基于并行蒙特卡洛法的边坡可靠性参数获取方法及装置与流程
本发明涉及数据处理领域,具体而言,涉及一种基于并行蒙特卡洛法的边坡可靠性参数获取方法及装置。
背景技术:
边坡的稳定性问题是工农业生产和地质灾害研究中常见问题。人类对边坡稳定性的研究经历了两次飞跃,即:从定性判断到定量分析的飞跃,从确定性理论到不确定性理论的飞跃。以蒙特卡洛模拟法为基础的可靠性分析方法,因其通用性好,精度高,占有很重要的地位,常作为其它边坡可靠性评价方法正确与否的基准。但常规蒙特卡洛模拟法也存在明显的缺陷,即计算效率不足。
传统上用蒙特卡洛法求解边坡可靠性问题,每一次蒙特卡洛模拟都要调用一次完整的边坡稳定性求解过程。而常规的蒙特卡洛法是典型的串行方法,无法利用当前计算机的多核心、多线程优势,对硬件平台来说是一种浪费。
因此,如何通过蒙特卡洛方法快速地进行边坡可靠性分析,提高计算效率,节约边坡可靠性分析的时间成本,是目前急需解决的问题。
技术实现要素:
有鉴于此,本发明实施例的目的在于提供一种基于并行蒙特卡洛法的边坡可靠性参数获取方法及装置,以改善上述问题。
第一方面,本发明实施例提供了一种基于并行蒙特卡洛法的边坡可靠性参数获取方法,所述方法包括:根据m个不确定性参数各自对应的均值与标准差,通过正交设计法,生成k个训练样本向量,每个所述训练样本向量由所述m个不确定性参数各自对应的试验数据构成,其中,m与k为非零自然数,k的最大取值与m呈指数关系;根据所述k个训练样本向量及一个或多个确定性参数,通过边坡稳定性分析方法,获取所述k个训练样本向量各自对应的边坡稳定系数;以所述k个训练样本向量为自变量,以其各自对应的所述边坡稳定系数为因变量,构成映射关系,通过支持向量机算法,获取映射关系表达式;通过并行蒙特卡洛法随机生成n个服从于联合概率分布的待测样本向量,根据所述映射关系表达式,获取边坡可靠性参数,所述边坡可靠性参数包括所述n个待测样本向量各自对应的边坡稳定系数的均值和标准差、边坡失效概率以及可靠度指标,其中,每个所述待测样本向量由所述m个不确定性参数各自对应的随机数据构成。
第二方面,本发明实施例提供了一种基于并行蒙特卡洛法的边坡可靠性参数获取装置,所述装置包括:训练样本生成模块,用于根据m个不确定性参数各自对应的均值与标准差,通过正交设计法,生成k个训练样本向量,每个所述训练样本向量由所述m个不确定性参数各自对应的试验数据构成,其中,m与k为非零自然数,k的最大取值与m呈指数关系;稳定系数获取模块,用于根据所述k个训练样本向量及一个或多个确定性参数,通过边坡稳定性分析方法,获取所述k个训练样本向量各自对应的边坡稳定系数;表达式获取模块,用于以所述k个训练样本向量为自变量,以其各自对应的所述边坡稳定系数为因变量,构成映射关系,通过支持向量机算法,获取映射关系表达式;可靠性参数获取模块,用于通过并行蒙特卡洛法随机生成n个服从于联合概率分布的待测样本向量,根据所述映射关系表达式,获取边坡可靠性参数,所述边坡可靠性参数包括所述n个待测样本向量各自对应的边坡稳定系数的均值和标准差、边坡失效概率以及可靠度指标,其中,每个所述待测样本向量由所述m个不确定性参数各自对应的随机数据构成。
本发明实施例的有益效果是:
本发明实施例提供一种基于并行蒙特卡洛法的边坡可靠性参数获取方法及装置,首先根据m个不确定性参数各自对应的均值与标准差,通过正交设计法,生成k个训练样本向量;再根据k个训练样本向量及一个或多个确定性参数值,通过边坡稳定性分析方法,获取k个训练样本向量各自对应的边坡稳定系数;以所述k个训练样本向量为自变量,以其各自对应的边坡稳定系数为因变量,构成映射关系,通过支持向量机算法,获取所述映射关系表达式;根据映射关系表达式,采用并行蒙特卡洛法随机生成的n个服从于联合概率分布的待测样本向量,从而获取边坡可靠性参数。所述方法有效地提高了计算效率,节约了边坡可靠性分析的时间成本。
本发明的其他特征和优点将在随后的说明书阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明实施例了解。本发明的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
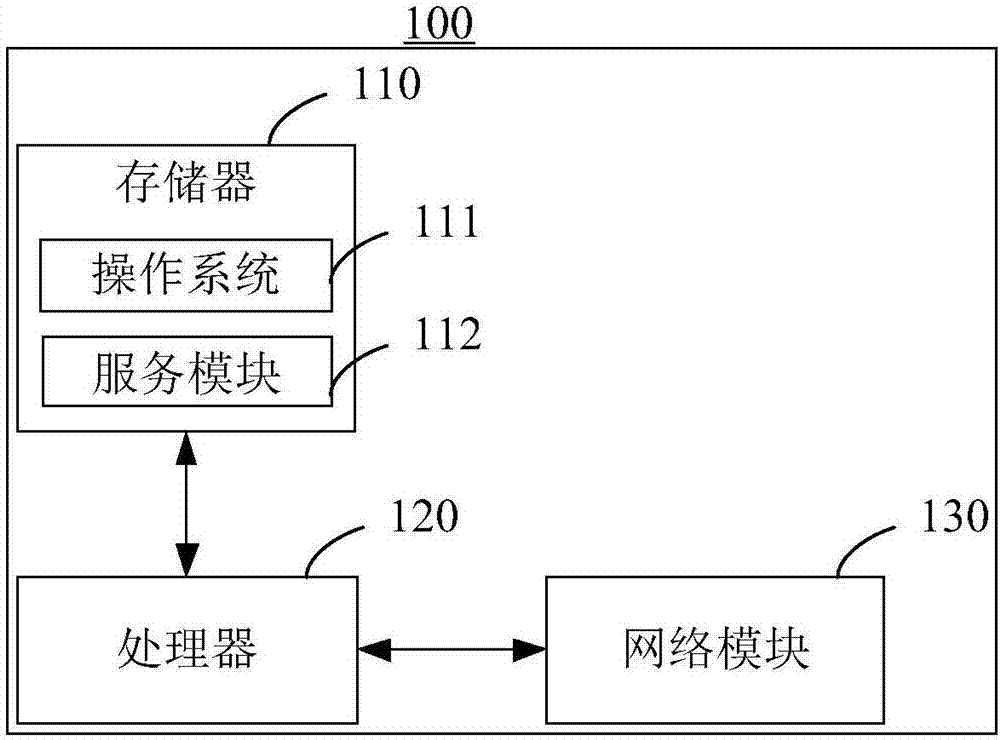
图1为本发明实施例提供的服务器的结构示意图;
图2为本发明实施例提供的一种基于并行蒙特卡洛法的边坡可靠性参数获取方法的流程图;
图3为本发明实施例提供的一种基于并行蒙特卡洛法的边坡可靠性参数获取方法中步骤s310的一种详细流程图;
图4为本发明实施例提供的一种基于并行蒙特卡洛法的边坡可靠性参数获取方法中步骤s330的一种详细流程图;
图5为本发明第一实施例提供的一种基于并行蒙特卡洛法的边坡可靠性参数获取方法中步骤s340的一种详细流程图;
图6为本发明实施例提供的一种基于并行蒙特卡洛法的边坡可靠性参数获取方法中步骤s340求解边坡稳定系数均值、失效概率和可靠度指标流程图;
图7为本发明实施例提供的一种基于并行蒙特卡洛法的边坡可靠性参数获取方法中步骤s340求解边坡稳定系数标准差流程图;
图8为本发明实施例提供的一种基于并行蒙特卡洛法的边坡可靠性参数获取方法应用于某尾矿坝坝坡的概化剖面图;
图9(a)为本发明实施例提供的一种基于并行蒙特卡洛法的边坡可靠性参数获取方法中在不同蒙特卡洛模拟次数下的某尾矿坝坝坡失效概率的效果示意图;
图9(b)为本发明第一实施例提供的一种基于并行蒙特卡洛法的边坡可靠性参数获取方法中在不同蒙特卡洛模拟次数下的某尾矿坝坝坡可靠度指标的效果示意图;
图10(a)为本发明实施例提供的一种基于并行蒙特卡洛法的边坡可靠性参数获取方法中并行算法的加速比实测值与理论值对比结果图;
图10(b)为本发明实施例提供的一种基于并行蒙特卡洛法的边坡可靠性参数获取方法中并行算法的并行效率实测值与理论值对比结果图;
图11为本发明实施例提供的一种基于并行蒙特卡洛法的边坡可靠性参数获取方法中并行算法的求解时间实测值和理论值对比结果图;
图12为本发明第二实施例提供的一种基于并行蒙特卡洛法的边坡可靠性参数获取装置的结构框图;
图13是本发明第二实施例提供的一种基于并行蒙特卡洛法的边坡可靠性参数获取装置中训练样本生成模块410的一种详细结构框图;
图14为本发明第二实施例提供的一种基于并行蒙特卡洛法的边坡可靠性参数获取装置中表达式获取模块430的一种详细结构框图;
图15为本发明实施例提供的一种基于并行蒙特卡洛法的边坡可靠性参数获取装置中可靠性参数获取模块440的一种详细结构框图。
具体实施方式
下面将结合本发明实施例中附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明一部分实施例,而不是全部的实施例。通常在此处附图中描述和出示的本发明实施例的组件可以以各种不同的配置来布置和设计。因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步定义和解释。同时,在本发明的描述中,术语“第一”、“第二”等仅用于区分描述,而不能理解为指示或暗示相对重要性。
本发明实施例提供的基于支持向量机的边坡可靠性参数获取方法可以应用于服务器中。图1示出了服务器100的结构示意图,请参阅图1,所述服务器100包括存储器110、处理器120以及网络模块130。
存储器110可用于存储软件程序以及模块,如本发明实施例中的基于支持向量机的边坡可靠性参数获取方法及装置对应的程序指令/模块,处理器120通过运行存储在存储器110内的软件程序以及模块,从而执行各种功能应用以及数据处理,即实现本发明实施例中的基于支持向量机的边坡可靠性参数获取方法。存储器110可包括高速随机存储器,还可包括非易失性存储器,如一个或者多个磁性存储装置、闪存、或者其他非易失性固态存储器。进一步地,上述存储器110内的软件程序以及模块还可包括:操作系统111以及服务模块112。其中操作系统111,例如可为linux、unix、windows,其可包括各种用于管理系统任务(例如内存管理、存储设备控制、电源管理等)的软件组件和/或驱动,并可与各种硬件或软件组件相互通讯,从而提供其他软件组件的运行环境。服务模块112运行在操作系统111的基础上,并通过操作系统111的网络服务监听来自网络的请求,根据请求完成相应的数据处理,并返回处理结果给客户端。也就是说,服务模块112用于向客户端提供网络服务。网络模块130用于接收以及发送网络信号。上述网络信号可包括无线信号或者有线信号。
可以理解,图1所示的结构仅为示意,服务器100还可包括比图1中所示更多或者更少的组件,或者具有与图1所示不同的配置。图1中所示的各组件可以采用硬件、软件或其组合实现。另外,本发明实施例中的服务器还可以包括多个具体不同功能的服务器。
请参照图2,图2为本发明实施例提供的一种基于并行蒙特卡洛法的边坡可靠性参数获取方法的流程图,所述方法具体包括如下步骤:
步骤s310:根据m个不确定性参数各自对应的均值与标准差,通过正交设计法,生成k个训练样本向量,每个所述训练样本向量由所述m个不确定性参数各自对应的试验数据构成,其中,m与k为非零自然数,k的最大取值与m呈指数关系。
m与k为非零自然数,即m,k∈n+。其中,不确定性参数可以为岩土体的粘聚力、内摩擦角、容重等边坡岩土体物理力学参数,可以理解的是,所述不确定性参数也可以是获取边坡可靠性参数时所需的其他参数,需根据具体的应用场景的不同进行相应的设置。
作为一种具体的实施方式,请参阅图3,所述步骤s310可以包括:
步骤s311:根据m个不确定性参数各自对应的均值和标准差,通过正交设计法,至少生成一组第一训练样本向量,每个所述不确定性参数的均值为μi,标准差为σi,每组所述第一训练样本向量中的每个所述不确定性参数对应的3个水平样本为:μi-2σi、μi、μi+2σi,或者为μi-3σi、μi、μi+3σi,其中i=1,2,…,m,每一组所述第一训练样本向量的数量为nj,nj≤3m,j为组编号,有j∈n+。
每个所述不确定性参数相当于一个随机变量,其对应的均值与标准差是已知的,将所述不确定性参数对应的均值表示为μi,标准差表示为σi,其中i=1,2,…,m。
每个所述不确定性参数可以围绕其对应的均值设置试验数据的范围,设每个所述不确定性参数对应的试验数据的范围包括μi-2σi、μi、μi+2σi,这种情况下,由于每个所述第一训练样本向量由所述m个不确定性参数各自对应的试验数据构成,而每个所述不确定性参数对应的试验数据可以是μi-2σi、μi、μi+2σi中的任意一种,因此总共可以生成3m个不同的第一训练样本向量。
类似的,还可以设每个所述不确定性参数对应的试验数据的范围包括μi-3σi、μi及μi+3σi。这种情况下,由于每个所述第一训练样本向量由所述m个不确定性参数各自对应的试验数据构成,而每个所述不确定性参数对应的试验数据可以是μi-3σi、μi及μi+3σi中的任意一种,因此总共可以生成3m个不同的第一训练样本向量。
正交设计法实际上就是从所述3m个不同的第一训练样本向量中选择nj个具有代表性的第一训练样本向量用于后续获取映射关系表达式,因此nj≤3m。所述正交设计法可以通过spss等现有成熟商业软件、excel电子表格功能函数或自行编程实现,此处不再累述。
生成的第一训练样本向量至少为一组,如j=1,可以为上述两种情况的任意一种。如当j=2,可以将μi-2σi、μi、μi+2σi作为每个所述不确定性参数对应的试验数据,生成一组第一训练样本向量,同时将μi-3σi、μi及μi+3σi作为每个所述不确定性参数对应的试验数据,再生成一组第一训练样本向量。其中,后期生成的样本组中如果含有与先期生成样本组相重复的元素(即样本向量),需删除。
此外,可以理解的是,每个所述不确定性参数对应的试验数据的范围可以根据具体需求具体设置,其设置方式并不构成对本发明具体实施方式的限制。
步骤s312:合并所述第一训练样本向量为训练样本向量,所述训练样本向量的样本数为k,
合并至少一组所述第一训练样本向量为训练样本向量。例如将步骤s312中当i=2时生成的两组样本合并,构造出k=n1+n2个样本,为训练样本向量。由于正交设计表的非唯一性,在大多数情况下是生成的k=n1+n2个样本,但并不一定包含m个因素全部取均值条件这一特殊样本。由于均值样本在统计学中的特殊意义,应予以特别关注。鉴于此,如若不含,应特别增补该样本进入正交设计表。因此样本数k满足k=n1+n2+1或k=n1+n2。
进一步地,考虑到复杂边坡问题的规模,以及后续映射关系表达式的回归效果检测不满足精度要求的问题,需要生成更多的训练样本。当精度不满足要求时,可以μi-2σi、μi、μi+2σi作为每个所述不确定性参数对应的试验数据,添加一组第一训练样本向量,按后续步骤构成映射关系表达式,检测回归效果是否达标;若仍不达标,则再以μi-3σi、μi及μi+3σi作为每个所述不确定性参数对应的试验数据,添加一组训练样本向量,按后续步骤再次构成映射关系表达式,再次检测回归效果是否达标。以此类推,直到满足要求。因此,应根据实际需求,获取一定组数的第一训练样本向量。其中,总样本数k满足
步骤s320:根据所述k个训练样本向量及一个或多个确定性参数,通过边坡稳定性分析方法,获取所述k个训练样本向量各自对应的边坡稳定系数。
其中,确定性参数可以为岩土体的粘聚力、内摩擦角、容重等边坡岩土体物理力学参数,可以为边坡的长度、宽度等几何参数,可以理解的是,所述确定性参数也可以是获取边坡可靠性参数时所需的其他参数,需根据具体的应用场景的不同进行相应的设置。
所述边坡稳定性分析方法可以为极限平衡法、有限元法或有限差分法等。其中,极限平衡法可以包括瑞典条分(swedenslice)法、斯宾塞(spencer)法、毕肖普(bishop)法、摩根斯坦-普莱斯(morgenstern-price)法等。所述边坡稳定性分析方法可以通过各种边坡稳定性分析的商业软件实现,如geostudio(包含极限平衡法和有限元法两类方法可供选择)、ansys(有限元法)、abaqus(有限元法)、adina(有限元法)、flac/flac3d(有限差分法)等。通过上述任意一种方法都可以得到相应的边坡稳定系数,但是由于各种方法的理论构架不同,因此根据不同的方法获取的边坡稳定系数在数值存在一定的差异,针对不同的应用场景可以根据需求采用更恰当的方法。
步骤s330:以所述k个训练样本向量为自变量,以其各自对应的所述边坡稳定系数为因变量,构成映射关系,通过支持向量机算法,获取映射关系表达式。
作为一种具体的实施方式,请参阅图4,所述步骤s330可以包括:
步骤s331:根据所述k个训练样本向量及其各自对应的边坡稳定系数,以及预设规则,获取最优偏移量以及所述k个训练样本向量各自对应的最优拉格朗日对偶。
优选的,在所述步骤s331之前,所述方法还可以包括:
对所述k个训练样本向量中的试验数据进行归一化处理。
由于如岩土体的粘聚力、内摩擦角、容重等各个不确定性参数的量纲不同、绝对值大小差异显著,因此对所述k个训练样本向量中的试验数据进行归一化处理后再执行后续步骤,可以有效地提高后续获取的各边坡稳定系数的精度,其中,所述k个训练样本向量中的试验数据经归一化处理后可以位于[-1,1]区间。
步骤s332:根据所述最优偏移量、所述k个训练样本向量及其各自对应的所述最优拉格朗日对偶,获取映射关系表达式。
下面对步骤s331及步骤s332进行详细说明。
根据向量机算法,设有k组试验数据,且每组有m个变量,构成数据对,即[(xi,yi)|i=i=1,2,…,k],其映射关系记为:
xi→yixi=[xi1,xi2,…xim]ti=1,2,…,k
xi∈rmyi∈r(1)
式中:向量xi代表第i组试验的数据(一般为经过归一化作预处理后的试验数据),由m个变量组成,分别代表影响边坡稳定性的m个随机因素(例如岩土体的粘聚力、内摩擦角、容重等)。yi表示第i组试验数据对应的边坡稳定系数,也就是向量机的输出。数学符号r表示实数空间,rm表示m维实数空间。
引入一个预测函数f(x),用以逼近所述训练样本向量与其各自对应的边坡稳定系数之间的映射关系,该预测函数f(x)可以表示为:
式中,
w可通过在满足式(4)的条件下使得式(3)最小的最优化问题来确定,其中式(3)与式(4)分别为:
式中,r(w,ξ,ξ*)为风险控制函数,ξ=[ξ1,ξ2,…,ξm]t和
进一步的,式(3)及式(4)所示的最优化问题可以通过引入拉格朗日乘子来转化为求取在满足式(6)的条件下使得式(5)最大的最优化问题,其中式(5)及式(6)分别为:
式中,αi和
k(x,y)=exp(-δ2||x-y||2)(7)
式中,δ为核函数参数。
将所述k个训练样本向量xi及其各自对应的边坡稳定系数yi代入式(5)后,可以通过优化算法,如贯序最小二乘法,求解式(5)及式(6)构成的最优化问题,以获取所述k个训练样本向量各自对应的最优拉格朗日对偶
式中,
将式(7)及式(8)代入式(2)后,式(2)可以表示为:
然后,构造一个函数η(b),用以表示所述k个训练样本向量各自对应的预测边坡稳定系数与实际边坡稳定系数误差的平方和,所述函数η(b)可以表示为:
将所述k个训练样本向量xi及其各自对应的边坡稳定系数yi代入式(10)后,可以通过优化算法,如最小二乘法,获取使得式(10)的值最小的偏移量b,即为最优偏移量。
最后,将所述最优偏移量b、所述k个训练样本向量及其各自对应的最优拉格朗日对偶
以上是步骤s330的理论依据,在具体实践中,为了达到更好的向量机回归效果,还需要进行一些辅助操作。在此列出步骤s330的详细分项步骤如下:
子步骤1,进行训练样本自变量的归一化处理。考虑到岩土体的粘聚力、内摩擦角、容重等随机变量的量纲不同、而且绝对值大小差异显著,为提升向量机回归效果,建议对步骤s310中的正交试验数据,也就是训练样本自变量
式中μj和σj分别为第j个分量的均值和标准差。
子步骤2,求解拉格朗日对偶和偏移量。按照(1)式映射关系,构造向量机的输入和输出,然后进行向量机训练。即按照贯序最小二乘法求解(5)~(6)式所示的最优化问题,得到拉格朗日对偶
子步骤3,获取映射关系表达式。将(9)式函数关系式作为边坡稳定系数(或称安全系数)fos(factorofsafety)求解的表达式如(12)式所示,也就是作为边坡可靠性求解过程中的响应面函数,从而实现以简洁的公式替代复杂的隐式过程。
子步骤4,向量机回归性能检验。采用三个指标:平均相对误差(meanrelativeerror)、相关系数(correlationcoefficient),样本数量冗余度来考核向量机对训练样本的回归程度,以及训练样本数量是否充足。设k个样本中,yj为稳定系数值实际值(通过步骤s320得到的边坡稳定系数实际值)fosj为通过(12)式得到的向量机预测值。按下式定义平均相对误差mre、相关系数r,样本数量冗余度p。
(14)式中nv为支持向量的数量。平均相对误差mre越小越好;相关系数r越大越好,其值介于–1与+1之间,即–1≤r≤+1。当r>0时,表示两变量正相关,r<0时,两变量为负相关。当|r|=1时,表示两变量为完全线性相关,即为线性函数关系。当r=0时,表示两变量间无线性相关关系。对于本实施例描述的问题,建议按三级考核:0<r<0.4为低度线性正相关;0.4≤r<0.7为显著性正相关;0.7≤r≤1为高度线性正相关。r越逼近+1表示向量机回归效果越好。样本数量冗余度p反映了训练样本数量是否足够多。当样本冗余度高,倾向于认为样本覆盖是全面的;相反,当冗余度较低时,意味着较大比例的样本入选为支持向量,倾向于认为样本覆盖面不够,需要增补训练样本。
对本实施例描述的方法而言,建议平均相对误差绝对值不超过10%,相关系数r不低于0.7,样本数量冗余度p不低于50%。上述三项指标限值可根据实际情况决定。
子步骤5,样本调整。当向量机的输出,即(12)式,无法同时满足上述要求时,应返回到步骤s310,重新生成新的训练样本,并继续后续流程,直到向量机回归性能检测合格为止。具体可从如下两种方式中选取其一:第一种方法,丢弃上述初始样本,按步骤1重新生成一组新的正交样本替代。第二种方法,保留上述初始样本,按步骤1再增补一组正交样本。
当满足向量机回归性能检验时,即(12)式完全确定,进入步骤s340。
步骤s340:根据通过并行蒙特卡洛法随机生成n个服从于联合概率分布的待测样本向量及所述映射关系表达式,获取边坡可靠性参数,所述边坡可靠性参数包括所述n个待测样本向量各自对应的边坡稳定系数的均值和标准差、边坡失效概率以及可靠度指标,其中,每个所述待测样本向量由所述m个不确定性参数各自对应的随机数据构成。
经过步骤s330,得到了稳定系数f(x)的显示表达,由此建立边坡可靠度指标求解的功能函数g(x)如(16)式所示:
根据功能函数g(x)的值判断边坡是否失稳:当g(x)>0,边坡处于稳定状态;当g(x)=0,边坡处于极限平衡状态;当g(x)<0,边坡失稳。因此,g(x)可讲看作是边坡安全余量的指示器,继而通过蒙特卡洛法求取失效概率。
作为一种具体的实施方式,请参照图5,图5为本发明实施例提供的一种基于并行蒙特卡洛法的边坡可靠性参数获取方法中的步骤s340的流程图。步骤s340中采用基于openmp并行计算模式将普通串行蒙特卡洛方法并行化,得到求解边坡可靠性参数的多线程并行化方法,其求解流程原理请参阅图6和图7。所述步骤s340可以包括:
步骤s341:采用openmp并行技术,将sum1及sum2设置为第一规约变量,所述sum1用于存储稳定系数之和,所述sum2用于存储失效次数之和。
所谓规约操作,是指反复将一个二元运算符应用在一个变量和另外一个值上,并把结果保存在原变量中,数组求和是常见的规约操作。需要说明的是,openmp并行技术中对规约类型的变量以特殊支持,以方便实现行化。即在某一线程在进行规约操作时,会阻止其它线程做同类操作,以防止线程争用带来的逻辑错误。
步骤s342:创建p个第一并行线程,所述p个第一并行线程用于随机生成n个服从于联合概率分布的待测样本向量,根据所述映射关系表达式及功能函数,分别获取所述sum1与所述sum2的规约和,其中,每个所述待测样本向量由所述m个不确定性参数各自对应的随机数据构成。
所述第一并行线程数p大小的选取原则上不超过计算机cpu的内核(含超线程虚拟内核)总数。例如4核8线计算机则可选取p=8。一般p值超出cpu内核总数时,程序仍然可以运行,但计算效率不会提升。线程编号从0至p-1,采取等分的策略,每个线程负责n次蒙特卡洛模拟循环中的一段。设t为线程编号,则当t<p-1时,编号为t的线程负责从t[n/p]+1到(t+1)[n/p]段蒙特卡洛模拟;对于最后一个线程,应将n/p除不尽时剩余段的蒙特卡洛模拟包含其中,即当t=p-1时,编号为t的线程负责从t[n/p]+1到n段蒙特卡洛模拟。其中,中括号[]表示当n/p除不尽时取整数。
p个线同时执行相同模式的计算任务,下面以0号线程为例进行说明。
向量x由m个变量构成,根据联合概率分布,随机产生服从于联合概率密度函数的随机样本向量xi,i=1,2,…,[n/p],i表示随机样本编号。其中,所述联合概率分布为与所述m个不确定性参数的概率分布对应的已知的分布。
进一步的,若在所述步骤s331之前,对所述k个训练样本向量中的试验数据进行了归一化处理,则此处,需对所述随机生成的服从于联合概率分布的待测样本向量xi进行相应的归一化处理。
将随机生成的[n/p]个服从于联合概率分布的待测样本向量分别代入所述映射关系表达式中,即可获取[n/p]个待测样本向量各自对应的边坡稳定系数f(xi)。
计算[n/p]个边坡稳定系数f(xi)和g(xi),将f(xi)累加进sum1,并根据g(xi)值是否小于等于零,来统计边坡失效的次数,当g(xi)≤0时,sum2数值累加1,直至所有线程循环结束。
步骤s343:结束所述p个第一并行线程,将所述稳定系数之和与所述n的比值作为边坡稳定系数的均值,将所述失效次数之和与所述n的比值作为边坡失效概率,根据所述边坡失效概率获取可靠度指标。
通过上述步骤获得所述稳定系数之和的规约和,即sum1,通过上述步骤获得所述失效次数之和的规约和,即sum2,则边坡失效概率pf,稳定系数均值mean_fos可根据下面的算式计算出:
根据所述边坡失效概率计算获得所述可靠度指标。由于一般认为失效概率pf与可靠度指标β满足如下(18)式关系,所以在已知失效概率pf的条件下,可采用(19)式计算可靠度指标β。
β=-φ-1(pf)(19)
(18)~(19)式中φ和φ-1分别为标准正态概率密度函数及其反函数。
步骤s344:采用openmp并行技术,将sum3设置为第二规约变量,所述sum3用于存储方差之和。
采用openmp并行技术,将sum3设置为第二规约变量,并赋初值为零,用于存储方差之和,即每个样本的稳定系数及与所述稳定系数均值之差的平方和。
步骤s345:创建p个第二并行线程,所述p个第二并行线程用于随机生成n个服从于联合概率分布的待测样本向量,根据所述映射关系表达式,计算所述待测样本向量的稳定系数及与所述稳定系数均值差的平方,获取所述sum3的规约和,其中,每个所述待测样本向量由所述m个不确定性参数各自对应的随机数据构成。
其具体的计算过程和步骤s342的模式一样,区别仅在于各线程累加求和的目的不同。在步骤s345操作中,采用规约变量sum3来保存方差之和,其具体过程参照步骤s342,为例描述的简洁,在此不再过多描述。
进一步的,若在所述步骤s331之前,对所述k个训练样本向量中的试验数据进行了归一化处理,在步骤s345中,需对所述随机生成的服从于联合概率分布的待测样本向量进行相应的归一化处理。
步骤s346:结束所述p个第二并行线程,根据所述方差之和获取稳定系数的标准差。
结束p个第二并行线程,规约和sum3即为所述方差之和,根据所述方差之和计算获取所述稳定系数标准差。
有鉴于通过步骤s343已经获得了稳定系数均值mean_fos,且sum3也已通过上述步骤得到,则该稳定系数标准差σ的计算式如下:
至此,通过步骤s340,边坡可靠性参数已经全部获得。其中,获取的所述n个待测样本向量各自对应的边坡稳定系数的均值和标准差、边坡失效概率以及可靠度指标是边坡可靠性评估中广为接受的、核心的量化评估指标,可用于对边坡的可靠性进行精确评估。
本发明实施例提供的基于并行蒙特卡洛法的边坡可靠性参数获取方法,根据m个不确定性参数各自对应的均值与标准差,通过正交设计法获取k个训练样本向量,并获取该k个训练样本向量对应的边坡稳定系数,然后通过支持向量机算法根据获取的k个训练样本向量与其对应的边坡稳定系数获取映射关系表达式,继而采用基于openmp技术的并行蒙特卡洛法获取边坡可靠性参数。这一方法有效的提高了计算效率,节约了边坡可靠性分析的时间成本。
进一步的,为了说明本发明实施例的有益效果,将本发明实施例提供的基于并行蒙特卡洛法的边坡可靠性参数获取方法应用于某尾矿坝坝坡的可靠性分析中。
所述某尾矿坝坝坡的概化剖面图如图8所示,其岩土体的物理力学性质指标如表1所示,其17个不确定性参数如表2所示,各自服从独立正态分布。利用正交设计法生成的163个正交训练样本向量编码表如表3所示,求解得到的映射关系表达式参数如表4所示,拉格朗日对偶
表1某尾矿坝坝坡岩土体的物理力学性质指标
表217个不确定性参数
注:17个不确定性参数分别编号为var1-var17
表3163个正交训练样本的向量编码表
注:1)编码表中“0”、“1”、“2”、“3”、“4”分别代表“均值-3×标准差”、“均值-2×标准差”、“均值”、“均值+2×标准差”和“均值+3×标准差”
2)“sv”代表支持向量,即supportvector,“non-sv”代表非支持向量,即nonsupportvector
表4求解得到的映射关系表达式参数
注:每个输入向量x包含如表所示的17个变量,分别编号为var1~var17
表5拉格朗日对偶
注:表中列出66组非零拉格朗日对偶取值及其对应的i序号,其余取零的未列出。i=1,2,…163(共计163组训练样本)
表6映射关系表达式回归效果检验
注:建议评价标准为:平均相对误差绝对值|mre|≤10%,相关系数r≥0.7,样本数量冗余度p≥50%。
由于所述某尾矿坝坝坡的岩土体由多层结构复杂的土体组成,使得最危险滑动面的位置难于确定,而以有限元法和有限差分法为基础的强度折减法在用于边坡稳定性分析时,能够自动定位最危险滑动面,因此,利用fla3d配合强度折减法,获取上述163个训练样本向量各自对应的边坡稳定系数,然后根据这163个训练样本向量及其各自对应的边坡稳定系数,通过支持向量机算法,获取映射关系表达式,其参数如表4和表5所示;而后根据(11)式建立回归方程;根据表6,支持向量机回归效果检验达标,说明回归方程满足精度要求,能够进入下一个环节;最后,将回归方程作为可靠性分析中的响应面,即映射关系表达式,采用蒙特卡洛法求解边坡的失效概率、可靠性指标、稳定系数均值等,结果见表7。
图9(a)示出了在不同蒙特卡洛模拟次数下的边坡失效概率,图中横坐标为蒙特卡洛模拟次数,纵坐标为边坡失效概率;图9(b)示出了在不同蒙特卡洛模拟次数下的边坡可靠度指标,图中横坐标为蒙特卡洛模拟次数,纵坐标为边坡可靠度指标;表7示出了某尾矿坝坝坡在一千万次蒙特卡洛模拟下的边坡可靠性参数。
上述获取边坡可靠性参数的过程中进行了1千万次蒙特卡洛模拟,试验证明,并行蒙特卡洛法新方法达到了很高的效率,加速比达到8左右(测试平台dellr410server(intelxeone56202.4ghzcpu,64gbram)windows2008操作系统),将串行条件下的几百秒缩减为并行条件下的几十秒左右,优势明显。某尾矿坝坝坡在一千万次蒙特卡洛下的可靠性分析结果见图3和表4所示。
表7某尾矿坝坝坡在1千万次蒙特卡洛模拟下的可靠性分析结果
为了定量评估并行算法所获得的效率提升,这里引入“加速比”和“并行效率”两个指标:
sp=t1/tp,ep=sp/p(21)
(21)式中p是并行线程数,sp为加速比,ep为并行效率,t1是串行算法求解所需时间,tp是p个线程并行条件下算法所需时间。通过将本实施例中p的值设为1,即线程数为1,此时并行算法退化为普通串行算法,记录串行算法的时间消耗t1,再记录p个线程并行条件下算法时间消耗tp,根据(21)式获得所述加速比和所述并行效率。如果某种条件下,加速比与的并行线程数p成正比,则称该并行算法在该条件下具有线性加速比。在某些条件下,若sp>p,则称该条件下,该算法具有超线性加速比。一般情况下,加速比是非线性的,且随着并行线程数量的增多,效率会降低。这主要是由于算法中并行的部分的比例不可能达到100%,再加之并行线程带来其它方面的系统开销所造成的。
评价并行算法的性能,可参照阿姆达尔定律:
sp=1/(1-fpar+fpar/p)(22)
式中fpar为并行计算部分所占时间比例。定律也可表述为,对系统内某部分的并行化改进造成的整体性能提升量取决于该部分在整体过程中执行的时间,即经常性事件或其部分的改进造成的整体性能得到较大提升,这一公式已被学术界所接受。根据该定律,联立(21)~(22)式可以求解理论加速比和理论并行效率,继而在已知单线程执行时间的情况下对并行算法执行时间进行预先估计。特别地,当fpar=0时(即只有串行,没有并行),加速比取得最小值sp=0。当p→∞时,极限加速比sp→1/(1-fpar),这也就是加速比的上限。例如,若可供并行改造的串行代码其执行时间占整个代码的75%,则通过上式可得出并行处理的总体性能不可能超过4倍。在本实施例中,通过并行算法的加速比、并行效率实测值和该定律的理论值作对比,可对算法的并行性能进行评估。
图10(a)、图10(b)分别示出了本实施例并行算法的加速比、并行效率实测值与依据阿姆达尔定律给出的理论值对比。图11示出了并行算法的求解时间实测值和依据阿姆达尔定律给出的理论值对比。从实测曲线和理论曲线的符合程度可知,本实施例所进行的并行化改造的比例达到了95%~98%,性能优异。分析显示,就本案例而言,并行线程数取8比较适中,再继续增加线程数,效果提升不显著。
请参照图13,图13为本发明实施例提供的一种基于并行蒙特卡洛法的边坡可靠性参数获取装置400的结构框图,所述装置具体包括:
训练样本生成模块410,用于根据m个不确定性参数各自对应的均值与标准差,通过正交设计法,生成k个训练样本向量,每个所述训练样本向量由所述m个不确定性参数各自对应的试验数据构成,其中,m与k为非零自然数,k的最大取值与m呈指数关系。
作为一种具体的实施方式,请参阅图14,所述训练样本生成模块410包括第一训练样本生成模块411和第二训练样本生成模块412。
第一训练样本生成模块411,用于根据m个不确定性参数各自对应的均值和标准差,通过正交设计法,至少生成一组第一训练样本向量,每个所述不确定性参数的均值为μi,标准差为σi,每组所述第一训练样本向量中的每个所述不确定性参数对应的3个水平样本为:μi-2σi、μi、μi+2σi,或者为μi-3σi、μi、μi+3σi,其中i=1,2,…,m,每一组所述第一训练样本向量的数量为nj,nj≤3m,j为组编号,有j∈n+。
第二训练样本生成模块412,用于合并所述第一训练样本向量为训练样本向量,所述训练样本向量的样本数为k,
稳定系数获取模块420,用于根据所述k个训练样本向量及一个或多个确定性参数,通过边坡稳定性分析方法,获取所述k个训练样本向量各自对应的边坡稳定系数。
表达式获取模块430,用于以所述k个训练样本向量为自变量,以其各自对应的所述边坡稳定系数为因变量,构成映射关系,通过支持向量机算法,获取映射关系表达式。
作为一种具体的实施方式,请参阅图14,所述表达式获取模块430可以包括第一获取模块431和第二获取模块432。
第一获取模块431,用于根据所述k个训练样本向量及其各自对应的边坡稳定系数,以及预设规则,获取最优偏移量以及所述k个训练样本向量各自对应的最优拉格朗日对偶。
优选的,所述第一获取模块431还包括第一处理模块431a,用于在根据所述k个训练样本向量及其各自对应的边坡稳定系数,以及预设规则,获取最优偏移量以及所述k个训练样本向量各自对应的最优拉格朗日对偶之前,对所述k个训练样本向量中的试验数据进行归一化处理。
第二获取模块432,用于根据所述最优偏移量、所述k个训练样本向量及其各自对应的所述最优拉格朗日对偶,获取映射关系表达式。
可靠性参数获取模块440,用于根据通过并行蒙特卡洛法随机生成n个服从于联合概率分布的待测样本向量及所述映射关系表达式,获取边坡可靠性参数,所述边坡可靠性参数包括所述n个待测样本向量各自对应的边坡稳定系数的均值和标准差、边坡失效概率以及可靠度指标,其中,每个所述待测样本向量由所述m个不确定性参数各自对应的随机数据构成。
作为一种具体的实施方式,请参阅图15,所述可靠性参数获取模块440可以包括第一计算模块441、第二计算模块442、第三计算模块443、第四计算模块444、第五计算模块445、第六计算模块446。
第一计算模块441,用于采用openmp并行技术,将sum1及sum2设置为第一规约变量,所述sum1用于存储稳定系数之和,所述sum2用于存储失效次数之和。
第二计算模块442,用于创建p个第一并行线程,所述p个第一并行线程用于随机生成n个服从于联合概率分布的待测样本向量,根据所述映射关系表达式及功能函数,分别获取所述sum1与所述sum2的规约和,其中,每个所述待测样本向量由所述m个不确定性参数各自对应的随机数据构成。
进一步的,若所述第一获取模块431包含第一处理模块431a,则所述第二计算模块442还包含第二处理模块442a,用于在创建p个第一并行线程,所述p个第一并行线程用于随机生成n个服从于联合概率分布的待测样本向量之后,根据所述映射关系表达式及功能函数,分别获取所述sum1与所述sum2的规约和之前,对所述随机生成的n个服从于联合概率分布的待测样本向量进行归一化处理。
第三计算模块443,用于结束所述p个第一并行线程,将所述稳定系数之和与所述n的比值作为边坡稳定系数的均值,将所述失效次数之和与所述n的比值作为边坡失效概率,根据所述边坡失效概率获取可靠度指标。
第四计算模块444,用于采用openmp并行技术,将sum3设置为第二规约变量,所述sum3用于存储方差之和。
第五计算模块445,用于创建p个第二并行线程,所述p个第二并行线程用于随机生成n个服从于联合概率分布的待测样本向量,根据所述映射关系表达式,计算所述待测样本向量的稳定系数及与所述稳定系数均值差的平方,获取所述sum3的规约和,其中,每个所述待测样本向量由所述m个不确定性参数各自对应的随机数据构成。
进一步的,若所述第一获取模块431包含第一处理模块431a,则所述第五计算模块445还包含第三处理模块445a,用于在所述创建p个第二并行线程,所述p个第二并行线程用于随机生成n个服从于联合概率分布的待测样本向量之后,根据所述映射关系表达式,计算所述待测样本向量的稳定系数及与所述稳定系数均值差的平方,获取所述sum3的规约和之前,对所述随机生成的n个服从于联合概率分布的待测样本向量进行归一化处理。
第六计算模块446,用于结束所述p个第二并行线程,根据所述方差之和获取稳定系数的标准差。
本发明实施例所提供的基于并行蒙特卡洛法的边坡可靠性参数获取装置,其实现原理及产生的技术效果和前述方法实施例相同,在此不再过多赘述,装置实施例部分未提及之处,可参考前述方法实施例中相应内容。
综上所述,本发明实施例提供一种基于并行蒙特卡洛法的边坡可靠性参数获取方法及装置,首先根据m个不确定性参数各自对应的均值与标准差,通过正交设计法,生成k个训练样本向量;再根据k个训练样本向量及一个或多个确定性参数值,通过边坡稳定性分析方法,获取k个训练样本向量各自对应的边坡稳定系数;以所述k个训练样本向量为自变量,以其各自对应的边坡稳定系数为因变量,构成映射关系,通过支持向量机算法,获取所述映射关系表达式;根据映射关系表达式,采用并行蒙特卡洛法随机生成的n个服从于联合概率分布的待测样本向量,从而获取边坡可靠性参数。所述方法有效地提高了计算效率,节约了边坡可靠性分析的时间成本。
在本申请所提供的几个实施例中,应该理解到,所揭露的装置和方法,也可以通过其它的方式实现。以上所描述的装置实施例仅仅是示意性的,例如,附图中的流程图和框图显示了根据本发明的多个实施例的装置、方法和计算机程序产品的可能实现的体系架构、功能和操作。在这点上,流程图或框图中的每个方框可以代表一个模块、程序段或代码的一部分,所述模块、程序段或代码的一部分包含一个或多个用于实现规定的逻辑功能的可执行指令。也应当注意,在有些作为替换的实现方式中,方框中所标注的功能也可以以不同于附图中所标注的顺序发生。例如,两个连续的方框实际上可以基本并行地执行,它们有时也可以按相反的顺序执行,这依所涉及的功能而定。也要注意的是,框图和/或流程图中的每个方框、以及框图和/或流程图中的方框的组合,可以用执行规定的功能或动作的专用的基于硬件的系统来实现,或者可以用专用硬件与计算机指令的组合来实现。
另外,在本发明各个实施例中的各功能模块可以集成在一起形成一个独立的部分,也可以是各个模块单独存在,也可以两个或两个以上模块集成形成一个独立的部分。
所述功能如果以软件功能模块的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(rom,read-onlymemory)、随机存取存储器(ram,randomaccessmemory)、磁碟或者光盘等各种可以存储程序代码的介质。需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步定义和解释。
- 还没有人留言评论。精彩留言会获得点赞!