一种基于物理属性的自适应行为识别方法与流程
本发明属于传感器网络领域,尤其涉及一种基于物理属性的自适应行为识别方法。
背景技术:
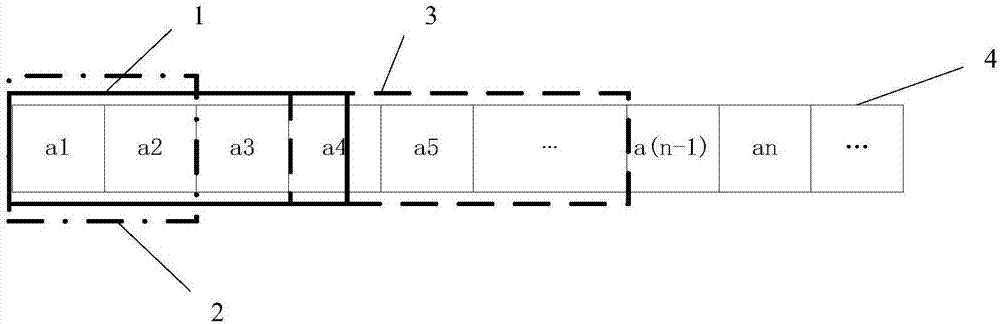
:近年来,随着物联网技术和信息科学技术的飞速发展,人体的行为识别得到人们越来越多的重视,它是改善人们生活的一项重要技术,具有非常广泛的应用前景。传统的行为识别方法能够有效识别人体行为,但其大多是建立在一个静态模型上,对样本特征值有非常强的依赖性,而没有考虑到对个别用户的灵活适应性和动态改进,比如不同的人有不同的行为特点,一个人的走路行为可能对应于另一个人的跑步行为。所以设计一个既能适应普通大众又能对用户行为进行增量学习进而可以动态改进的行为识别系统非常重要。技术实现要素:为了克服现有的行为识别算法对个别用户缺少灵活适应性的不足,本发明提供一种对个别用户具有良好的灵活适应性、识别率较高的基于物理属性的自适应行为识别方法。本发明解决其技术问题所采用的技术方案是:一种基于物理属性的自适应行为识别方法,所述方法包括以下步骤:步骤1:样本特征值的提取,过程如下:步骤1.1:收集运动过程中的加速度数据作为训练样本;步骤1.2:利用卡尔曼滤波器滤除训练样本中的异常数据,通过滤波得到了可用的训练集,训练集中的数据分为3类,分别是加速度计x、y、z轴的数据,通过分离出每个动作周期,分别记录每个动作平均一个完整周期所需要的加速度数据个数,用以作为后期滑动窗口的大小;步骤1.3:将每个行为的一个完整动作周期所产生的三轴合成加速数据集合看做物质,基于物理属性进行特征值提取;步骤2:分类算法,过程如下:步骤2.1:选择各特征值的平均值及引力作为投票依据;步骤2.2:设计一个动态滑动窗口来处理实时数据流,将训练样本所得的每个行为动作一个周期的加速度数据个数从小到大排列好,先将滑动窗口大小设定为d,然后求取窗口内数据集合的上述物理特征,再与所训练样本的三个特征平均值的相对误差及引力大小作比较;每个特征平均值将票投给相对误差较小的一类行为,引力则将票投给引力较大的一类,投票结果选择票数最多且大于等于2票的行为;只有投票结果与所选窗口大小对应的行为一致时,该行为步数加1,滑动窗口移至下一窗口;否则将滑动窗口按上述排列结果向数据流反方向依次增大,继续判断,直至可以判断出结果。进一步,所述步骤1.2中,下楼d、上楼u、骑车c、跑步r、走路w作为后期滑动窗口的大小;步骤1.3:当行为为走路时,如走一步产生的数据集合分别为a1(x1,y1,z1)、a2(x2,y2,z2)、a3(x3,y3,z3)、…、an(xn,yn,zn),其中x、y、z分别表示三轴加速度值,n表示每组数据所包含的数据个数,然后提取以下物理特征:(1)分子量mr,定义分子量计算公式为:mr=xa+2ya+3za(1)其中(xa,ya,za)为重心,且(2)范德华力u,定义范德华力的计算公式为:其中a、b为常量且:(3)密度ρ,密度代表了行为加速度数据点分布的聚散程度,定义如下:其中m=mr×n,表示物质的质量,所述物质为一个动作周期产生的数据集合;v表示物质的体积,选择数据集合的最小外接长方体作为物质的体积,分别取x、y、z轴的最值作为长方体的顶点,设minx,miny,minz,maxx,maxy,maxz分别为x、y、z轴的最小值和最大值,则体积:v=(maxx-minx)×(maxy-miny)×(maxz-minz)(7)(4)引力f,引力f的定义如下:其中g为常量,mx为训练样本的数据质量,m为所识别数据的质量,r为两物质重心间的距离。再进一步,所述步骤2.1中,设有k组样本周期,分子量mr平均值的计算公式如下:同理,求得走路范德华力和密度的平均值所述步骤2.2中,先将滑动窗口大小设定为w,然后求取窗口内数据集合的上述物理特征,再与所训练样本的三个特征平均值的相对误差及引力大小作比较,其中相对误差δ的计算公式为:同理,求得走路范德华力和密度的相对误差。更进一步,所述步骤2.2中,如果都无法判断出结果时,将滑动窗口向数据流反方向移动w/4个窗口大小再次重复上述投票,直至可以判断出结果。所述步骤2.2中,如果移动一个周期之后仍无法判断则判定为其他动作;然后继续投票判断;其中,在票数对等的情况下,需要进一步判断,将四个特征值看做一个四维向量然后进行余弦相似度分析,判断结果判定为相似度较大的一类动作;其中余弦相似度计算公式如公式11所示:更进一步,所述方法还包括以下步骤:步骤3,增量学习,过程如下:在可以确定行为但确定性不够大时,每个行为的训练样本为k个周期,每次进行增量学习为1个行为周期,设进行增量学习的实时数据重心为(x,y,z),则重心(xa,ya,za)的更新方法如下:每进行一次增量学习,则每个行为训练样本特征值的数据重心就更新一次,随之的各物理特征也进行更新,之后的行为识别判断也将依据新的物理特征值返回到步骤1~步骤2进行投票。本发明的技术构思为:每个行为动作一个完整周期的三轴合成加速度数据集合类似物理学中的分子而整体则可看作一个物质,故可计算其物理属性作为特征值;不同行为动作一个完整周期所产生的加速度数据点个数是不同的,针对此可以设计了一个可变大小的动态滑动窗口,这样能够充分利用数据,更有效的处理实时数据流;不同的用户有不同的行为习惯,比如一个人的走路行为可能对应另一个人的跑步行为,因此可以设计一个增量学习过程来动态更新样本特征值,使其逐渐趋向于用户的行为习惯,增强识别系统的适应性。基于三轴加速度计设计了一种基于物理属性的能够对用户行为进行增量学习的自适应性行为识别算法,该算法提出了一种新的提取加速度特征的方法,通过将三轴加速度计采集到的合成加速度数据集合看做物质,来提取物质的物理特征并训练这些物理特征用于投票分类,然后再通过增量学习来更新样本特征值,使其逐渐趋向于用户的行为习惯,从而达到更高的识别率。本发明的有益效果主要表现在:能够充分利用加速度数据,使整个行为识别系统具有更好的适应性,提高系统性能,识别率较高。附图说明图1是本发明方法的流程图。图2是本发明的动态滑动窗口与数据流图,其中,1是滑动窗口,2是缩小后的滑动窗口,3是移动后的滑动窗口,4是实时数据流。具体实施方式下面结合附图对本发明作进一步详细描述。参照图1和图2,一种基于物理属性的自适应行为识别方法,包括以下步骤:步骤1:样本特征值的提取步骤1.1:首先招募8名志愿者做传统的转呼啦圈运动,将硬件佩戴在志愿者的腰部,每名志愿者每个动作做1000次,收集运动过程中的加速度数据作为训练样本,加速度计读取数据的频率为100hz。步骤1.2:首先利用卡尔曼滤波器滤除训练样本中一些异常数据,通过滤波得到了可用的训练集,训练集中的数据分为3类,分别是加速度计x、y、z轴的数据,通过分离出每个动作周期,分别记录每个动作平均一个完整周期所需要的加速度数据个数,d(下楼)、u(上楼)、c(骑车)、r(跑步)、w(走路),用以作为后期滑动窗口的大小。步骤1.3:本发明将每个行为的一个完整动作周期所产生的三轴合成加速数据集合看做物质,基于物理属性进行特征提取,以走路为例,如走一步产生的数据集合分别为a1(x1,y1,z1)、a2(x2,y2,z2)、a3(x3,y3,z3)、…、an(xn,yn,zn),其中x、y、z分别表示三轴加速度值,n表示每组数据所包含的数据个数,然后提取以下物理特征:(1)分子量mr,不同行为的一个完整动作周期产生的加速度数据个数与大小是不同的,也就是说其一组数据集的大小与位置是不同的,我们将此特性用于区别不同行为,故定义分子量计算公式为:mr=xa+2ya+3za(1)其中(xa,ya,za)为重心,且(2)范德华力u,范德华力即分子间作用力,本是存在于分子间的一种吸引力,本发明中与相邻数据点间的距离有关,因为每个行为的数据间间距不同,范德华力可以反映出该行为数据内部的关联性,用于区分其他行为,本发明定义范德华力的计算公式为:其中a、b为常量且:(3)密度ρ,密度是物质的特性之一,不同物质的密度一般是不同的,而不同的行为其加速度点的分布情况也是有差异的,本发明中密度代表了行为加速度数据点分布的聚散程度,定义如下:其中m=mr×n,表示物质(一个动作周期产生的数据集合)的质量。v表示物质的体积,我们选择数据集合的最小外接长方体作为物质的体积,分别取x、y、z轴的最值作为长方体的顶点,设minx,miny,minz,maxx,maxy,maxz分别为x、y、z轴的最小值和最大值,则体积:v=(maxx-minx)×(maxy-miny)×(maxz-minz)(7)(4)引力f,宇宙中每两个物体间都存在一种作用力,即引力。同样的,两组行为数据集间的相关联程度也可以用两者间的引力表示,相同的行为其一个动作周期产生的数据集将比较相近,即引力较大。根据牛顿万有引力可知,两物体间引力的大小与物体的质量成正比而与物体间距离的平方成反比;故引力f的定义如下:其中g为常量,mx为训练样本的数据质量,m为所识别数据的质量,r为两物质重心间的距离。步骤2:分类算法;步骤2.1:本发明选择上述各特征值的平均值及引力作为投票依据,因引力与物质的重心和距离都有关,本发明认为引力的判决力度相对较小,而其他三种特征值均值的判决力度相同。我们以走路训练为例进行说明,其他动作处理过程相同,设有k组样本周期,样本特征值平均值的计算公式如下(以走路为例):同理,可求得走路范德华力和密度的平均值步骤2.2:结合图2,说明本步骤的实现过程。样本训练完成之后就可以进入识别阶段了,因为数据流是动态持续的,在此我们设计了一个动态滑动窗口来处理实时数据流,如图2所示。我们将训练样本所得的每个行为动作一个周期的加速度数据个数从小到大排列好,依次计为w(走路)、r(跑步)、c(骑车)、d(下楼)、u(上楼),则我们先将滑动窗口大小设定为w,然后求取窗口内数据集合的上述物理特征,再与所训练样本的三个特征平均值的相对误差及引力大小作比较,其中相对误差δ的计算公式为(以分子量为例):每个特征平均值将票投给相对误差较小的一类行为,引力则将票投给引力较大的一类。比较结果包含的情况如表1所示(以走路为例):表1:投票情况投票情况走路票数下楼票数上楼票数跑步票数判断结果1111fn21+f110n32f10n42f+100相似度(yorn)52+f100y增量学习63f00y74000y表1中n表示无法判断,y表示可以确定投票结果为下楼,f表示引力。因为引力的判决力度较小,所以当判决结果为第4种的时候,我们需要进行余弦向量相似度分析,将四个特征值看做一个四维向量然后进行余弦相似度分析,判断结果判定为相似度较大的一类动作。其中余弦相似度计算公式如公式11所示:如果最后投票结果为走路动作,则可以判定为走路动作,走路步数加1,滑动窗口直接移至下一窗口,如果此时投票结果为其他动作如跑步,则此次投票无效,将滑动窗口向数据流反方向增大至r继续进行投票,如果此次最终投票结果为跑步则可以判定为跑步,跑步步数加1,如果投票结果为跑步之外的其他动作则此次投票无效,再以同样的方法变动滑动窗口的大小,直至可以判断出结果,若都无法判断出结果,则将滑动窗口向数据流反方向移动w/4个窗口大小再次重复上述投票,直至可以判断出结果;若移动一个周期之后仍无法判断则判定为其他动作。然后继续投票判断。当判断结果为第5种情况时,进行增量学习,以此来对训练样本进行更新,使样本逐渐趋向于该用户的行为特征,从而提高判决准确率。步骤3,增量学习当投票结果为第5种情况时,确定性相对较小,此时我们开始实施增量学习。每个行为的训练样本为k个周期,每次进行增量学习为1个行为周期,设进行增量学习的实时数据重心为(x,y,z),则重心(xa,ya,za)的更新方法如下:每进行一次增量学习,则每个行为训练样本特征值的数据重心就更新一次,随之的各物理特征也进行更新,之后的行为识别判断也将依据新的物理特征值按照上述步骤来进行投票。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1