一种基于信息密度提取网页正文的方法与流程
本发明涉及计算机网络技术领域,具体而言,本发明涉及一种基于信息密度提取网页正文的方法。
背景技术:
随着网络技术的不断发展,互联网已成为信息的主要来源,但是,目前互联网中的重复内容、广告内容及无意义内容等无效信息越来越多,而有效信息在网页中所占比重越来越少,使得人们通过互联网如搜索引擎获取其所需的有效信息的效率大幅降低
网页正文提取是实现搜索引擎、舆情监控等系统的技术基础之一,通过网页正文提取,可以将网页中广告、推荐等等与主题无关的信息滤除,利用正文提取的功能,可以提高搜索引擎的搜索精确度,减小舆情监控系统的错报、误报率。
现有的正文提取装置主要采用模式匹配的方法,通过预设网页正文的提取规则,通过模式匹配在网页中寻找正文所在的位置。这种方式具有很大的局限性,首先是需要人工的介入,系统无法自动获取网页正文提取规则,需要事先由操作者对网页进行分析总结后将提取规则输入系统;其次是适应性差,当网页的排版发生改变后,系统即部分或完全失效,无法自适应的对新的网页结构进行提取。
技术实现要素:
本发明主要解决的技术问题是提供一种基于信息密度提取网页正文的方法,利用该方法能够过滤网页中与主题无关的信息,并将网页中真实主题的正文提取。该方法基于对网页html标签及内容的统计分析提出了一种网页信息密度的计算方法,利用网页信息密度的分布规律区分网页中的有效信息和无关的信息。该方法有很强的通用性,无需预先设定网页的提取规则,不需要人为设置提取的阈值,对各类网页正文提取准确高效。
为解决上述技术问题,本发明采用的技术方案是:
1.通过网络或其他途径获取网页html文件;
将其中与网页展示内容不相关的标签删除,例如<script><code>等标签;
统计出网页html标签的数量以及每一个html标签包含子标签的数量,网页中每一个html标签包含字符的数量,网页中每一个html标签包含标点符号的数量,网页中每一个html标签包含链接的数量,网页中每一个html标签包含图片的数量;
计算网页中的每一个html标签的信息密度;
筛选出网页中信息密度值最大的标签作为正文输出,也即选择具有最大信息密度的标签,将其内容输出,该输出即为采用本方法提取出的网页正文。
2.所述的将其中与网页展示内容不相关的标签删除,其中,与网页展示内容不相关的标签,主要包括以下4种标签:
①.代表注释的标签,如<!-->;
②.与网页前端执行脚本相关的标签,如<script>,<var>,<link>,<code>;
③.与css格式相关的标签,如<style>;
④.对网页展示的内容和格式完全无影响的标签,如<!doctype>。
其中,至少需要删除4种标签中的一种,特别是1,2,3中的一种,全部删除4种与网页展示内容不相关的标签,得到的速度和效果最佳。
3.所述统计出网页html标签的数量以及每一个html标签包含子标签的数量,网页中每一个html标签包含字符的数量,网页中每一个html标签包含标点符号的数量,网页中每一个html标签包含链接的数量,网页中每一个html标签包含图片的数量。计算网页信息密度所需的统计项包括:
①网页html标签的数量以及每一个html标签包含子标签的数量;
②网页中每一个html标签包含字符的数量;
③网页中每一个html标签包含标点符号的数量;
④网页中每一个html标签包含链接的数量;
⑤网页中每一个html标签包含图片的数量。
具体为:
由于网页标题及正文必定存在于body标签中,查找到<body>标签,将其作为根标签输入递归调用模块;
递归统计根标签及其所有下级子标签的子标签数量、字符数量、标点符号数量、链接数量、图片数量。
具体递归统计过程,在具体实施方式和附图中进行了详细的说明。
4.所述的计算网页中的每一个html标签的信息密度,包括:
计算出网页标签密度,字符密度,标点密度,链接密度,图片密度五个计算分量;
将五个计算分量标签密度,字符密度,标点密度,链接密度,图片密度的乘积作为每一个html标签的信息密度。
5.所述的计算出标签密度,字符密度,标点密度,链接密度,图片密度五个计算分量,具体计算方法为:
标签密度,计算方法为本标签内部包含所有子标签的数量除以网页标签的总数;
字符密度,计算方法为本标签内部包含所有字符的数量除以网页字符的总数;
标点密度,计算方法为本标签内部包含所有标点的数量除以网页标点的总数;
链接密度,计算方法为本标签以外包含的所有链接的数量除以网页链接的总数;
图片密度,计算方法为本标签以外包含的所有图片的数量除以网页图片的总数。
6.所述计算网页信息密度的方法,也就是本发明所提出的一种网页信息密度的计算方法,具体为:
1)对网页中的所有标签计算各自的信息密度,每一个html标签的信息密度为五个计算分量的乘积,该五个计算分量分别为:
①标签密度,计算方法为本标签内部包含所有子标签的数量除以网页标签的总数
dtaga=num(taga)/num(root)
上式中,dtaga为标签a的标签密度,num(taga)为标签a内包含所有标签及其子标签的数量,num(root)为根标签包含的所有标签数量,即该网页的标签总数。
②字符密度,计算方法为本标签内部包含所有字符的数量除以网页字符的总数
dworda=word(a)/word(root)
上式中,dworda为标签a的字符密度,对于英文或其他拉丁文字来说,每一个单词称为一个字符,对于汉字来说,每一个字称为一个字符。word(a)为标签a及其所有子标签中包含的字符数量,word(root)为根标签包含的所有字符数量,即该网页的字符总数。
③标点密度,计算方法为本标签内部包含所有标点的数量除以网页标点的总数
dinta=interpunction(a)/interpunction(root)
上式中,dinta为标签a的标点密度。,interpunction(a)为标签a及其所有子标签中包含的标点数量,interpunction(root)为根标签包含的所有标点数量,即该网页的标点总数。
④链接密度,计算方法为本标签以外包含的所有链接的数量除以网页链接的总数
上式中,dlinka为标签a的标点密度,link(a)为标签a及其所有子标签中包含的链接数量,link(root)为根标签包含的所有链接数量,即该网页的链接总数。
⑤图片密度,计算方法为本标签以外包含的所有图片的数量除以网页图片的总数
上式中,dimagea为标签a的图片密度,image(a)为标签a及其所有子标签中包含的图片数量,image(root)为根标签包含的所有图片数量,即该网页的图片总数。
2)每一个标签的信息密度为标签密度、字符密度、标点密度、链接密度、图片密度五个分量的乘积。即如下公式:
da=dtaga*dworda*dinta*dlinka*dimagea
附图说明
图1为本发明中的一种基于信息密度提取网页正文的方法的一个实施例的流程图。
图2为一个三级标签结构的网页递归过程示意图。
具体实施方式
图1为本发明中的一种基于信息密度提取网页正文的方法的一个实施例的流程图,结合附图对本发明的较佳实施例进行详细阐述,以使本发明的优点和特征能更易于被本领域技术人员理解,从而对本发明采用的技术方案和保护范围做出更为清楚明确的理解。
获取网页html文件后,以body标签为根标签,以递归的方式遍历所有下级标签页,并统计每一个标签内包含的下级标签、字符、标点符号、链接和图片的数量。
步骤s1:通过网络或其他途径获取html文件;
步骤s2:将其中与网页html内容展示不相关的标签删除,主要包括以下4种标签:
1.代表注释的标签,如<!-->;
2.与网页前端执行脚本相关的标签,如<script>,<var>,<link>,<code>;
3.与css格式相关的标签,如<style>;
4.对网页展示的内容和格式完全无影响的标签,如<!doctype>。
步骤s3:查找到body标签,由于标题及正文必定存在于body标签中,将其作为根标签输入递归调用模块。
步骤s4:执行递归调用,其运行目的为统计标签及其所有下级子标签的:子标签数量、字符数量、标点符号数量、链接数量、图片数量。
步骤s5:基于信息密度计算公式计算所有标签的信息密度,其具体方法如前述“5.所述计算网页信息密度的方法,也就是本发明所提出的一种网页信息密度的计算方法”所具体描述的计算方法和计算公式。
步骤s6:选择具有最大信息密度的标签,将其内容输出,该输出即为采用本方法提取出的网页正文。
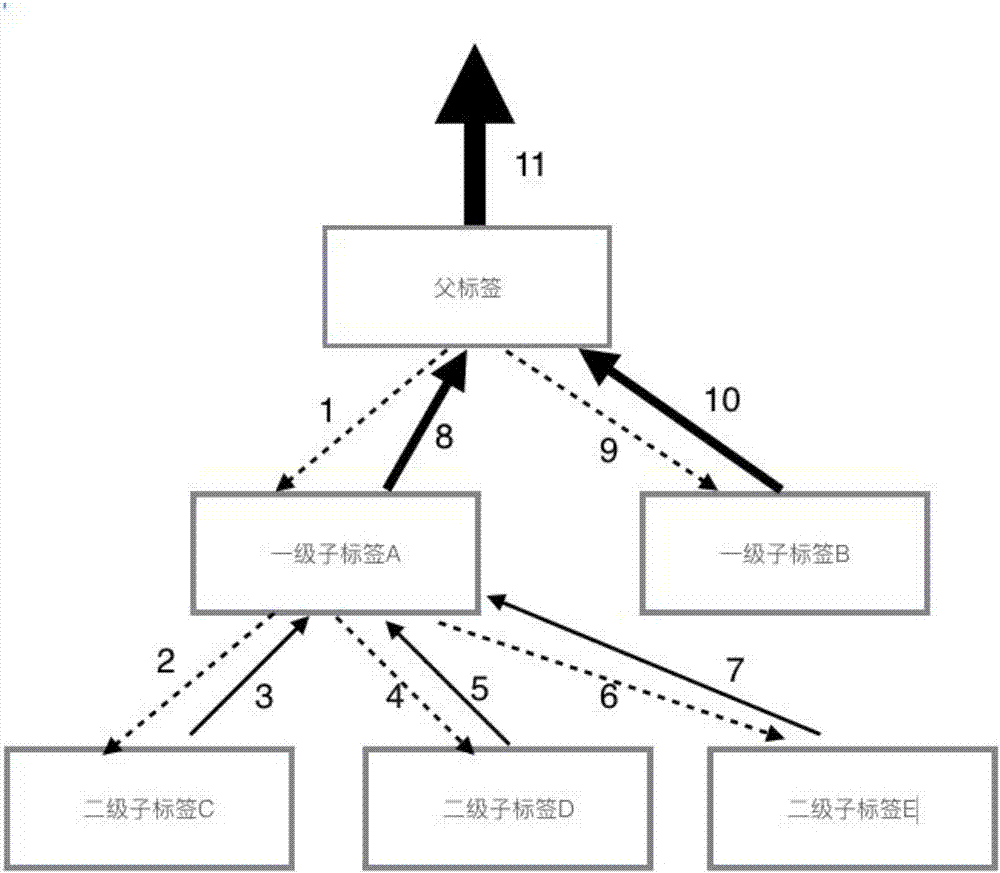
下面以图2的一个三级标签结构的网页递归为例,具体说明步骤s4的递归统计过程:
1.父标签发现其自身存在子标签a,将统计命令发送给子标签a;
2.一级子标签a收到统计命令,发现其自身存在子标签c,d,e,并将统计命令发给子标签c;
3.二级子标签c收到统计命令,发现其自身不存在子标签,则在其内部进行字符,标点,链接和图片数量的计数统计,并将结果返回一级子标签a;
4.一级子标签a将统计命令发给子标签d;
5.二级子标签d收到统计命令,发现其自身不存在子标签,则在其内部进行字符,标点,链接和图片数量的计数统计,并将结果返回一级子标签a;
6.一级子标签a将统计命令发给子标签e;
7.二级子标签e收到统计命令,发现其自身不存在子标签,则在其内部进行字符,标点,链接和图片数量的计数统计,并将结果返回一级子标签a;
8.一级子标签将3,5,7步骤中收到的返回结果与自身内部的统计结果相加,连同子标签的数量(c,d,e共3个子标签)返回父标签;
9.父标签将统计命令发给子标签b;
10.一级子标签b收到统计命令,发现其自身不存在子标签,则在其内部进行字符,标点,链接和图片数量的计数统计,并将结果返回父标签;
11.父标签将8,10步骤中收到的返回结果相加,连同自身内部的统计结果,输出。
在上述递归计算过程中,所有标签都计算出了自身包含的子标签数量、字符数量、标点符号数量、链接数量、图片数量
步骤5基于步骤4统计出的信息,结合上述网页信息密度计算公式计算所有标签的信息密度
步骤6选择具有最大信息密度的标签,将其内容输出,该输出即为采用本方法提取出的网页正文。
- 还没有人留言评论。精彩留言会获得点赞!