点所生成的索引项插入到上一个节点层中。如此反复将空间网格扩大,直到将网格中的所有索引项组合成r-tree节点,保存到r-tree中,并插入到上一个节点层中。当节点层从下至上一层一层将索引项组合保存到r-tree中,到了最顶层,所有节点的索引项数量小于索引节点的最大索引项数量时,将该层的所有索引项组合成一个节点,保存到r-tree中,作为r-tree的根节点。对于非根节点层,当节点层中的索引项不足r-tree节点的最小索引项数量时,不能直接将节点层中剩余的索引项组合成一个节点保存到r-tree中。对于这些索引项,插入到r-tree中与当前节点层高相同的节点中。找到与当前节点层高相同,并且最适合插入的节点,使插入索引项后,节点的mbr增加最小。将所有节点层中的索引项都插入到r-tree中,所得到的根节点即为批处理建立的r-tree的根节点,至此,基于网格的批处理方法的r-tree索引子树已经生成。(3)索引合并。将生成的3dr-tree,与数据库中原有的3dr-tree合并。在合并的同时,考虑到3dr-tree索引结构保持平衡的性质,以及保持3dr-tree的时间和空间的区分能力。在合并3dr-tree的时候,需要考虑原有3dr-tree与新插入3dr-tree的层高。为了保持3dr-tree的结构平衡,以及减少3dr-tree的插入操作,将层高较低的3dr-tree插入到层高较高的3dr-tree中。如图7所示,r1是层数为2的3dr-tre,r2的层数为3,因此在插入的时候,将r1插入到r2中层高与r1相同的父节点中,在图7中,将r1插入到r2的根节点中。在插入的时候,还要考虑到被插入3dr-tree的根节点的索引项的数量,因为将3dr-tree的根节点插入到另一个3dr-tree中时,有可能作为生成的3dr-tree中的一个内部节点。例如图7所示,r1插入到r2中,将r1的根节点作为r3中的一个内部节点存在,因此需要考虑r1根节点中索引项的数量。当r1根节点的索引项的数量小于内部节点索引项的最小数量时,需要将r1的根节点拆分,将r1根节点中所有索引项作为一个3dr-tree的子树插入到r2中。考虑这两种情况,可以得到3dr-tree索引合并的算法,如算法2所示。其中smallrtree是高度较低的r-tree,而largertree是层高较高的r-tree。如果smallrtree的根节点的索引项的数量大于或者等于r-tree的内部节点的索引项数量的最小值,则将smallrtree的根节点作为一个索引项插入到largertree中层高与smallrtree相同的父节点中。如果smallrtree的根节点的索引项的数量小于r-tree的内部节点的索引项数量的最小值,则将smallrtree的根节点的所有索引项插入到与smallrtree层高相同的largertree的内部节点中。算法2.rtreeinsert(smallrtree,largertree)输入:较小3dr-tree索引smallrtree较大3dr-tree索引largertree输出:合并后的3dr-tree1.if(smallrtree.root的索引项数量大于或等于内部节点索引项数量的最小值)2.将smallrtree.root作为一个索引项插入到largertree;3.else4.foreachentryinsmallrtree.root5.将entry插入到largertree;6.endfor7.endif8.returnlargertree;通过3dr-tree合并之后,得到更新后的轨迹数据的3dr-tree索引,完成移动对象的轨迹索引的更新。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1