用于图纸排版的文本断句方法及系统与流程
本发明涉及图纸排版,具体涉及用于图纸排版的文本断句方法及系统。
背景技术:
随着国际合作日益加强,无论是中国公司还是外国公司,在国际工程与国际科研的立项及开展过程中,都需要通过图纸文件与对方进行交流。图纸文件中的注释内容、公司信息和标注等文本往往需要进行非语法的断句,由于各种语言文化的差异,这些文本断句往往也存在极大的区别,增大了文本断句的难度。
传统对图纸排版中文本的断句,往往采用人工排版和人工断句,费时费力,成本较高;同时,对不同语言的图纸需要不同的工作人员对其进行排版和断句,极大的降低了图纸排版效率。
技术实现要素:
本发明所要解决的技术问题是在图纸排版中采用人工断句时,费时费力,成本较高,多语种图纸文本断句效率低下,目的在于提供用于图纸排版的文本断句方法及系统,解决上述问题。
本发明通过下述技术方案实现:
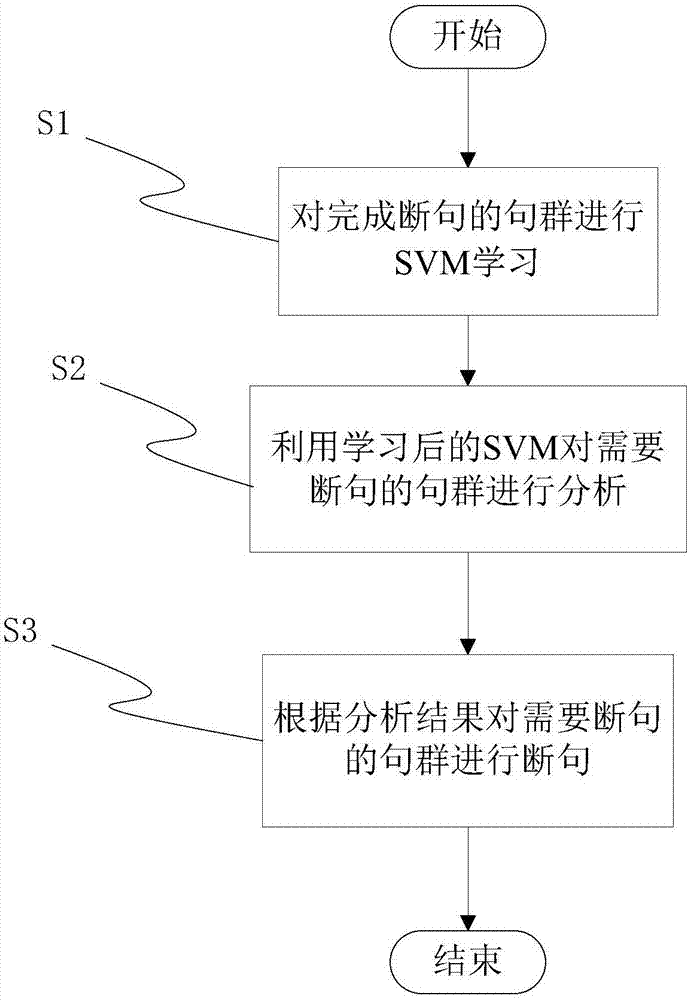
用于图纸排版的文本断句方法,包括以下步骤:s1:对完成断句的句群进行svm学习;s2:利用学习后的svm对需要断句的句群进行分析;s3:根据分析结果对需要断句的句群进行断句。
现有技术中,图纸排版中采用人工断句时,费时费力,成本较高,多语种图纸文本断句效率低下。本发明应用时,先对完成断句的句群进行svm学习,再利用学习后的svm对需要断句的句群进行分析,然后根据分析结果对需要断句的句群进行断句,从而实现对图纸排版中的文字进行机器断句,提高了文本断句效率,降低了成本。对断句的句群进行机器学习时,由于句群的特征量庞大,使得学习样本为高维样本,一般的机器学习方法在这里需要对学习样本进行降维处理,同时,句群的特征量一般为非线性数据,一般的机器学习方法对非线性问题处理效果不好。针对以上两个特点,发明人通过大量实验和创造性劳动,优选出svm作为本发明的机器学习方法,svm适合解决高维问题,而不需要对学习样本进行降维处理,提高了文本断句效率,同时svm适合解决非线性问题,提高了本发明的处理效果。svm比起其他机器学习方法,还具有小样本情况下,机器学习的能力,这就使得进行多语种图纸文本断句时,只需要增加一个语种的小样本进行学习,就可以实现对该语种图纸文本的断句,提高了多语种图纸文本断句的效率。
进一步的,步骤s1包括以下子步骤:s11:收集完成断句的句群;s12:标记完成断句的句群中需要提取特征的地方;s13:对标记后句群的特征进行svm学习。
本发明应用时,先收集完成断句的句群,再标记完成断句的句群中需要提取特征的地方,然后对标记后句群的特征进行svm学习。本发明通过对完成断句的句群进行标记,提高了提取特征的准确性和效率。
再进一步的,步骤s13中所述svm学习包括利用线性核函数对特征进行处理。
本发明应用时,所述svm学习包括利用线性核函数对特征进行处理。svm在机器学习的过程中,需要数据是可分的,而句群的特征量在当前维度是不可分的,于是需要通过核函数对该句群的特征量进行升维使得句群的特征量在更高的维度上可分。发明人选取了线性核函数、多项式核函数、sigmoid核函数和高斯核函数等多种核函数进行大量的实验和创造性劳动发现,多项式核函数、sigmoid核函数和高斯核函数在机器学习过程中,会使得svm出现过学习现象,从而将线性核函数优选为本发明所使用的核函数,使得svm学习过程更加稳定,对文本断句处理更加准确。
再进一步的,所述svm学习后形成二元分类器。
本发明应用时,svm学习后形成二元分类器,使得svm在对需要断句的句群分析时,只需要通过二元分类器将该句群的特征值与学习的特征值进行“是”与“否”的判断,就可以得出需要断句的位置,提高了文本断句效率。
进一步的,步骤s2包括以下子步骤:s21:输入需要断句的句群;s22:标记需要断句的句群中需要提取特征的地方;s23:对标记后句群的特征通过svm进行分析。
本发明应用时,先输入需要断句的句群,再标记需要断句的句群中需要提取特征的地方,然后对标记后句群的特征通过svm进行分析。本发明通过对需要断句的句群进行标记,提高了提取特征的准确性和效率。
用于图纸排版的文本断句系统,包括:对完成断句的句群进行svm学习的学习单元;利用学习后的svm对需要断句的句群进行分析的分析单元;根据分析结果对需要断句的句群进行断句的断句单元。
现有技术中,图纸排版中采用人工断句时,费时费力,成本较高,多语种图纸文本断句效率低下。本发明应用时,学习单元对完成断句的句群进行svm学习,分析单元利用学习后的svm对需要断句的句群进行分析,断句单元根据分析结果对需要断句的句群进行断句,从而实现对图纸排版中的文字进行机器断句,提高了文本断句效率,降低了成本。对断句的句群进行机器学习时,由于句群的特征量庞大,使得学习样本为高维样本,一般的机器学习方法在这里需要对学习样本进行降维处理,同时,句群的特征量一般为非线性数据,一般的机器学习方法对非线性问题处理效果不好。针对以上两个特点,发明人通过大量实验和创造性劳动,优选出svm作为本发明的机器学习方法,svm适合解决高维问题,而不需要对学习样本进行降维处理,提高了文本断句效率,同时svm适合解决非线性问题,提高了本发明的处理效果。svm比起其他机器学习方法,还具有小样本情况下,机器学习的能力,这就使得进行多语种图纸文本断句时,只需要增加一个语种的小样本进行学习,就可以实现对该语种图纸文本的断句,提高了多语种图纸文本断句的效率。
进一步的,所述分析单元包括:用于输入需要断句的句群的输入模块;用于标记需要断句的句群中需要提取特征的地方的标记模块;用于对标记后句群的特征通过svm进行分析的分析模块。
本发明应用时,输入模块输入需要断句的句群,标记模块标记需要断句的句群中需要提取特征的地方,分析模块对标记后句群的特征通过svm进行分析。本发明通过对需要断句的句群进行标记,提高了提取特征的准确性和效率。
本发明与现有技术相比,具有如下的优点和有益效果:
1、本发明用于图纸排版的文本断句方法,通过svm学习,提高了文本断句效率,降低了成本,提高了多语种图纸文本断句的效率;
2、本发明用于图纸排版的文本断句方法,通过将线性核函数优选为本发明所使用的核函数,使得svm学习过程更加稳定,对文本断句处理更加准确;
3、本发明用于图纸排版的文本断句方法,svm学习后形成二元分类器,提高了文本断句效率;
4、本发明用于图纸排版的文本断句方法,通过对需要断句的句群进行标记,提高了提取特征的准确性和效率;
5、本发明用于图纸排版的文本断句方法,通过对需要断句的句群进行标记,提高了提取特征的准确性和效率;
6、本发明用于图纸排版的文本断句系统,通过svm学习,提高了文本断句效率,降低了成本,提高了多语种图纸文本断句的效率;
7、本发明用于图纸排版的文本断句系统,通过对需要断句的句群进行标记,提高了提取特征的准确性和效率。
附图说明
此处所说明的附图用来提供对本发明实施例的进一步理解,构成本申请的一部分,并不构成对本发明实施例的限定。在附图中:
图1为本发明方法步骤示意图;
图2为本发明s1子步骤示意图;
图3为本发明s2子步骤示意图;
图4为本发明系统结构示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,下面结合实施例和附图,对本发明作进一步的详细说明,本发明的示意性实施方式及其说明仅用于解释本发明,并不作为对本发明的限定。
实施例1
如图1所示,用于图纸排版的文本断句方法,包括以下步骤:s1:对完成断句的句群进行svm学习;s2:利用学习后的svm对需要断句的句群进行分析;s3:根据分析结果对需要断句的句群进行断句。
本实施例实施时,先对完成断句的句群进行svm学习,再利用学习后的svm对需要断句的句群进行分析,然后根据分析结果对需要断句的句群进行断句,从而实现对图纸排版中的文字进行机器断句,提高了文本断句效率,降低了成本。对断句的句群进行机器学习时,由于句群的特征量庞大,使得学习样本为高维样本,一般的机器学习方法在这里需要对学习样本进行降维处理,同时,句群的特征量一般为非线性数据,一般的机器学习方法对非线性问题处理效果不好。针对以上两个特点,发明人通过大量实验和创造性劳动,优选出svm作为本发明的机器学习方法,svm适合解决高维问题,而不需要对学习样本进行降维处理,提高了文本断句效率,同时svm适合解决非线性问题,提高了本发明的处理效果。svm比起其他机器学习方法,还具有小样本情况下,机器学习的能力,这就使得进行多语种图纸文本断句时,只需要增加一个语种的小样本进行学习,就可以实现对该语种图纸文本的断句,提高了多语种图纸文本断句的效率。
实施例2
如图2所示,本实施例在实施例1的基础上,步骤s1包括以下子步骤:s11:收集完成断句的句群;s12:标记完成断句的句群中需要提取特征的地方;s13:对标记后句群的特征进行svm学习。
本实施例实施时,先收集完成断句的句群,再标记完成断句的句群中需要提取特征的地方,然后对标记后句群的特征进行svm学习。本发明通过对完成断句的句群进行标记,提高了提取特征的准确性和效率。
实施例3
本实施例在实施例2的基础上,步骤s13中所述svm学习包括利用线性核函数对特征进行处理。
本实施例实施时,所述svm学习包括利用线性核函数对特征进行处理。svm在机器学习的过程中,需要数据是可分的,而句群的特征量在当前维度是不可分的,于是需要通过核函数对该句群的特征量进行升维使得句群的特征量在更高的维度上可分。发明人选取了线性核函数、多项式核函数、sigmoid核函数和高斯核函数等多种核函数进行大量的实验和创造性劳动发现,多项式核函数、sigmoid核函数和高斯核函数在机器学习过程中,会使得svm出现过学习现象,从而将线性核函数优选为本发明所使用的核函数,使得svm学习过程更加稳定,对文本断句处理更加准确。
实施例4
本实施例在实施例3的基础上,所述svm学习后形成二元分类器。
本实施例实施时,svm学习后形成二元分类器,使得svm在对需要断句的句群分析时,只需要通过二元分类器将该句群的特征值与学习的特征值进行“是”与“否”的判断,就可以得出需要断句的位置,提高了文本断句效率。
实施例5
如图3所示,本实施例在实施例1的基础上,步骤s2包括以下子步骤:s21:输入需要断句的句群;s22:标记需要断句的句群中需要提取特征的地方;s23:对标记后句群的特征通过svm进行分析。
本实施例实施时,先输入需要断句的句群,再标记需要断句的句群中需要提取特征的地方,然后对标记后句群的特征通过svm进行分析。本发明通过对需要断句的句群进行标记,提高了提取特征的准确性和效率。
实施例6
本实施例在实施例1~5的基础上,需要分句的句群为:
图3临潼强震台强震动记录xi'ancateringco.,ltd.
本实施例实施时,对该句群进行标记,标记后为
图3临潼强震台强震动记录xi'ancateringco.,ltd.
然后提取特征,对临潼这个词提取特征如下:
a)这个词本身是什么——临潼
b)前一个词是数字吗——是
c)前两个词是什么——图
d)前一个词是什么——3
e)后一个词——强
f)当前词词性——名词
g)前一个词词性——数词
h)后一个词词性——名词
对记录这个词提取特征如下:
a)这个词本身是什么——记录
b)前一个词是数字吗——否
c)前两个词是什么——强
d)前一个词是什么——震动
e)后一个词——xi'an
f)当前词词性——名词
g)前一个词词性——名词
h)后一个词词性——名词
svm学习时,提取的断句特征为后一个词为拉丁字母构成的文字,二元分类器对临潼和记录这两个词分类,结果为临潼为否,记录为是,则在记录后面进行断句,断句后的结果为:
图3临潼强震台强震动记录
xi'ancateringco.,ltd.
实施例7
本实施例在实施例6的基础上,需要分句的句群为:
综合资质甲级a141001996号comprehensivegradeaqualificationno.a141001996
本实施例实施时,对该句群进行标记,标记后为
综合资质甲级a141001996号comprehensivegradeaqualificationno.a141001996
然后提取特征,对甲级这个词提取特征如下:
a)这个词本身是什么——甲级
b)前一个词是数字吗——否
c)前两个词是什么——综合
d)前一个词是什么——资质
e)后一个词——a
f)后两个词是什么——141001996
g)当前词词性——形容词
h)前一个词词性——名词
i)后一个词词性——字母
对号这个词提取特征如下:
a)这个词本身是什么——号
b)前一个词是数字吗——是
c)前两个词是什么——a
d)前一个词是什么——141001996
e)后一个词——comprehensive
f)后两个词是什么——grade
g)当前词词性——名词
h)前一个词词性——数词
i)后一个词词性——形容词
svm学习时,提取的断句特征为后一个词为拉丁字母构成的文字且后两个词也为拉丁字母构成的文字,二元分类器对甲级和号这两个词分类,结果为甲级为否,号为是,则在号后面进行断句,断句后的结果为:
综合资质甲级a141001996号
comprehensivegradeaqualificationno.a141001996
实施例8
本实施例在实施例6的基础上,需要分句的句群为:
5)anchorpanelstobeinstalledandboltedtothestonewallatallhorizontaljoints.6)listelanclestobeextended6'beyondthewindowopeningateachends.
本实施例实施时,对该句群进行标记,标记后为:
5)anchorpanelstobeinstalledandboltedtothestonewallatallhorizontaljoints.6)listelanclestobeextended6'beyondthewindowopeningateachends.
然后提取特征,对installed这个词提取特征如下:
a)这个词本身是什么——installed
b)前一个词是数字吗——否
c)前两个词是什么——to
d)前一个词是什么——be
e)后一个词——and
f)后两个词是什么——bolted
g)当前词词性——形容词
h)前一个词词性——动词
i)后一个词词性——介词
对第一个.提取特征如下:
a)这个词本身是什么——.
b)前一个词是数字吗——否
c)前两个词是什么——horizontal
d)前一个词是什么——joints
e)后一个词——6
f)后两个词是什么——)
g)当前词词性——标点
h)前一个词词性——动词
i)后一个词词性——数词
svm学习时,提取的断句特征为后一个词为数词且后两个词为反括号,二元分类器对installed和.这两个词分类,结果为installed为否,.为是,则在.后面进行断句,断句后的结果为:
5)anchorpanelstobeinstalledandboltedtothestonewallatallhorizontaljoints.
6)listelanclestobeextended6'beyondthewindowopeningateachends.
实施例9
本发明用于图纸排版的文本断句系统,包括:对完成断句的句群进行svm学习的学习单元;利用学习后的svm对需要断句的句群进行分析的分析单元;根据分析结果对需要断句的句群进行断句的断句单元。
本实施例实施时,学习单元优选为ibm公司的asic芯片,断句单元优选为ad8130arm,学习单元对完成断句的句群进行svm学习,分析单元利用学习后的svm对需要断句的句群进行分析,断句单元根据分析结果对需要断句的句群进行断句,从而实现对图纸排版中的文字进行机器断句,提高了文本断句效率,降低了成本。对断句的句群进行机器学习时,由于句群的特征量庞大,使得学习样本为高维样本,一般的机器学习方法在这里需要对学习样本进行降维处理,同时,句群的特征量一般为非线性数据,一般的机器学习方法对非线性问题处理效果不好。针对以上两个特点,发明人通过大量实验和创造性劳动,优选出svm作为本发明的机器学习方法,svm适合解决高维问题,而不需要对学习样本进行降维处理,提高了文本断句效率,同时svm适合解决非线性问题,提高了本发明的处理效果。svm比起其他机器学习方法,还具有小样本情况下,机器学习的能力,这就使得进行多语种图纸文本断句时,只需要增加一个语种的小样本进行学习,就可以实现对该语种图纸文本的断句,提高了多语种图纸文本断句的效率。
实施例10
本实施例在实施例9的基础上,所述分析单元包括:用于输入需要断句的句群的输入模块;用于标记需要断句的句群中需要提取特征的地方的标记模块;用于对标记后句群的特征通过svm进行分析的分析模块。
本实施例实施时,输入模块优选为usb2.0,标记模块优选为ad5339arm,分析模块优选为scx-asic,输入模块输入需要断句的句群,标记模块标记需要断句的句群中需要提取特征的地方,分析模块对标记后句群的特征通过svm进行分析。本发明通过对需要断句的句群进行标记,提高了提取特征的准确性和效率。
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!