一种改进的全局最优化k‑中心点聚类方法与流程
一、所属技术领域:
本发明提供一种改进的全局最优化k-中心点聚类方法,k-中心点是指从数据对象中选择k个对象为类的代表中心;本发明一种最优化的k-中心点聚类方法,解决了一般的k-中心点聚类方法具有初始解敏感性以及不能保证获得最优聚类结果的缺点;本方法属于数据统计与分析领域,能帮助数据分析人员在数据模式识别中获得更好的聚类效果。
二、
背景技术:
:
聚类(clustering)是指将若干数据对象的按照同类间相似度最大且异类间相似性最小的原则划分若干类的过程。在数据分析与数据挖掘领域,聚类是一种重要的数据分析方法,是挖掘隐藏在大量数据中的数据分布模式的主要手段之一,具有广泛用途。k-中心点聚类是要求在聚类结果必须以原数据对象为聚类中心点的一种特殊聚类分析方法,即从数据对象中选择k个对象为类的代表中心,使类成员达到该中心点的距离之和最小化。传统的k-中心聚类方法,即围绕中心点的聚类方法(简称pam方法),是基于非线性整数规划模型的方法,有两个明显的缺陷:(1)计算结果有可能会止于局部最优解,使聚类结果达不到全局最优;(2)方法对初始中心点的选择比较敏感,选择不同的初始中心点可能导致不同的计算结果。
本发明所提出的方法是基于线性化的整数规划方法,该方法可以直接获得全局最的聚类结果,不会陷入局部最优结果,且不依赖与初始中心点的选择。本方法能够对多达1000个数据对象的中等规模k-中心聚类问题提供全局最优的聚类结果。
三、
技术实现要素:
:
3.1发明目的
本发明的目的在于改进现有k-中心点聚类方法(即pam方法)的缺点,提供一种全局化最优化的聚类方法,为大数据分析和数据模式识别等相关工作提供具有更好聚类效果的聚类方法。
3.2技术方案
首先,本发明要解决的问题描述如下:假定有n个对象和m个属性,这n个对象需要按照其属性值的相似程度划分为k个聚类,使同类对象之间尽可能地相似。其中任意两个对象i和j,以dij表示它们之间的区分度。区分度越大,相似度越小。这里的dij以两点之间的距离来表示且为已知。对于每一个聚类,其中的某一个成员对象将被选择为该类的中心点,代表该类的整体性质。属于同一聚类的所有物体与该类的类中心之间的距离之总和被定义为簇内距离,反映了同族成员之间差异。k-中心点聚类的目标即为使各组组内距离之和最小。
为最优地解决上述问题,本发明方法的技术实现方案由四个步骤组成。各步骤中用到的数学符号预先介绍如下:
本发明一种改进的全局最优化k-中心点聚类方法,其步骤如下:
步骤一:数据预处理准备
1.1对需要被聚类分组的n个物体进行编号,编号值从1到n;以vir表示对象i在属性r上的值;
1.2按下面方法计算每两个对象i和j之间的距离dij,以获得距离矩阵d={dij}:
1)计算对象i和j在属性r上的标准化距离,以dijr表示;
2)当属性r为数字型属性时,令
3)当属性k为分类型属性时,令
4)令
步骤二:建立线性数学规划模型
依据聚类问题的特点并为了避免传统聚类方法对于初始解过于敏感的缺点,本发明建立了线性数学规划模型,该线性数学规划模型由目标函数与约束条件构成,如下:
目标函数:
约束条件:
(1)
(2)
(3)
其中,上列线性数学规划模型中的符号即目标函数与约束条件中的符号,其含义如下所述:
n对象的集合
n对象集n所包含的对象的个数,n=card(n)
i,j对象的标号i,j∈n
dij对象i和对象j之间的距离,dij∈d
m属性的集合
m属性集m所包含的属性的个数,m=card(m)
r属性的标号,r∈m
k聚类的个数
ωij0/1决策变量,当i所在类中心为j时取1;否则取0.
ω变量ωij组成的集合,ωij∈ω
上述约束条件中,约束条件(1)表示每一个对象i都必须且仅能分属于某一个聚类j,满足有ωij=1;约束条件(2)表示必须有m个聚类;约束条件(3)表示仅当对象j为聚类中心时,ωij才允许取1,否则只能取0;
上述数学规划模型是线性的,具备求解可行性;
步骤三:线性数学规划模型求解
其中线性数学规划模型指的是上文中所述,为包含目标函数与约束条件的线性数学规划模型;对该线性数学规划模型最优化求解,可考虑多种已有的求解方式:(1)直接运用单纯形法、分支定界方法、割平面法等对模型进行最优求解;(2)利用求解软件,如lingo,ampl等对模型进行最优化求解;
具体求解方法如下:(1)若直接运用单纯形法、分支定界方法、割平面法等对模型进行最优求解,则可以直接手工演算求解,不再赘述;(2)若利用求解软件,如lingo,ampl等对模型进行最优化求解,则可以建立用于求解的执行脚本文件(*.dat),并将已知数据与线性数学规划模型相应的数据文件(*.dat)与模型文件(*.mod),一并带入软件进行求解,得到求解结果;(文件详情见具体实施方式内容)
步骤四:求解结果输出
求解软件完成对线性数学规划模型求解计算后,可获得求解结果ω,并对其进行解析,获得聚类结果以及各类的中心点;方法如下:
1)对于所有i∈n判断ωii,如果ωii=1,则表示对象i代表一个聚类且代表该类的中心点;
2)如果ωii=1,则对所有j∈n判断ωij,如果ωij=1,则表对象j隶属于对象i所代表的类;
根据上述方法,获得最终的聚类分组结果以及总簇内距离。
通过以上步骤,达到了对一组数据进行聚类分组的效果,使得同组数据的相似度较大,非同组数据的相似度较小;在聚类过程中,解决了传统聚类方法必须给出初始解,并且对于初始解过于敏感的问题;此外本发明可以在不给出初始解的情况下,直接获得最优聚类结果,大大提高了聚类过程的便利性与准确性。
3.3优点和功效
本发明提出的基于线性规划方程的新的k-中心点聚类方法,该方法通过定义新的二元决策变量使得原问题转换为线性整数规划问题,避免了传统方法容易陷入局部最优解和易受初始解影响的问题。通过对随机产生的算例的比较求解计算来看,本发明提出的方法比传统方法能获得更好的聚类效果。
四、附图说明
图1五组随机点的产生区域划分。
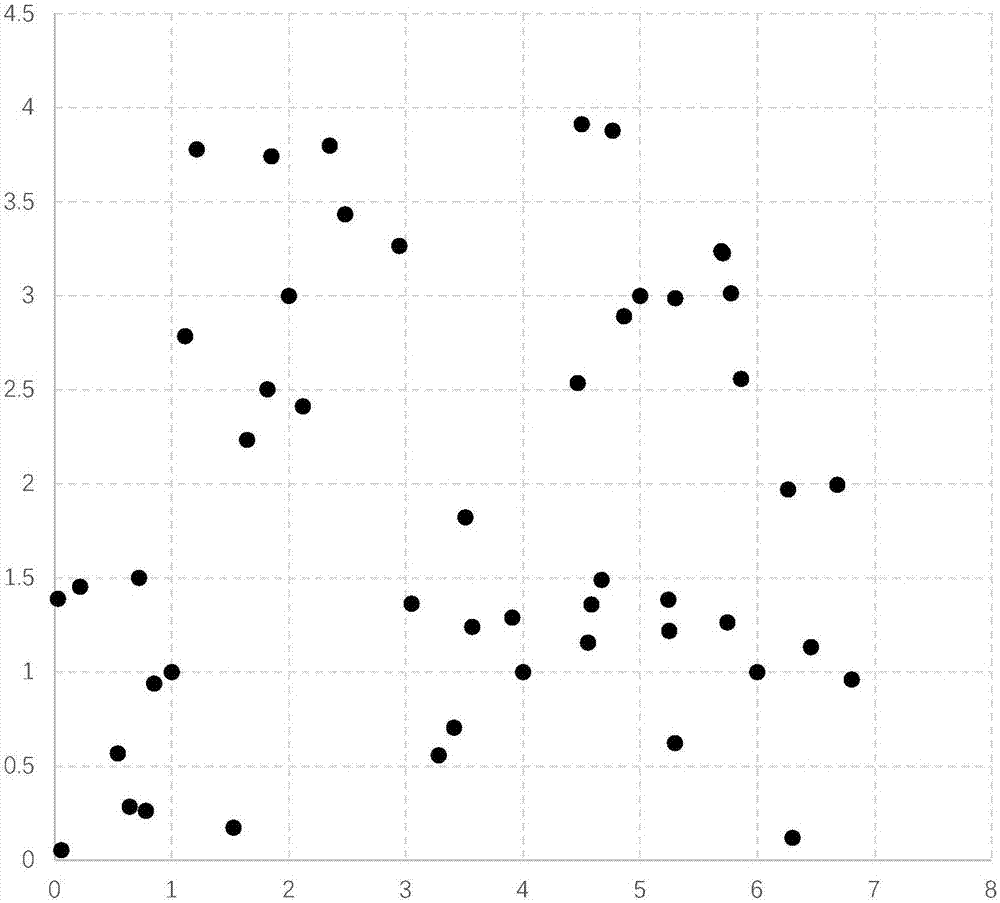
图2算例数据对象的分布散点图。
图3本专利方法对算例的聚类结果的散点图。
图4传统k-中心点聚类方法对算例的聚类结果散点图。
图5本发明的实施流程图。
五、具体实施方式
本节以一个实例说明本发明方法的具体过程,并与传统的k-中心点聚类方法进行比较,以展示该方法的优越性。该实例为将二维平面上的随机50个点按欧式距离聚类为5个类,并使簇类距离达到最小。首先在区域内划分出了5个形状相同的矩形,然后在该5个区域内分别随机生成10个点,共50个点,如图1所示,各点的x和y坐标值在表1中详细列出。
表1随机点的坐标值
下面按照技术方案所给出的四个步骤,将上述50个点(对象)聚类为5个类,并给出每一类的中心点。聚类前50个点的整体分布如图2所示。
本发明一种改进的全局最优化k-中心点聚类方法,该聚类方法流程如图5所示,其具体实施步骤如下:
步骤一:数据预处理准备
对数据对象进行编号,计算距离矩阵d={dij}。这里以ampl环境为例,建立距离矩阵的数据文件syn.dat,格式如下表所示:
步骤二:建立线性数学规划模型
目标函数:
约束条件:
(1)
(2)
(3)
其中,目标函数与约束条件中的符号含义即为上文技术方案的符号表中所述。
基于上述数学规划模型,建立ampl环境下的模型文件syn.mod
步骤三:线性数学规划模型求解
本算例使用求解软件ampl进行求解,建立执行脚本文件syn.sh,如下:
步骤四:求解结果输出
在ampl环境下执行上述文件syn.sh、syn.mod以及syn.dat,执行的计算系统为macbook,计算时间小于1秒。得到最优的目标函数值为36.04,以及最优的ω值。通过对ω值进行解析,获得各聚类的划分结果以及聚类中心点,并绘制散点,如图3所示。
再运用传统的k-中心点聚类方法对讲上述算例进行计算,可得出最小组内距离为42.27,并绘制聚类结果的散点图,如图4所示。通过对比可以发现,传统方法所获得的目标值大于本方法得到的最小组内距离(36.04),在图4中有若干明显的不合理聚类分布,使各聚类的离散程度差异较大。而本方法的聚类结果分布图与初始理想聚类分布图基本一致,结果合理。因此本方法比传统的中心点聚类方法能得到更佳的聚类结果。
六、结论
通过以上步骤,达到了对一组数据进行聚类分组的效果,使得同组数据的相似度较大,非同组数据的相似度较小。在聚类过程中,解决了传统聚类方法必须给出初始解,并且对于初始解过于敏感的问题。本发明可以在不给出初始解的情况下,直接获得最优聚类结果,大大提高了聚类过程的便利性与准确性。
- 还没有人留言评论。精彩留言会获得点赞!