基于sql语义自动解析的数据血统分析系统及方法与流程
本发明涉及数据血统分析领域,具体涉及一种基于sql语义自动解析的数据血统分析系统及方法。
背景技术:
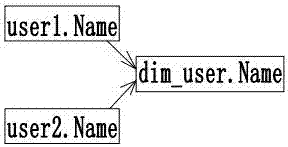
:数据血统(lineage,provenance,pedigree)亦可译为(血缘、起源、世系、谱系),是近几年随着数据库和网络的发展而发展起来的一个研究领域,其内容主要包括数据血统的计算、存储、传播和查询等。对于数据库系统,有时需要追溯查询结果的来源,以衡量数据的可信度、数据的质量等。随着信息技术的快速发展,企业内部积累了越来越多的数据资产,为了支持管理决策,充分挖掘数据价值,企业需要对大量的源数据进行数据处理和分析,随着数据量的增多、业务的复杂性增加,数据的处理和分析过程也越来越复杂,这就使得数据的变化难以监控跟踪,用户对数据的信任程度降低,专家流失会导致重大的数据问题发生,底层的模型结构难以变更,分析人员需要花费大量的时间来手动进行数据的血统分析。针对这个问题,目前有很多数据血统分析的方法,主要是基于etl(extract-transform-load,数据仓库)处理过程的分析系统,这种系统可以对数据的etl过程进行记录,记录数据的变化过程作为元数据,后续通过对元数据的解析,生成特点数据的血统图。但是这种系统仅能解决数据利用工具进行etl处理的情况,对于通过数据库管理工具利用sql脚本处理的数据不适用。因此鉴于上述缺陷,有必要设计一种基于sql脚本语义自动解析的数据血统分析系统。技术实现要素:本发明意在提供一种能够通过数据库管理工具利用sql脚本处理的数据进行数据血统分析的基于sql语义自动解析的数据血统分析系统。为达到以上目的,提供如下方案:方案一:基于sql语义自动解析的数据血统分析系统,包括依次连接的sql预处理模块、血统识别模块和血统展现模块;所述sql预处理模块,建立关键字规则库,从待检测数据所在的数据库中读取待检测的数据模型结构和数据处理的sql脚本,并对数据处理的sql脚本进行分解,形成脚本分析表;所述血统识别模块对sql预处理模块中读取的数据处理的sql脚本进行关键字识别,并对关键字对应的数据处理的sql脚本进行血统信息提取,并将血统信息存储至脚本分析表中;所述血统展现模块对脚本分析表中的血统信息进行顺序整合并展现血统连接的过程。工作原理:sql预处理模块根据预先输入的关键字建立关键字规则库。工作时,sql预处理模块从待检测数据所在的数据库中读取待检测的数据模型结构和数据处理的sql脚本,并对数据处理的sql脚本进行分解,形成脚本分析表;然后,血统识别模块对sql预处理模块中读取的数据处理的sql脚本进行关键字识别,并对关键字对应的数据处理的sql脚本进行血统信息提取,并将血统信息存储至脚本分析表中;最后,血统展现模块对脚本分析表中的血统信息进行顺序整合并展现血统连接的过程。有益效果:每段sql脚本都对应一个关键字,通过关键字来自动解析每个sql脚本,使在脚本分析表中有联系的sql脚本形成可追溯的血统关系。采用该系统相比人工检测节省了大量时间和精力。其次弥补了传统只对etl过程进行分析的不足,补充了血统分析的方法。方案二:在方案一的基础上进一步,所述sql预处理模块,包括依次连接的关键字规则库建立单元、数据模型及数据处理的sql脚本提取单元以及脚本分解单元;所述关键字规则库建立单元,建立关键字规则库,收集关键字,确定每个关键字的结构并规范结构中的血统变化流向;所述数据模型及数据处理的sql脚本提取单元从待检测数据所在的数据库中读取待检测的数据模型结构和数据处理的sql脚本;所述脚本分解单元对数据模型及数据处理的sql脚本提取单元中的数据处理的sql脚本按照最小的操作单元进行分段,并且按sql执行顺序进行编号,然后对每段sql脚本细化分解并存储至脚本分析表。方案三:在方案一的基础上进一步,所述血统识别模块,包括依次连接的关键字发现单元和血统提取单元;所述关键字发现单元,通过规则库建立单元中建立的关键字规则库,对脚本分解单元中的数据处理的sql脚本进行关键字匹配,并将关键字存储至脚本分析表;所述血统提取单元根据关键字规则库中的关键字语句结构以及上游和下游的血统规范,对脚本分析表中的脚本信息进行匹配,确定血统变化的流向,并记录于脚本分析表中。名词解释:上游:指产生该数据的前一个环节。下游:指该数据产生的下一个环节。方案四:在方案一的基础上进一步,所述血统展现模块包括血统展现单元;所述血统展现单元对脚本分析表中的数据按照顺序编号,对血统上游和下游的血统信息进行分类整合,再按照脚本分析表中的顺序编号提取出来,完成了血统的展现。方案五:在方案二的基础上进一步,所述数据模型结构,包括表结构、字段定义及规范、在数据库中预定义的主外键约束。本发明的另一目的是提供一种基于sql语义自动解析的数据血统分析系统的分析方法,包括以下步骤:步骤一:在sql预处理模块中的关键字规则库建立单元中,根据sql脚本体系建立关键字规则库;步骤二:数据模型及数据处理的sql脚本提取单元从待检测血统的数据所在的数据库中读取数据模型和数据处理的sql脚本;步骤三:脚本分解单元对步骤二中读取的数据处理的sql脚本进行排序、分解;每段数据分析sql脚本对应一个顺序编号;分解得到子脚本;将顺序编号和子脚本存储到脚本分析表中,步骤四:关键字发现单元对步骤三中分解出来的子脚本,进行关键字识别,并将识别得到的关键字与关键字规则库中的关键字进行匹配;将匹配的关键字名称存储到脚本分析表中;步骤五:血统提取单元对已经识别关键字的子脚本,再以关键字规则库中的关键字结构识别结构中的参数对应的数据字段,确定子脚本的上游数据和下游数据,并存储到脚本分析表中;步骤六:血统展现单元对脚本分析表中的数据按照顺序编号,对血统上游、下游进行分类整合。进一步,在步骤三中,首先,在数据库中建立脚本分析表的数据模型;然后,以数据处理的sql脚本的执行顺序进行排序;最后,对已经排好序的各段数据处理的sql脚本分别分解到的子脚本为可执行的最小单位。进一步,从同一段数据处理的sql脚本中拆分出来的子脚本对应的顺序编号相同。进一步,在步骤六中,对整合后的血统按照顺序编号从小到大的顺序展现。附图说明图1是本发明基于sql语义自动解析的数据血统分析系统实施例的逻辑框图。图2是血统展现单元展现出的血统信息示例图。具体实施方式下面通过具体实施方式对本发明作进一步详细的说明:说明书附图中的附图标记包括:sql预处理模块10、关键字规则库建立单元11、数据模型及数据处理的sql脚本提取单元12、脚本分解单元13、血统识别模块20、关键字发现单元21、血统提取单元22、血统展现模块30、血统展现单元31。如图1所示,本实施例中基于sql脚本语义自动解析的数据血统分析系统由sql预处理模块10,血统识别模块20和血统展现模块30组成。sql预处理模块10负责建立关键字规则库,从待检测数据所在的数据库中读取待检测的数据模型结构和数据处理的sql脚本,并对脚本进行分解,由关键字规则库建立单元11、数据模型及数据处理的sql脚本提取单元12、脚本分解单元13组成。关键字规则库建立单元11负责建立关键字规则库,穷举关键字以及根据sql语义人为记录关键字中对应的血统变化流向。数据模型及数据处理的sql脚本提取单元12从待检测数据所在的数据库中读取待检测的数据模型结构和数据处理脚本,包括表结构、字段定义及规范、在数据库中预定义的主外键约束、以及数据处理的sql脚本信息。脚本分解单元13对数据模型及数据处理的sql脚本提取单元12中的数据处理sql脚本按照最小的操作单元进行分段,并且按sql执行顺序进行编号,然后对每段sql脚本细化分解,如一段脚本是对多个字段进行处理,则分解为多个脚本,每个脚本只对一个字段进行处理,最后将执行顺序的编号以及细化的多个脚本存储于脚本分析表中。血统识别模块20负责对脚本进行关键字识别与发现,并对关键字对应的脚本进行血统信息提取,由关键字发现单元21、血统提取单元22组成。关键字发现单元21利用规则库建立单元11中建立的关键字规则库,对脚本分解单元中的脚本进行关键字匹配,将关键字存储于脚本分析表中。血统提取单元22根据关键字规则库中的关键字语句结构,以及上下游血统规范,对脚本分析表中的脚本信息进行匹配,确定血统变化的流向,记录于脚本分析表中。血统展现模块30负责对脚本分析表中的血统进行顺序整合,以及血统连接展现的过程,由血统展现单元31组成。血统展现单元31是对脚本分析表中的数据按照顺序编号,对血统上游、下游进行分类整合,再按照脚本分析表中的顺序编号提取出来,并用单向箭头连接从上游指向下游,即完成了血统的展现。本实例待分析数据血统关系的sql脚本如下:selectname,year(getdate())-ageintodim_user(name,birthyear)fromuser1;insertintodim_user(name,birthyear)selectname,year(getdate())-agefromuser2;脚本执行的目的是对表1、表2的数据源表user1、user2进行处理,并将处理结果存入表3的dim_user中。因此,实例通过分析的数据处理sql脚本以得出表之间的数据血统关系。表1idnameage1tom242lee21………表2idnameage1jack302jane19………表3idnamebirthyear本实施例基于sql语义自动解析的数据血统分析系统的分析方法包括以下步骤:s1:sql预处理模块10的关键字规则库建立单元11,分析人员根据sql脚本体系建立初始化的关键字规则库,主要内容如表4所示,后续若关键字规则库内容有变更,则由分析人员进行维护修改。表4s2:数据模型及数据处理的sql脚本提取单元12从待检测血统的数据所在的数据库中读取数据模型,如表1、表2、表3所示,读取前面写到的数据处理的sql脚本。s3:脚本分解单元13对的脚本进行排序、分解并存储到如表5的脚本分析表中,如表5的第2、3列。表5s3.1:首先在数据库中建立如表5所示的脚本分析表的数据模型。s3.2:对的脚本进行排序,以脚本的执行顺序为依据。如,sql脚本在数据库中按顺序应该先执行selectname,year(getdate())-ageintodim_user(name,birthyear)fromuser1,则对这段脚本记录顺序编号为1,然后再执行insertintodim_user(name,birthyear)selectname,year(getdate())-agefromuser2,则对这段脚本记录顺序编号为2,顺序编号如表5中的第2列(顺序编号)。s3.3:对s3.2中的各段脚本进行分解,分解为可执行的最小单位,并且对多个字段的处理也要细分为多个脚本,如selectname,year(getdate())-ageintodim_user(name,birthyear)fromuser1这段脚本,可以拆分细化为selectnameintodim_user(name)fromuser1和selectyear(getdate())-ageintodim_user(birthyear)fromuser1两个子脚本,拆分后存储到表5的脚本分析表中,如第3列。s3.3.1:注意,从同一段脚本中拆分出来的子脚本对应的顺序编号相同。s4:关键字发现单元21对s3分解出来的sql脚本,即表5的第3列,以表4中的第2列关键字名称作为识别依据,进行匹配,如果子脚本匹配到关键字名称,则将关键字名称存储在脚本分析表中,即存入表5的第4列。如子脚本selectnameintodim_user(name)fromuser1经过匹配后,确定关键字为selectintofrom。s5:血统提取单元22对已经识别关键字的子脚本,再以关键字规则库中的关键字结构识别结构中的参数对应的数据字段,如selectnameintodim_user(name)fromuser1对应的关键字为selectintofrom,在关键字规则库中selectintofrom对应的关键字结构为selectaintot2fromt1,则可以确定这段子脚本中,a为name,t2为dim_user,t1为user1,因此可以确定血统上游数据为t1.a即user1.name,血统下游数据为t2.a即dim_user.name。将确定后的血统上下游数据存入脚本分析表中,如表5的第5、6列。s6:血统展现单元31对脚本分析表中的数据按照顺序编号,对血统上游、下游进行分类整合。s6.1:对血统信息整合,如对表5中第6列的dim_user.name整合,确定dim_user.name来源于user1.name和user2.name。s6.2:对整合后的血统按照顺序编号从小到大的顺序展现,如s6.1中例子按照顺序编号后展现为图2所示结构。以上的仅是本发明的实施例,方案中公知的具体结构及特性等常识在此未作过多描述,所属领域普通技术人员知晓申请日或者优先权日之前发明所属
技术领域:
所有的普通技术知识,能够获知该领域中所有的现有技术,并且具有应用该日期之前常规实验手段的能力,所属领域普通技术人员可以在本申请给出的启示下,结合自身能力完善并实施本方案,一些典型的公知结构或者公知方法不应当成为所属领域普通技术人员实施本申请的障碍。应当指出,对于本领域的技术人员来说,在不脱离本发明结构的前提下,还可以作出若干变形和改进,这些也应该视为本发明的保护范围,这些都不会影响本发明实施的效果和专利的实用性。本申请要求的保护范围应当以其权利要求的内容为准,说明书中的具体实施方式等记载可以用于解释权利要求的内容。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1