基于显著故障变量提取的卷烟制叶丝段故障诊断方法与流程
本发明涉及卷烟制叶丝段Sirox增温增湿机和KLD薄板烘丝机的故障变量提取、故障离线建模与在线故障诊断技术。
背景技术:
随着我国烟草行业整体实力的不断提高,有效提升设备的智能化水平和高效运行能力已成为卷烟工业企业关注的焦点,状态监测与故障诊断是提升设备智能化和高效运行的重要手段。王伟[王伟,赵春晖,楼卫东,等.基于相对变化分析的多模态卷烟制叶丝段故障监测[J].烟草科技,2015,48(12):78-86.]等提出一种基于相对变化分析的多模态卷烟制叶丝段故障监测方法,能够及时有效地检测出设备故障。故障诊断可在检测到故障后更及时的定位故障,缩小故障的判断范围,从而使维保人员的注意力集中到发生故障的部件上来。对于故障诊断问题,目前主要有两类方法:基于统计理论的方法(贡献图法[Nomikos P,MacGregor J F.Multivariate SPC charts for monitoring batch processes[J].Technometrics,1995,37(1):41-59.]、结构化残差法[Gertler J,Li W,Huang Y,et al.Isolation enhanced principal component analysis[J].AIChE Journal,1999,45(2):323-334.]和信号重构法[Dunia R,S J Qin.Subspace approach to multidimensional fault identification and reconstruction[J].AIChE Journal,1998,44(8):1813-1831.])和基于模式分类的方法(特征方向法[Zhang J,Martin E B,Morris A J.Fault detection and diagnosis using multivariate statistical techniques[J].Chemical Engineering Research and Design,1996,74(1):89-96.,Chiang L H,Russell E L,Braatz R D.Fault diagnosis in chemical processes using Fisher discriminant analysis,discriminant partial least squares,and principal component analysis[J],Chemometrics and Intelligent Laboratory Systems,2000,50(2):243-252.]、统计距离法[Kano M,Hasebe S,Hashimoto I.A new multivariate statistical process monitoring method using principal component analysis[J].Computers and Chemical Engineering,2001,25(7-8):1103-1113.]和支持向量机法[Chu Y,Qin S J,Han C.Fault detection and operation mode identification based on pattern classification with variable selection.Industrial&Engineering Chemical Research,2004,43(7):1701-1710.,Chiang L H,Kotanchek M E,Kordon A K.Fault diagnosis based on Fisher discriminant analysis and support vector machines[J].Computers and Chemical Engineering,2004,28(8):1389-1401.]),其中贡献图故障诊断方法简单易行,且不需要预先的过程知识,得到了广泛的应用。但由于过程变量间的强相关性,故障变量的信息会传播到其它变量上,使得故障变量贡献与正常变量贡献之间的差异减少,甚至出现正常变量贡献大于故障变量贡献的情况,导致错误的诊断结果[Yue H H,Qin S J.Reconstruction-based fault identification using a combined index[J].Industrial&Engineering Chemistry Research,2001,40(20):4403-4414.]。基于Fisher判别分析(Fisher Discriminant Analysis,FDA)提取特征方向的故障诊断方法利用正常工况和各种故障工况的历史数据进行建模,其故障诊断能力要优于贡献图故障诊断方法[6]。但是基于FDA提取特征方向的故障诊断方法存在类内离散度矩阵奇异性问题,同时它将所有监测变量作为一个整体建立诊断模型而没有分离特殊的故障变量,在一定程度上制约了该方法的应用效果。
技术实现要素:
本发明提出一种基于显著故障变量提取的卷烟制叶丝段故障诊断方法。改进Fisher判别分析通过两步特征提取避免了类内散布矩阵奇异性问题,通过迭代循环提取足够判别成分,采用数据紧缩手段保证了成分间的垂直性,实现对故障方向的高效提取;沿故障方向通过变量贡献度分析,度量不同变量对故障的不同影响,通过变量选择策略区分对故障有重要影响的故障变量和没有影响的一般变量,进而分别建立故障变量和一般变量的诊断模型。利用制叶丝段设备实际运行数据验证所提故障诊断方法的有效性,以期对设备故障进行及时准确识别。
本发明所采用的具体技术方案如下:
基于显著故障变量提取的卷烟制叶丝段故障诊断方法,包括:
1)收集卷烟制叶丝段Sirox增温增湿机和KLD薄板烘丝机运行过程的正常工况数据Xn(Nn×J)和典型故障工况数据Xf,i(Nf,i×J),针对正常工况数据和每种典型故障工况数据采用改进Fisher判别分析方法提取每种故障对应的故障方向Ri(J×R)。
2)沿提取的故障方向,分别计算正常工况数据、故障工况数据对应的特征矩阵Tn,i、Tf,i。再根据马氏距离分别计算正常工况数据、故障工况数据对应的统计量Dn,i,m2、Df,i,m2,根据正常工况数据对应统计量的密度分布确定控制限
3)如果故障工况数据对应的统计量Df,i,m2超过了控制限进行故障变量提取。沿故障方向Ri分别计算正常工况、故障工况的变量贡献度根据计算的变量贡献度比例的大小确定最重要的故障变量j,将故障变量j移到故障变量数据库。更新正常工况数据和故障工况数据重新计算故障方向进行故障变量提取,当故障工况数据对应的统计量在控制限以内时,表明所有故障变量均已提取。
4)通过故障变量的选取,可以将每一种故障工况的监测变量分为故障变量和一般变量。由于不同的故障工况可能具有相同的故障变量,但这些故障变量的相关关系不同,仅仅利用选取的故障变量不能准确区分不同的故障工况。因此,基于每种故障工况分离后的故障变量和一般变量,分别建立故障诊断模型揭示该类故障工况的故障影响,并计算得到故障评价统计量。
5)在第k个采样时刻获得一个新的观测数据xnew(J×1),采用王伟等人[1]提出的基于相对变化分析的多模态卷烟制叶丝段故障监测方法检测是否有异常发生。存在异常时,对于新检测的故障数据,进行在线故障诊断。通过迭代评价新检测故障数据与每种故障工况的相似性,确定该故障数据属于哪种故障工况。
在步骤1)中,FDA是广泛应用于模式识别的一种降低空间维数的模式分类方法,通过线性变换找到最优的Fisher判别向量,使得类间离散度最大、同时类内离散度最小。设Xi(i=1,2,…C)为第i类的Ni×J维数据矩阵,其中C为数据类的总数,Ni为第i类的测量样本数,J为测量变量数。Xi第k行的转置是列向量xk,则第i类的类内离散度矩阵为:
其中为第i类数据的J维平均值向量。
所有数据类的总体类内离散度矩阵为:
类间离散度矩阵为:
其中为所有数据类的J维平均值向量。
寻找最优的Fisher判别向量使得类间离散度最大、同时类内离散度最小,即对如下的目标函数求取最优的Fisher判别向量:
其中w为所求的最优Fisher判别向量。
式(4)等价于求解如下的广义特征值问题:
Sbw=λSww (5)其中λ为对应w的特征值,其大小反映了原始C个数据类在w方向的分离程度。
如果类内离散度矩阵Sw为非奇异阵(即可逆),则式(5)可以转化为一个标准特征值问题形式:
Sw-1Sbw=λw (6)
可以获得与M个非零特征值λm(m=1,2,…M)对应的判别向量wm。第一个Fisher向量是具有最大特征值的判别向量,第二个Fisher向量是具有次大特征值的判别向量,依次类推。因为Sb的秩小于C,所以最多有C-1个非零特征值,即M≤C-1,由此可构建判别矩阵W=[w1,w2,…,wM]。当不同类的数据投影到判别向量w1时(即沿着w1方向),类间具有最大分离度。
FDA方法存在3点局限:1、类内离散度矩阵Sw要求为非奇异阵,实际中该条件有时不能满足;2、求取的判别向量个数受限于类间离散度矩阵Sb的秩大小(即M≤C-1),然而M个判别向量有时不能充分揭示不同数据类之间的差异;3、M个判别向量wm之间的关联性越小,判别矩阵W的性能越好,求取的判别向量无法保证相互垂直。
具有正交判别向量的改进Fisher判别算法的计算步骤如下:
①数据预处理
计算每个数据类的数据均值向量并根据式(2)计算得到类内离散度矩阵Sw(J×J)和类间离散度矩阵Sb(J×J)。
②判别向量的首次提取
通过最小化类内离散度矩阵Sw计算判别向量:
J1(w)=min(wTSww) (7)
求取判别向量w使得J1(w)最小等价于求解如下的特征值问题:
Sww=λw (8)
判别向量wm(m=1,2,…M)的个数取决于非零特征值的个数,可构建判别矩阵W=[w1,w2,…,wM],其中M为保留的判别向量个数。
每个数据类相互垂直的特征矩阵可以表示为:
Zi=XiW (9)
将数据类X1,X2,…,XC的数据从上到下进行堆叠,构成堆叠矩阵在判别矩阵方向上的投影可以表示为:
Z=XW (10)其中堆叠特征矩阵等于每个数据类的特征矩阵Zi(Ni×M)从上到下进行堆叠。容易得到特征矩阵Zi保持相互垂直。
③判别向量的第二次提取
将特征矩阵Zi代替每个数据类的原始数据Xi,利用式(2)和(3)分别计算得到类内离散度矩阵S′w和类间离散度矩阵Sb′。
寻找最优的Fisher判别向量θ使得类间离散度最大、同时类内离散度最小,即对如下的目标函数求取最优的Fisher判别向量:
式(11)等价于求解如下的标准特征值问题:
根据Zi计算得到的对应特征向量ti(J×1)为:
ti=Ziθ=XiWθ=Xiβ (13)
其中β=Wθ为通过两次提取得到的判别向量。
④数据紧缩
剔除每个数据类原始数据Xi中与ti相关的信息:
piT=(tiTti)-1tiTXi (14)
Ei=Xi-tipiT (15)
其中Ei为原始数据Xi中与ti无关的残差矩阵。
⑤迭代循环
用残差矩阵Ei代替步骤1中的原始数据Xi,依次执行步骤①~④,当提取到每个数据类中所有期望的判别向量时迭代停止。
通过迭代循环获得每个数据类的特征矩阵Ti==[t1,t2,…,tR],该特征矩阵能够沿着判别方向对不同数据类进行区分。其中能够计算得到的特征向量个数与堆叠矩阵X的秩相同,但并不是所有的特征向量都是必须的,实际应用中根据不同类数据的判别和区分能力确定保留的特征向量个数R。判别矩阵Θ(J×R)由每次迭代式(13)中的判别向量β(J×1)构成,负载矩阵Pi(J×R)每次迭代式(14)中的负载向量pi(J×1)构成。
通过特征矩阵Ti(Ni×R)和负载矩阵Pi(J×R)可重构每个数据类原始数据:
由于判别矩阵Θ(J×R)与每个数据类的残差矩阵相互垂直,即ER,iΘ=0。可以得到:
其中ER,i表示从原始数据Xi中剔除R个判别向量变化信息的残差矩阵。
将式(16)带入式(17)可得:
Ti=XiΘ(PiTΘ)-1(18)
因此,从每个数据类原始数据Xi计算特征矩阵Ti时,对应的判别矩阵Ri(J×R)为:
Ri=Θ(PiTΘ)-1 (19)
在步骤2)中,沿提取的故障方向Ri,计算故障工况数据对应的特征矩阵:
Tf,i=Xf,iRi (20)
其中Tf,i(Nn×R)表示故障工况Xf,i对应的特征矩阵。
沿提取的故障方向Ri,计算正常工况数据对应的特征矩阵:
Tn,i=XnRi (21)
正常工况第m个采样数据xn,m到正常工况训练数据中心的马氏距离为评价该采样数据与正常工况训练数据的相似性提供了一种有效度量,其计算公式如下:
其中tn,i,m表示正常工况第m个采样数据沿方向Ri计算得到的特征向量,表示沿方向Ri计算得到的特征矩阵Tn,i的均值向量,Σn,i表示对角矩阵,其对角元素由沿方向Ri计算得到的特征矩阵Tn,i的方差构成,统计量Dn,i,m2表示正常工况第m个采样数据沿方向Ri的变化程度。
基于正常工况数据统计量Dn,i,m2的计算值,采用经验参考分布法[13]确定置信度为99%所对应的Dn,i,m2统计量计算值,将其作为控制限
故障工况第m个采样数据xf,i,m到正常工况训练数据中心的马氏距离为:
其中tf,i,m表示故障工况第m个采样数据沿方向Ri计算得到的特征向量,统计量Df,i,m2表示故障工况第m个采样数据沿方向Ri的变化程度。
在步骤3)中,如果故障工况第m个采样数据的统计量Df,i,m2超过控制限进行故障变量提取,其目标是从故障工况数据中找到引起统计量变化的主要监测变量,用于故障分类。第m个采样数据中各变量对统计量D2的贡献度计算如下:
其中下标中的*用于区分正常工况和故障工况数据,*为n时表示正常工况数据,*为f时表示故障工况数据。ri,j表示判别矩阵Ri的第j个行向量,x*,m,j表示第m个采样数据的第j个变量,表示正常工况训练数据第j个变量的均值。表示沿故障方向Ri正常或故障工况第m个采样数据第j个变量对统计量D2的贡献度。
引入故障工况与正常工况数据中变量贡献度比例,以描述了变量贡献度在统计量D2中的重要程度。故障工况第m个采样数据的第j个变量贡献度比例计算如下:
其中表示沿故障方向Ri正常工况数据中第j个变量的贡献度向量,表示基于贡献度向量的各个元素数据,采用经验参考分布法确定置信度为99%时的控制限。
的值越大,表明故障工况数据中第j个变量对故障变化的贡献越大,该变量也越重要。对于所有故障工况采样数据,第j个变量贡献度比例为一个Nf维的向量沿时间方向,可以计算得到第j个变量贡献度比例的均值用其描述多个采样数据的故障影响。根据各个变量贡献度比例均值的大小,选取均值最大的变量作为最重要的故障变量。通过变量选取过程的迭代循环,依次选取后续的故障变量直至满足迭代停止条件,剩余的变量为对故障影响较小的变量,称其为一般变量。
在步骤4)中,根据每种故障工况的故障变量分离结果,故障工况数据可分为两部分和正常工况数据可分成对应的两部分和其中Jf,i和Jn,i分别表示第i种故障工况的故障变量个数和一般变量个数。
针对由故障变量构成的正常工况子数据和故障工况子数据采用改进Fisher判别分析方法进行分析,获得表征故障方向的判别矩阵揭示从正常工况到该种故障工况的主要异常变化,其中Rf表示保留的判别成分个数。对于故障工况子数据沿故障方向计算故障评价统计量:
其中表示特征矩阵的第m个行向量,表示特征矩阵的均值向量,表示特征矩阵的协方差矩阵,故障评价统计量描述了沿故障方向的故障变化。
基于故障评价统计量的计算值,采用经验参考分布法确定置信度为99%所对应的统计量计算值,将其作为控制限
针对由一般变量构成的正常工况子数据和故障工况子数据组成扩展数据对扩展数据进行PCA分解提取监测方向其中Rn表示监测方向个数(保留所有监测方向)。沿监测方向计算故障评价统计量:
其中表示得分矩阵的第m个行向量,表示得分矩阵的均值向量,表示得分矩阵的协方差矩阵,统计量描述了沿监测方向的一般变化。
假定过程数据服从多变量高斯分布且采样点足够多,采用χ2分布方法确定统计量的控制限:
其中表示根据扩展数据计算得到统计量的均值,ν表示统计量的方差。
通过上述分析和建模,每种故障工况数据可以划分为故障变量子数据和一般变量子数据,分别建立了每种故障工况的故障诊断模型并求取相应的控制限。在线故障诊断时,根据每种候选故障工况的故障信息尝试确定新的故障数据归属。
在步骤5)中,在第k个采样时刻获得一个新的观测数据xnew(J×1),采用文献[1]的方法检测是否有异常发生。存在异常时,对于新检测的故障数据,进行在线故障诊断。通过迭代评价新检测故障数据与每种故障工况的相似性,确定该故障数据属于哪种故障工况。
假设新检验的故障数据属于第i种候选故障工况,根据该种候选故障工况的故障变量和一般变量,将新检验的故障数据分成两部分,即分别计算新检验的故障子数据与该种故障工况的相似性。采用第i种候选故障工况的故障变量诊断模型计算新检测故障子数据的故障评价统计量:
其中表示根据第i种候选故障工况的故障变量选取得新检测故障子数据,表示第i种候选故障工况的故障方向,表示特征向量,统计量描述了沿故障方向的故障变化。
采用第i种候选故障工况的一般变量诊断模型计算新检测故障子数据的故障评价统计量:
其中表示根据第i种候选故障工况的一般变量选取得新检测故障子数据,表示第i种候选故障工况的监测方向,表示得分向量,统计量描述了沿监测方向的一般变化。
统计量和描述了新检测故障数据的不同变化,将上述两个统计量与第i种候选故障工况的相应控制限进行比较。如果两个统计量均位于控制限以内,表明新检测故障数据的故障变量和一般变化均与该种候选故障工况类似,新检测故障数据属于该种故障工况;如果统计量超过相应的控制限,表明新检测故障数据与该种候选故障工况不相符。通过在所有候选故障工况中统计量计算以及与控制限比较,可以确定新检测故障数据属于的故障工况。
本发明的有益效果是:
本发明针对卷烟制叶丝段过程变量间的强相关性,故障变量信息传播和扩散导致的误诊断问题,提出一种基于显著故障变量提取的卷烟制叶丝段故障诊断方法。设计一种具有正交判别成分的改进Fisher判别分析方法,通过两步特征提取避免了类内散布矩阵奇异性问题,通过数据紧缩保证了判别成分间的垂直性。利用改进Fisher判别分析方法提取故障方向,沿故障方向通过贡献度分析度量不同变量对故障影响,获得对故障有重要影响的故障变量和没有影响的一般变量,进而分别建立故障变量和一般变量的诊断模型进行故障诊断。基于制叶丝段Sirox增温增湿机和KLD薄板烘丝机实验验证表明,本发明有助于对故障过程和特性的深入理解,通过显著故障影响的分析与提取,克服了非关键故障诊断信息的影响,提高了卷烟制叶丝段故障诊断的可靠性。
附图说明
图1为基于改进Fisher判别分析的显著故障变量提取流程图;
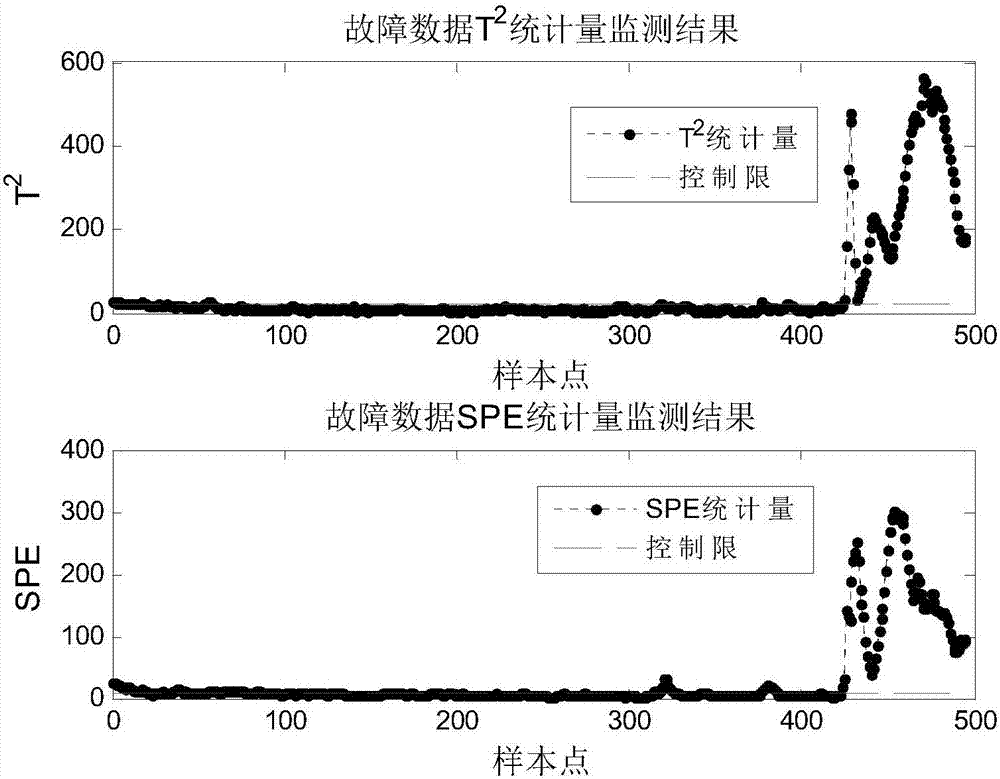
图2为制叶丝段F线利群软红长嘴牌号下某次断料故障的监测图;
图3为某次断料故障第429样本点时刻各个变量的贡献图;
图4为某次断料故障第450样本点时刻各个变量的贡献图;
图5为根据第1中候选故障工况模型计算得到的故障诊断结果图;
图6为根据第2中候选故障工况模型计算得到的故障诊断结果图。
具体实施方式
为了更好的理解本发明的技术方案,以下结合说明书附图对本发明的实施方式作进一步描述。
本实施是用于卷烟制叶丝段Sirox增温增湿机和KLD薄板烘丝机。Sirox增温增湿机的主要作用是在烘丝之前对叶丝进行膨胀和润湿,提高叶丝的温度和含水率,使烘后叶丝填充值得到提高。叶丝经过落料槽和叶轮闸门到达气流旋风分离器,气流旋风分离器的轴为空心,轴上有带螺纹的孔。饱和蒸汽由空心轴上的孔中流出落在叶丝上,使叶丝膨胀和湿润,气流旋风分离器再将叶丝输送至一个有盖板的出料振槽输送机。气流旋风分离器的轴由变频器进行驱动,进而控制轴的转速。在蒸汽喷雾管路的开闭通过调整阀来实现,根据运行需要调节蒸汽量。KLD薄板烘丝机的主要作用是利用饱和蒸汽将筒体加热来烘干叶丝,改善和提高叶丝的感官质量,以满足后工序的加工要求。叶丝通过振槽式输送机由入口罩板中的开孔进入烘丝机,烘丝机中的叶丝持续由一个旋转着的滚筒进行输送。滚筒壁上装有可由蒸汽加热的叶片,滚筒旋转时叶片带动叶丝一起转动并通过滚筒斜坡将叶丝往前输送。由于滚筒的旋转以及其倾角使叶丝始终与滚筒内叶片接触,在此过程中叶丝被搅拌并被均匀地加热。滚筒壁温度可以通过蒸汽压力或蒸汽流量进行调节,滚筒中的热风温度可以通过热交换器的蒸汽压力进行调节。
本发明的基于显著故障变量提取的卷烟制叶丝段故障诊断方法主要分为以下几步:
(1)正常工况、故障工况的数据获取
选取杭州卷烟厂F线制叶丝段的关键设备Sirox增温增湿机和KLD薄板烘丝机,包含的23个过程变量及其工程单位如表1所示,过程变量的采样频率为10s/次。
表1制叶丝段的过程变量
本实例中,收集2015年10月制叶丝段F线利群软红长嘴牌号下8个正常批次的运行数据进行预处理,并作为正常工况数据,即Xn(4935×23);选取2015年8~10月制叶丝段F线利群软红长嘴牌号下的两次断料故障,一次是由监测变量10(KLD总蒸汽压力)波动引起,一次是由监测变量6(Sirox蒸汽流量)波动引起,通过对原始数据的预处理分别构建故障工况建模数据Xf,1(19×23)、Xf,2(13×23)。
(2)故障方向的提取
针对正常工况数据和每种典型故障工况数据采用改进Fisher判别分析方法提取每种故障对应的故障方向Ri(J×R)。
本实例中,对正常工况数据Xn(4935×23)和故障工况数据Xf,1(19×23)进行改进Fisher判别分析,提取的故障方向为R1(23×5);对正常工况数据Xn(4935×23)和故障工况数据Xf,2(13×23)进行改进Fisher判别分析,提取的故障方向为R2(23×5)。
(3)统计量和控制限的确定
沿提取的故障方向,分别计算正常工况数据、故障工况数据对应的特征矩阵Tn,i、Tf,i。再根据马氏距离分别计算正常工况数据、故障工况数据对应的统计量Dn,i,m2、Df,i,m2,根据正常工况数据对应统计量的密度分布确定控制限
本实例中,根据故障方向R1(23×5)和R2(23×5)计算得到对应的特征矩阵Tn,1(4935×5)、Tf,1(19×5)和Tn,2(4935×5)、Tf,2(13×5)。针对故障工况1,根据马氏距离计算得到的统计量为Dn,12(4935×1)、Df,12(19×1),对应控制限为15.1201;针对故障工况2,根据马氏距离计算得到的统计量为Dn,22(4935×1)、Df,22(13×1),对应控制限为15.1201。
(4)故障变量的提取
如果故障工况数据对应的统计量Df,i,m2超过了控制限进行故障变量提取。沿故障方向Ri分别计算正常工况、故障工况的变量贡献度根据计算的变量贡献度比例的大小确定最重要的故障变量j,将故障变量j移到故障变量数据库。更新正常工况数据和故障工况数据重新计算故障方向进行故障变量提取,当故障工况数据对应的统计量在控制限以内时,表明所有故障变量均已提取。基于改进Fisher判别分析的显著故障变量提取过程如图1所示。
本实例中,针对故障工况1,沿故障方向R1(23×5)提取的故障变量为:14、12、15、10、20、22、16、11、23、9、2、17、4、7、8、21、13,即2区筒壁温度、1区筒壁温度、1区冷凝水温度、KLD总蒸汽压力、KLD烘后水分、冷却水分、2区冷凝水温度、1区蒸汽压力、冷却温度、KLD排潮风门开度、烘前水分、KLD热风温度、Sirox后叶丝温度、Sirox蒸汽薄膜阀开度、KLD排潮负压、KLD烘后水分、2区蒸汽压力。针对故障工况2,沿故障方向R2(23×5)提取的故障变量为:6、7、10、5、3,即Sirox蒸汽质量流量、Sirox蒸汽薄膜阀开度、KLD总蒸汽压力、Sirox蒸汽体积流量、Sirox阀前蒸汽压力。
(5)故障变量和一般变量诊断模型的建立
基于每种故障工况分离后的故障变量和一般变量,分别建立故障诊断模型揭示该类故障工况的故障影响,并计算得到故障评价统计量。
本实例中,针对故障工况1,由故障变量构成的正常工况子数据和故障工况子数据采用改进Fisher判别分析方法进行分析,获得表征故障方向的判别矩阵计算得到特征矩阵的均值向量特征矩阵的协方差矩阵等故障变量诊断模型参数,同时获得模型控制限为51.8047;由一般变量构成的正常工况子数据和故障工况子数据组成扩展数据对扩展数据进行PCA分解提取监测方向计算得到得分矩阵的均值向量得分矩阵的协方差矩阵等一般变量诊断模型参数,同时获得模型控制限为16.8536。针对故障工况2,由故障变量构成的正常工况子数据和故障工况子数据采用改进Fisher判别分析方法进行分析,获得表征故障方向的判别矩阵计算得到特征矩阵的均值向量特征矩阵的协方差矩阵等故障变量诊断模型参数,同时获得模型控制限为370.6117;由一般变量构成的正常工况子数据和故障工况子数据组成扩展数据对扩展数据进行PCA分解提取监测方向计算得到得分矩阵的均值向量得分矩阵的协方差矩阵等一般变量诊断模型参数,同时获得模型控制限为34.9992。
(6)基于典型故障模型库的在线故障诊断
在第k个采样时刻获得一个新的观测数据xnew(J×1),采用王伟等人[1]提出的基于相对变化分析的多模态卷烟制叶丝段故障监测方法检测是否有异常发生。存在异常时,对于新检测的故障数据,进行在线故障诊断。通过迭代评价新检测故障数据与每种故障工况的相似性,确定该故障数据属于哪种故障工况。
本实例中,收集2015年11月制叶丝段F线利群软红长嘴牌号下的某次断料故障数据,通过对原始数据的预处理获得监测数据X(495×23)。采用王伟等人[1]提出的基于相对变化分析的多模态卷烟制叶丝段故障监测方法计算监测数据的T2和SPE统计量,监测结果如图2所示。
从图2可知,T2和SPE监测统计量从425个样本点开始大幅超过控制限,一直持续到495个样本点。采用传统贡献图诊断方法[2],在首次故障报警的第429个样本点时刻各个变量对T2和SPE的贡献率如图3所示。
从图3可知,对T2监测统计量超限贡献较大的变量为第10、17个变量,对应为KLD总蒸汽压力、KLD热风温度,对SPE监测统计量超限贡献较大的变量为第16个变量,对应为2区冷凝水温度。对本次断料故障的事后专家诊断分析,故障原因为KLD总蒸汽压力的突降(降低22%),由于过程变量间的相关性,传播到KLD热风温度、2区冷凝水温度,造成上述两个参数实际值的波动,其中KLD热风温度降低2%、2区冷凝水温度升高13%。随着时间的推移,故障会继续传播到其它变量上,在第450个样本点时刻各个变量对T2和SPE的贡献率如图4所示。
从图4可知,KLD总蒸汽压力故障被进一步传播到11、12、13、14、15、20和22,分别对应1区蒸汽压力、1区筒壁温度、2区蒸汽压力、2区筒壁温度、1区冷凝水温度、KLD烘后水分、冷却水分。
将从425个样本点开始到495样本点结束的监测数据作为故障工况测试数据Xf,test(71×23),采用第1种候选故障工况的故障变量诊断模型、一般变量诊断模型分别计算新检测故障子数据的故障评价统计量和计算结果如图5所示;采用第2种候选故障工况的故障变量诊断模型、一般变量诊断模型分别计算新检测故障子数据的故障评价统计量和计算结果如图6所示。
从图5和图6可知,采用第1种候选故障工况模型计算故障工况测试数据Xf,test的故障评价统计量都位于对应控制限以内,表明故障工况测试数据Xf,test属于第1种候选工况,断料故障原因由监测变量10(KLD总蒸汽压力)波动引起;采用第2种候选故障工况一般变量诊断模型计算故障工况测试数据Xf,test的故障评价统计量超过了控制限,表明故障工况测试数据Xf,test与第2种候选故障工况不相符,断料故障原因不是由监测变量6(Sirox蒸汽流量)波动引起。
- 还没有人留言评论。精彩留言会获得点赞!