基于大数据的热点话题分析方法与流程
本发明涉及评估分析领域,具体涉及一种基于大数据的热点话题分析方法。
背景技术:
伴随着互联网技术的快速发展,信息量以指数形式迅猛增长。新闻消息由静态输出和被动获取转变为人人可以参与讨论、传播的新方式,在微博、知乎、instagram等平台,人们可以随意获取以及传播自己感兴趣的内容,在这个信息时代,任何一个人的想法都可能被大众广泛的感知,从而形成一个新话题的产生,引发更多人的关注,热点话题也从众多话题中脱颖而出,由于讨论度高的话题会被各个平台推送,因此也可以吸引更多人的注意,也从侧面反映了人们在现阶段关注的话题,另一方面,人们在互动平台上所表现出来的民情以及民意都对社会发展有重大的研究和参考价值。
各个媒体、商家以及政府只有了解到民众所关注的话题,才能掌握大众的需求以及舆论导向,针对热点问题采取相应的措施。在这个信息爆炸的数字时代,如何在众多话题中发现最有价值的热点话题也成为一个值得关注的方面,现如今热点话题和热点事件的发现和提取已成为有关话题检测与跟踪研究的分支之一,在大数据话题研究方面也有越来越多的身影。
21世纪,随着网络的快速发展,数据量也随之增长。数据量的增长则意味着进入了大数据时代。现有的技术中有关大数据的处理是基于hadoop的平台。hadoop是一个开源分布式计算平台,核心包括hdfs,其优点是允许用户将hadoop平台部署在低廉的硬件上,搭建分布式集群,构建分布式系统;hbase则是建立在分布式文件系统hdfs之上的分布式数据库系统,主要功能是存储非结构化和半结构化的松散数据。
现在要对存储在hbase上的松散数据进行热点话题的聚类分析,现有的聚类分析方法为采用层次聚类和k-means聚类算法相结合的方法,这种算法在使用上必须先确定聚类中心的个数k的大小,但在实际情况中,对话题进行抽取分类时预先不能确定k值的大小,这种情况会导致聚类结果产生较大偏差,误差相对来说比较大,并且由于层次聚类算法使用的是“贪心算法”,缺点是计算量比较大,这样不可避免的会降低运算速度。
因此,现在急需提供一种运算速度快的基于大数据的热点话题分析方法。
技术实现要素:
本发明意在提供一种基于大数据的热点话题分析方法,以解决现有分析方法速度慢的问题。
为解决以上问题提供如下方案:
方案一:本方案中的基于大数据的热点话题分析方法,包括以下步骤:
步骤一:热点话题数据收集;
步骤二:热点话题数据预处理:对步骤一所收集的数据进行干扰信息排除,提取文本数据中的关键项;每一个关键项对应一个用来表示在文档中作用程度的质量值q:
其中,n表示文档的总数,fn表示文档的关键项在文档n中出现的次数,l表示关键内容的长度;
设定一个标准值qs,当q>qs时,该关键项保留,当q<qs时,该关键项删除。
步骤三:利用canopy算法计算得到各个热点话题数据的关键项的初始中心个数k;
步骤四:利用k-means算法对数据进行聚类分析,最终聚类结果所得到的类即确定为话题;
步骤五:对步骤四中分好的各类话题进行话题热度分析;话题热度的主要参考指标为报道频率、报道持续天数、搜索量、点击量、评论量以及点赞量;话题热度计算公式可以表示为:
h=a1·h1+a2·h2+a3·h3+a4·h4+a5·h5+a6·h6
h表示话题的热度,h1代表话题的报道频率,h2代表话题的报道天数,h3代表话题的搜索量,h4代表话题的点击量,h5代表话题的评论量,h6则代表话题的点赞数,a1~a6则分别代表各个参考指标在话题热度分析中所占的比重系数。
有益效果:
本发明是一种基于大数据的热点话题分析方法。该分析方法主要采用了canopy和k-means相结合的聚类分析法对所有的数据文档进行话题分类,既保证了话题分类的精确度又提升了速度,在热点话题分析中有良好的应用。对热点话题进行分析和提取,可以使各大媒体、商家以及政府迅速掌握人民群众的思想动态,从而使媒体确定自己报道的哪些内容能够吸引人们的注意力,使商家可以根据民众所需进行设计生产进而实现利益最大化,使政府在人民群众的讨论中进行反思和改革,有利于国家的建设与发展。
方案二:步骤一中对热点话题数据的抽取是基于分布式云计算平台通过网络爬虫来实现的,对收集的数据进行存储则是在基于hdfs的分布式存储设备。
hdfs具有众多优点(主要包括高容错性、高伸缩性等)允许用户将hadoop部署在低廉的硬件上,搭建分布式集群,构成分布式系统。hbase(hadoopdatabase,hadoop数据库)是建立在分布式文件系统hdfs之上的提供高可靠性、高性能、列存储、可伸缩、实时读写的分布式数据库系统,主要用来存储非结构化和半结构化的松散数据。将收集的数据存储在基于hdfs的分布式存储设备中,有利于更快地进行数据存储。
方案三:步骤二中的干扰信息包括图片、视频、表情以及标点符号。
方案四:步骤三中用canopy算法计算时以质量值作为计算对象确定各个类的初始中心点,对于canopy算法的距离值参数t1和t2,t1、t2的初始值可以根据用户的需要设定,或者使用交叉验证获得。
t1、t2的初始值设定对聚类中心的个数k有较大影响,直接通过用户的需求设定,可以使整个计算更加满足客户实际需求。也可以通过交叉验证获得t1、t2的初始值,得到一个根据当前收集到的热点话题数据得出一个合适的参数初始值。
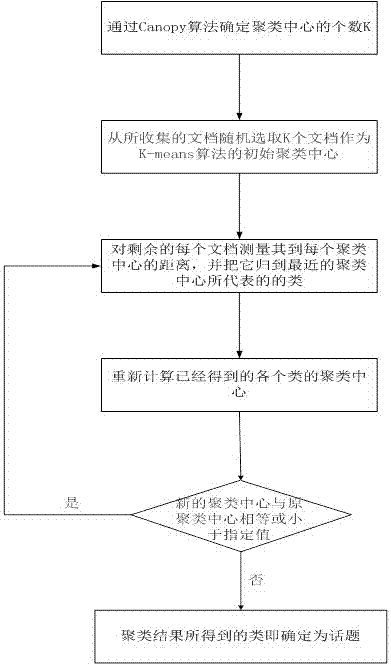
方案五:步骤四中利用k-means算法对数据进行聚类分析,包括以下步骤:
步骤一,通过canopy算法确定聚类中心的个数k;
步骤二,从所收集的文档随机选取k个文档作为k-means算法的初始聚类中心;
步骤三,对剩余的每个文档测量其到每个聚类中心的距离,并把它归到最近的聚类中心所代表的的类;
步骤四,重新计算已经得到的各个类的聚类中心;
步骤五,迭代步骤三至步骤四的步骤,直至新的聚类中心与原聚类中心相等或小于指定值。
迭代直至新的聚类中心与原聚类中心相等或小于指定值,将各类文档进行归类,确定它所在的类(也就是他属于哪个话题)。
附图说明
图1是基于大数据的热点话题分析的流程图。
图2是数据分类时采用的算法流程框图。
具体实施方式
下面通过具体实施方式对本发明作进一步详细的说明:
说明书附图中的附图标记包括:数据收集10、数据预处理20、数据分类30、话题热度分析40。
如附图1所示,本发明的主要步骤分为4步:数据收集,数据预处理,数据分类和话题热度分析。
数据收集的方法主要是通过网络爬虫来实现,爬虫的主要目的是将互联网上的网页下载到本地形成一个或联网内容的镜像备份,下载范围可以是微博、知乎、instagram、各大网站的推送等等。
对收集的数据则是在基于hdfs的分布式存储设备进行存储。
数据预处理的主要目的是排除非文字类的不必要信息的干扰,在一篇文档中如果出现图片、表情、视频以及用标点符号所表示的网络字符,则应把它所表达的情感进行人工标注,将其添加入文档信息。排除非文字类信息的影响之后,人工提取文本数据中的关键项,利用相关公式计算关键项的质量值,也就是它在文档中的质量程度,计算公式如下所示:
上式中,n表示收集数据的文档总数,fn表示文档的关键项在第n篇文档中出现的次数,l表示关键内容的长度,即关键项的长度。
根据统计,设定一个标准值qs,当q>qs时,该关键项保留,即所选取的关键项可以代表本篇文档的讨论内容,在文档中的质量程度较高,而当q<qs时则代表所选取的关键项不是该文档的讨论内容。
在数据预处理之后,对数据进行分类,将提取出的各个关键项分到一个大的类中,也就是话题。在数据欲处理之后可以获取每篇新闻报道或者讨论的关键项,首先通过canopy算法对关键项进行“粗”聚类分析确定聚类中心的个数k,具体算法的步骤如下
(1)将收集的所有数据记为总集合s,确定两个阈值t1和t2,且t1>t2(t1、t2的设定可以根据用户的需要,或者使用交叉验证获得);如,根据用户希望某一类(话题)中各个文档的相关程度的高低来确定,如果希望对话题进行细分,则可设t1的值较小;如果只是对话题进行简单粗略地分,可设t1的值设较小。具体将值设为多少代表相关度是高或是低,则是在用这个方法对热点话题分析多次之后,通过实验数据来确定。
(2)在s中任取一个文档记为样本点p,计算p与文档中其它样本数据向量之间的距离d;
(3)把d小于t1的文档划到一个canopy中,如果没有canopy则选择这个点为一个canopy的中心;
(4)把d小于t2的从数据从集合s中移除,这个点以后做不了其他的canopy的中心了;
(5)重复(2)~(4)步,直至数据集合s为空。
此时canopy的数目为聚类中心的个数k。
接下来利用k-means算法对数据进行“精”聚类分析,具体的算法步骤如下:
(1)从所收集的文档随机选取k个文档作为k-means算法的初始聚类中心;
(2)对剩余的每个文档测量其到每个聚类中心的距离,并把它归到最近的聚类中心所代表的的类;
(3)重新计算已经得到的各个类的聚类中心;
(4)迭代(2)~(3)步,直至新的聚类中心与原聚类中心相等或小于指定值。
最终聚类结果所得到的类即确定为话题。
最后一步是对话题进行热度分析,话题热度的主要参考指标为报道频率、报道持续天数、搜索量、点击量、评论量以及点赞量。话题热度计算公式可以表示为:
h=a1·h1+a2·h2+a3·h3+a4·h4+a5·h5+a6·h6
h表示话题的热度,h1代表话题的报道频率,h2代表话题的报道天数,话题被报道的越多,持续天数越长,则从侧面反映出公众对该话题的关注程度;h3代表话题的搜索量,h4代表话题的点击量,
搜索量表示公众对该话题自己想要了解的程度,更强调主观性,点击量则是在话题被给出以后公众想要对它的了解程度;h5代表话题的评论量,h6则代表话题的点赞数,这两个数据表现出公众对该话题的参与度。a1~a6则分别代表各个参考指标在话题热度分析中所占的比重系数,分析人可以根据自己对某一方面的看重程度来设定具体的数值,关注度越高的,比重系数越大。
以上所述的仅是本发明的实施例,方案中公知的具体结构及特性等常识在此未作过多描述,所属领域普通技术人员知晓申请日或者优先权日之前发明所属技术领域所有的普通技术知识,能够获知该领域中所有的现有技术,并且具有应用该日期之前常规实验手段的能力,所属领域普通技术人员可以在本申请给出的启示下,结合自身能力完善并实施本方案,一些典型的公知结构或者公知方法不应当成为所属领域普通技术人员实施本申请的障碍。应当指出,对于本领域的技术人员来说,在不脱离本发明结构的前提下,还可以作出若干变形和改进,这些也应该视为本发明的保护范围,这些都不会影响本发明实施的效果和专利的实用性。本申请要求的保护范围应当以其权利要求的内容为准,说明书中的具体实施方式等记载可以用于解释权利要求的内容。
- 还没有人留言评论。精彩留言会获得点赞!