基于深度学习的安卓恶意应用的检测和分析方法与流程
本发明涉及恶意软件的检测领域。更具体地,涉及一种基于深度学习的安卓恶意应用的检测和分析方法。
背景技术:
安卓操作系统是一种基于linux的自由及开放源代码的操作系统,主要使用于移动设备,如智能手机和平板电脑,是目前使用最为广泛的移动终端。随着智能手机和移动设备的快速发展,安卓平台服务已经成为大部分网络用户不可或缺的要素。与此同时,移动恶意软件也快速增长成为威胁网络安全和隐私的重要源头。最近的研究报告指出,安卓系统已经占据了87.6%的市场份额,同时高达91.1%的恶意软件来自于安卓市场。大量的安卓恶意软件对企业及个人信息造成了威胁。安卓恶意应用的检测已经成了现今移动互联网发展的重要技术保障,研究和实现高精准的安卓恶意应用检测具有很强的现实意义和实用价值,被相关学术界和业界所关注。安卓平台的开放性导致其成为了恶意应用攻击的重点,随着伪装、加壳等恶意软件的不断出现,如何提高安卓系统恶意软件检测的准确率,并且降低人工参与的难度,是当前亟待解决的问题。
当前,随着安卓移动智能终端的迅速普及、安卓应用(app)的种类、数量也正在呈井喷式增长。然而,随之而来的网络与信息安全问题司益凸显,移动智能终端安全事件层出不穷,移动恶意应用肆意泛滥,个人隐私窃取、资费消耗等安全问题时有发生,严重影响行业的健康发展。而上述这些问题,大多是由移动恶意代码造成的。移动恶意代码通常在app软件开发或二次打包过程中植入,通过诱骗欺诈、障私窃取、恶意扣费等方式莲取经济利益或传播垃圾信息。其中恶意在用增长尤其迅猛,给智能终端用户带来了严重的经济损失。
目前,安卓恶意应用检测技术手段主要依赖于一种风险评估机制,这种评估机制可以在恶意应用软件安装前提示并警告用户正在安装的应用所需求的系统权限信息。实际上,由于这种技术提示的“应用所需权限”过于单一和片面,很难使得普通用户仅根据此项信息能够快速地分辨出是否属于恶意应用。实践表明,许多的恶意应用与正常应用很可能所需求的权限是一致的,这使得用户更加难以分辨恶意应用和正常应用。因此,构建准确的安卓恶意家族分类和行为描述的特征子集十分有必要。
恶意家族是指具有相似性、继承性、以及衍生性的恶意软件集合,在恶意软件检测领域逐渐引起注意。然而针对恶意家族的研究,目前仍然存在如下问题:
1、恶意家族的界定不清,针对同一个恶意软件的样本,不同的杀毒软件可能将其定义为不同的家族;
2、家族识别方法不完善,不论是基于特征的检测,还是基于异常的检测方法,在当前的研究中都没有广泛接受的结论。恶意家族难以识别,主要是因为恶意软件本身可能会具有不只一种恶意行为,同时,也没有确定的结果指出,哪些特征可以有效的用于恶意家族的识别;
3、针对新出现的类型难以处理,恶意行为的伪装性和复杂度逐渐增强,因此对于新出现的恶意软件,通常难以在第一时间检测和分析,这也导致了在检测上的滞后性。
深度学习是近年来兴起的一种新的机器学习领域。传统的及其学习模型,像直齿向量机、逻辑回归、决策树、贝叶斯以及传统神经网络模型,均被认为含有少于三层的计算单元和浅层的学习构架。与之不同,深度学习拥有较深层次的学习构架,能够更好地模仿人脑更聪明的学习和认知。实际应用中,深度学习更多的是一种构架设计思想,可以采用不同的思路方式,利用多种不同的算法和方法共同实现。
因此,需要提供一种基于深度学习构建的特征数据集,来实现对恶意家族的识别和行为分析的方法。
技术实现要素:
本发明的目的在于提供一种基于深度学习构建的特征数据集来实现对恶意家族的识别和行为分析的方法,将深度学习方法应用于安卓恶意软件检测中,并且通过应用特征选择方法,实现恶意家族的分类,进一步挑选出能够进行恶意家族行为分析的特征子集。
为达到上述目的,本发明采用下述技术方案:
一种基于深度学习的安卓恶意应用的检测和分析方法,包括:
基于类别提取恶意应用特征集;
采用深度学习算法对应用样本进行恶意性检测并依据检测结果将应用样本分为恶意应用和正常应用;
采用特征选择算法对恶意应用特征进行排序;
采用机器学习分类算法对恶意家族进行识别;
构建恶意家族特征子集并进行恶意家族行为分析。
优选地,采用静态分析方法提取恶意应用特征集,特征集至少包括以下类别的特征:可疑api调用(suspiciousapicalls)、代码相关模式(coderelatedpatterns)、硬件特征(hardwarefeatures)、过滤的intent对象(filteredintents)、请求的权限(requestedpermissions)、受限制的api调用(restrictedapicalls)和应用的权限(usedpermissions)。
上述特征为算法的有效输入。
优选地,对应用样本进行恶意性检测之前,还包括以下步骤:
通过清洗、构建特征表、数值化映射过程,并采用word2vector技术,将所提取的安卓软件特征处理为可以供深度学习训练的特征矩阵。
对应用样本进行恶意性检测时,通过不同的参数对比,给出不同数据集的参数建议。
优选地,采用特征选择算法对恶意应用特征进行排序具体包括:
采用fisher特征选择算法对恶意软件特征进行排序并给出恶意家族特征的重要性序列,基于重要性序列挑选特征子集;
基于频率的特征筛选算法,在特征选择结果的基础上挑选出能够描述恶意家族行为的特征。
进一步优选地,基于频率的特征筛选算法基于当前特征在恶意样本和正常样本中出现的概率,判断该特征是否能够用来描述恶意家族的特征。
进一步优选地,基于频率的特征筛选算法具体包括:
针对特征选择排序结果中的一个特征,计算该特征在两个类别样本中分别出现的概率;
当出现在恶意样本中的概率大于出现在正常样本中的概率时,则认为当前特征能够用来描述恶意家族的特征;
当出现在正常样本中的概率大于或等于出现在恶意样本中的概率时,则认为当前特征不能用来描述恶意家族的特征。
优选地,对恶意家族进行识别采用svm机器学习算法,将构建出的特征作为输入来识别出经过训练的恶意家族类型。
优选地,结合特征选择、特征筛选和特征子集进行恶意家族行为分析,用于反映并分类当前家族的恶意行为。
本发明的有益效果如下:
本发明提出的基于深度学习的安卓恶意应用的检测和分析方法,将深度学习方法应用于安卓恶意应用检测中,并且通过应用特征选择方法,实现恶意家族的分类,进一步挑选出能够进行恶意家族行为分析的特征子集,通过特征子集的构建对恶意家族进行行为分析。本发明能够提高现有的安卓恶意应用分类的准确率,改善当前安卓市场人工审核造成的工作量巨大、准确率不高的问题,有助于根据恶意应用的行为采取有针对性的防护措施。
附图说明
下面结合附图对本发明的具体实施方式作进一步详细的说明。
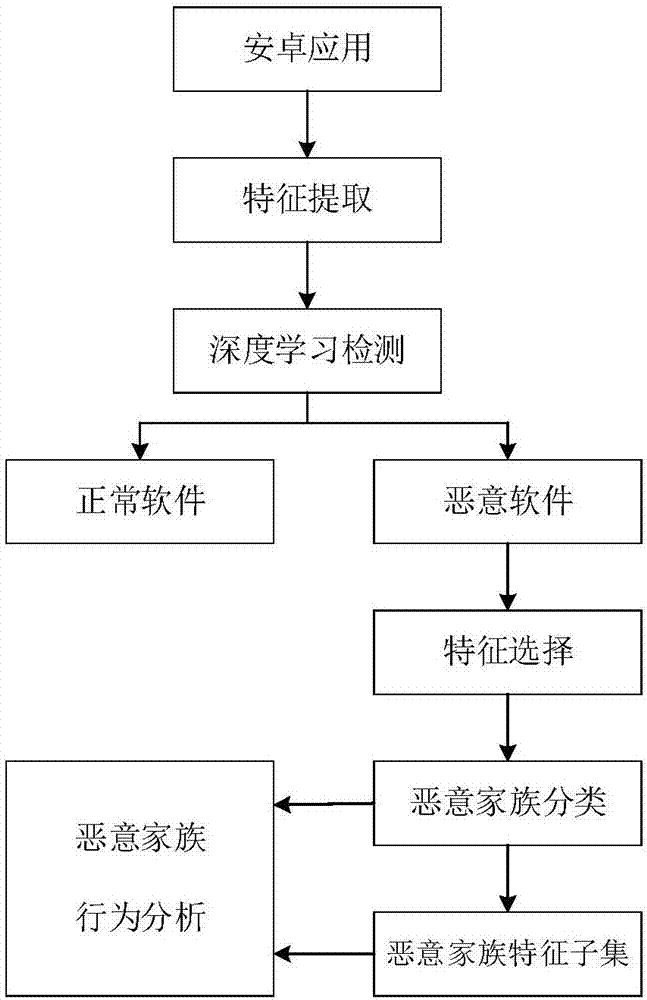
图1示出一种基于深度学习的安卓恶意应用的检测和分析方法步骤图。
图2示出实施例中基于深度学习的安卓恶意应用的检测和分析方法流程图。
图3示出实施例中cnn恶意软件分类结果。
图4(a)示出实施例中s_l1的cnn恶意软件分类roc曲线图。
图4(b)示出实施例中s_l2的cnn恶意软件分类roc曲线图。
图4(c)示出实施例中s_l3的cnn恶意软件分类roc曲线图。
图4(d)示出实施例中s_l4的cnn恶意软件分类roc曲线图。
图4(e)示出实施例中s_l5的cnn恶意软件分类roc曲线图。
图5示出实施例中排名前20的特征。
图6示出实施例中特征子集。
图7示出实施例中十个家族的识别率对比柱形图。
具体实施方式
为了更清楚地说明本发明,下面结合优选实施例和附图对本发明做进一步的说明。附图中相似的部件以相同的附图标记进行表示。本领域技术人员应当理解,下面所具体描述的内容是说明性的而非限制性的,不应以此限制本发明的保护范围。
深度学习通过组合低层特征的训练和学习,形成抽象的高层特征表示,从而用以发现数据的分布式特征。lecuny等提出的卷积神经网络(cnn)算法,是第一个真正多层结构的学习算法,利用空间相对关系减少参数数目,从而提高训练的性能。cnn是一种特殊的深层神经网络模型,采用局部感受野、权值共享、子采样等技术,来实现对位移、比例缩放、以及一些其他变形操作的不变性。其中,局部感受野是指每一个神经元从上一层的局部接受域得到输入,提取局部特征。当一个特征被提取出来时,它相对于其他特征的位置被近似的保留下来,因此其精确位置变的不那么重要,因此能够降低图片位移和变形带来的影响。权值共享是指每个卷积核通过相同的权值覆盖整个可视域,这些共享的单元构成一个特征映射。权值共享的原因在于重复的单元能够对特征进行识别,而不考虑它在可视域中的位置。每一个卷积层后面都跟有一个实现子采样的计算层,由此特征映射过程中的分辨率降低,这种操作使特征映射的输出对平移和其他形变的变形敏感度下降,同时也降低参数的数量。
如图1所示,一种基于深度学习的安卓恶意应用的检测和分析方法,包括以下步骤:
s1:基于类别提取恶意应用特征集。采用静态分析方法提取恶意应用特征集,特征集至少包括以下类别的特征:可疑api调用(suspiciousapicalls)、代码相关模式(coderelatedpatterns)、硬件特征(hardwarefeatures)、过滤的intent对象(filteredintents)、请求的权限(requestedpermissions)、受限制的api调用(restrictedapicalls)和应用的权限(usedpermissions),这些特征将作为算法的有效输入。
s2:采用深度学习算法对应用样本进行恶意性检测并依据检测结果将应用样本分为恶意应用和正常应用。其处理过程包括:采用word2vector技术,将所提取的安卓软件特征通过清洗、构建特征表、数值化映射过程,处理为可以供深度学习训练的特征矩阵;采用深度学习算法对应用样本进行恶意性检测并依据检测结果将应用样本分为恶意应用和正常应用,其中,通过不同的参数对比,给出不同数据集的参数建议。
s3:采用特征选择算法对恶意应用特征进行排序。其处理过程包括:采用fisher特征选择算法对恶意软件特征进行排序并给出恶意家族特征的重要性序列,基于重要性序列挑选特征子集;基于频率的特征筛选算法,在特征选择结果的基础上挑选出能够描述恶意家族行为的特征。
基于频率的特征筛选算法基于当前特征在恶意样本和正常样本中出现的概率,判断该特征是否能够用来描述恶意家族的特征。具体地,针对特征选择排序结果中的一个特征,计算该特征在两个类别样本中分别出现的概率;当出现在恶意样本中的概率大于出现在正常样本中的概率时,则认为当前特征能够用来描述恶意家族的特征;当出现在正常样本中的概率大于或等于出现在恶意样本中的概率时,则认为当前特征不能用来描述恶意家族的特征。
s4:采用机器学习分类算法对恶意家族进行识别。对恶意家族进行识别采用svm机器学习算法,将构建出的特征作为输入来识别出经过训练的恶意家族类型。
s5:构建恶意家族特征子集并进行恶意家族行为分析。结合特征选择、特征筛选和特征子集进行恶意家族行为分析,用于反映并分类当前家族的恶意行为。
下面结合一个具体实施例对检测与分析过程进行说明
如图2所示,本发明实施例实现了一个集成深度学习方法cnn、特征选择方法fisher、机器学习算法svm以及自定义的特征筛选方法,从而进行安卓恶意软件检测、恶意家族识别、以及恶意家族行为分析。
步骤一构建样本数据集
首先,构建安卓恶意软件和正常软件的测试集。本实施例中构建两种类型的数据集。从国内典型的安卓恶意软件第三方市场中收集应用软件样本,并且采用virustotal进行检测和标记,最终构建出1000个正常样本、1000个恶意样本作为测试数据集。采用androguard提取样本的特征,共包含七个类别、34570个维度的特征。这些数据将用来显示cnn恶意软件分类的过程。
然后,构建恶意家族的数据集。由于恶意家族的样本通常难以获得,并且各家族的类别通常也不平衡,因此在本实施过程中,通过单独收集样本,构建了包含10个恶意家族的数据集,分别是:fakeinst,dowgin,opfake,agent,plankton,wapsx,adwo,droidkungfu,smsreg,gingermaster。
应注意的是,构建不同样本的过程,不影响本发明方法的连续性应用。
步骤二cnn恶意软件分类
鉴于cnn有不同的实现方法,本实施例中选择了以顺序模型为例,分别进行了五组比较,其中训练样本时采用不同的模型类别,从1层到5层,卷积核设为5*5,验证指标包含了误报率(fpr)、检测率(tpr)、准确率(acc),敏感率(spc),以及精确率(ppv)。
从图3中可以看出,随着训练层数的增加,分类准确率逐渐上升,其中s_l4和s_l5能够达到相同的tpr,但是s_l5有更好的准确率acc,以及更低的误报率fpr。进一步比较五组实验的roc曲线,从图4(a)~(e)中可以看出,当fpr较低时,s_l4的分类效果略高于s_l5,然而当fpr逐渐升高时,各组的tpr逐渐相似。总体而言,采用深度学习方法能够达到较高的分类准确率99.25%。
步骤三fisher特征选择方法特征排序
验证特征选择方法应用于特征排序中的有效性,需要将十个恶意家族中的所有类别的特征分别采用fisher算法进行排序。这里将包含93个维度的“申请权限”作为特征的样例,以fakeinst,dowgin,opfake三个家族作为样例,按照fisher特征选择方法对其进行排序,排序结果中的前20个特征如图5所示。可以看出,特征选择算法能够有效的实现对特征的排序。
步骤四特征筛选算法
特征筛选算法是在特征选择方法的基础上对结果的进一步处理。特征选择方法能够挑选出那些倾向于将两个类别样本区分开的特征,因此所选择出来的特征,不能够作为有效描述恶意家族特征的特征。因此提出一种特征筛选算法,从而对特征进行进一步的筛选,挑选出能够有效描述恶意家族的特征。定义五元组[f,n,m,ns,r],其中包含如下定义:
(1)f:当前待评估的特征类别,特征的维度表示为dim_f,该特征集中的某一个特定的维度,即某一个特定的特定,表示为f_i;
(2)n:样本数,其中n_be表示正常(benign)组中包含的样本数;n_ma表示恶意(malicious)组中包含的样本数;
(3)m:特征数,其中m_be表示正常(benign)在当前特征数;m_ma表示恶意(malicious)组当前的特征数。采用样本数与特征维度的乘积来估计特征数,即m_be=n_be*dim_f。m-ma=n_ma*dim_f;
(4)ns:某一个特征f_i在特征集中出现的次数。ns_be表示特征f_i在正常(benign)中出现的次数,ns_ma表示特征f_i在恶意(malicious)中出现的次数。
(5)r:特征数量比值,用来衡量当前特征f_i是否纳入特征子集。
因此将根据r值的大小,来选择是否将当前特征纳入特征集中。
步骤五5、构建恶意家族特征子集并进行行为分析
以“申请权限”、“硬件”、“可疑api调用”三个类别的特征,以三个家族作为样例,通过特征选择和特征筛选算法的处理,得到的关键特征结果如图6所示。其中“申请权限”类每个家族选择10个特征,其余两个类别分别包含5个特征。根据这些特征的选择结果,可以对特定家族的行为进行分析。例如,fakeinst家族中,包含了大量的与短消息、网络相关的权限:“receive_sms”,“send_sms”,以及“access_network_state”,在硬件特征方面,更为关注手机状态以及网络状态,例如“telephony”,“bluetooth”,在api调用方面,则包含了“sendsms()”,“httppost()”,“readsms()”,这说明这一家族的恶意行为倾向于收集操作系统状态或手机的状态,并且向外界发送信息等。
步骤六、svm进行恶意家族识别
采用上述构建出来的20个特征,分别构建出十个恶意家族的数据集。在一次分类中,将当前家族标记为一类,同时将所有的其他家族标记为另一类,据此检验所构建出来的特征对于识别当前家族的能力。采用svm算法对数据集进性分类,十个家族的识别结果如图7所示,可以看出,识别效果最好的plankton家族可以达到超过99%的准确率。
综上所述,本发明实施方式所采取的方法,能够结合深度学习的优势,并且通过所提出的特征筛选方法,能够在特征选择的基础上,构建出恶意家族的描述性特征,从而实现对安卓恶意软件的检测,从而根据恶意行为有针对性的预防,降低人工分析的难度,提高检测的准确率。
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定,对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动,这里无法对所有的实施方式予以穷举,凡是属于本发明的技术方案所引伸出的显而易见的变化或变动仍处于本发明的保护范围之列。
- 还没有人留言评论。精彩留言会获得点赞!