一种云计算中保护数据隐私的快速多关键词语义排序搜索方法与流程
本发明涉及云计算领域,特别是一种云计算中保护数据隐私的快速多关键词语义排序搜索方法。
背景技术:
随着云计算技术的飞速发展,敏感数据越来越多的存储到云中,如电子邮件、个人健康记录、私人视频和照片、公司财务数据和政府文件等。云服务器提供了高质量的数据存储服务,将数据存储到云中,可以减少用户的数据存储和维护开销。但是数据拥有者和云服务器不在同一个信任域中会使外包数据处于危险之中,为了保护用户的隐私安全,将数据加密后再存储到云服务器是一种常见的解决方法。然而数据经过加密后不再具有原有的特性,当用户需要某些数据时,无法直接在密文中分辨出所需要的数据,在数据量很小的情况下,可以将所有的密文数据下载至本地,解密后在明文中搜索自己想要的数据。然而随着云端数据规模的急剧增长,这种浪费了大量时间开销与带宽功耗的做法显然已经不能满足用户的实际需求,因此,如何在大量密文中搜索到需要的文档成为了一个难题。
在song等提出通过密钥流加密数据并实现可搜索加密方案后,wang等提出了单关键词排序搜索方案,通过保序加密对文档的tf-idf(词频-逆文档频率)进行加密,实现对搜索结果的精确排序。cao等提出了多关键词排序可搜索加密方案,引入了向量空间模型和安全knn(securek-nearestneighbor)方法,通过矩阵对索引向量进行加密,并对索引向量和搜索向量计算内积相似度来实现了多关键词的排序搜索。li等提出了支持布尔查询的可搜索加密方案,将执行“或”、“与”、“非”查询词的权重设置为三组正数递增序列ai,bj,ck,并且序列间满足超递增,即∑ai<b1,∑ai+∑bj<c1,接着将执行“非”查询词的权重ck置换成对应的相反数-ck,则相关度分数大于0的文档即为满足布尔查询的相关文档。但是上述方案没有考虑到文档向量的高度稀疏性,一篇文档中往往只会出现少量的关键词,因此文档向量中会出现大量的0,在检索时,云服务器无法知道哪些是相关文档,因而要对所有的文档进行相似度分数的计算和排序,浪费了大量的时间,降低了方案的查询效率。
用户输入的搜索请求经常会出现拼写错误或格式不匹配的情况,以上方案并不能满足用户的实际需求。因此,li等实现了关键词的模糊搜索方案,用通配符的方法构造关键词模糊集合,并以编辑距离作为相似度度量标准。liu等提出了节省存储空间的模糊搜索方案,通过字典来构造模糊集,但是搜索的精确度有所降低。chai等人首次提出了“半诚实且好奇”的云服务器模型,服务器提供商为了节省计算量和带宽资源,可能仅仅执行了部分搜索操作并返回部分搜索结果,因此,文章提出了基于查找树索引结构的可验证的可搜索加密方案。wang等利用通配符和索引树,实现了高效的模糊搜索方案。chuah等为了提高搜索效率,实现了基于bedtree的多关键词模糊搜索方案。wang等将局部敏感哈希和安全knn方法(securek-nearestneighbor)结合,实现了一种新的多关键词模糊搜索方案。wang等人在关键词模糊搜索的基础上,通过构造符号索引树,提出了可验证的关键词模糊搜索方案。但是以上的模糊搜索方案仅仅考虑了关键词字符上的相似,并没有考虑到关键词语义上的相似。因此,fu等对文档关键词进行同义词拓展,通过计算内积的方式,实现了支持同义词查询的多关键词排序搜索方案。xia等为文档集创建倒排索引,利用语义库扩展查询关键词,并且通过一对多保序加密函数对相关度分数进行加密,实现了多关键词语义排序搜索方案。然而,这些语义模糊搜索方案没有将语义相似度参与到文档的评分中,并且忽略了不同域中的关键词的权重差异。
针对目前的密文关键词搜索方案中,查询效率低、索引创建时间长、排序结果不精确等问题,本发明提出了一种可以提高查询效率、降低索引创建时间,并实现语义的密文关键词搜索方案。
技术实现要素:
有鉴于此,本发明的目的是提出一种云计算中保护数据隐私的快速多关键词语义排序搜索方法,可以提高查询效率、降低索引创建时间,并实现语义的密文关键词搜索。
本发明采用以下方案实现:一种云计算中保护数据隐私的快速多关键词语义排序搜索方法,包括数据拥有者、授权用户、私有云服务器以及公有云服务器,具体包括以下步骤:
步骤s1:数据拥有者从明文文档集合f=(f1,f2,…,fm)中抽取关键词,得到关键词集合w=(w1,w2,…,wn);
步骤s2:数据拥有者随机产生一个(n+2)比特的向量s和两个(n+2)×(n+2)维的可逆矩阵{m1,m2},密钥sk由四元组{s,m1,m2,u}组成,u是一个正整数并且u|n;接着,数据拥有者生成一个加密文档的密钥sk,将密钥sk、sk发送给授权用户;
步骤s3:创建索引:数据拥有者为每篇文档fi生成文档向量
采用安全knn算法加密文档向量
步骤s4:数据拥有者使用对称加密算法对文档集合f=(f1,f2,…,fm)进行加密,得到密文集合c=(c1,c2,…,cm)并上传给公有云服务器;
步骤s5:构建陷门:当授权用户搜索时,首先输入η个搜索关键词γ=(q1,q2,…,qs,…,qη),接着进行语义扩展,计算原单词qs和拓展词之间的语义相似度并排序,选取最相关的前σ个拓展词作为最终拓展词,得到语义拓展集合q=(q1,q2,…,qη,δ1,…,δσ)及其对应的语义相似度分数sc=(sc1,sc2,…,scη,scη+1,…,scη+σ);根据语义扩展集q创建查询向量
采用安全knn算法加密查询向量
步骤s6:私有云服务器接收到授权用户发送的查询标记向量
私有云服务器将sid∈上传给公有云服务器,公有云服务器根据索引的标识符sidi找到对应的安全索引ii,将对应的vi和陷门tq计算文档的相似度分数,将所有分数排序后,返回前k篇文档给用户;
步骤s7:授权用户使用数据拥有者分发的密钥sk,对返回的top-k篇密文进行解密,获得所需的明文文档集。
进一步地,还包括分别对文档向量和查询向量进行分块,生成维数较小的文档标记向量和查询标记向量,通过文档标记向量和查询标记向量的匹配,快速过滤掉大量无关文档。
进一步地,对文档向量进行分块具体包括以下步骤:
步骤s11:文档向量
步骤s12:遍历所有文档,得到文档标记向量集合b=(b1,b2,...,bm)。
进一步地,通过文档标记向量和查询标记向量的匹配具体包括以下步骤:
步骤s21:私有云服务器接收到授权用户发送的查询标记向量
步骤s22:块的标记值bbs若为0,则说明该文档对应的块没有搜索的关键词,如果为1则将对应的索引标识符sidi记录下来,得到可能包含搜索关键词的候选索引标识符集合sid∈=(···,sidi,···,sidj,···,sidz,···);
步骤s23:私有云服务器将sid∈上传给公有云服务器,公有云服务器根据索引的标识符sidi找到对应的安全索引ii,将对应的vi和陷门tq计算文档的相似度分数,将所有分数排序后,返回前k篇文档给用户。
进一步地,还包括将文档向量分段,将每一段分别与维度减小的矩阵相乘,具体包括以下步骤:
步骤s31:数据拥有者随机产生一个(n+2)比特的向量s和两个(n+2)×(n+2)维的可逆矩阵{m1,m2},密钥sk由四元组{s,m1,m2,u}组成,u是一个正整数并且u|n;
步骤s32:数据拥有者在构建索引时,根据安全knn算法将文档向量
步骤s33:授权用户在生成陷门时也采用步骤s32中构建索引时类似的操作,得到陷门
步骤s34:公有云服务器在计算相关度分数时,采用的公式如下:
进一步地,所述排序采用三因子排序方法,对处于文档不同域中的关键词赋予不同的权重,将语义相似度、域加权评分和相关度分数三者结合,具体包括以下步骤:
步骤s41:计算语义相似度:采用基于信息内容的resnik算法;
步骤s42:计算域加权评分:给定一系列文档,假定每篇文档有l个域,其对应的权重系数分别是g1,…gl∈[0,1],他们满足:
令si为查询和文档的第i个域的匹配得分,其中1和0分别表示是否匹配,于是,域加权评分定义为:
步骤s43:计算相关度分数:基于tf-idf权值计算方法以及tf的亚线性尺度变换方法计算相关度分数。
与现有技术相比,本发明有以下有益效果:
1、本发明能够实现高效的查询效率:本发明针对可搜索加密方案效率不高的缺陷,设计了一种向量分块标记匹配算法,分别对文档向量和查询向量进行分块,生成维数较小的文档标记向量和查询标记向量。通过文档标记向量和查询标记向量的匹配,快速过滤掉大量无关文档,减少了计算文档相似度分数和排序的时间,提高了检索的效率。
2、本发明能够减少索引创建时间:可搜索加密方案创建的文档向量的维度通常很大,所以方案构建索引的时间主要花费在文档向量和矩阵的相乘上。本发明设计了一种向量分段加密算法,将文档向量分段,将每一段分别与维度大大减小的矩阵相乘,这使得此方案的索引构建时间大大减少。
3、本发明能够精确返回排序结果:本发明首次将域加权评分的概念引入文档的评分当中,对处于文档不同域中的关键词赋予不同的权重,解决了现有方案中未考虑关键词位置信息的缺陷,同时实现了语义模糊检索。本发明将语义相似度、域加权评分和相关度分数三者结合,设计了一种三因子排序方法,云服务器能够对搜索结果进行精确的排序并返回给搜索用户。
附图说明
图1为本发明实施例的系统框架图。
图2为本实施例索引的创建过程。
图3为本发明实施例中陷门的构建过程。
图4为本发明实施例中当文档数量m=10,关键词数n=100,标记向量维度u=10时,向量分块标记算法的过程。
图5为本发明实施例中当文档数量m=10时,文档标记向量与查询标记向量匹配算法的过程。
图6为本发明实施例中向量分段加密算法的主要过程。
具体实施方式
下面结合附图及实施例对本发明做进一步说明。
图1为本发明实施例的系统框架,包含四个实体:数据拥有者,授权用户,私有云服务器和公有云服务器。本实施例的索引和陷门加密采用安全knn算法加密(可以参考wongwk,cheungwl,kaob,etal.secureknncomputationonencrypteddatabases//proceedingsoftheacmsigmodinternationalconferenceonmanagementofdata.newyork,usa,2009:139-152.)。本实施例的基本流程如下:
(1)setup:数据拥有者从明文文档集合f=(f1,f2,…,fm)中抽取关键词,得到关键词集合w=(w1,w2,…,wn)。
(2)keygen(n):数据拥有者随机产生一个(n+2)比特的向量s和两个(n+2)×(n+2)维的可逆矩阵{m1,m2},密钥sk由四元组{s,m1,m2,u}组成,u是一个正整数并且u|n。接着,数据拥有者生成一个加密文档的密钥sk,将密钥sk、sk发送给授权用户。
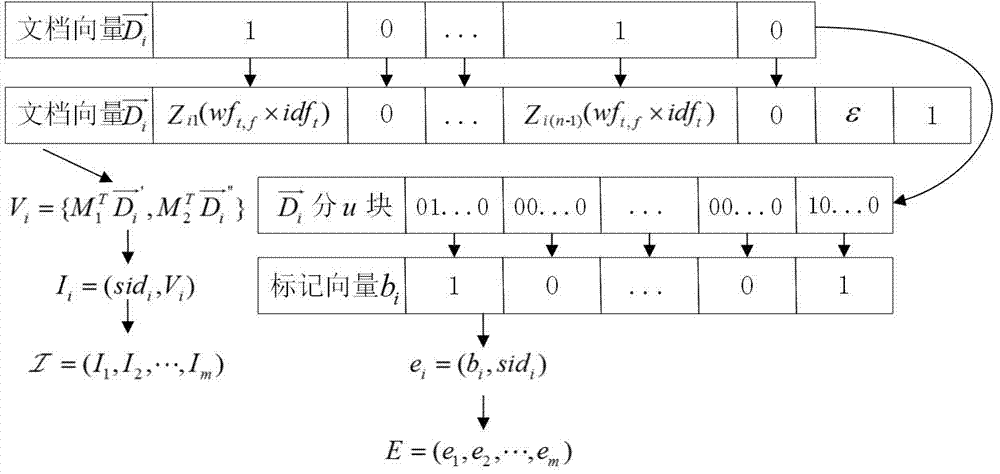
(3)buildindex(f,w,sk):图2为本实施例索引的创建过程,基于向量空间模型,数据拥有者为每篇文档fi生成文档向量
采用安全knn算法加密文档向量
(4)encrypt(f,sk):数据拥有者使用对称加密算法对文档集合f=(f1,f2,…,fm)进行加密,得到密文集合c=(c1,c2,…,cm)并上传给公有云服务器。
(5)trapdoor(γ,sk):图3为本发明实施例中陷门的构建过程,当授权用户搜索时,首先输入η个搜索关键词γ=(q1,q2,…,qs,…,qη)。接着进行语义扩展,计算原单词qs和拓展词之间的语义相似度并排序,选取最相关的前σ个拓展词作为最终拓展词,得到语义拓展集合q=(q1,q2,…,qη,δ1,…,δσ)及其对应的语义相似度分数sc=(sc1,sc2,…,scη,scη+1,…,scη+σ)。根据语义扩展集q创建查询向量
采用安全knn算法加密查询向量
(6)query
私有云服务器将sid∈上传给公有云服务器,公有云服务器根据索引的标识符sidi找到对应的安全索引ii,将对应的vi和陷门tq计算文档的相似度分数,将所有分数排序后,返回前k篇文档给用户。
(7)decrypt(c,sk):授权用户使用数据拥有者分发的密钥sk,对返回的top-k篇密文进行解密,获得所需的明文文档集。
较佳的,本实施例还采用了向量分块标记匹配算法,具体如下:
可搜索加密方案创建的字典集一般很大,这使得mrse方案(caon,wangc,lim,etal.privacy-preservingmulti-keywordrankedsearchoverencryptedclouddata.ieeetransactionsonparallelanddistributedsystems,2014,25(1):829-837)中创建的文档向量的维度通常很大。在检索时,云服务器无法知道哪些是相关文档,因而要对所有文档进行相似度分数的计算和排序,浪费了大量的时间。
本实施例分别对文档向量和查询向量进行分块,生成维数较小的文档标记向量和查询标记向量。通过文档标记向量和查询标记向量的匹配,快速过滤掉大量无关文档,减少了计算文档相似度分数和排序的时间,提高了检索的效率。
(1)向量分块标记算法:
文档向量
遍历所有文档,得到文档标记向量集合b=(b1,b2,...,bm)。
图4表示当文档数量m=10,关键词数n=100,标记向量维度u=10时,向量分块标记算法的过程。
关键词数n=100,则文档向量
将10个文档依次按此操作得到文档标记向量b1到b10。
(2)查询标记向量和文档标记向量的匹配算法:
私有云服务器接收到授权用户发送的查询标记向量
块的标记值bbs若为0,则说明该文档对应的块没有搜索的关键词,如果为1则将对应的索引标识符sidi记录下来,得到可能包含搜索关键词的候选索引标识符集合sid∈=(···,sidi,···,sidj,···,sidz,···);
私有云服务器将sid∈上传给公有云服务器,公有云服务器根据索引的标识符sidi找到对应的安全索引ii,将对应的vi和陷门tq计算文档的相似度分数,将所有分数排序后,返回前k篇文档给用户。
图5表示当文档数量m=10时,文档标记向量与查询标记向量匹配算法的过程。
当查询关键词的标记向量为
依次将
私有云服务器将候选索引标识符集合sid∈发送给公有云服务器,进行相似度分数的计算及排序操作。
较佳的,本实施例还采用了向量分段加密算法,具体如下:
mrse方案(caon,wangc,lim,etal.privacy-preservingmulti-keywordrankedsearchoverencryptedclouddata.ieeetransactionsonparallelanddistributedsystems,2014,25(1):829-837)创建的文档向量的维度通常很大,所以方案构建索引的时间主要花费在文档向量和矩阵的相乘上。本实施例将文档向量分段,将每一段分别与维度大大减小的矩阵相乘,这使得此方案的索引构建时间大大减少。
图6为向量分段加密算法的主要过程,步骤如下:
1)数据拥有者随机产生一个(n+2)比特的向量s和两个(n+2)×(n+2)维的可逆矩阵{m1,m2},密钥sk由四元组{s,m1,m2,u}组成,u是一个正整数并且u|n。
2)数据拥有者在构建索引时,根据安全knn算法将文档向量
3)授权用户在生成陷门时也采用构建索引时类似的操作,得到陷门
4)公有云服务器在计算相关度分数时,采用的公式如下:
较佳的,本实施例还采用了三因子排序方法。具体如下:
本实施例实现了语义模糊检索,当授权用户希望搜索到查询关键词语义相关的文档,或者由于各种原因无法输入准确的关键词时,也可以匹配到语义相关的文档并返回给授权用户,满足用户的搜索需求。
本实施例首次将域加权评分的概念引入文档的评分当中,对处于文档不同域中的关键词赋予不同的权重,将语义相似度、域加权评分和相关度分数三者结合,提出了一种三因子排序方法,使得排序结果更加精确。
(1)语义相似度
本实施例采用基于信息内容的resnik算法(可以参考resnikp.usinginformationcontenttoevaluatesemanticsimilarityinataxonomy.//proceedingsofthe14thinternationaljointconferenceonartificialintelligence.montreal,canada,1995:448-453.)计算语义相似度,步骤如下:
1)采用resnik算法计算两个概念c1和c2相似度,计算公式如下:
sim(c1,c2)=-logp(lso(c1,c2))=ic(lso(c1,c2))
其中lso(c1,c2)表示概念c1和c2在wordnetis-a树中最深层的公共父节点。
p(c)是wordnet语料库中出现概念c的名词的概率,其计算方法如下:
其中,n表示wordnet语料库中名词的个数,freq(c)表示语料库中包含概念c的单词个数,其计算公式如下:
其中,words(c)表示包含概念c的单词集合。
2)resnik算法计算两个单词w1和w2相似度,计算公式如下:
其中,s(w1)和s(w2)分别表示单词w1和w2包含的概念集合,一个单词可能包含若干个概念。
(2)域加权评分
本实施例首次将域加权评分(可以参考manningcd,raghavanp,schützeh.introductiontoinformationretrieval.cambridge:cambridgeuniversitypress,2008.)的概念引入文档的评分当中,给定一系列文档,假定每篇文档有l个域,其对应的权重系数分别是g1,…gl∈[0,1],它们满足:
令si为查询和文档的第i个域的匹配得分(1和0分别表示是否匹配),于是,域加权评分方法可以定义为:
(3)相关度分数
基于tf-idf权值计算方法,并参考tf的亚线性尺度变换方法(可以参考jinli,chenx.efficientmulti-userkeywordsearchoverencrypteddataincloudcomputing.computing&informatics,2013,32(4):723-738),步骤如下:
1)计算词频权重wft,f:
2)计算逆文档频率idft:
本实施例将语义相似度、域加权评分和相关度分数三者结合,设计一种三因子排序方法,使得排序结果更加精确。公有云服务器上文档得分的计算公式如下:
其中,zij、(wft,f×idft)和scj分别为文档fi中关键词wj的域加权评分、相关度分数和语义相似度。
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
- 还没有人留言评论。精彩留言会获得点赞!