一种基于多源域的任务拆分迁移学习预测方法与流程
本发明涉及机器学习领域的迁移学习方向,特别是涉及一种基于多源域的任务拆分迁移学习预测方法。
背景技术:
传统的机器学习预测方法并没有摆脱训练数据和测试数据独立同分布的约束条件,使得机器学习方法必须在样本数据独立同分布的前提假设条件下执行,然而,随着现实应用中大数据的普及,这种前提假设很难适应数据智能时代的发展。针对因训练样本稀缺导致的机器学习方法不适应跨领域学习,以及训练样本的采集和标注耗费代价昂贵的问题,迁移学习作为一种类人学习的技术方法得到广泛关注和研究发展。迁移学习不再限定源域和目标域数据独立同分布,实现跨领域学习,通过知识迁移再利用的方式完成目标任务,是一种非零基础学习的强智能学习方法。
迁移学习在人类学习过程中普遍存在,实现的是一种环境学到的知识、技术或方法对新环境目标任务学习的影响。迁移学习的研究中涉及到领域
技术实现要素:
针对现有技术存在的缺陷,本发明的目的是提出一种基于多源域的任务拆分迁移学习预测方法,解决关联多领域复杂目标任务的预测问题,预防和避免跨领域迁移学习中出现的欠迁移和负迁移的发生,以任务拆分方法降低模型的复杂度,解决过拟合问题,提高模型的泛化能力。
为达到上述目的,本发明采用如下技术方案:
一种基于多源域的任务拆分迁移学习预测方法,具体步骤如下:
步骤1:通过分析目标域的特征项所涉及的领域划分成对应的子域,进而划分出子域对应的子任务,实现对目标任务的拆分,其中以特征量为关联因子来量化相应子任务的重要程度,实现目标任务拆分后的集成;
步骤2:特征映射域关联,利用子任务对应的子域中所需的特征项,与源域建立特征关联,以特征映射的方式建立共享特征空间;
步骤3:基于多源域中子任务模型的构建,结合多任务学习的方法选取基本学习器进行训练,以迭代的方式训练源域数据并更新模型参数,降低子模型误差,及时优化拟合子模型;
步骤4:迁移子任务模型集成目标任务模型,完成目标任务的初始预测模型的构建;
步骤5:跨领域迁移和预测,迁移初始目标任务模型f0(x)预测并优化,以梯度提升的方法快速拟合最终模型,完成最终预测任务。
所述步骤1中的任务拆分和任务重要程度,具体为:
步骤1.1:任务关联拆分,首先,根据目标域中复杂的特征项对目标域进行拆分,目标域划分成多个关联的子域,以此将目标任务拆分成对应子域的多个子任务,任务拆分表示成加和的形式,即
步骤1.2:计算子任务对应目标任务的重要程度,即权重
所述步骤2中的基于特征映射的域关联选取,利用子域中所需的特征项,通过特征映射的方式,建立子域和源域间的共享特征空间,实现子任务的特征关联。
所述步骤3中的多源域子任务模型的构建包括迭代次数的选取和模型参数的更新。
所述步骤4中的目标任务模型的集成,具体为:
步骤4.1:基于子模型关联特征项迁移共享参数模型,多源域中训练出的对应子任务模型表示成
步骤4.2:结合步骤1.2计算出的对应子任务模型权重以及共享参数模型集成构建出初始目标任务模型,表示成为:
所述步骤5中的跨领域目标任务迁移和预测,迁移后的初始任务模型通过梯度提升的方式进行优化,这里采用gradientboosting技术方法,考虑到模型训练过程中的稳定和健壮性,选取更具稳健的胡波损失函数函数,即,
通过梯度下降快速实现损失函数误差最小化,以求得最优预测模型,其负梯度更新表示为,
此过程中选择δ特定值为常数1,即δ=1,模型参数梯度优化使得最终预测模型快速拟合,提高预测泛化能力。
与现有技术相比,本发明具有如下突出的实质性特点和显著的优点:
(1)解决机器学习独立同分布的要求限制,实现跨领域的异构迁移学习。
(2)通过任务拆分降低训练过程的复杂程度,实现复杂问题简单化的学习过程。
(3)多源域技术方法的引入可以避免欠迁移和预防负迁移的发生,解决迁移学习中域和任务相似度关联不充分问题。
(4)参数模型的迁移学习实现了非零基础的学习方式,更加符合类人学习的模式,适应现实应用,其学习效率更快更高,预测精确度也比较高。
(5)可以用于复杂任务多领域的迁移预测,比如预测城市居民幸福度、居民诚信度、股票预测以及跨领域天气等,甚至可以实现文本、图片、声音的知识迁移,进行更具挑战性的预测,比如利用卫星图片进行迁移预测。
附图说明
图1为基于多源域的任务拆分迁移学习预测方法的流程图。
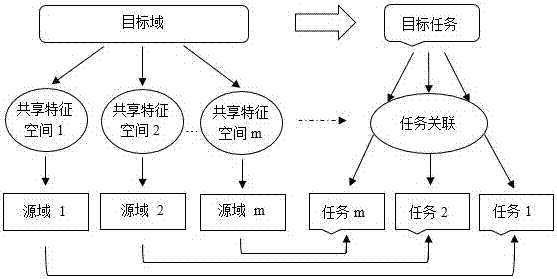
图2为特征映射域关联及任务拆分结构示意图。
具体实施方式
为使本发明的目的、优势和技术方案能更易于被本技术领域人员理解,从而对本发明做出更为清楚详细的界定和说明,下面结合实验数据和附图对本发明的具体实施方案进一步详细阐述。
本发明采用的实验数据集来自londondatastore,其中londondatastore是伦敦政府公开的真实数据集。通过本发明预测伦敦城市居民幸福度,目标域数据集选取londonwardwell-beingscores,简称为well-being,其中目标域涉及到9个关联源域,在此归纳为:health、economic、safety、education、children、families、transport、environment、happiness。为了使得数据集适应本发明的迁移场景,对原始数据的选取进行了基本预处理,源领域和目标领域数据选取及描述如下:
分析复杂的目标任务很难通过极少量的目标域数据训练出高质量的预测模型,相关联的多源域数据充足可以辅助目标任务的学习,以目标任务拆分的方式可以充分利用关联的多源域数据,通过完成子任务来解决目标任务。
结合图1可以看出,本发明提出的基于多源域的任务拆分迁移学习预测方法具体实现步骤包括如下:
步骤1:通过分析目标域的特征项所涉及的领域划分成对应的子域,对应数据集中的9个关联源域,进而划分出子域对应的子任务,实现对目标任务的拆分,其中以特征量为关联因子来量化相应子任务的重要程度,实现目标任务拆分后的集成。
步骤1.1:结合附图2所示,根据目标域中复杂的特征项对目标域进行拆分,目标域划分成多个关联的子域,以此将目标任务拆分成对应子域的多个子任务,其中,目标任务可以表示成加和的形式,即
步骤1.2:根据特征项对目标域的拆分,以特征项的数量来衡量相应子任务所占目标任务的比重,以此计算子任务相应目标任务的重要程度,即权重
步骤2:结合附图2所述的基于特征映射的域关联选择,利用子任务对应的子域中所需的特征项,与源域建立特征关联,以特征映射的方式建立共享特征空间。
步骤3:多源域子任务模型的构建,结合多任务学习的方法选取基本学习器进行训练,以迭代的方式训练源域数据并更新模型参数,降低子模型误差,及时优化拟合子模型。
步骤4:迁移子任务模型集成目标任务模型,完成目标任务的初始预测模型的构建;
步骤4.1:多源域中训练出的对应子任务模型可以表示成
步骤4.2:结合步骤1.2计算出的对应子任务模型权重以及共享参数模型集成构建出初始目标任务模型,可以表示成为
步骤5:跨领域目标任务迁移和预测,迁移初始目标任务模型f0(x)预测并优化,采用gradientboosting技术方法实现快速拟合,从参数梯度降低的角度最小化损失函数值,提高目标任务函数模型的精确度,构建出最优预测模型,完成目标任务,从整体训练过程的稳健性考虑,选取胡波损失函数,即,
通过梯度下降快速实现损失函数误差最小化,求得最优模型,其负梯度更新表示为,
预测幸福指数在1-10区间,此过程中选择δ特定值为常数1,即δ=1。
- 还没有人留言评论。精彩留言会获得点赞!