基于峰值密度聚类的主动学习方法与流程
本发明涉及主动学习领域,尤其是基于峰值密度聚类的主动学习方法。
背景技术:
主动学习在某些情况下,没有类标签的数据相当丰富而有类标签的数据相当稀少,并且人工对数据进行标记的成本又相当高昂。在这种情况下,我们可以让学习算法主动地提出要对哪些数据进行标注,之后我们要将这些数据送到专家那里让他们进行标注,再将这些数据加入到训练样本集中对算法进行训练,这一过程叫做主动学习。
主动学习这个过程最重要的是两点:一、由学习算法主动提出对未标记的样本的标记需求;二、选择策略。
聚类算法:类,就是指相似元素的集合。聚类是把一些对象按照具体特征组织到若干个类别里。
如图1展示了一个一般的主动学习实现的框架,主要可以分为以下两个部分:
第一部分是初始化阶段,通常是随机从样本中选择一部分实例构成初始训练集。然后送入分类器,对样本进行分类。
第二部分是循环查询阶段,选择器根据一定的查询策略从未标记的样本中选择最有信息的样本进行标记;被选择的实例会加入训练集中,重新训练分类器,过程一直迭代,直到终止条件满足。
现有技术主要缺点是初始阶段,需要从大量样本中随机进行选择,构建初始训练集,如果随机选择的初始样本不好,很有可能导致后续算法无法达到预定的效果。需要构建一个复杂的分类器,有些方法是每次选择一个样本,重新加入分类器,对样本进行分类,这样可能极大的降低算法的效率。
因此,对于上述问题有必要提出基于峰值密度聚类的主动学习方法。
技术实现要素:
针对上述现有技术中存在的不足,本发明的目的在于提供一种大大减少人工标记实例的个数,大大减少成本,提高经济效益的基于峰值密度聚类的主动学习方法。
首先提出基于固定标记个数的主动学习问题:
输入:决策系统s=(u,c,d),用户指定的标记个数。
输出:该决策系统中所有实例的标签。
优化目标:预测准确度最高。
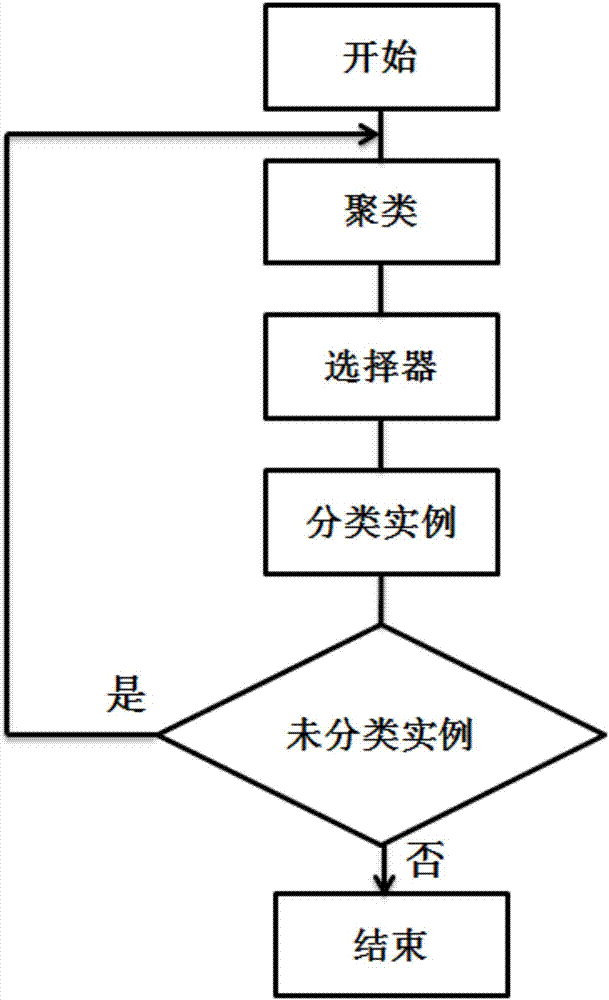
基于峰值密度聚类的主动学习方法,其方法步骤为:(1)开始时,将所有未能标记数据进行聚类;(2)根据聚类的信息,构建一个选择器,从大量未标记样本中,选择最有价值的样本进行标记;(3)根据已经标记的样本和已有的聚类结构,对未能标记的样本进行预测和分类;(4)判断是否未分类实例,若是,则重新进行聚类,若否,则结束。
优选地,所述聚类可以采用kmeans或densitypeak主流聚类方法进行。
优选地,所述聚类首先进行定义本地密度α,其中:
αi=∑jχ(dij-dc)
然后计算最小距离β,β是点i与如何密度比它大的点之间的最小距离,其中:
最后构建聚类关系树结构ms=[m(x1),l,m(xn)],该树仅构建一次,存储,用于后续的聚类分析。
优选地,所述聚类首先设置选择参数γ,其中:
γ=α×β
然后排序,根据聚类后形成的簇,分簇对γ进行排序,形成排序表。
优选地,所述分类实施分为两种情况分类,其中一种情况实施步骤为:(1)标记的实例的数量未达到指定的最大数量;(2)根据聚类后形成的簇,分簇对γ进行排序的选择器选择最有价值的实例;(3)预测实例,并继续重新聚类未标记的实例;(4)将检查每个聚类中的标记数据,如果聚类中的所有标签都是相同的,确定该簇是纯的;(5)对于一个纯粹的聚类,直接预测所有未标记数据与任何其他数据相同,如果聚类是不纯净的,将执行重新聚类,迭代地,直到标记的数据达到设定的最大值。
优选地,所述分类实施的另一种情况实施方法:如果标记的数据的数量已达到最大极限,但仍然有不纯净的簇和未标记的数据,将使用投票策略来确定未标记实例的标签。
由于采用上述技术方案,本发明将alec方法与最主流的分类算法knn,c4.5决策树算法,普通贝叶斯方法naivebayes方法在以下12数据集上进行了仔细的比较,可以以很少的标记数量获得很高的准确度,可以大大减少人工标记实例的个数,从而大大减少成本,提高经济效益,同时具有很强的实用性。
附图说明
图1是现有主动学习方法示意图;
图2是本发明的方法示意图;
图3是本发明的具有20个实例的聚类树结构构建示意图;
图4是本发明实施例的聚类后排序表;
图5是本发明dla数据集对比实验图;
图6是本发明dccc数据集对比实验图;
图7是本发明poker数据集对比实验图;
图8是本发明penbased数据集对比实验图;
图9是本发明segment数据集对比实验图;
图10是本发明glass数据集对比实验图;
图11是本发明seeds数据集对比实验图;
图12是本发明iris数据集对比实验图;
图13是本发明aggregation数据集对比实验图;
图14是本发明r15数据集对比实验图;
图15是本发明flame数据集对比实验图;
图16是本发明spiral数据集对比实验图。
具体实施方式
以下结合附图对本发明的实施例进行详细说明,但是本发明可以由权利要求限定和覆盖的多种不同方式实施。
如图2并结合图3至图16所示,基于峰值密度聚类的主动学习方法,其方法步骤为:(1)开始时,将所有未能标记数据进行聚类;(2)根据聚类的信息,构建一个选择器,从大量未标记样本中,选择最有价值的样本进行标记;(3)根据已经标记的样本和已有的聚类结构,对未能标记的样本进行预测和分类;(4)判断是否未分类实例,若是,则重新进行聚类,若否,则结束。
进一步的,所述聚类可以采用kmeans或densitypeak主流聚类方法进行。
进一步的,所述聚类首先进行定义本地密度α,其中:
αi=∑jχ(dij-dc)
然后计算最小距离β,β是点i与如何密度比它大的点之间的最小距离,其中:
最后构建聚类关系树结构ms=[m(x1),l,m(xn)],该树仅构建一次,存储,用于后续的聚类分析。
进一步的,所述聚类首先设置选择参数γ,其中:
γ=α×β
然后排序,根据聚类后形成的簇,分簇对γ进行排序,形成排序表,如图4所示,红色部分为每一簇所选择的实例。
进一步的,所述分类实施分为两种情况分类,其中一种情况实施步骤为:(1)标记的实例的数量未达到指定的最大数量;(2)根据聚类后形成的簇,分簇对γ进行排序的选择器选择最有价值的实例;(3)预测实例,并继续重新聚类未标记的实例;(4)将检查每个聚类中的标记数据,如果聚类中的所有标签都是相同的,确定该簇是纯的;(5)对于一个纯粹的聚类,直接预测所有未标记数据与任何其他数据相同,如果聚类是不纯净的,将执行重新聚类,迭代地,直到标记的数据达到设定的最大值。
所述分类实施的另一种情况实施方法:如果标记的数据的数量已达到最大极限,但仍然有不纯净的簇和未标记的数据,将使用投票策略来确定未标记实例的标签。
图3为聚类树,从图可以看出,第一次,整个树被聚成块1和块2,图4为块信息表,表示每块根据优先级的大小降序排列,依次选择最有价值的实例进行标注;
图5至图16是在12个数据集上的对比实验图,横轴为用户指定的标记个数,纵轴为输出的分类精度。
本发明将alec方法与最主流的分类算法knn,c4.5决策树算法,普通贝叶斯方法naivebayes方法在图5至图16中12个数据集上进行了仔细的比较,可以以很少的标记数量获得很高的准确度,可以大大减少人工标记实例的个数,从而大大减少成本,提高经济效益,同时具有很强的实用性。
以上所述仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!