一种基于分层块克里格模型的流动人口监测网布局优化方法与流程
本发明涉及一种监测抽样布局方法,属于地球空间信息技术领域。
技术背景
抽样调查是用抽样数据推断调查对象的属性,相对于普查而言,抽样调查具有费用低、速度快和精度高等优点。一般来说,在试验费用固定的情况下,样本设计应使在用样本数据来估计抽样区域变量的空间分布时,估计值达到最高精度;而在样本精度要求已经确定的情况下,样本设计应使得抽样的费用最小。怎样在样本精度和费用之间达到较好的平衡,就是抽样的优化问题。
抽样按照是否考虑样本的空间相关性和空间异质性,可以划分为经典抽样和空间抽样(王劲峰,2009)。经典抽样是以cochran(1977)的专著为代表,其理论建立在样本相互独立的假设之上。经典抽样可以用于空间对象的调查,虽然输入简单,较易使用,但效率较低。空间抽样调查则考虑了样本的空间自相关特性和空间异质性,效率较高(wangetal.2012a)。
目前,我国流动人口抽样方法主要是经典抽样方法,以分层、多阶段、与规模成比例的pps(即probabilityproportionatetosizesampling)抽样方法为主。2009~2013年,国家卫生计生委(原国家人口计生委)连续5年进行流动人口动态监测调查,按照随机原则在31个省(区、市)和新疆生产建设兵团抽取样本点,采取pps抽样方法进行抽样。然而流动人口的分布与地理空间是高度相关的,不同类型区的流动人口具有不同的空间分布特征(刘盛和,2010),这种传统的抽样方法没有考虑空间差异和地理特征,监测网络布局没有建立在对全国流动人口地域类型划分的基础上,典型性和代表性有待进一步提高,数据缺乏验证机制,采集成本极高,调查网点布局不尽合理,监测网络需要进一步优化。
常用的空间采样优化中的采样方式主要可以分为基于设计的采样(design-basedsampling)方式(cochran1977,degruijteretal.1990)和基于模型的采样(model-basedsampling)(brusetal.1997,wangetal.2012a)。基于设计的采样方式包括简单随机采样,系统采样和分层采样。基于模型的采样主要应用于研究对象表现出显著的空间自相关特征。
针对流动人口在空间上的自相关性,本发明采用基于模型的采样方法来说优化流动人口的采样点位置。基于地统计的采样优化是最为常见的基于模型的优化方法。它通过定义目标函数来搜索最佳的采样方案,这个目标通常为平均克里格误差方差最小(vangroenigenetal.1998,steinetal.2003,wangetal.2012c)。然而,流动人口的估算是以区域为单位,即某区域流动人口总体的估计误差方差最小。在这种情况下,待估计的不是区域上的所有点,而是整个研究区。也就是说,估计的单元由空间点到面区域。从理论上,目标为最小化块克里格方差(verhoef2002,gruijteretal.2006)。针对流动人口的空间异质性,本发明通过区划或分区的方法来定量衡量每个分区的变异特征,可以提高监测网优化的效率,用较少的观测点可以得到获得统计单元较可靠的估计值,有助于探索人口流动过程的成因和影响因素。
技术实现要素:
本发明解决的技术问题:克服现有技术的不足,传统的流动人口抽样方法没有考虑流动人口的空间差异和地理特征,监测网络布局没有建立在对流动人口地域类型划分的基础上,不具有典型性和代表性。本发明通过能捕捉变量空间异质性和空间相关性的空间抽样方式,对于流动人口的抽样,采取将基于克里格方法的监测网优化方法与传统的空间分层抽样相结合的空间抽样方法,得到具有空间异质性的流动人口的监测网布局优化。
本发明的技术方案:一种基于分层块克里格模型的流动人口监测网布局优化方法包括如下步骤:
步骤1、对研究区域相关数据与先验信息进行收集处理,先验数据包括研究区以往的分区流动人口和总人口的数量,研究区行政区划数据,在arcgis中将研究区域流动人口数量进行空间化;
步骤2、根据步骤1获取的研究区流动人口数量通过分区的方式将流动人口研究区域划分为几个相同均质的区域,即对于每个区域认为是相对均值的,满足二阶平稳假设的随机场;将流动人口研究区域划分为几个相同均质的区域过程如下:
(1)在arcgis中先根据流动人口数量进行分区,采用自然断点方法进行分区;
(2)在分区后,若存在空间上不连续的地区需要进行合并处理,主要原则为若某一街道或地区镶嵌到一种流动人口数量类型区内,则将该街道或地区合并到该类型区内。样处理,主要是基于遵循区域共轭性原则的考虑,要保持地域完整性,必须要将镶嵌的区域进行处理;对于同一类型区内,空间上不连续的街道或地区进行处理的方式,主要根据这个街道或地区与空间相邻类型的差异进行合并处理。
步骤3、根据步骤1中的研究区流动人口数量,以研究区各个分区的几何中心为样本点,各个分区即为分层克里格中的分层,根据各分层分别建立各分层克里格变异函数;对于研究区域a被分为l个层,第k个层ak定义为由一组空间点s构成的集合,有ak={s∈a,sk=s(s)},sk表示第k层空间中的点,对于k层的变异函数的计算:
k代表研究区域的第k个层,si表示第k个层空间上的一个点,z(si)为空间点si点的属性值,n(h;sk)为点对之间观测点的对数。
变异函数采用指数模型进行拟合:
其中h为两点间距离,c(0)为块金值,c为偏基台值,a为变程。
步骤4、在布设样本点之前,首先要确定总样本量以及各层观测点数量,通过研究样本量和对应目标函数的关系曲线,目标函数为区域总量估计误差的方差最小,区域总量估计误差的方差用astrbkv表示;区域总量估计误差的方差计算过程为:
ai为对应分区区块的面积,σ2bk为块克里格方差:
μ(v)为拉格朗日乘数,cz为点与点之间的协方差,
最小区域总量估计误差通过空间模拟退火来获得,获得步骤如下:
第一步:设置一个初始的,某一样本量下的样本布设方案s0,并计算对应的目标函数值astrbkv;
第二步:对于方案sk,随机移动一个样本点n得到一个新的方案sk+1,其中,样本点n的移动方向是随机选择的,移动长度是介于零和最大值之间的随机值,并且最大移动距离随着模拟退火循环次数的增加而减小;
第三步:计算新方案sk+1的目标函数值astrbkv,如果新方案的目标函数值大于旧方案的目标函数值,那么接受新方案,并且循环次数为k+1;否则按照一定概率接受新方案,并且接受变差了的方案的概率随着循环次数的增加而逐渐减小,这样做的目的是防止算法陷入局部最优状态;
第四步:返回第二步,如果接受了新方案,则用方案sk+1作为初始样点布设方案,否则继续采用方案sk;
第五步:循环到一定次数或者达到一定的目标函数值后停止,输出该样本量下的最小区域总量估计误差,确定各层的最优样本量。
绘制不同样本量与区域总量估计误差的最小方差关系曲线图。观察曲线变化,若样本量达到某个值时,样本量的增加并不能显著地降低最后的astrbkv值,则选择该样本量为总布设样本量;
步骤5、以步骤4中确定的样本量,以astrbkv为目标函数,通过空间模拟退火来确定最终的每个分层样本点布设的空间位置,目标函数随着搜索次数的增加而快速收敛,当循环一定次数后,循环终止,得到最终样本点的空间分布。步骤如下:
第一步:设置一个初始的(随机)样本布设方案p0,并计算对应的目标函数值astrbkv;
第二步:对于方案pi,随机移动一个样本点m得到一个新的方案pi+1,其中,样本点m的移动方向是随机选择的,长度是介于零和最大值之间的随机值,并且最大移动距离随着模拟退火循环次数的增加而减小;
第三步:计算新方案pi+1的目标函数值astrbkv,如果新方案的目标函数值大于旧方案的目标函数值,那么接受新方案,并且循环次数为i+1;否则按照一定概率接受新方案,并且接受变差了的方案的概率随着循环次数的增加而逐渐减小,这样做的目的是防止算法陷入局部最优状态;
第四步:返回第二步,如果接受了新方案,则用方案pi+1作为初始样点布设方案,否则继续采用方案pi;
第五步:循环到一定次数或者达到一定的目标函数值后停止,输出样本的空间坐标位置和最优的目标函数值。
本发明与现有技术相比的优点在于:
(1)传统的流动人口抽样方法没有考虑流动人口的空间差异和地理特征,监测网络布局没有建立在对流动人口地域类型划分的基础上,不具有典型性和代表性。本发明通过能捕捉变量空间异质性和空间相关性的空间抽样方式,对于流动人口的抽样,采取将基于克里格方法的监测网优化方法与传统的空间分层抽样相结合的空间抽样方法,得到具有空间异质性的流动人口的监测网布局优化。该方法通过定义合理的目标函数,进而利用空间模拟退化算法来寻找最佳的布设方案,达到最佳的流动人口采样方案。分层块克里格法可以同时考虑变量流动人口在空间上的相关性和异质性的特征,通过区划或分区的方法来定量衡量每个分区的变异特征,通过最小化块克里格方差来定义搜索方案,优化后的监测网络可以较好地捕捉研究区内流动人口的空间特征。
(2)本发明采用的方法可以在采样之前就得到待布设网络的估计误差的方差,并且在空间异质面条件下,分层块克里格法可以提高变量的均值估算精度,进而可以提高监测网优化的效率,用较少的观测样点可以得到获得统计单元较可靠的估计值。
附图说明
图1为本发明的主流程图;
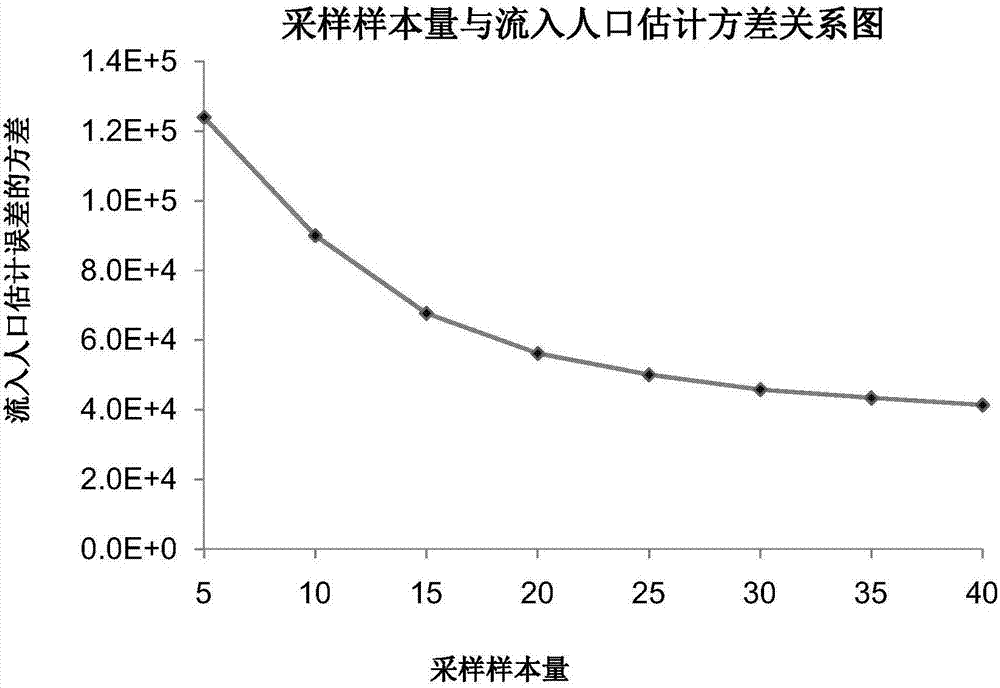
图2朝阳区选取的采样样本量与流入人口估计标准差关系图;
图3朝阳区流动人口空间采样优化结果。
具体实施方式
如图1所示,以北京市朝阳区流动人口抽样布局优化为例,本发明的具体实施步骤如下:
步骤1、为了辅助设计朝阳区流动人口抽样,需要历史的人口普查数据,收集到的数据包括2010年朝阳区各个街道上流动人口和总人口的数量,以及朝阳区的行政区划数据。朝阳区常住人口3545137人,流入人口1514822人,流入人口占常住人口的42.7%。因此,朝阳区以人口流入为主。
从空间上来看,朝阳区的流动人口主要位于四环-五环之间的区域。
步骤2、对于朝阳区,更关注的是外来人口流入,因此,流动人口地域类型划分主要考虑流入人口指标。
在流动人口监测网设计之前,需要根据研究区内流动人口的不同空间变异特征,将研究区分为不同的区域。首先根据流入人口总量进行分区,采用自然断点方法,分为4个区。分区后的图明显看出,朝阳区的流入人口空间分布呈现明显的梯度特点,流入人口主要集中在城郊过渡带地区,如十八里店、崔各庄、平房、望京、来广营、王四营、高碑店及大屯等街道地区。城市核心区由于其人口容量较小,相对流入人口量也较小。
根据分区原则,将朝阳区按流入人口总量进行划分。根据分区的结果,按照流入人口的比例,将朝阳区分为3个等级,分别为流入人口低值区、较高区、和高值区。而对于流动人口高值区空间上不连续,为此,将高值区分为两个子区,分别为高值区1和高值区2,总计四个分区。
步骤3、在四个分区中,以街道的几何中心为样本点,分别建立各个分区的变差函数。在arcgis中将分区流动人口空间化数据输入,在工具箱中的地统计分析工具可以自动拟合各个分区的最优变差函数。
步骤4、在优化之前,需要确定合适的样本量。即如何确定合适的样本来得到流入人口的可靠的估计结果。朝阳区共有43个街道,为此,本发明研究了样本量在5,10,15,20,25,30,35,40情况下,朝阳区流入人口估计方差的变化。结果如图3所示,流动人口抽样精度随着样本量的增加而增加。当样本达到20以后,抽样精度增加减缓。为此,将样本量确定为10,15,20,分别表征低样本率,中样本率和高样本率。
步骤5、对朝阳区的43个街道中,从四个分区中分别抽取10、15、20个乡镇街道,以astrbkv为目标函数,通过空间模拟退火算法来确定最终的10、15、20个流入人口样本点的空间位置。和预期的一致,目标函数随着搜索次数的增加而快速收敛。空间模拟退火整个过程可以用r等语言编程实现。
从结果中来看,四个分区表现出不同的抽样比和格局。对于流动人口低值区域,抽样比较高,样本分布也比较分散。而对于流动人口高值区域,对应的抽样比较高。当样本量达到20的时候,甚至高值区域的抽样比达到了80%以上。
图3为朝阳区流动人口空间采样优化结果,即分别为抽取10、15、20个样本点时,样本点的分布地区。
实验中将朝阳区根据流入人口的比例,将朝阳区分为流动人口高值区,中值区和低值区,利用分层的思想,采用基于块克里格模型去优化抽样单元。目的是使得抽样的乡镇街道在空间上能够代表流动人口的空间分布格局,从而利用抽样结果估计朝阳区总的流动人口总量。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本邻域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的权利要求范围之内。
- 还没有人留言评论。精彩留言会获得点赞!