用于提供向量混合和置换功能的指令和逻辑的制作方法
本申请是国际申请日为2011年12月23日、中国国家阶段申请号为201180075784.9、题为“用于提供向量混合和置换功能的指令和逻辑”的发明专利申请的分案申请。
本公开涉及处理逻辑、微处理器以及相关联的指令集体系结构的领域,该指令集体系结构在被处理器或其他处理逻辑所执行时运行逻辑、数学或其他功能性操作。具体而言,本公开涉及用于提供向量混合和置换功能的指令和逻辑。
背景技术:
目前的诸多处理器通常包括用于提供计算密集型操作但提供高度数据并行性的指令,这些指令可通过使用多种数据存储设备的高效实现来使用,这些数据存储设备诸如:单指令多数据(simd)向量寄存器。
利用simd向量寄存器的处理器的一个可能的性能问题是,存储在物理存储器中的数据的放置方式需要在向量寄存器中进行重排以应用所期望的存储器和/或simd算术操作,例如处于未对齐地址的数据、或处于两个相应高速缓存行的末尾和开始处的数据、或在表的不同条目中的数据、或在图像中跨越块边界的数据,等等。
过去的一些实施例已经实现用于处理这些可能的性能问题中的某些特殊情况的指令,诸如处理未对齐地址或执行特定转换的特殊重新安排的指令。然而,用于处理某些特殊情况的实现方式可能难以更普遍地适应,和/或可能需要更多个专用电路或预先处理数据以作出适应。这样的实现方式会限制例如来自宽或大宽度向量体系结构的原本预期的性能优势。
迄今为止,尚未充分探索针对这样的性能受限问题和瓶颈的潜在解决方案。
附图说明
在附图的各图中通过示例而非限制地示出本发明。
图1a是执行用于提供向量混合和置换功能的指令的系统的一个实施例的框图。
图1b是执行用于提供向量混合和置换功能的指令的系统的另一实施例的框图。
图1c是执行用于提供向量混合和置换功能的指令的系统的另一实施例的框图。
图2是执行用于提供向量混合和置换功能的指令的处理器的一个实施例的框图。
图3a示出根据一个实施例的打包数据类型。
图3b示出根据一个实施例的打包数据类型。
图3c示出根据一个实施例的打包数据类型。
图3d示出根据一个实施例的用于提供向量混合和置换功能的指令编码。
图3e示出根据另一实施例的用于提供向量混合和置换功能的指令编码。
图3f示出根据另一实施例的用于提供向量混合和置换功能的指令编码。
图3g示出根据另一实施例的用于提供向量混合和置换功能的指令编码。
图3h示出根据另一实施例的用于提供向量混合和置换功能的指令编码。
图4a示出用于执行提供向量混合和置换功能的指令的处理器微体系结构的一个实施例的要素。
图4b示出用于执行提供向量混合和置换功能的指令的处理器微体系结构的另一实施例的要素。
图5是执行用于提供向量混合和置换功能的指令的处理器的一个实施例的框图。
图6是执行用于提供向量混合和置换功能的指令的计算机系统的一个实施例的框图。
图7是执行用于提供向量混合和置换功能的指令的计算机系统的另一实施例的框图。
图8是用于执行提供向量混合和置换功能的指令的计算机系统的另一实施例的框图。
图9是用于执行提供向量混合和置换功能的指令的芯片上系统的一个实施例的框图。
图10是执行用于提供向量混合和置换功能的指令的处理器的实施例的框图。
图11是提供向量混合和置换功能的ip核开发系统的一个实施例的框图。
图12示出提供向量混合和置换功能的体系结构仿真系统的一个实施例。
图13示出用于转换提供向量混合和置换功能的指令的系统的一个实施例。
图14示出用于执行提供向量混合和置换功能的指令的装置的一个实施例。
图15示出用于提供向量混合和置换功能的过程的一个实施例的流程图。
图16示出用于提供向量混合和置换功能的过程的替代实施例的流程图。
图17示出编码指令的实施例。
图18示出编码指令的另一实施例。
具体实施方式
以下描述公开了用于提供在处理器、计算机系统或其他处理装置之内的或与处理器、计算机系统或其他处理装置相关联的向量混合和置换功能的指令和处理逻辑。
指令和逻辑提供向量混合和置换功能。在一些实施例中,向量混合和置换指令指定:目的地寄存器,具有用于存储向量元素的字段;元素尺寸;掩码;索引向量;第一源向量;以及第二源向量。从索引向量中的字段中读取索引。每个索引具有第一选择器部分和第二选择器部分。如下地将未被掩蔽的向量元素存储至目的地操作数的相应字段。在混合操作期间,当相应的第一选择器部分具有一个特定值(例如0)时,将每个向量元素复制至来自第一源向量的相应数据字段的中间向量,而当相应的第一选择器部分具有另一特定值(例如1)时,将每个向量元素复制至来自第二源向量的相应数据字段的中间向量。然后,在置换操作期间,按照来自索引向量的相应第二选择器字段部分所提供的索引,将目的地的未被掩蔽的数据字段替换为来自中间向量的数据字段。
因此,通过提供向量混合和置换功能的指令和逻辑,可在向量寄存器中高效地重新安排那些存储在物理存储器中的且放置方式需要在向量寄存器中进行重排以应用所期望的存储器和/或simd算术操作的数据,例如,处于未对齐地址的数据、或处于两个相应高速缓存行的末尾和开始处的数据、或在表的不同条目中的数据、或在图像中跨越块边界的数据,等等。
在以下描述中,陈述了诸如处理逻辑、处理器类型、微体系结构状况、事件、启用机制等多种特定细节,以提供对本发明实施例的更透彻理解。然而,本领域技术人员应当领会,没有这些具体细节也可实践本发明。此外,没有详细示出一些公知的结构、电路等等,以避免不必要地模糊本发明的实施例。
虽然下述的诸个实施例参照处理器来描述,但其他实施例也适用于其他类型的集成电路和逻辑设备。本发明的实施例的类似技术和教导可应用于其它类型的电路或半导体器件,这些其它类型的电路或半导体器件也可受益于更高的流水线吞吐量和提高的性能。本发明的诸个实施例的教导适用于执行数据操纵的任何处理器或机器。然而,本发明不限于执行512位、256位、128位、64位、32位、或16位数据运算的处理器或机器,并可适用于执行数据操纵或管理的任何处理器和机器。此外,下述描述提供了示例,并且附图出于示意性目的示出了多个示例。然而,这些示例不应该被理解为具有限制性目的,因为它们仅仅旨在提供本发明的诸个实施例的示例,而并非对本发明的实施例的所有可能实现方式进行穷举。
虽然下述的示例描述了在执行单元和逻辑电路情况下的指令处理和分配,但本发明的其他实施例也可通过存储在机器可读有形介质上的数据或指令来完成,这些数据或指令在被机器执行时使得机器执行与本发明至少一个实施例相一致的功能。在一个实施例中,与本发明的实施例相关联的功能被具体化在机器可执行指令中。这些指令可用来使通过这些指令编程的通用处理器或专用处理器执行本发明的步骤。本发明的诸个实施例也可以作为计算机程序产品或软件来提供,该计算机程序产品或软件可包括其上存储有指令的机器或计算机可读介质,这些指令可被用来对计算机(或其他电子设备)进行编程来执行根据本发明的实施例的一个或多个操作。另选地,本发明的诸个实施例的这些步骤可由包含用于执行这些步骤的固定功能逻辑的专用硬件组件来执行,或由经编程的计算机组件以及固定功能硬件组件的任何组合来执行。
被用于对逻辑进行编程以执行本发明的诸个实施例的指令可被存储在系统中的存储器(诸如,dram、高速缓存、闪存、或其他存储器)内。进一步的,指令可经由网络或其他计算机可读介质来分发。因此,计算机可读介质可包括用于以机器(诸如,计算机)可读的格式存储或发送信息的任何机制,但不限于:软盘、光盘、致密盘只读存储器(cd-rom)、磁光盘、只读存储器(rom)、随机存取存储器(ram)、可擦除可编程只读存储器(eprom)、电可擦除可编程只读存储器(eeprom)、磁卡或光卡、闪存、或在经由互联网通过电、光、声、或其他形式的传播信号(诸如,载波、红外信号、数字信号等)发送信息中所用的有形机器可读存储器。因此,计算机可读介质包括用于存储或发送机器(例如,计算机)可读形式的电子指令或信息的任何类型的有形机器可读介质。
设计会经历多个阶段,从创新到模拟到制造。表示设计的数据可用多种方式来表示该设计。首先,如模拟中将有用的,可使用硬件描述语言或其他功能性描述语言来表示硬件。此外,具有逻辑和/或晶体管门电路的电路级模型可在设计流程的其他阶段产生。此外,大多数设计在某些阶段都到达表示硬件模型中多种设备的物理配置的数据水平。在使用常规半导体制造技术的情况下,表示硬件模型的数据可以是在不同掩模层上对用于生成集成电路的掩模指示不同特征的存在与否的数据。在任何的设计表示中,数据可被存储在任何形式的机器可读介质中。存储器或磁/光存储器(诸如,盘)可以是存储信息的机器可读介质,这些信息是经由光学或电学波来发送的,这些光学或电学波被调制或以其他方式生成以传送这些信息。当发送指示或承载代码或设计的电学载波时,执行电信号的复制、缓冲或重传情况时,制作一个新的副本。因此,通信提供商或网络提供商会在有形机器可读介质上至少临时地存储具体化本发明的诸个实施例的技术的物品(诸如,编码在载波中的信息)。
在现代处理器中,多个不同执行单元被用于处理和执行多种代码和指令。并不是所有指令都被同等地创建,因为其中有一些更快地被完成而另一些需要多个时钟周期来完成。指令的吞吐量越快,则处理器的总体性能越好。因此,使大量指令尽可能快地执行将会是有利的。然而,某些指令具有更大的复杂度,并需要更多的执行时间和处理器资源。例如,存在浮点指令、加载/存储操作、数据移动等等。
因为更多的计算机系统被用于互联网、文本以及多媒体应用,所以逐渐地引进更多的处理器支持。在一个实施例中,指令集可与一个或多个计算机体系结构相关联,一个或多个计算机体系结构包括数据类型、指令、寄存器体系结构、寻址模式、存储器体系结构、中断和异常处理以及外部输入输出(i/o)。
在一个实施例中,指令集体系结构(isa)可由一个或更多微体系结构来实现,微体系结构包括用于实现一个或多个指令集的处理器逻辑和电路。因此,具有不同微体系结构的诸个处理器可共享公共指令集的至少一部分。例如,
在一个实施例中,指令可包括一个或多个指令格式。在一个实施例中,指令格式可指示多个字段(位的数目、位的位置等)以特别指定将要被执行的操作以及将要被执行的操作的操作数。一些指令格式可进一步被指令模板(或子格式)所细分定义。例如,给定指令格式的指令模板可被定义为具有指令格式字段的不同的子集,和/或被定义为具有不同解释的给定字段。在一个实施例中,使用指令格式(并且,如果定义过,则以该指令格式的一个给定指令模板)来表示指令,并且该指令指定或指示操作以及该操作将操作的操作数。
科学应用、金融应用、自动向量化通用应用、rms(识别、挖掘和合成)应用以及视觉和多媒体应用(诸如,2d/3d图形、图像处理、视频压缩/解压缩、语音识别算法和音频处理)可能需要对大量数据项执行相同的操作。在一个实施例中,单指令多数据(simd)指的是使得处理器在多个数据元素上执行一操作的一种类型的指令。simd技术可被用于处理器中,这些处理器将寄存器中的诸个位(bit)逻辑地划分入多个固定尺寸或可变尺寸的数据元素,每个数据元素表示单独的值。例如,在一个实施例中,64位寄存器中的诸个位可被组织为包含四个单独的16位数据元素的源操作数,每个数据元素表示单独的16位值。该数据类型可被称为“打包”数据类型或“向量”数据类型,并且该数据类型的操作数被称为打包数据操作数或向量操作数。在一个实施例中,打包数据项或向量可以是存储在单个寄存器中的打包数据元素的序列,并且打包数据操作数或向量操作数可以是simd指令(或“打包数据指令”或“向量指令”)的源操作数或目的地操作数。在一个实施例中,simd指令指定了将要对两个源向量操作数执行的单个向量操作,以生成具有相同或不同尺寸的、具有相同或不同数量的数据元素的、具有相同或不同数据元素次序的目的地向量操作数(也被称为结果向量操作数)。
诸如由
在一个实施例中,目的地寄存器/数据和源寄存器/数据是表示对应数据或操作的源和目的地的通用术语。在一些实施例中,它们可由寄存器、存储器或具有与所示出的那些名称或功能不同的名称或功能的其他存储区域所实现。例如,在一个实施例中,“dest1”可以是临时存储寄存器或其他存储区域,而“src1”和“src2”是第一和第二源存储寄存器或其他存储区域,等等。在其他实施例中,src和dest存储区域中的两个或更多区域可对应于相同存储区域中的不同数据存储元素(例如,simd寄存器)。在一个实施例中,例如通过将对第一和第二源数据执行的操作的结果写回至两个源寄存器中作为目的地寄存器的那个寄存器,源寄存器中的一个也可以作为目的地寄存器。
图1a是根据本发明的一个实施例的示例性计算机系统的框图,具有包括执行单元以执行指令的处理器。根据本发明,诸如根据在此所描述的实施例,系统100包括诸如处理器102之类的组件,以采用包括逻辑的执行单元来执行算法以处理数据。系统100代表基于可从美国加利福尼亚州圣克拉拉市的英特尔公司获得的
实施例不限于计算机系统。本发明的替换实施例可被用于其他设备,诸如手持式设备和嵌入式应用。手持式设备的一些示例包括:蜂窝电话、互联网协议设备、数码相机、个人数字助理(pda)、手持式pc。嵌入式应用可包括:微控制器、数字信号处理器(dsp)、芯片上系统、网络计算机(netpc)、机顶盒、网络中枢、广域网(wan)交换机、或可执行参照至少一个实施例的一个或多个指令的任何其他系统。
图1a是计算机系统100的框图,计算机系统100被形成为具有处理器102,处理器102包括一个或多个执行单元108以执行算法,以执行根据本发明的一个实施例的至少一个指令。参照单处理器桌面或服务器系统来描述了一个实施例,但替代实施例可被包括在多处理器系统中。系统100是“中枢”系统体系结构的示例。计算机系统100包括处理器102以处理数据信号。处理器102可以是复杂指令集计算机(cisc)微处理器、精简指令集计算(risc)微处理器、超长指令字(vliw)微处理器、实现指令集组合的处理器或任意其它处理器设备(诸如数字信号处理器)。处理器102耦合至处理器总线110,处理器总线110可在处理器102和系统100内的其他组件之间传输数据信号。系统100的诸个元素执行本领域所熟知的常规功能。
在一个实施例中,处理器102包括第一级(l1)内部高速缓存存储器104。取决于体系结构,处理器102可具有单个内部高速缓存或多级内部高速缓存。或者,在另一个实施例中,高速缓存存储器可位于处理器102的外部。其他实施例也可包括内部高速缓存和外部高速缓存的组合,这取决于特定实现和需求。寄存器组106可在多个寄存器(包括整数寄存器、浮点寄存器、状态寄存器、指令指针寄存器)中存储不同类型的数据。
执行单元108(包括执行整数和浮点操作的逻辑)也位于处理器102中。处理器102还包括微代码(ucode)rom,其存储用于特定宏指令的微代码。对于一个实施例,执行单元108包括处理打包指令集109的逻辑。通过将打包指令集109包括在通用处理器102的指令集内并包括相关的电路以执行这些指令,可使用通用处理器102中的打包数据来执行许多多媒体应用所使用的操作。因此,通过将处理器数据总线的全带宽用于对打包数据进行操作,许多多媒体应用可获得加速,并更为有效率地执行。这能减少在处理器数据总线上传输更小数据单元以在一个时间对一个数据元素执行一个或多个操作的需要。
执行单元108的替换实施例也可被用于微控制器、嵌入式处理器、图形设备、dsp以及其他类型的逻辑电路。系统100包括存储器120。存储器设备120可以是动态随机存取存储器(dram)设备、静态随机存取存储器(sram)设备、闪存设备或其他存储器设备。存储器120可存储可由处理器102执行的指令和/或数据,数据由数据信号表示。
系统逻辑芯片116耦合至处理器总线110和存储器120。在所示出的实施例中的系统逻辑芯片116是存储器控制器中枢(mch)。处理器102可经由处理器总线110与mch116通信。mch116提供至存储器120的高带宽存储器路径118,用于指令和数据存储,以及用于存储图形命令、数据和纹理。mch116用于引导处理器102、存储器120以及系统100内的其他组件之间的数据信号,并在处理器总线110、存储器120和系统i/o接口总线122之间桥接数据信号。在一些实施例中,系统逻辑芯片116可提供耦合至图形控制器112的图形端口。mch116经由存储器接口118耦合至存储器120。图形卡112通过加速图形端口(agp)互连114耦合至mch116。
系统100使用外围设备中枢接口总线122以将mch116耦合至i/o控制器中枢(ich)130。ich130经由局部i/o总线提供至一些i/o设备的直接连接。局部i/o总线是高速i/o总线,用于将外围设备连接至存储器120、芯片组以及处理器102。一些示例是音频控制器、固件中枢(闪存bios)128、无线收发机126、数据存储器124、包括用户输入和键盘接口的传统i/o控制器、串行扩展端口(诸如通用串行总线usb)以及网络控制器134。数据存储设备124可以包括硬盘驱动器、软盘驱动器、cd-rom设备、闪存设备、或其他大容量存储设备。
对于系统的另一个实施例,根据一个实施例的指令可被用于芯片上系统。芯片上系统的一个实施例包括处理器和存储器。用于这样一个系统的存储器是闪存存储器。闪存存储器可位于与处理器和其他系统组件相同的管芯上。此外,诸如存储器控制器或图形控制器之类的其他逻辑块也可位于芯片上系统上。
图1b示出数据处理系统140,数据处理系统140实现本发明的一个实施例的原理。本领域的技术人员将容易理解,在此描述的诸个实施例可用于替代处理系统,而不背离本发明的实施例的范围。
计算机系统140包括处理核159,处理核159能执行根据一个实施例的至少一个指令。对于一个实施例,处理核159表示任何类型的体系结构的处理单元,包括但不限于:cisc、risc或vliw类型体系结构。处理核159也可适于以一种或多种处理技术来制造,并且通过充分详细地表示在机器可读介质上可以便于其制造。
处理核159包括执行单元142、一组寄存器组145以及解码器144。处理核159也包括对于理解本发明的实施例不是必需的额外电路(没有示出)。执行单元142用于执行处理核159所接收到的指令。除了执行典型的处理器指令外,执行单元142也能执行打包指令集143中的指令,用于对打包数据格式执行操作。打包指令集143包括用于执行本发明的诸个实施例的指令以及其他打包指令。执行单元142通过内部总线而耦合至寄存器组145。寄存器组145表示处理核159上的存储区域,用于存储包括数据的信息。如前所述的,可以理解,该存储区域被用于存储打包数据不是关键。执行单元142耦合至解码器144。解码器144用于将处理核159所接收到的指令解码为控制信号和/或微代码进入点。响应于这些控制信号和/或微代码进入点,执行单元142执行合适的操作。在一个实施例中,解码器用于解释指令的操作码,操作码指示应当对该指令内所指示的对应数据执行何种操作。
处理核159耦合至总线141,用于与多个其他系统设备进行通信,这些系统设备包括但不限于:例如,同步动态随机存取存储器(sdram)控制器146、静态随机存取存储器(sram)控制器147、猝发闪存接口148、个人计算机存储卡国际协会(pcmcia)/致密闪存(cf)卡控制器149、液晶显示器(lcd)控制器150、直接存储器存取(dma)控制器151、以及替代的总线主接口152。在一个实施例中,数据处理系统140也包括i/o桥154,用于经由i/o总线153与多个i/o设备进行通信。这样的i/o设备可包括但不限于:例如,通用异步接收机/发射机(uart)155、通用串行总线(usb)156、蓝牙无线uart157、以及i/o扩展接口158。
数据处理系统140的一个实施例提供了移动通信、网络通信和/或无线通信,并提供了能够执行simd操作的处理核159,simd操作包括向量混合和置换功能。处理核159可编程有多种音频、视频、图像和通信算法,包括离散变换(诸如walsh-hadamard变换、快速傅立叶变换(fft)、离散余弦变换(dct)、以及它们相应的逆变换)、压缩/解压缩技术(诸如色彩空间变换)、视频编码运动估计或视频解码运动补偿、以及调制/解调(modem)功能(诸如脉冲编码调制pcm)。
图1c示出了能够执行用于提供向量混合和置换功能的指令的数据处理系统的其他替代实施例。根据一个替代实施例,数据处理系统160可包括主处理器166、simd协处理器161、高速缓存处理器167以及输入/输出系统168。输入/输出系统168可选地耦合至无线接口169。simd协处理器161能够执行包括根据一个实施例的指令的操作。处理核170可适于以一种或多种处理技术来制造,并且通过充分详细地表示在机器可读介质上可以便于包括处理核170的数据处理系统160的全部或一部分的制造。
对于一个实施例,simd协处理器161包括执行单元162以及一组寄存器组164。主处理器166的一个实施例包括解码器165,用于识别指令集163的指令,指令集163包括根据一个实施例的用于由执行单元162所执行的指令。对于替换实施例,simd协处理器161也包括解码器165b的至少一部分以解码指令集163的指令。处理核170也包括对于理解本发明的实施例不是必需的额外电路(没有示出)。
在操作中,主处理器166执行数据处理指令流,数据处理指令流控制通用类型的数据处理操作,包括与高速缓存存储器167以及输入/输入系统168的交互。simd协处理器指令嵌入数据处理指令流中。主处理器166的解码器165将这些simd协处理器指令识别为应当由附连的simd协处理器161来执行的类型。因此,主处理器166在协处理器总线171上发出这些simd协处理器指令(或表示simd协处理器指令的控制信号),任何附连的simd协处理器从协处理器总线171接收到这些指令。在该情况中,simd协处理器161将接受并执行任何接收到的针对该simd协处理器的simd协处理器指令。
可经由无线接口169接收数据以通过simd协处理器指令进行处理。对于一个示例,语音通信可以数字信号的形式被接收到,其将被simd协处理器指令所处理,以重新生成表示该语音通信的数字音频采样。对于另一个示例,压缩音频和/或视频可以数字位流的形式被接收到,其将被simd协处理器指令所处理,以重新生成数字音频采样和/或运动视频帧。对于处理核170的一个实施例,主处理器166和simd协处理器161被集成在单个处理核170中,该单个处理核170包括执行单元162、一组寄存器组164、以及解码器165以识别指令集163的指令,指令集163包括根据一个实施例的指令。
图2是包括逻辑电路以执行根据本发明的一个实施例的指令的处理器200的微体系结构的框图。在一些实施例中,根据一个实施例的指令可被实现为对具有字节尺寸、字尺寸、双字尺寸、四字尺寸等并具有诸多数据类型(诸如单精度和双精度整数和浮点数据类型)的数据元素执行操作。在一个实施例中,有序前端201是处理器200的一部分,其取出将要被执行的指令,并准备这些指令以在稍后供处理器流水线使用。前端201可包括诸个单元。在一个实施例中,指令预取器226从存储器取出指令,并将指令馈送至指令解码器228,指令解码器228随后解码或解释指令。例如,在一个实施例中,解码器将所接收到的指令解码为机器可执行的被称为“微指令”或“微操作”(也称为微操作数或uop)的一个或多个操作。在其他实施例中,解码器将指令解析为操作码和对应的数据及控制字段,它们被微体系结构用于执行根据一个实施例的操作。在一个实施例中,追踪高速缓存230接受经解码的微操作,并将它们组装为程序有序序列或微操作队列234中的踪迹,以用于执行。当追踪高速缓存230遇到复杂指令时,微代码rom232提供完成操作所需的微操作。
一些指令被转换为单个微操作,而其他指令需要若干个微操作以完成整个操作。在一个实施例中,如果需要超过四个微操作来完成指令,则解码器228访问微代码rom232以进行该指令。对于一个实施例,指令可被解码为少量的微操作以用于在指令解码器228处进行处理。在另一个实施例中,如果需要若干微操作来完成操作,则可将指令存储在微代码rom232中。追踪高速缓存230参考进入点可编程逻辑阵列(pla)来确定正确的微指令指针,以从微代码rom232读取微代码序列以完成根据一个实施例的一个或多个指令。在微代码rom232完成对于指令的微操作序列化之后,机器的前端201恢复从追踪高速缓存230取出微操作。
无序执行引擎203是将指令准备好用于执行的单元。无序执行逻辑具有若干个缓冲器,用于将指令流平滑并且重排序,以优化指令流进入流水线后的性能,并调度指令流以供执行。分配器逻辑分配每个微操作需要的机器缓冲器和资源,以用于执行。寄存器重命名逻辑将诸个逻辑寄存器重命名为寄存器组中的条目。在指令调度器(存储器调度器、快速调度器202、慢速/通用浮点调度器204、简单浮点调度器206)之前,分配器也将每个微操作的条目分配入两个微操作队列中的一个,一个队列用于存储器操作,另一个队列用于非存储器操作。微操作调度器202、204、206基于对它们的依赖输入寄存器操作数源的准备就绪以及微操作完成它们的操作所需的执行资源的可用性来确定微操作何时准备好用于执行。一个实施例的快速调度器202可在主时钟周期的每半个上进行调度,而其他调度器可仅仅在每个主处理器时钟周期上调度一次。调度器对分配端口进行仲裁以调度微操作以便执行。
寄存器组208、210位于调度器202、204、206和执行块211中的执行单元212、214、216、218、220、222、224之间。也存在单独的寄存器组208、210,分别用于整数和浮点操作。一个实施例的每个寄存器组208、210也包括旁路网络,旁路网络可将刚完成的还没有被写入寄存器组的结果旁路或转发给新的依赖微操作。整数寄存器组208和浮点寄存器组210也能够彼此通信数据。对于一个实施例,整数寄存器组208被划分为两个单独的寄存器组,一个寄存器组用于低阶的32位数据,第二个寄存器组用于高阶的32位数据。一个实施例的浮点寄存器组210具有128位宽度的条目,因为浮点指令通常具有从64至128位宽度的操作数。
执行块211包括执行单元212、214、216、218、220、222、224,在执行单元212、214、216、218、220、222、224中实际执行指令。该区块包括寄存器组208、210,寄存器组208、210存储微指令需要执行的整数和浮点数据操作数值。一个实施例的处理器200由多个执行单元组成:地址产生单元(agu)212、agu214、快速alu(算术逻辑单元)216、快速alu218、慢速alu220、浮点alu222、浮点移动单元224。对于一个实施例,浮点执行块222、224执行浮点、mmx、simd、sse以及其他操作。一个实施例的浮点alu222包括64位/64位浮点除法器,用于执行除法、平方根、以及余数微操作。对于本发明的诸个实施例,涉及浮点值的指令可使用浮点硬件来处理。在一个实施例中,alu操作进入高速alu执行单元216、218。一个实施例的高速alu216、218可执行高速操作,有效等待时间为半个时钟周期。对于一个实施例,大多数复杂整数操作进入慢速alu220,因为慢速alu220包括用于长等待时间类型操作的整数执行硬件,诸如,乘法器、移位器、标记逻辑和分支处理。存储器加载/存储操作由agu212、214来执行。对于一个实施例,整数alu216、218、220被描述为对64位数据操作数执行整数操作。在替换实施例中,alu216、218、220可被实现为支持大范围的数据位,包括16、32、128、256等等。类似地,浮点单元222、224可被实现为支持具有多种宽度的位的操作数范围。对于一个实施例,浮点单元222、224可结合simd和多媒体指令对128位宽度打包数据操作数进行操作。
在一个实施例中,在父加载完成执行之前,微操作调度器202、204、206就分派依赖操作。因为在处理器200中微操作被投机地调度和执行,所以处理器200也包括处理存储器未命中的逻辑。如果数据加载在数据高速缓存中未命中,则可能存在带有临时错误数据离开调度器并运行在流水线中的依赖操作。重放机制跟踪使用错误数据的指令,并重新执行这些指令。仅仅依赖操作需要被重放,而允许独立操作完成。处理器的一个实施例的调度器和重放机制也被设计为捕捉提供掩码寄存器与通用寄存器之间的转换的指令。
术语“寄存器”指代被用作为指令的一部分以标识操作数的板上处理器存储位置。换句话说,寄存器是那些处理器外部(从编程者的角度来看)可用的处理器存储位置。然而,一实施例的寄存器不限于表示特定类型的电路。相反,一实施例的寄存器能够存储并提供数据,并且能够执行在此所述的功能。在此所述的寄存器可由处理器中的电路使用任何数量不同技术来实现,诸如,专用物理寄存器、使用寄存器重命名的动态分配物理寄存器、专用和动态分配物理寄存器的组合,等等。在一个实施例中,整数寄存器存储三十二位整数数据。一个实施例的寄存器组也包含八个多媒体simd寄存器,用于打包数据。对于以下讨论,寄存器应被理解为设计成保存打包数据的数据寄存器,诸如来自美国加利福尼亚州圣克拉拉市的英特尔公司的启用了mmx技术的微处理器的64位宽mmxtm寄存器(在一些实例中也称为“mm寄存器)。”这些mmx寄存器(可用在整数和浮点格式中)可与伴随simd和sse指令的打包数据元素一起操作。类似地,涉及sse2、sse3、sse4或更新的技术(统称为“ssex”)的128位宽xmm寄存器也可被用于保持这样打包数据操作数。在一个实施例中,在存储打包数据和整数数据时,寄存器不需要区分这两类数据类型。在一个实施例中,整数和浮点数据可被包括在相同的寄存器组中,或被包括在不同的寄存器组中。进一步的,在一个实施例中,浮点和整数数据可被存储在不同的寄存器中,或被存储在相同的寄存器中。
在下述附图的示例中,描述了多个数据操作数。图3a示出根据本发明的一个实施例的多媒体寄存器中的多种打包数据类型表示。图3a示出了打包字节310、打包字320、打包双字(dword)330的用于128位宽操作数的数据类型。本示例的打包字节格式310是128位长,并且包含十六个打包字节数据元素。字节在此被定义为是8位数据。每一个字节数据元素的信息被存储为:对于字节0存储在位7到位0,对于字节1存储在位15到位8,对于字节2存储在位23到位16,最后对于字节15存储在位120到位127。因此,在该寄存器中使用了所有可用的位。该存储配置提高了处理器的存储效率。同样,因为访问了十六个数据元素,所以现在可对十六个数据元素并行地执行一个操作。
通常,数据元素是单独的数据片,与具有相同长度的其他数据元素一起存储在单个寄存器或存储器位置中。在涉及ssex技术的打包数据序列中,存储在xmm寄存器中的数据元素的数目是128位除以单个数据元素的位长。类似地,在涉及mmx和sse技术的打包数据序列中,存储在mmx寄存器中的数据元素的数目是64位除以单个数据元素的位长。虽然图3a中所示的数据类型是128位长,但本发明的诸个实施例也可操作64位宽、256位宽、512位宽或其他尺寸的操作数。本示例的打包字格式320是128位长,并且包含八个打包字数据元素。每个打包字包含十六位的信息。图3a的打包双字格式330是128位长,并且包含四个打包双字数据元素。每个打包双字数据元素包含三十二位信息。打包四字是128位长,并包含两个打包四字数据元素。
图3b示出了替代的寄存器内数据存储格式。每个打包数据可包括超过一个独立数据元素。示出了三个打包数据格式:打包半数据元素314、打包单数据元素342、以及打包双数据元素343。打包半数据元素341、打包单数据元素342、打包双数据元素343的一个实施例包含定点数据元素。对于替代实施例,一个或多个打包半数据元素341、打包单数据元素342、打包双数据元素343可包含浮点数据元素。打包半数据元素341的一个替代实施例是一百二十八位长度,包含八个16位数据元素。打包单数据元素342的一个替代实施例是一百二十八位长度,且包含四个32位数据元素。打包双数据元素343的一个实施例是一百二十八位长度,且包含两个64位数据元素。可以理解的是,这样的打包数据格式进一步可被扩展至其他寄存器长度,例如,96位、160位、192位、224位、256位、512位或更长。
图3c示出了根据本发明的一个实施例的多媒体寄存器中的多种有符号和无符号打包数据类型表示。无符号打包字节表示344示出了simd寄存器中的无符号打包字节的存储。每一个字节数据元素的信息被存储为:对于字节0存储在位7到位0,对于字节1存储在位15到位8,对于字节2存储在位23到位16,等等,最后对于字节15存储在位120到位127。因此,在该寄存器中使用了所有可用的位。该存储配置可提高处理器的存储效率。同样,因为访问了十六个数据元素,所以可对十六个数据元素并行地执行一个操作。有符号打包字节表示345示出了有符号打包字节的存储。注意到,每个字节数据元素的第八位是符号指示符。无符号打包字表示346示出了simd寄存器中字7到字0如何被存储。有符号打包字表示347类似于无符号打包字寄存器内表示346。注意到,每个字数据元素的第十六位是符号指示符。无符号打包双字表示348示出了双字数据元素如何存储。有符号打包双字表示349类似于无符号打包双字寄存器内表示348。注意到,必要的符号位是每个双字数据元素的第三十二位。
图3d是与可从美国加利福尼亚州圣克拉拉市的英特尔公司的万维网intel.com/products/processor/manuals/上获得的“
图3e示出了具有四十个或更多位的另一个替代操作编码(操作码)格式370。操作码格式370对应于操作码格式360,并包括可选的前缀字节378。根据一个实施例的指令可通过字段378、371和372中的一个或多个来编码。通过源操作数标识符374和375以及通过前缀字节378,可标识每个指令中高达两个操作数位置。对于一个实施例,前缀字节378可被用于标识32位或64位的源和目的地操作数。对于一个实施例,目的地操作数标识符376与源操作数标识符374相同,而在其他实施例中它们不相同。对于替代实施例,目的地操作数标识符376与源操作数标识符375相同,而在其他实施例中它们不相同。在一个实施例中,指令对由操作数标识符374和375所标识的一个或多个操作数进行操作,并且由操作数标识符374和375所标识的一个或多个操作数被指令的结果所覆写,然而在其他实施例中,由标识符374和375所标识的操作数被写入另一个寄存器中的另一个数据元素中。操作码格式360和370允许由mod字段363和373以及由可选的比例-变址-基址(scale-index-base)和位移(displacement)字节所部分指定的寄存器到寄存器寻址、存储器到寄存器寻址、由存储器对寄存器寻址、由寄存器对寄存器寻址、直接对寄存器寻址、寄存器至存储器寻址。
接下来转到图3f,在一些替换实施例中,64位(或128位、或256位、或512位或更多)单指令多数据(simd)算术操作可经由协处理器数据处理(cdp)指令来执行。操作编码(操作码)格式380示出了一个这样的cdp指令,其具有cdp操作码字段382和389。对于替代实施例,该类型cdp指令操作可由字段383、384、387和388中的一个或多个来编码。可以对每个指令标识高达三个操作数位置,包括高达两个源操作数标识符385和390以及一个目的地操作数标识符386。协处理器的一个实施例可对8、16、32和64位值操作。对于一个实施例,对整数数据元素执行指令。在一些实施例中,使用条件字段381,可有条件地执行指令。对于一些实施例,源数据尺寸可通过字段383来编码。在一些实施例中,可对simd字段执行零(z)、负(n)、进位(c)和溢出(v)检测。对于一些指令,饱和类型可通过字段384来编码。
接下来转到图3g,其描绘了根据另一实施例的与可从美国加利福尼亚州圣克拉拉市的英特尔公司的万维网(www)intel.com/products/processor/manuals/上获得的“
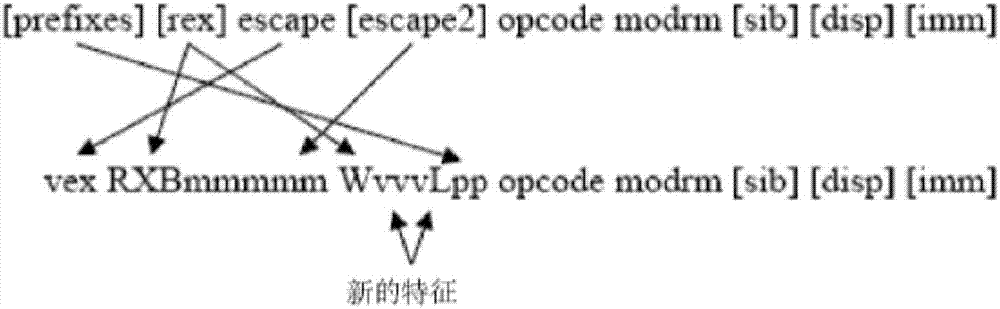
原始x86指令集向1字节操作码提供多种地址字节(syllable)格式以及包含在附加字节中的直接操作数,其中可从第一个“操作码”字节中获知附加字节的存在。此外,特定字节值被预留给操作码作为修改符(称为前缀prefix,因为它们被放置在指令之前)。当256个操作码字节的原始配置(包括这些特殊前缀值)耗尽时,指定单个字节以跳出(escape)到新的256个操作码集合。因为添加了向量指令(诸如,simd),即便通过使用前缀进行了扩展以后,也需要产生更多的操作码,并且“两字节”操作码映射也已经不够。为此,将新指令加入附加的映射中,附加的映射使用两字节加上可选的前缀作为标识符。
除此外,为了便于在64位模式中实现额外的寄存器,在前缀和操作码(以及任何的用于确定操作码所需的跳出字节)之间使用额外的前缀(被称为“rex”)。在一个实施例中,rex具有4个“有效载荷”位,以指示在64位模式中使用附加的寄存器。在其他实施例中,可具有比4位更少或更多的位。至少一个指令集的通用格式(一般对应于格式360和/或格式370)被一般地示出如下:
[prefixes][rex]escape[escape2]opcodemodrm(等等)
操作码格式397对应于操作码格式370,并包括可选的vex前缀字节391(在一个实施例中,以十六进制的c4或c5开始)以替换大部分的其他公共使用的传统指令前缀字节和跳出代码。例如,图17示出了使用两个字段来编码指令的实施例,其可在原始指令中不存在第二跳出代码时使用。在图17所示的实施例中,传统跳出由新的跳出值所表示,传统前缀被完全压缩为“有效载荷(payload)”字节的一部分,传统前缀被重新申明并可用于未来的扩展,并且加入新的特征(诸如,增加的向量长度以及额外的源寄存器区分符)。
当原始指令中存在第二跳出代码时,或当需要使用rex字段中的额外的位(例如xb和w字段)时。在图18示出的替代实施例中,将第一传统跳出和传统前缀按照上述类似地压缩,并且将第二跳出代码压缩在“映射”字段中,在未来映射或特征空间可用的情况下,重新添加新的特征(例如增加的向量长度和附加的源寄存器区分符)。
根据一个实施例的指令可通过字段391和392中的一个或多个来编码。通过字段391与源操作码标识符374和375以及可选的比例-变址-基址(scale-index-base,sib)标识符393、可选位移标识符394以及可选直接字节395相结合,可以为每个指令标识高达四个操作数位置。对于一个实施例,vex前缀字节391可被用于标识32位或64位的源和目的地操作数和/或128位或256位simd寄存器或存储器操作数。对于一个实施例,由操作码格式397所提供的功能可与操作码格式370形成冗余,而在其他实施例中它们不同。操作码格式370和397允许由mod字段373以及由可选的sib标识符393、可选的位移标识符394以及可选的直接字节395所部分指定的寄存器到寄存器寻址、存储器到寄存器寻址、由存储器对寄存器寻址、由寄存器对寄存器寻址、直接对寄存器寻址、寄存器至存储器寻址。
现在转到图3h,其描绘了根据另一实施例的用于提供向量混合和置换功能的另一替代操作编码(操作码)格式398。操作码格式398对应于操作码格式370和397,并包括可选的evex前缀字节396(在一个实施例中,以十六进制的62开始)以替换大部分的其他公共使用的传统指令前缀字节和跳出代码,并提供附加的功能。根据一个实施例的指令可通过字段396和392中的一个或多个来编码。通过字段396与源操作码标识符374和375以及可选的比例-变址-基址(scale-index-base,sib)标识符393、可选的位移标识符394以及可选的直接字节395相结合,可以标识每个指令高达四个操作数位置和掩码。对于一个实施例,evex前缀字节396可被用于标识32位或64位的源和目的地操作数和/或128位、256位或512位simd寄存器或存储器操作数。对于一个实施例,由操作码格式398所提供的功能可与操作码格式370或397形成冗余,而在其他实施例中它们不同。操作码格式398允许由mod字段373以及由可选的(sib)标识符393、可选的位移标识符394以及可选的直接字节395所部分指定的利用掩码的寄存器到寄存器寻址、存储器到寄存器寻址、由存储器对寄存器寻址、由寄存器对寄存器寻址、直接对寄存器寻址、寄存器至存储器寻址。至少一个指令集的通用格式(一般对应于格式360和/或格式370)被一般地示出如下:
evexlrxbmmmmmwvvvlppevex4opcodemodrm[sib][disp][imm].
对于一个实施例,根据evex格式398来编码的指令可具有额外的“荷载”位,其被用于提供掩码寄存器与通用寄存器之间的转换,并具有附加的新特征,诸如例如,用户可配置掩码寄存器、附加的操作数、从128位、256位或512位向量寄存器或待选择的更多的寄存器中的选择、等等。
例如,vex格式397或evex格式398可用于提供向量混合和置换功能。此外,对于128位、256位、512位或更大(或更小)的向量寄存器,vex格式397或evex格式398可用于提供向量混合和置换功能。
通过以下示例示出用于提供向量混合和置换功能的示例指令:
此类指令对于需要在向量寄存器中进行重排以应用所期望的存储器和/或simd算术操作的方式所存储和/或存在的数据可能有用,例如处于未对齐地址的数据、或处于两个相应高速缓存行的末尾和开始处的数据、或在表的不同条目中的数据、或在图像中跨越块边界的数据,等等,通过提供向量混合和置换功能的指令和逻辑可在向量寄存器中高效地重新安排这些数据。
图4a是示出根据本发明的至少一个实施例的有序流水线以及寄存器重命名级、无序发布/执行流水线的框图。图4b是示出根据本发明的至少一个实施例的要被包括在处理器中的有序体系结构核以及寄存器重命名逻辑、无序发布/执行逻辑的框图。图4a中的实线框示出了有序流水线,虚线框示出了寄存器重命名、无序发布/执行流水线。类似地,图4b中的实线框示出了有序体系结构逻辑,而虚线框示出了寄存器重命名逻辑以及无序发布/执行逻辑。
在图4a中,处理器流水线400包括取出级402、长度解码级404、解码级406、分配级408、重命名级410、调度(也称为分派或发布)级412、寄存器读/存储器读级414、执行级416、写回/存储器写级418、异常处理级422和提交级424。
在图4b中,箭头指示两个或更多个单元之间的耦合,且箭头的方向指示那些单元之间的数据流的方向。图4b示出了包括耦合到执行引擎单元450的前端单元430的处理器核490,且执行引擎单元和前端单元两者都耦合到存储器单元470。
核490可以是精简指令集计算(risc)核、复杂指令集计算(cisc)核、超长指令字(vliw)核或混合或替代核类型。作为另一个选项,核490可以是专用核,诸如网络或通信核、压缩引擎、图形核或类似物。
前端单元430包括耦合到指令高速缓存单元434的分支预测单元432,该指令高速缓存单元434被耦合到指令翻译后备缓冲器(tlb)436,该指令翻译后备缓冲器436被耦合到指令取出单元438,指令取出单元438被耦合到解码单元440。解码单元或解码器可解码指令,并生成一个或多个微操作、微代码进入点、微指令、其他指令、或其他控制信号作为输出,这些输出是从原始指令中解码出、或以其他方式反映原始指令、或是从原始指令中推导而出的。解码器可以使用各种不同的机制来实现。合适的机制的示例包括但不限于:查找表、硬件实现、可编程逻辑阵列(pla)、微代码只读存储器(rom)等等。指令高速缓存单元434进一步耦合至存储器单元470中的第二级(l2)高速缓存单元476。解码单元440耦合至执行引擎单元450中的重命名/分配器单元452。
执行引擎单元450包括重命名/分配器单元452,该重命名/分配器单元452耦合至引退单元454和一个或多个调度器单元456的集合。调度器单元456表示任何数目的不同调度器,包括预留站、中央指令窗等。调度器单元456被耦合到物理寄存器组单元458。物理寄存器组单元458中的每一个表示一个或多个物理寄存器组,其中不同的物理寄存器组存储一个或多个不同的数据类型(诸如标量整数、标量浮点、打包整数、打包浮点、向量整数、向量浮点、等等)、状态(诸如,指令指针是将要被执行的下一个指令的地址)等等。物理寄存器组单元458被引退单元454所覆盖,以示出可实现寄存器重命名和无序执行的多种方式(诸如,使用重排序缓冲器和引退寄存器组、使用未来文件(futurefile)、历史缓冲器、引退寄存器组、使用寄存器映射和寄存器池等等)。通常,体系结构寄存器从处理器外部或从编程者的视角来看是可见的。这些寄存器不限于任何已知的特定电路类型。多种不同类型的寄存器可适用,只要它们能够存储并提供在此所述的数据。合适的寄存器的示例包括但不限于:专用物理寄存器、使用寄存器重命名的动态分配物理寄存器、专用物理寄存器和动态分配物理寄存器的组合等等。引退单元454和物理寄存器组单元458耦合至执行群集460。执行群集460包括一个或多个执行单元462的集合和一个或多个存储器访问单元464的集合。执行单元462可以执行各种操作(例如,移位、加法、减法、乘法),以及对各种类型的数据(例如,标量浮点、打包整数、打包浮点、向量整型、向量浮点)执行。尽管某些实施例可以包括专用于特定功能或功能集合的多个执行单元,但其他实施例可包括全部执行所有函数的仅一个执行单元或多个执行单元。调度器单元456、物理寄存器组单元458、执行群集460被示出为可能是复数个,因为某些实施例为某些数据/操作类型创建了诸个单独流水线(例如,均具有各自调度器单元、物理寄存器组单元和/或执行群集的标量整数流水线、标量浮点/打包整数/打包浮点/向量整数/向量浮点流水线、和/或存储器访问流水线,以及在单独的存储器访问流水线的情况下特定实施例被实现为仅仅该流水线的执行群集具有存储器访问单元464)。还应当理解,在分开的流水线被使用的情况下,这些流水线中的一个或多个可以为无序发布/执行,并且其余流水线可以为有序发布/执行。
存储器访问单元464的集合被耦合到存储器单元470,该存储器单元470包括耦合到数据高速缓存单元474的数据tlb单元472,其中数据高速缓存单元474耦合到二级(l2)高速缓存单元476。在一个示例性实施例中,存储器访问单元464可包括加载单元、存储地址单元和存储数据单元,其中的每一个均耦合至存储器单元470中的数据tlb单元472。l2高速缓存单元476被耦合到一个或多个其他级的高速缓存,并最终耦合到主存储器。
作为示例,示例性寄存器重命名的、无序发布/执行核体系结构可以如下实现流水线400:1)指令取出438执行取出和长度解码级402和404;2)解码单元440执行解码级406;3)重命名/分配器单元452执行分配级408和重命名级410;4)调度器单元456执行调度级412;5)物理寄存器组单元458和存储器单元470执行寄存器读取/存储器读取级414;执行群集460执行执行级416;6)存储器单元470和物理寄存器组单元458执行写回/存储器写入级418;7)各单元可牵涉到异常处理级422;以及8)引退单元454和物理寄存器组单元458执行提交级424。
核490可支持一个或多个指令集(诸如,x86指令集(具有增加有更新版本的一些扩展)、加利福尼亚州桑尼威尔的mips技术公司的mips指令集、加利福尼亚州桑尼威尔的arm控股公司的arm指令集(具有可选附加扩展,诸如neon))。
应当理解,核可支持多线程化(执行两个或更多个并行的操作或线程的集合),并且可以按各种方式来完成该多线程化,此各种方式包括时分多线程化、同步多线程化(其中单个物理核为物理核正同步多线程化的各线程中的每一个线程提供逻辑核)、或其组合(例如,时分取出和解码以及此后诸如用
尽管在无序执行的上下文中描述了寄存器重命名,但应当理解,可以在有序体系结构中使用寄存器重命名。虽然处理器的所示出的实施例也包括单独的指令和数据高速缓存单元434/474以及共享的l2高速缓存单元476,但替代的实施例也可具有用于指令和数据的单个内部高速缓存,诸如例如第一级(l1)内部高速缓存、或多个级别的内部高速缓存。在某些实施例中,该系统可包括内部高速缓存和在核和/或处理器外部的外部高速缓存的组合。或者,所有高速缓存都可以在核和/或处理器的外部。
图5是根据本发明的实施例的单核处理器和多核处理器500的框图,具有集成的存储器控制器和图形器件。图5的实线框示出了处理器500,处理器500具有单个核502a、系统代理510、一组一个或多个总线控制器单元516,而可选附加的虚线框示出了替代的处理器500,其具有多个核502a-n、位于系统代理单元510中的一组一个或多个集成存储器控制器单元514以及集成图形逻辑508。
存储器层次结构包括在各核内的一个或多个级别的高速缓存、一个或多个共享高速缓存单元506的集合、以及耦合至集成存储器控制器单元514的集合的外部存储器(未示出)。该共享高速缓存单元506的集合可以包括一个或多个中间级高速缓存,诸如二级(l2)、三级(l3)、四级(l4)或其他级别的高速缓存、末级高速缓存(llc)、和/或其组合。虽然在一个实施例中基于环形的互连单元512将集成图形逻辑508、该组共享高速缓存单元506和系统代理单元510进行互连,但替代的实施例也使用任何数量的公知技术来互连这些单元。
在一些实施例中,核502a-n中的一个或多个核能够多线程化。系统代理510包括协调和操作核502a-n的那些组件。系统代理单元510可包括例如功率控制单元(pcu)和显示单元。pcu可以是或包括调整核502a-n和集成图形逻辑508的功率状态所需的逻辑和组件。显示单元用于驱动一个或多个外部连接的显示器。
核502a-n可以是在体系结构和/或指令集上同构的或异构的。例如,核502a-n中的一些可以是有序的,而另一些是无序的。如另一个示例,核502a-n中的两个或多个核能够执行相同的指令集,而其他核能够执行该指令集中的一个子集或执行不同的指令集。
处理器可以是通用功能处理器,诸如酷睿(coretm)i3、i5、i7、2duo和quad、至强(xeontm)、安腾(itaniumtm)、xscaletm或strongarmtm处理器,这些均可以从加利福尼亚圣克拉拉市的intel公司获得。或者,处理器可以来自另一个公司,诸如来自arm控股公司、mips、等等。处理器可以是专用处理器,诸如,例如,网络或通信处理器、压缩引擎、图形处理器、协处理器、嵌入式处理器、或类似物。该处理器可以被实现在一个或多个芯片上。处理器500可以是一个或多个衬底的一部分,和/或可以使用诸如例如bicmos、cmos或nmos等的多个加工技术中的任何一个技术将其实现在一个或多个衬底上。
图6-8是适于包括处理器500的示例性系统,图9是可包括一个或多个核502的示例性芯片上系统(soc)。本领域已知的对膝上型设备、台式机、手持pc、个人数字助理、工程工作站、服务器、网络设备、网络集线器、交换机、嵌入式处理器、数字信号处理器(dsp)、图形设备、视频游戏设备、机顶盒、微控制器、蜂窝电话、便携式媒体播放器、手持设备以及各种其他电子设备的其他系统设计和配置也是合适的。一般来说,能够纳入本文中所公开的处理器和/或其它执行逻辑的大量系统和电子设备一般都是合适的。
现在参考图6,所示出的是根据本发明一个实施例的系统600的框图。系统600可包括耦合至图形存储器控制器中枢(gmch)620的一个或多个处理器610、615。附加处理器615的可选性质用虚线表示在图6中。
每个处理器610、615可以是处理器500的某些版本。然而,应该理解,集成图形逻辑和集成存储器控制单元不太可能出现在处理器610、615中。图6示出gmch620可耦合至存储器640,该存储器640可以是例如动态随机存取存储器(dram)。对于至少一个实施例,dram可以与非易失性缓存相关联。
gmch620可以是芯片组或芯片组的一部分。gmch620可以与(多个)处理器610、615进行通信,并控制处理器610、615与存储器640之间的交互。gmch620还可担当(多个)处理器610、615和系统600的其它元件之间的加速总线接口。对于至少一个实施例,gmch620经由诸如前端总线(fsb)695之类的多站总线与(多个)处理器610、615进行通信。
此外,gmch620耦合至显示器645(诸如平板显示器)。gmch620可包括集成图形加速器。gmch620还耦合至输入/输出(i/o)控制器中枢(ich)650,该输入/输出(i/o)控制器中枢(ich)650可用于将各种外围设备耦合至系统600。在图6的实施例中作为示例示出了外部图形设备660以及另一外围设备670,该外部图形设备660可以是耦合至ich650的分立图形设备。
替代地,系统600中还可存在附加或不同的处理器。例如,附加(多个)处理器615可包括与处理器610相同的附加(多个)处理器、与处理器610异类或不对称的附加(多个)处理器、加速器(诸如图形加速器或数字信号处理(dsp)单元)、现场可编程门阵列或任何其它处理器。按照包括体系结构、微体系结构、热、功耗特征等等优点的度量谱,物理资源610、615之间存在各种差别。这些差别会有效显示为处理器610、615之间的不对称性和异类性。对于至少一个实施例,各种处理器610、615可驻留在同一管芯封装中。
现在参照图7,所示出的是根据本发明实施例的第二系统700的框图。如图7所示,多处理器系统700是点对点互连系统,并包括经由点对点互连750耦合的第一处理器770和第二处理器780。处理器770和780中的每一个可以是处理器500的一些版本,如处理器610、615中的一个或多个一样。
虽然仅以两个处理器770、780来示出,但应理解本发明的范围不限于此。在其它实施例中,在给定处理器中可存在一个或多个附加处理器。
处理器770和780被示为分别包括集成存储器控制器单元772和782。处理器770还包括作为其总线控制器单元的一部分的点对点(p-p)接口776和778;类似地,第二处理器780包括点对点接口786和788。处理器770、780可以使用点对点(p-p)电路778、788经由p-p接口750来交换信息。如图7所示,imc772和782将各处理器耦合至相应的存储器,即存储器732和存储器734,这些存储器可以是本地附连至相应的处理器的主存储器的一部分。
处理器770、780各自可使用点对点接口电路776、794、786、798经由单独的p-p接口752、754与芯片组790交换信息。芯片组790还可经由高性能图形接口739与高性能图形电路738交换信息。
共享高速缓存器(未示出)可以被包括在任一处理器中或者两个处理器的外面,通过p-p互连,与处理器相连接,以便如果处理器被置于低功率模式下,处理器中的任何一个或两者的本地缓存信息可以存储在共享高速缓存器中。
芯片组790可经由接口796耦合至第一总线716。在一个实施例中,第一总线716可以是外围部件互连(pci)总线,或诸如pciexpress总线或其它第三代i/o互连总线之类的总线,但本发明的范围并不受此限制。
如图7所示,各种i/o设备714可以连同总线桥718耦合到第一总线716,总线桥718将第一总线716耦合至第二总线720。在一个实施例中,第二总线720可以是低引脚数(lpc)总线。在一个实施例中,多个设备可以耦合到第二总线720,包括例如键盘和/或鼠标722、通信设备727以及可以包括指令/代码和数据730的存储单元728(诸如盘驱动器或其它海量存储设备)。进一步地,音频i/o724可以耦合到第二总线720。注意,其它体系结构是可能的。例如,取代图7的点对点体系结构,系统可以实现多站总线或其它这类体系结构。
现在参照图8,所示出的是根据本发明实施例的第三系统800的框图。图7和8中的类似元件使用类似附图标记,且在图8中省略了图7的某些方面以避免混淆图8的其它方面。
图8示出了处理器870、880可以分别包括集成的存储器和i/o控制逻辑(“cl”)872和882。对于至少一个实施例,cl872、882可包括诸如以上联系图5和7所描述的集成存储器控制器单元。此外。cl872、882还可包括i/o控制逻辑。图8示出不仅存储器832、834耦合至cl872、882,而且i/o设备814也耦合至控制逻辑872、882。传统i/o设备815被耦合至芯片组890。
现在参照图9,所示出的是根据本发明一个实施例的soc900的框图。在图5中,相似的部件具有同样的附图标记。另外,虚线框是更先进的soc的可选特征。在图9中,互连单元902被耦合至:应用处理器910,包括一个或多个核502a-n的集合和共享高速缓存单元506;系统代理单元510;总线控制器单元516;集成存储器控制器单元514;一个或多个媒体处理器920的集合,可包括集成图形逻辑508、用于提供静态和/或视频照相机功能的图像处理器924、用于提供硬件音频加速的音频处理器926、以及用于提供视频编码/解码加速的视频处理器928;静态随机存取存储器(sram)单元930;直接存储器存取(dma)单元932;以及显示单元940,用于耦合至一个或多个外部显示器。
图10示出处理器,包括中央处理单元(cpu)和图形处理单元(gpu),可执行根据一个实施例的至少一个指令。在一个实施例中,执行根据至少一个实施例的操作的指令可由cpu来执行。在另一个实施例中,指令可以由gpu来执行。在还有一个实施例中,指令可以由gpu和cpu所执行的操作的组合来执行。例如,在一个实施例中,根据一个实施例的指令可被接收,并被解码用于在gpu上执行。然而,经解码的指令中的一个或多个操作可由cpu来执行,并且结果被返回给gpu用于指令的最终引退。相反,在一些实施例中,cpu可作为主处理器,而gpu作为协处理器。
在一些实施例中,受益于高度并行吞吐量的指令可由gpu来执行,而受益于处理器(这些处理器受益于深度流水线体系结构)的性能的指令可由cpu来执行。例如,图形、科学应用、金融应用以及其他并行工作负荷可受益于gpu的性能并相应地执行,而更多的序列化应用,诸如操作系统内核或应用代码更适于cpu。
在图10中,处理器1000包括:cpu1005、gpu1010、图像处理器1015、视频处理器1020、usb控制器1025、uart控制器1030、spi/sdio控制器1035、显示设备1040、高清晰度多媒体接口(hdmi)控制器1045、mipi控制器1050、闪存存储器控制器1055、双数据率(ddr)控制器1060、安全引擎1065、i2s/i2c(集成跨芯片声音/跨集成电路)接口1070。其他逻辑和电路可被包括在图10的处理器中,包括更多的cpu或gpu以及其他外围设备接口控制器。
至少一个实施例的一个或多个方面可以由存储在机器可读介质上的代表性数据来实现,该数据表示处理器中的各种逻辑,其在被机器读取时使得该机器生成执行本文描述的技术的逻辑。此类表示即所谓“ip核”可以存储在有形的机器可读介质(“磁带”)上并提供给各种顾客或制造商,以加载到实际制作该逻辑或处理器的编制机器中去。例如,ip核(诸如由arm控股公司所开发的cortextm处理器族以及由中国科学院计算机技术研究所(ict)所开发的龙芯ip核)可被授权或销售给多个客户或受许可方,诸如德州仪器、高通、苹果、或三星,并被实现在由这些客户或受许可方所制造的处理器中。
图11示出根据一个实施例的ip核开发的框图。存储器1130包括模拟软件1120和/或硬件或软件模型1110。在一个实施例中,表示ip核设计的数据可经由存储器1140(诸如,硬盘)、有线连接(诸如,互联网)1150或无线连接1160而被提供给存储器1130。由模拟工具和模型所生成的ip核信息可随后被发送给制造工厂,在制造工厂可由第三方来进行生产以执行根据至少一个实施例的至少一个指令。
在一些实施例中,一个或多个指令可以对应于第一类型或体系结构(例如x86),并且在不同类型或体系结构的处理器(例如arm)上被转换或仿真。根据一个实施例,指令可以在任何处理器或处理器类型上执行,包括arm、x86、mips、gpu或其它处理器类型或体系结构。
图12示出了根据一个实施例的第一类型的指令如何被不同类型的处理器所仿真。在图12中,程序1205包含一些指令,这些指令可执行与根据一个实施例的指令相同或基本相同的功能。然而,程序1205的指令可以是与处理器1215所不同或不兼容的类型和/或格式,这意味着程序1205中的类型的指令不能原生地被处理器1215所执行。然而,借助于仿真逻辑1210,程序1205的指令可被转换成能够由处理器1215所原生执行的指令。在一个实施例中,仿真逻辑被具体化在硬件中。在另一实施例中,仿真逻辑具体化在有形的机器可读介质中,该机器可读介质包含将程序1205中的该类指令翻译成能由处理器1215原生执行的类型的软件。在其它实施例中,仿真逻辑是固定功能或可编程硬件和存储在有形的机器可读介质上的程序的组合。在一个实施例中,处理器包含仿真逻辑,但在其它实施例中,仿真逻辑在处理器之外并由第三方提供。在一个实施例中,处理器能够通过执行包含在处理器中或者与之相关联的微代码或固件,加载具体化在包含软件的有形的机器可读介质中的仿真逻辑。
图13是根据本发明的各实施例的对照使用软件指令转换器将源指令集中的二进制指令转换成目标指令集中的二进制指令的框图。在所示的实施例中,指令转换器是软件指令转换器,但作为替代该指令转换器可以用软件、固件、硬件或其各种组合来实现。图13示出了用高级语言1302的程序可以使用x86编译器1304来编译,以生成可以由具有至少一个x86指令集核1316的处理器原生执行的x86二进制代码1306。具有至少一个x86指令集核1316的处理器表示任何处理器,该处理器能够通过兼容地执行或以其它方式处理(1)英特尔x86指令集核的指令集的大部分或(2)旨在具有至少一个x86指令集核的英特尔处理器上运行的应用或其它软件的目标代码版本来执行与具有至少一个x86指令集核的英特尔处理器基本相同的功能,以实现与具有至少一个x86指令集核的英特尔处理器基本相同的结果。x86编译器1304表示用于生成x86二进制代码1306(例如,对象代码)的编译器,该二进制代码1316可通过或不通过附加的链接处理在具有至少一个x86指令集核2216的处理器上执行。类似地,图13示出用高级语言1302的程序可以使用替代的指令集编译器1308来编译,以生成可以由不具有至少一个x86指令集核1314的处理器(例如具有执行加利福尼亚州桑尼维尔市的mips技术公司的mips指令集,和/或执行加利福尼亚州桑尼维尔市的arm控股公司的arm指令集的核的处理器)原生执行的替代指令集二进制代码1310。指令转换器1312被用来将x86二进制代码1306转换成可以由不具有x86指令集核1314的处理器原生执行的代码。该转换后的代码不大可能与替换性指令集二进制代码1310相同,因为能够这样做的指令转换器难以制造;然而,转换后的代码将完成一般操作并由来自替换性指令集的指令构成。因此,指令转换器1312通过仿真、模拟或任何其它过程来表示允许不具有x86指令集处理器或核的处理器或其它电子设备执行x86二进制代码1306的软件、固件、硬件或其组合。
图14示出将在用于提供向量混合和置换功能的指令的执行中使用的装置1401的一个实施例。装置1401包括:一个或多个向量寄存器的第一源操作数1413,每个向量寄存器包括数据字段用于存储向量元素1423、……、1453、1463的值;以及第二源操作数1414,具有向量元素1424、……、1454、1464。装置1401还包括用于存储一组索引的一个或多个向量寄存器的索引向量操作数1412、具有向量元素1425、……、1455、1465的一个或多个向量寄存器的目的地操作数1415、以及可选的掩码操作数1416。在索引向量操作数1412中,索引值分别具有第一源选择器部分(例如1421、……、1451、1461)和第二元素选择器部分(例如1422、……、1452、1462)。在一些实施例中,混合-置换指令指定向量元素1424、1454、1464、1425、1455、1465等等的尺寸。响应于解码混合-置换指令,来自索引向量操作数1412中的具有向量元素尺寸的数据字段的索引值的源选择器部分1421、……、1451、1461可被用于混合级1402中的向量寄存器数据字段以产生具有向量元素1427、……、1457、1467的中间向量1470,向量元素1427、……、1457、1467中的每一个是通过多路复用器1420、……、1425、1426根据具有第一值(例如0或正的符号位)或第二值(例如1或负的符号位)的相应第一源选择器部分1421、……、1451、1461从第一源操作数1413中的向量元素的具有指定尺寸的相应数据字段或从第二源操作数1414中的向量元素的相应数据字段复制而来。
装置1401包括开关1403,开关1403用于,根据第二元素选择器部分1422、……、1452、1462所提供的索引,响应于控制逻辑1433以从输入1432、……、1435、1436上的中间向量1470的向量元素1427、……、1457、1467中选择替换元素。控制逻辑1433处理第二元素选择器部分1422、……、1452、1462,从而产生控制信号1434、……、1437、1438,以将来自中间向量1470的向量元素1427、……、1457、1467的替换元素置于开关1403的输出1428、……、1458、1468之上。被掩蔽替换逻辑1404可选地分别通过多路复用器1440、……、1445、1446选择目的地操作数1415中的向量元素1425、……、1455、1465的指定尺寸的未被掩蔽的数据字段(例如根据可选的掩码操作数1416),这些数据字段将根据相应的第二元素选择器部分1422、……1452、1462提供的索引而被中间向量1470中的数据字段所替换。
因此,装置1401的实施例可用于执行提供向量混合和置换功能的指令。将理解,虽然装置1401被示为连接在一个装置中,但装置1401的多个部分(例如级1402和中间向量1470、开关1403、被掩蔽替换逻辑1404、以及操作数1412、1413、1414、1415和1416)可分布和/或彼此操作地耦合,以响应于用于提供向量混合和置换功能的指令来执行它们各自的操作。
图15示出用于提供向量混合和置换功能的过程的替代实施例的过程1501的一个实施例的流程图。过程1501和本文中公开的其他过程通过处理块来执行,处理块可包括专用硬件或可由通用机器或专用机器或其某种组合执行的软件或固件操作码。
在过程1501的处理块1510,用于提供向量混合和置换功能的指令的执行开始。在处理块1520,解码级解码混合-置换指令,该混合-置换指令指定:一个或多个向量寄存器的目的地操作数,每个向量寄存器包括用于存储向量元素的值的数据字段;向量元素的尺寸;索引向量操作数,用于存储一组索引;一个或多个向量寄存器的第一源操作数;以及第二源操作数。
在处理块1530中开始,执行级响应于经解码的混合-置换指令从索引向量操作数中具有向量元素尺寸的数据字段读取索引值,每个索引值具有第一选择器部分和第二选择器部分。在处理块1540,混合每个向量寄存器数据字段,每个向量寄存器数据字段是根据具有第一值(例如零或正的)或第二值(例如1或负的)的相应第一选择器部分从第一源操作数中的指定向量元素尺寸的相应数据字段或从第三源操作数中的向量元素的相应数据字段被复制至中间向量。在处理块1550,将目的地操作数中的具有指定向量元素尺寸的数据字段的部分(例如,可以是或可以不是由掩码确定的)替换为由相应的第二选择器部分提供索引的中间向量结果中的相应数据字段。然后,用于提供向量混合和置换功能的指令的处理在处理块1560结束。
将理解,虽然将过程1501的处理块示为按照特定顺序依序地执行,但许多操作在可能时可并行地或按照与所示不同的顺序执行。
图16示出用于提供向量混合和置换功能的过程的替代实施例的过程1601的另一实施例的流程图。在过程1601的处理块1610,用于提供向量混合和置换功能的指令的执行开始。在处理块1620,解码级解码混合-置换指令,该混合-置换指令指定:一个或多个向量寄存器的目的地操作数,每个向量寄存器包括用于存储向量元素的值的数据字段;向量元素的尺寸;掩码操作数;索引向量操作数,用于存储一组索引;一个或多个向量寄存器的第一源操作数;以及第二源操作数。
在处理块1630中开始,执行级响应于经解码的混合-置换指令,从索引向量操作数中具有向量元素尺寸的数据字段读取索引值,每个索引值具有第一源选择器部分和第二元素选择器部分。在处理块1640,混合每个向量寄存器数据字段以产生中间向量,每个向量寄存器数据字段是根据具有第一值(例如零或正的)或第二值(例如1或负的)的相应第一源选择器部分从第一源操作数中的指定向量元素尺寸的相应数据字段或从第三源操作数中的向量元素的相应数据字段复制的。在处理块1650,将目的地操作数中的具有指定向量元素尺寸的未被掩蔽的数据字段替换为由相应的第二元素选择器部分提供索引的中间向量中的相应数据字段。然后,用于提供向量混合和置换功能的指令的处理在处理块1660结束。
仍将理解,虽然将过程1601的处理块示为按照特定顺序依序地执行,但许多操作在可能时可并行地或按照与所示不同的顺序执行。
本发明的实施例涉及用于提供向量混合和置换功能的指令,其中通过此类指令可在向量寄存器中高效地重新安排那些存储在物理存储器中和/或放置方式需要在向量寄存器中进行重排以应用所期望的存储器和/或simd算术操作的数据,例如处于未对齐地址的数据、或处于两个相应高速缓存行的末尾和开始处的数据、或在表的不同条目中的数据、或在图像中跨越块边界的数据,等等。
本文公开的机制的各实施例可以被实现在硬件、软件、固件或这些实现方法的组合中。本发明的实施例可实现为在可编程系统上执行的计算机程序或程序代码,该可编程系统包括至少一个处理器、存储系统(包括易失性和非易失性存储器和/或存储元件)、至少一个输入设备以及至少一个输出设备。
可将程序代码应用至输入指令以执行本文描述的功能并产生输出信息。输出信息可以按已知方式被应用于一个或多个输出设备。为了本申请的目的,处理系统包括具有诸如例如数字信号处理器(dsp)、微控制器、专用集成电路(asic)或微处理器之类的处理器的任何系统。
程序代码可以用高级程序化语言或面向对象的编程语言来实现,以便与处理系统通信。程序代码也可以在需要的情况下用汇编语言或机器语言来实现。事实上,本文中描述的机制不仅限于任何特定编程语言的范围。在任一情形下,语言可以是编译语言或解释语言。
至少一个实施例的一个或多个方面可以由存储在机器可读介质上的代表性指令来实现,该指令表示处理器中的各种逻辑,其在被机器读取时使得该机器生成执行本文描述的技术的逻辑。被称为“ip核”的这样的表示可以存储在有形的机器可读介质中,并提供给各种客户或生产设施,以加载到实际制造逻辑或处理器的制造机器中。
此类机器可读存储介质可包括但不限于通过机器或设备制造或形成的粒子的有形排列,包括存储介质,诸如:硬盘;包括软盘、光盘、压缩盘只读存储器(cd-rom)、可重写压缩盘(cd-rw)以及磁光盘的任何其它类型的盘;诸如只读存储器(rom)之类的半导体器件;诸如动态随机存取存储器(dram)、静态随机存取存储器(sram)之类的随机存取存储器(ram);可擦除可编程只读存储器(eprom);闪存;电可擦除可编程只读存储器(eeprom);磁卡或光卡;或适于存储电子指令的任何其它类型的介质。
因此,本发明的各实施例还包括非瞬态、有形机器可读介质,该介质包含指令或包含设计数据,诸如硬件描述语言(hdl),它定义本文中描述的结构、电路、装置、处理器和/或系统特性。这些实施例也被称为程序产品。
在某些情况下,指令转换器可用来将指令从源指令集转换至目标指令集。例如,指令转换器可以变换(例如使用静态二进制变换、包括动态编译的动态二进制变换)、变形、仿真或以其它方式将指令转换成将由核来处理的一个或多个其它指令。指令转换器可以用软件、硬件、固件、或其组合实现。指令转换器可以在处理器上、在处理器外、或者部分在处理器上部分在处理器外。
因此,揭示了用于执行根据至少一个实施例的一个或多个指令的技术。虽然已经描述了特定示例实施例,并示出在附图中,可以理解到,这些实施例仅仅是示例性的且不限制本发明的翻译,并且本发明不限于所示出和所描述的特定结构和配置,因为本领域技术人员在研究了本公开文本之后可以料知到多种其他修改方式。在本技术领域中,因为发展很快且未来的进步未曾可知,本公开的诸个实施例可通过受益于技术进步而容易地获得配置和细节上的改动,而不背离本公开的原理和所附的权利要求书的范围。
- 还没有人留言评论。精彩留言会获得点赞!