基于用户偏好的协同过滤推荐方法与流程
本发明涉及互联网个性化推荐领域,尤其涉及一种基于用户偏好的协同过滤推荐方法。
背景技术:
internet技术的快速发展增加了web信息的容量,如何为用户提供有价值的信息成为电子商务必须面对的问题。推荐系统通过学习用户的行为,了解和掌握用户的偏好,从而可以更有针对性地向用户推荐他们可能感兴趣的内容。协同过滤是推荐系统中的一种流行技术,它能有效地解决信息过载问题,帮助用户迅速找到有价值的信息,过滤无用信息。其基本思想是:依据用户的购买记录、评分记录、浏览记录以及标注等,推荐给用户所需要的信息或者预测用户对项目的兴趣偏好,以实现推荐结果的个性化。
基于用户的协同过滤推荐算法利用用户间的相似爱好推荐用户目标,其结果可解释性强。但数据的极端稀疏影响用户近邻的准确选择。针对此问题,文献:b.jeong,j.lee,h.cho.usercredit-basedcollaborativefiltering[j].expertsystemswithapplications,2009,36(6):7309-7312(b.jeong,j.lee,h.cho,基于用户信用的协同过滤[j],专家系统及其应用,2009,36(6):7309-7312)利用用户-项目评分矩阵设计了利用用户的信用等级代替用户之间相似度的计算,利用用户间不同的级别能更好地寻找目标用户的近邻;文献:f.j.huete,j.m.fernandez-luna,m.camposluis,etal.usingpasting-predictionaccuracyinrecommendersystems[j].informationsciences,2012,199(15)78-92(在推荐系统中利用粘贴预测精度[j],信息科学,2012,199(15)7892)。依据用户过去评分的相关性,有效地利用用户的评分习惯,提高了推荐质量;文献:林耀进,胡学钢,李慧宗.基于用户群体影响的协同过滤推荐算法[j].情报学报,2013,32(3):299-3055利用用户个体之间的相似性和用户所处群体之间的相似性,准确寻找目标用户的近邻;文献:李鹏,于晓洋,孙渤禹.基于用户群组行为分析的视频推荐方法研究[j].电子与信息学报,2014,36(6):1485-1491通过rfm模型分析用户行划分群组,然后基于相似向量比对用户的相似度,提高推荐效率和准确性;文献:冷亚军,梁昌勇,丁勇,陆青,等.协同过滤中一种有效的最近邻选择方法[j].模式识别与人工智能,2013,26(10):68-974提出一种有效的针对稀疏评分的最近邻选择方法:两阶段最近邻选择算法。
在基于用户的协同过滤推荐模型中,评分矩阵r(m,n)包含m个用户的集合user={u1,u2,...,um}和n个项目的集合item={i1,i2,...,in},如表1所示。其中,矩阵的行表示用户,列表示项目,ri,j表示用户ui(1≤i≤m)对项目ij(1≤j≤n)的评分。
表1用户-项目评分矩阵
为获取目标用户的相似邻居,需计算用户间的相似度,传统的相似性度量方法主要有以下二种:
(1)相关相似性(pearsoncorrelationcoefficient,pcc),通过pearson相关系数度量用户之间的相似度,即
(2)余弦相似性(cosine,cos),通过向量间的余弦夹角度量用户之间的相似度,即
式(1)和(2)中,ua和ub表示用户集合中任意二位用户,sim(ua,ub)表示用户之间的相似度。其中,c(a,b)表示用户ua和ub共同评分项的集合,ra,k表示用户ua对项目ik的评分,
通过式(1)或(2),可得到用户之间的相似度矩阵。进一步利用用户之间相似度大小,为目标用户寻找k个最相似的邻居用户。最后,通过式(3)对目标用户的未评分项进行预测。
式(3)中,pt,i为目标用户ut对未评分项ii的评分,k为目标用户ut近邻的个数,rx,i为用户ux对项目ii的评分,
传统的相似性度量算法(pcc和cos)过分依赖用户间的共同评分项,未从全局考虑用户的评分倾向性。为更好地度量用户之间的相似性,现有一种引入nhsm相似性度量方法,该方法主要体现三方面信息:用户之间评分差异(pss),用户之间共同评分项(jaccard')及所有用户潜在评分倾向性(urp)。新启发式相似性度量方法定义如式(4)所示。
sim(ua,ub)nhsm=sim(ua,ub)pss×sim(ua,ub)jaccard′×sim(ua,ub)urp(4)
式中,ua和ub表示用户集合中任意二位用户,sim(ua,ub)pss定义如式(5)所示:
式(5)中,
proximity(ra,k,rb,k)=1-1/(1+exp(-|ra,k-rb,k|))(6)
significance(ra.k,rb,k)=1/(1+exp(-|ra,k-rmed|·|rb,k-rmed|))(7)
singularity(ra,k,rb,k)=1-1/(1+exp(-|(ra,k-rb,k)/2-μk|)(8)
式(6-8)中,μk为项目k的平均评分,ra,k为用户ua对项目ik的评分,rmed为评分集合的中位数。
其次,利用改进的jaccard系数来反映共同评分项带来的影响,定义如(9)所示。
式中,|ia|为用户ua已评分项的个数,|ia∩ib|为用户ua和ub的共同评分项个数。
最后,用户潜在的评分倾向性用式(10)度量。
式中,μa和μb分别为用户ua和ub的平均评分;
基于用户的协同过滤推荐算法是利用用户之间的相互作用,通过寻找最相似的k邻居来辅助目标用户预测未评分项。但用户在评分时存在偏好行为,存在用户打分偏低或偏高的情况,相似兴趣的用户也存在评分不同,会导致计算用户之间的相似性出现偏差,这影响推荐的质量。
技术实现要素:
本发明所要解决的技术问题在于提供了一种进一步提升推荐质量的基于用户偏好的协同过滤推荐方法。
本发明通过以下技术手段解决上述技术问题的:一种基于用户偏好的协同过滤推荐方法,包括下述步骤:
步骤1:输入用户-项目评分矩阵,取所有用户评分的平均评分,设定为阈值p,依据该阈值p将用户分为偏好高评用户和偏好低评用户;
步骤2:利用nhsm相似性度量方法计算任意二位用户之间的相似度,获得用户间的相似矩阵sim;
步骤3:设目标用户ua,其同偏好用户群体为s,不同偏好群体为d,计算目标用户ua与其他用户ub的相似度:
如maxsim(ua,ub)s>maxsim(ua,ub)d则:
如maxsim(ua,ub)s≤maxsim(ua,ub)d则:
式(12)和(13)中,sim(ua,ub)为用户ua和ub的相似度,其中,ua表示目标用户,ub表示其他用户,maxsim(ua,ub)s为ua与s中相似度最大的值,maxsim(ua,ub)d为ua与d中相似度最大的值,
步骤4:利用式(14)得到用户间新的相似矩阵newsim:
步骤5:根据式(15)预测目标用户ut在项目ii上的评分pt,i:
式(15)中,pt,i为目标用户ut对项目ii的评分。其中,υ表示目标用户的近邻集合,xk表示目标用户ut的第k个近邻,近邻个数k由大间隔自动确定,
优选的,所述步骤1中,阈值p根据评分矩阵确定,如式(11)所示:
式中,
优选的,所述步骤2中的相似度计算方法如下:
sim(ua,ub)nhsm=sim(ua,ub)pss×sim(ua,ub)jaccard′×sim(ua,ub)urp(4)
式中,ua和ub表示用户集合中任意二位用户,sim(ua,ub)pss定义如式(5)所示:
式(5)中,
proximity(ra,k,rb,k)=1-1/(1+exp(-|ra,k-rb,k|))(6)
significance(ra.k,rb,k)=1/(1+exp(-|ra,k-rmed|·|rb,k-rmed|))(7)
singularity(ra,k,rb,k)=1-1/(1+exp(-|(ra,k-rb,k)/2-μk|)(8)
式(6-8)中,μk为项目k的平均评分,ra,k为用户ua对项目ik的评分,rmed为评分集合的中位数。
其次,利用改进的jaccard系数来反映共同评分项带来的影响,定义如(9)所示。
式中,|ia|为用户ua已评分项的个数,|ia∩ib|为用户ua和ub的共同评分项个数。
最后,用户潜在的评分倾向性用式(10)度量。
式中,μa和μb分别为用户ua和ub的平均评分;
本发明相比现有技术具有以下优点:构建一种基于用户偏好的协同过滤推荐模型,减少了预测结果的偶然性。实验结果表明,与其他推荐方法相比,本发明的推荐方法能够更加精确地度量用户间的相似度,提高推荐质量。
附图说明
图1是本发明基于用户偏好的协同过滤推荐方法的流程图。
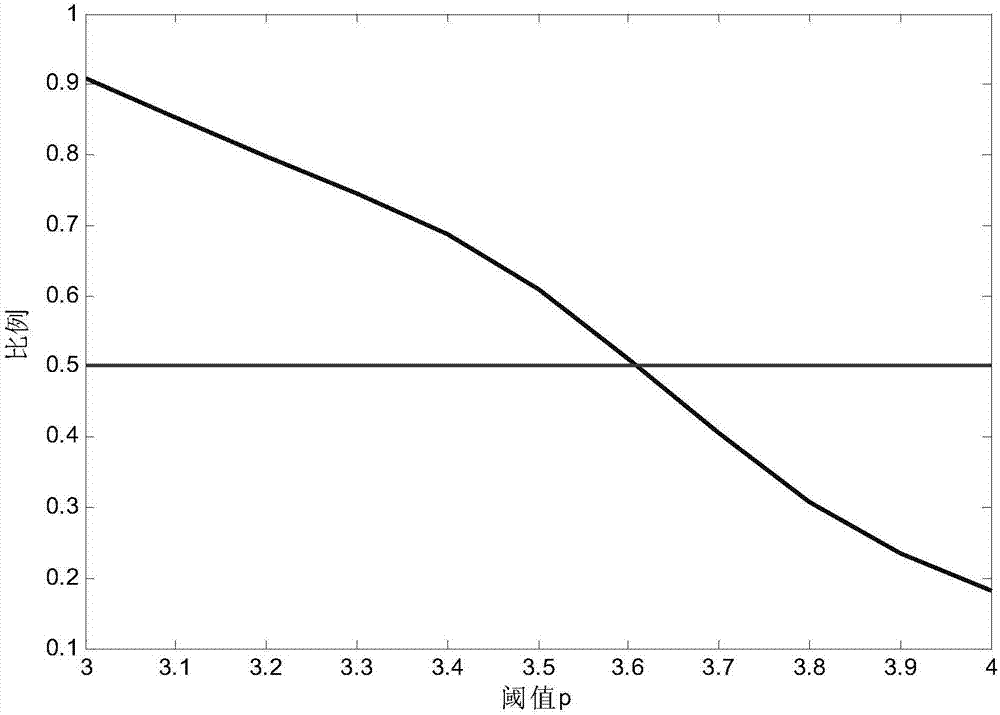
图2是本发明实施例中movielens数据集中用户评分分布情况。
图3为在movielens数据集上,随近邻数k的变化,mae的变化情况。
图4为在movielens数据集上,随近邻数k的变化,coverage的变化情况。
图5为在jester-data-2数据集,随近邻数k的变化,mae的变化情况。
图6为在jester-data-2数据集,随近邻数k的变化,coverage的变化情况。
具体实施方式
下面对本发明的实施例作详细说明,本实施例在以本发明技术方案为前提下进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
参阅图1所示,本发明基于用户偏好的协同过滤推荐方法包括下述步骤:
步骤1:输入用户-项目评分矩阵,取所有用户评分的平均评分,设定为阈值p,依据该阈值p将用户分为偏好高评用户和偏好低评用户;
步骤2:利用nhsm相似性度量方法计算任意二位用户之间的相似度,获得用户间的相似矩阵sim;
步骤3:设目标用户ua,其同偏好(偏好高评或低评)用户群体为s,不同偏好(偏好低评或高评)群体为d,计算目标用户ua与其他用户ub的相似度:
如maxsim(ua,ub)s>maxsim(ua,ub)d则:
如maxsim(ua,ub)s≤maxsim(ua,ub)d则:
式(12)和(13)中,sim(ua,ub)为用户ua和ub的相似度,其中,ua表示目标用户,ub表示其他用户,maxsim(ua,ub)s为ua与s中相似度最大的值,maxsim(ua,ub)d为ua与d中相似度最大的值,
基于大间隔寻找近邻的主要思想是:通过设计一种新的相似性度量公式,使用户空间中与目标用户相同偏好的近邻属于同一类别,不同偏好的用户与目标用户尽量区分开。这体现了用户潜在的偏好行为,缩小有相同偏好用户之间的距离,增大不同偏好用户之间的距离。相比其他许多改进的协同过滤推荐算法,该算法也能自动确定近邻个数,提高推荐效率;
步骤4:利用式(14)得到用户间新的相似矩阵newsim:
步骤5:根据式(15)预测目标用户ut在项目ii上的评分pt,i:
式(15)中,pt,i为目标用户ut对项目ii的评分。其中,υ表示目标用户的近邻集合,xk表示目标用户ut的第k个近邻,近邻个数k由大间隔自动确定,
所述步骤1中,设定不同偏好用户群体用户数量平衡,根据用户对项目的评分值,设定阈值p将用户划分为高评用户(偏好打高分的用户)和低评用户(偏好打低分的用户)。其中,阈值p根据评分矩阵确定,如式(11)所示:
式中,
表格2为给定用户对项目的实际评分矩阵。其中,矩阵的行表示用户,列表示项目。评分为5分制。
表2用户-项目实际评分矩阵
根据式(11),可计算出阈值p=3.06。将每个用户的平均评分和阈值p比较,用户u1、u3和u5被划为高评用户,其它3用户归类为低评用户。
本文以movielens数据集(来自http://movielens.umn.edu)为例,对阈值p在[34]之间的用户数进行统计,如图2所示。图2为用户评分分布情况。其中,横坐标表示阈值p,纵坐标表示平均评分大于阈值p的用户占所有用户的比例。如p取值3,平均评分大于阈值p的用户占所有用户百分比高于90%。
所述步骤2中的相似度计算方法如下:
sim(ua,ub)nhsm=sim(ua,ub)pss×sim(ua,ub)jaccard′×sim(ua,ub)urp(4)
式中,ua和ub表示用户集合中任意二位用户,sim(ua,ub)pss定义如式(5)所示:
式(5)中,
proximity(ra,k,rb,k)=1-1/(1+exp(-|ra,k-rb,k|))(6)
significance(ra.k,rb,k)=1/(1+exp(-|ra,k-rmed|·|rb,k-rmed|))(7)
singularity(ra,k,rb,k)=1-1/(1+exp(-|(ra,k-rb,k)/2-μk|)(8)
式(6-8)中,μk为项目k的平均评分,ra,k为用户ua对项目ik的评分,rmed为评分集合的中位数。
其次,利用改进的jaccard系数来反映共同评分项带来的影响,定义如(9)所示。
式中,|ia|为用户ua已评分项的个数,|ia∩ib|为用户ua和ub的共同评分项个数。
最后,用户潜在的评分倾向性用式(10)度量。
式中,μa和μb分别为用户ua和ub的平均评分;
实验结果及分析
1、数据集
本文采用公开的movielens和jester-data-2数据集(http://www.ieor.berkeley.edu/~goldberg/jester-data)验证本文所提算法。movielens数据集包含943个用户在1682个电影上的评分,其中每个用户至少对20部电影有评分记录;jester-data-2数据集包含1582个用户在100个笑话上的评分,其中每个用户至少对1个笑话有评分记录,数据集的详细信息如表3所示。为保证实验结果的无偏性,数据集分成训练集和测试集,训练集占整个数据集的80%,其余20%数据作为测试集。整个过程采用五折交叉验证方法,测试集之间是互斥的,并且有效地覆盖了整个数据集。
表3数据描述
2、度量指标
本文评价推荐质量的度量指标包括mae(meanabsoluteerror)和覆盖率(coverage)。mae是一种常见的度量指标,通过计算预测的用户评分和实际用户评分之间的偏差来度量预测的准确性,mae值越小,推荐质量越好。覆盖率(coverage)用来衡量一个算法能够预测的项目占所有项目的百分比,coverage值越大,推荐质量越好。
设有n个项目,用户的实际评分集合为r={r1,r2,...,rn},预测的用户评分集合为p=(p1,p2,...,pn),s表示p集合中有评分的个数,则度量指标mae和覆盖率(coverage)分别表示为:
3、实验结果分析
本文所提算法与基于pearson相关系数的协同过滤算法(pcc-cf)、基于cosine相似性的协同过滤算法(cos-cf)和基于nhsm相似性的协同过滤推荐算法(nhsm-cf)在算法性能上进行比较。
图3和图4分别为在movielens数据集上,随近邻数k的变化,mae和coverage的变化情况,其中近邻数k在10~100之间变动,从图中可看出基于nhsm相似性的协同过滤推荐算法(nhsm-cf)的mae值比cos-cf和pcc-cf都要小,coverage值相对要大;在jester-data-2数据集上mae和coverage的变化情况如图5和图6所示,nhsm-cf的mae值跟cos-cf和pcc-cf相比要小,coverage值要大。可以得出,nhsm-cf的推荐质量相优于cos-cf和pcc-cf。
从图3~图6可得知,无论近邻数k如何变化,largemargin-nhsm-cf的mae和coverage都能够取相对稳定的值。这是由于在利用大间隔确定目标用户与其他用户的相似度时,k的取值对推荐结果的影响较小。从图3和图4可以看出,在movielens数据集上largemargin-nhsm-cf的mae值都比nhsm-cf小,coverage值跟nhsm-cf相比要大。同样,在jester-data-2数据集中,mae和coverage的变化情况与movielens数据集呈现相同的规律。因此,本文所提算法(largemargin-nhsm-cf)优于nhsm-cf算法,进一步提高了协同过滤系统的推荐质量,验证了基于用户偏好的协同过滤推荐算法的有效性。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!