一种基于数据服务依赖图的高校数据组合视图自动生成方法与流程
本发明专利涉及高校数据集成、数据服务、视图生成等领域,特别是给出了一种基于数据服务依赖图的高校数据组合视图自动生成方法。
背景技术:
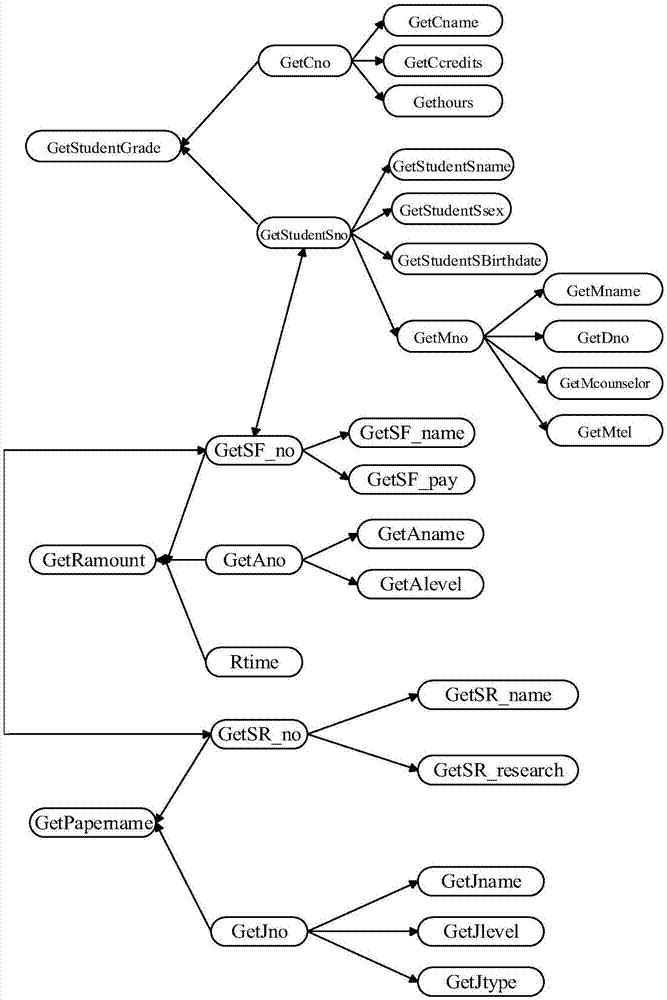
:随着数字化校园建设的深入发展,高校各部门都建立了业务信息系统,如门户网站系统、教务信息系统、教学信息系统、人事信息系统、科研信息系统等,积累了大量的行政、教学、科研、财务、人事等方面的数据。由于这些信息系统采用不同的数据库和开发技术,导致数据存储在跨平台且异构,形成了一个个“数据孤岛”,使分散在高校各部门的数据难以集成和共享。因此,如何对跨部门异构数据进行集成并在此基础上通过数据组合方法满足用户数据需求变得越来越重要。在高校数据集成方法研究方面,吴振涛(电子设计工程,2016)设计了一套基于数据仓库技术的数据集成方案,将数据从业务系统中抽离出来,根据主题重新进行组合,实现业务系统间的数据共享;肖瑞等(中国科技信息,2013)基于云计算的环境下提出一种数字化校园数据集成系统的框架,借助云计算环境下统一的数据获取、分析、应用接口和异构数据集成、访问接口,可实时将学校各系统数据汇总统计;郭越等(自动化技术与应用,2011)提出了基于ODI的高校异构数据库数据集成的解决方案,说明了传统ETL工具的缺点和ODI的优势,提供了一种数字化校园异构数据源数据集成的有效方法。在基于数据服务的数据集成技术研究方面,XLiu等(InternationalConferenceonInformationScience&Applications,2014)为现代企业信息系统设计了一套数据服务架构,用来解决数据的语义集成和数据服务器的适应性,使各种企业信息系统能获取和共享数据;谢兴生等(中国科学技术大学学报,2009)提出了一种基于数据服务匹配的数据集成方法,该方法主要基于数据服务发布、注册和检索的方式,利用数据形式语义进行数据集成,并增强与语义Web和描述逻辑推理等智能技术的融合,具有良好的性能和可伸缩性;温彦等(计算机科学与探索,2012)提出了跨组织业务数据视图的动态生成方法iViewer,通过可视化和易用的数据服务组合操作来动态构建数据视图;张鹏等(计算机学报,2013)提出了一种基于数据服务的嵌套视图动态更新方法,利用指针为嵌套视图中的元组建立嵌套任意层次的数据服务的引用,同时给出了一种记录数据服务更新的日志以及在该日志上的嵌套视图增量更新算法,该方法减少了嵌套视图的更新时间,提高了嵌套视图的数据新鲜度;王桂玲等(计算机学报,2015)提出了基于云计算的流数据集成与服务,归纳了大规模流数据的集成与服务研究面临的挑战,探讨了云计算环境下求解相关问题的思路;谢军等(武汉大学学报,2014)提出一种基于虚拟视图的多源数据集成方法,该方法利用分类包装器对底层物理数据进行包装和转换,统一异构数据源访问接口,把底层的数据转换为统一的数据模型,有效地实现了多源异构数据的集成。技术实现要素:本发明要克服现有技术的上述缺点,提出一种基于数据服务依赖图的高校数据组合视图自动生成方法,将高校各个部门的异构数据集封装为数据服务,然后根据数据服务间的依赖关系构建成数据服务依赖图,在数据服务依赖图的基础上根据用户数据需求自动对数据服务组合,生成复合数据服务,再通过执行复合数据服务生成数据组合视图,提高了数据组合视图生成的自动化程度,具有较强的实用价值。一种基于数据服务依赖图的高校数据组合视图自动生成方法,包括以下步骤:(1)将高校各部门的数据集划分为原子数据服务;(1.1)建立高校各部门数据集的数据依赖图;根据属性间的函数依赖和连接依赖,建立高校各部门数据集的数据依赖图DDG;定义1数据依赖图,数据依赖图表示为一个扩展的有向图DDG=(U,E),其中U={a1,a2,…,an}是单个属性的集合;E={e1,e2,…,em}是属性间依赖关系的集合,如ei=X→aj表示属性aj完全依赖于属性集X,建立属性间数据依赖图的步骤为:输入:基本表及其属性,函数依赖集合,连接依赖集合输出:数据依赖图步骤a1:确定每个基本表的所有候选键;步骤a2:根据函数依赖,确定每个基本表内属性之间的依赖关系;步骤a3:根据连接依赖,确定所有基本表间的依赖关系;步骤a4:建立属性间的数据依赖图,其节点为属性,有向边为依赖关系;(1.2)基于数据依赖图将高校各部门数据集划分原子数据服务;基于所构建的数据数据依赖图,将高校各部门的数据集划分为原子数据服务ADS,其定义如下:定义2原子数据服务,将可独立访问且语义不可再分的数据服务称为原子数据服务,表示为一个八元组ADS=<Id,Name,Fields,Description,Input,Output,Operations,Publisher>,其中Id是ADS的唯一标识;Name是ADS的名称;Fields是ADS的属性列表;Description是ADS的语义描述;Input是ADS的输入,有一个或多个;Output是ADS的输出,是一个关系;Operations是对ADS可执行的操作,包括查询、修改和删除;Publisher是ADS的发布者;基于步骤(1.1)中生成的数据依赖图将高校各部门的数据集划分为原子数据服务的算法如下:输入:数据依赖图DDG输出:原子数据服务集合步骤b1:从DDG的任意结点开始访问,设初始访问结点为v;步骤b2:访问结点v,做已访问标记,按照广度优先策略访问;步骤b3:查找结点v的任一邻接结点w,判断结点w是否存在,若不存在,转步骤b8;若邻接结点w存在且未访问,访问结点w,做已访问标记;步骤b4:判断结点v的前驱结点是否存在且未访问,若否,则确定v结点为前驱结点,w结点为后继结点,以v结点为输入,以w结点为输出,封装为ADS,执行步骤b5;若存在且未访问过,转步骤b7;步骤b5:查找结点v的下一个邻接结点wn,若存在且未访问,访问该结点,并将该结点标记为已访问,然后以v结点为输入,该邻接结点为输出,封装为ADS,转步骤b5;若不存在,执行步骤b6;步骤b6:确定v结点先访问到的邻接结点w1,后访问到的邻接结点wn,分别以w1结点,wn结点为新的初始访问结点v,并使w1结点的邻接结点先于wn的邻接结点被访问,转步骤b3;步骤:b7:判断v结点的前驱结点是否唯一,若唯一,则访问前驱结点,做已访问标记,并以前驱结点为输入,以v结点为输出,封装为ADS,转步骤b5;若不唯一,则访问所有的前驱结点,做已访问标记,首先把v结点所有的前驱结点分别封装为一个ADS,再把v结点和它所有的前驱结点封装为一个ADS,转步骤b5;步骤b8:输出原子数据服务集合;(2)基于REST技术对原子数据服务进行封装;高校各部门的数据集,包括结构化与非结构化数据,如图片、视频和文件,都当作资源被封装成基于REST风格的服务,且REST风格服务的封装设计需要包含3个层面:①每一种资源通过唯一的URI来访问;②客户端通过HTTP协议的GET,POST,PUT,DELETE四个操作方式对服务器资源进行创建、读取、更新和删除操作;③服务器与客户端之间传递着资源的某种表述形式;将各部门数据集封装成基于REST的原子数据服务,注册并统一管理,用唯一的URI进行统一访问;(3)构建高校各部门的数据服务依赖图;由于原子数据服务是通过封装数据集的属性得到的,因此原有属性间的数据依赖关系直接转换为数据服务之间的依赖关系;根据属性间的依赖得到数据服务之间的以下三种依赖关系:定义3顺序依赖,对于两个原子数据服务ADSi与ADSj,若ADSi的属性值确定,ADSj上的属性值也相应确定,即ADSi→ADSj,则称ADSi与ADSj之间为顺序依赖;定义4合并依赖,对于原子数据服务ADS1、ADS2、…、ADSm以及ADSj,若{ADS1∪ADS2∪ADS3∪…∪ADSm}→ADSj,则称为合并依赖;定义5相互依赖,对于原子数据服务ADSi以及ADS1、ADS2、…、ADSm,若ADSi→{ADS1∧ADS2∧ADS3∧…∧ADSm},则称为并发依赖;根据数据服务的依赖关系,构建出高校各部门的数据服务依赖图,简称服务依赖图DSDG,定义如下:定义6服务依赖图,将原子数据服务间的依赖关系描述为一个扩展的有向图,表示为一个二元组DSDG=(D,E),其中D={ADS1,ADS2,…,ADSn}是原子数据服务集合;E={e1,e2,…em}是原子数据服务间依赖关系集合,如ei=A→ADSj表示原子数据服务ADSj依赖于原子数据服务集合A,(4)根据用户数据需求将原子数据服务组合为复合数据服务;(4.1)用户数据需求描述;数据服务组合过程是在用户数据需求驱动下进行的,用数据需求DR表示用户所需要操作的数据对象,其定义如下:定义7数据需求,用户所需要的属性列表、约束条件以及执行的操作称为数据需求,表示为一个三元组DR=<Requires,Conditions,Operations>,其中Requires表示数据需求的属性列表;Conditions={<Field,Value>|Field表示属性名,Value表示属性值>}表示数据需求的约束条件,如果值为Null,则表示没有约束条件;Operations={get,delete,update}表示需要执行的操作;(4.2)基于数据服务依赖图生成复合数据服务;将用户数据需求作为输入,在数据服务依赖图上自动搜索相关的原子数据服务,并将原子数据服务组合的结果称为复合数据服务CDS,其定义如下:定义8复合数据服务,由若干原子数据服务组成且可被独立访问的数据服务称为复合数据服务,它表示为一个八元组CDS=<Id,Name,Sub-DSDG,Description,Input,Output,Operations,Operations>,其中Id是CDS的唯一标识;Name是CDS的名称;Sub-DSG是DSDG的子图;Description是ADS的语义描述;Input是CDS的输入,有一个或多个;Output是CDS的输出,是一个关系;Operations是对ADS可执行的操作;Publisher是ADS的发布者;基于数据服务依赖图组合生成复合数据服务的算法如下:输入:数据服务依赖图DSDG,数据需求DR输出:复合数据服务CDS步骤c1:从原子数据服务库中检索出包含DR中Requires属性列表和Conditions属性列表的所有的ADS;步骤c2:任选其中一个ADS作为初始访问结点v,做已访问标记,按照深度优先策略访问;步骤c3:查找DSDG中v结点的第一个邻接结点w,判断结点w是否存在,若不存在,转步骤c5;若邻接结点w存在且未访问,访问结点w,做已访问标记;步骤c4:判断v结点,w结点之间是否包含DR属性列表中所有的ADS,若包含,则把v结点和w结点之间单链条所有访问结点封装为一个CDS,结束算法;若不包含,确定w结点为新的初始访问结点v,转步骤c3;步骤c5:确定v结点排在w结点后的下一个邻接结点为初始访问结点v,转步骤c3;该算法可能会产生多个组合方案,将包括ADS数量最少以及包括的属性个数最少的通路作为最终输出,得到最优的数据服务组合结果,该结果即是需要的CDS;此外,该算法假设DSDG的所有节点是联通的,如果不是联通的,则分别对DSDG的所有子图循环使用该算法,并输出每个子图的CDS;(5)执行复合数据服务自动生成数据组合视图;复合数据服务CDS包含了与数据需求相关的原子数据服务及其依赖关系,其执行的结果称为数据组合视图,其定义如下:定义9数据组合视图,执行复合数据服务后生成的结果称为数据组合视图,其形式上是一张二维表格;以查询操作为例,执行CDS生成数据组合视图的步骤如下:步骤d1:分别执行CDS的所有ADS,并根据Conditions条件对ADS的执行结果进行筛选;步骤d2:对具有服务依赖关系的ADS的结果执行连接操作;步骤d3:根据DR中的Requires属性列表对连接的结果执行投影操作;步骤d4:若存在多个CDS,则反复执行步骤d1和步骤d4,得到多个满足DR的数据子集;步骤d5:对得到的多个数据子集执行并操作;执行复合数据服务所涉及的操作包括选择、连接、并和投影。本发明的优点是:本发明将高校各部门的数据集封装为原子数据服务,并基于REST技术将原子数据服务封装注册并统一管理,根据原子数据服务的依赖关系构建数据服务依赖图,在此基础上,根据用户数据需求自动组合原子数据服务生成复合数据服务,再执行复合数据服务生成数据组合视图。本发明为基于数据服务的高校数据集成提供了一种有效的数据组合视图自动生成方法,提高了其自动化程度。附图说明图1高校各部门数据集的数据依赖图图2原子数据服务的依赖关系图图3根据用户数据需求组合得到的复合数据服务具体实施方式为便于说明,以高校学工处对学生进行奖学金评定为例,假设高校存在学生教务系统、学生财务系统和学生科研系统三个业务系统,奖学金评定工作所需的学生信息涉及这三个业务系统;教务系统有学生成绩数据集,它包括的基本表如表1、表2、表3、表4所示;财务系统有学生财务数据集,它包括的基本表如表5、表6、表7;科研系统有学生科研数据集,它包括的基本表如表8、表9、表10所示;其中的属性Sno、属性SF_no和属性SR_no在三个业务系统中语义等价,相互依赖,为数据集成和共享提供了桥梁作用;结合以上高校三个部门的数据集对基于服务依赖图的高校数据组合视图自动生成方法的具体实施方式进行说明,步骤如下:(1)将高校各部门的数据集划分为原子数据服务;(1.1)建立高校各部门数据集的数据依赖图;根据属性间的函数依赖和连接依赖,以及等价的属性集Sno、SF_no和SR_no,建立高校各部门数据集的数据依赖图DDG,如图1所示;(1.2)基于数据依赖图将高校各部门数据集划分原子数据服务;根据图1所示的数据依赖图,对其中属性按照
发明内容中的划分算法得到划分厚的原子数据服务集合,如表11所示;表11原子数据服务集合(2)基于REST技术对原子数据服务进行封装;根据表1的划分结果,基于REST技术对原子数据服务进行封装,以原子数据服务GetStudentSname为例,给出封装的实现代码:(3)构建高校各部门的数据服务依赖图;由于原子数据服务是通过封装数据集的属性得到的,因此原有属性间的数据依赖关系可以直接转换为数据服务之间的依赖关系,由此可以建立原子数据服务的依赖关系图,如图2所示;(4)根据用户数据需求将原子数据服务组合为复合数据服务;(4.1)用户数据需求描述;数据服务组合过程是在用户数据需求驱动下进行的,用数据需求DR表示用户所需要操作的数据对象;假设存在一个数据查询需求:查询学生学号为S01的课程成绩、学费支付情况及科研论文,则该数据需求DR可以表示为:DR=<{{Sname,Cname,Grade},{SF_name,SF_pay},{SR_name,Jname,Pname}},{<Sno,“S01”>},Get>,其中:{Sname,Cname,Grade}表示查询学生成绩所需的属性列表,{SF_name,SF_pay}表示查询学生待缴金额所需的属性列表,{SR_name,Jname,Pname}表示查询学生发表论文名称所需的属性列表,Get表示查询操作;(4.2)基于数据服务依赖图生成复合数据服务;将用户数据需求作为输入,在数据服务依赖图上自动搜索相关的原子数据服务,并将原子数据服务组合为复合数据服务CDS;以上述查询需求DR为例,自动生成满足该需求的复合数据服务如图3所示;(5)执行复合数据服务生成数据组合视图;执行图3所示的CDS中所有ADS,并根据Conditions约束条件对ADS的执行结果进行筛选,对具有服务依赖关系的ADS的结果执行连接操作,根据DR中的Requires属性列表对连接的结果执行投影操作,得到表12的结果。表12跨部门数据组合视图学号姓名课程名课程号成绩代缴金额期刊名称论文名称S01李伟云计算C03750计算机学报三维重建算法研究当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1