基于大数据的用户画像系统及画像方法与流程
本发明涉及一种基于大数据的用户画像系统及画像方法,属于大数据、数据挖掘、人工智能、商业智能领域。
背景技术:
大数据的核心是数据蕴含的价值,如何从海量数据中挖掘从商业价值是大数据、商业智能的关键所在。目前,大数据的应用很广泛。
大数据在医疗行业的应用,主要在下面几个方面,新药品效果的预测建模、提高临床试验设计的统计工具和算法、临床实验数据的分析、个性化治疗。这几个方面应用的前提,是有海量的真实患者数据。患者患病的机理与原因、患者患病的症状、患者对药物的反应、治疗方案对患者的效果、患者的后期康复治疗等患者相关数据,是做医疗大数据必不可少的生产资料。
大数据在金融行业的应用比较成功与广泛,综合起来,主要应用在如下几个方面,客户画像、精准营销、风险管控。客户画像又分为个人客户画像、企业(单位)客户画像,个人客户画像包括人口统计学特征、消费能力数据、兴趣数据、风险偏好等;企业客户画像包括企业的生产、流通、运营、财务、销售和客户数据、相关产业链上下游等数据。在客户画像的基础上银行可以有效的开展精准营销,包括,贷款额度、信用等级、理财产品、流失预警及留客策略等。风险管控,包括个人贷款风险评估、中小企业贷款风险评估和欺诈交易识别等手段。其中客户画像是核心与基础,精准营销与风险管控是在客户画像完成的基础上进行的。
电商为代表的行业已经在利用大数据掘金,主要是因为电商本身就拥有大量的消费者行为记录,能够依据这些数据快速了解消费者的需求。如何快速、准确地帮助顾客找到想要的商品,如何加大商品的有效曝光度如何根据顾客的需求,向其推荐偏好的商品,如何提高顾客的活跃度,降低顾客的弃单率,核心是消费者网上消费行为数据,它已经变得越来越重要,收集并分析这些消费者数据,将帮助商家预测顾客的下一步购物行为。利用顾客留在网站上的行为轨迹数据,分析顾客浏览商品类别,可以帮助商家预测顾客需要哪类商品,并推出相应的相关商品:根据顾客询价情况,商家还可以预测顾客购买力,从而对高级顾客推荐名牌商品,对普通顾客推荐物美价廉的商品,以满足不同的顾客对商品的不同心理价位;跟踪顾客经常购物的网店,对此类数据进行分析,可以预测用户的下一次购物行为将可能发生在哪个网店。
全球大的运营商中约有超过一半的运营商正在实施大数据业务。商业应用集中在两方面,市场与精准营销与数据商业化。市场与精准营销方向包括客户画像、精准营销、实时营销和个性化推荐。其中客户画像是基础,运营商可以基于客户终端信息、位置信息、通话行为、手机上网行为轨迹等丰富的数据,为每个客户打上人口统计学特征、消费行为、上网行为和兴趣爱好标签,并借助数据挖掘技术(如分类、聚类、rfm等)进行客户分群,完善客户的360度画像,帮助运营商深入了解客户行为偏好和需求特征。数据商业化方面对外(各行业的商家)提供营销洞察和精准广告投放。电信运营商分析用户线上(上网)行为大数据,给用户打标签、完成用户画像后。把这些数据提供给各行业的商家,各商家利用这些数据获得客户,比如提供数据给教育行业,教育行业利用这些数据获取学员、学生。提供给汽车商、4s店经销商,有购车需求的用户及联系方式,商家根据信息联系用户,完成售车。
大数据在医疗、金融、电商、电信应用的基础是获得足够多用户与获得用户足够全数据。医疗大数据,需要足够多患者全面的资料。金融大数据需要对用户做精确的画像,特别是资产、信用、消费能力等方面。电商大数据建立在海量消费者网上全面的消费行为数据。各行业大数据应用需要获得足够多用户与获得用户足够全数据(用户全面、及时更新的精确画像)。目前,2016年6月,我国网上用户(包括有线宽带用户与移动互联网用户)达到7.1亿,毫无疑问是海量用户与用户足够全数据(用户全面、及时更新的精确画像)的主要来源。所以,如何获得足够多用户与获得用户足够全数据将成为应用成功的关键。
技术实现要素:
针对现有技术存在的问题,本发明针对网上用户(包括有线宽带用户与移动互联网用户)提供了一种基于大数据的用户唯一上网识别号与网站账号关联的方法,将解决如何获得足够多用户与获得用户足够全数据(用户全面、及时更新的精确画像)的问题。
本发明的上述技术问题主要是通过下述技术方案实现的:
一种基于大数据的用户画像系统,系统主要包括“用户关联模块”、“用户画像模块”。
用户关联模块,由三个独立单元组成,用户数据处理单元,网站数据处理单元以及数据匹配单元。
用户处理单元用于处理用户数据,该数据由数据提供商提供(数据提供商为电信运营商或者第三方数据提供商),该数据主要由用户唯一上网识别号、用户点击的ts(时间戳)、用户点击的url(统一资源定位器)等组成。这些数据量很大,每天有数个tb的数据。从这些数据中目标网站数据,选择url来自一些大型的论坛网站,比如天涯、猫扑、豆瓣等,还可以选择专业网站比如“汽车之家”——汽车类、“我你在一起”——患病患者类等。再对选择出来的用户数据按照url与ts进行排序。再对排序的结果数据进行处理,如果相同url有多条记录,取ts最小的那条。这些被选取出来的记录组成一个新的用户数据集。
网站数据处理单元用来处理网站数据,主要包括网站的帖子、文章、评论等数据,通过爬虫软件爬取。爬虫爬取上面提到网站(天涯、猫扑、豆瓣、我你在一起、汽车之家等)的帖子、文章、评论的url、发布时间,用户的网站账号。发布时间的格式通常是年月日时分秒,需要转换成时间戳(ts)。处理后的数据结构是——帖子、文章、评论等的url,发布的时间戳,网站账号。
数据匹配单元用来完成用户唯一上网识别号与网站账号的算法匹配,电信运营商或者第三方提供的用户数据和网站数据(网站的帖子、文章、评论等数据),找出这两份数据中相同url的记录。再比较两条记录中的ts是否相等,如果相等,则认为该网站账号属于该用户唯一上网识别号。一个用户唯一上网识别号可以拥有多个网站账号。
用户画像模块,用于对用户进行精准画像,由三个独立单元组成,网站数据爬取单元,文本数据处理单元,用户标签单元。
网站数据爬取单元,在用户关联模块完成关联匹配的基础上进行。需要借助爬虫软件获取帖子、文章、评论的内容。爬虫爬取上面提到网站(天涯、猫扑、豆瓣、我你在一起、汽车之家等)的帖子、文章、评论的内容,发布的网站账号,发布时间。
文本数据处理单元处理过程如下,网站数据爬取单元获取的数据后,按照用户唯一上网识别号进行处理,把与同一个用户唯一上网识别号对应的网站账号所发布网站发布帖子、文章、评论的内容筛选出来,作为一个数据集。首先对数据集进行分词处理。再利用分词结果进行分类处理,识别出用户关注哪一领域(即用户的兴趣点),比如:医疗、金融、购物、汽车、房产等。在进行关键词提取,提取出用户感兴趣的具体方面,比如,医疗领域的肠胃、高血压等,汽车领域的宝马、奔驰等。
用户标签单元主要给用户打标签,最终完成精准画像。文本数据处理单元处理后,获得用户的关注点。利用这些关注点,给用户打上标签,比如:医疗、健康方面:身体健康,金融方面:高收入、有多套房产,汽车方面:捷豹一辆、现关注宝马,购物方面:消费品牌的列表等。精准画像后,可以在各行各业的应用了。
本发明的有益效果是:通过用户关联模块将用户数据和网站数据进行关联,再对关联后得到的数据集进行分析,最终得到用户的精准画像。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明中用户数据和网站数据的关联图;
图2为本发明中用户画像流程图。
具体实施方式
下面结合附图对本发明的优选实施例进行详细阐述,以使本发明的优点和特征能更易于被本领域技术人员理解,从而对本发明的保护范围做出更为清楚明确的界定。
参照图1-图2所示,基于大数据的用户画像系统,包括:
“用户关联模块”、“用户画像模块”。用户关联模块如图1所示,包括用户数据处理单元,网站数据处理单元以及数据匹配单元。
用户数据处理单元处理用户数据主要包括:
101:从电信运营商的大数据平台获取用户数据。大数据平台可以是开源的hadoop大数据平台、cdh大数据平台等。电信运营商的用户每天生产的海量数据,主要包括用户的网上行为等数据,由用户唯一上网识别号、用户点击的时间戳(ts,timestamp)、用户点击的url(uniformresourelocator,统一资源定位器)、用户ip等组成。
102:从电信运营商的海量用户数据中,提取出来自目标网站的数据,因为原数据集太大,每天有数tb的数据量,几十天可能要pb级数据,需要高配置的硬件资源来处理数据,必须要缩减计算的数据量。
103:如果用户没有点击目标网站的url,则不选取该条记录。
104:如果用户点击了目标网站的url,则选取该条记录,作为后面使用的数据集。
105:对数据集104按照url与ts进行排序的结果。
106:对排序的结果进行选择,选择的规则是相同url,取点击ts最小(ts越小,时间约早)的一条。目的是找出,最早点击网站的帖子、文章、评论url的用户唯一上网识别号。107:如果相同url里面,取点击ts不是最小,则不选择该条记录。
108:如果相同url里面,取点击ts最小,则选择该条记录。
网站数据处理单元对网站的帖子、文章、评论等数据处理,目的是获取目标网站的url信息与步骤108中得到的数据匹配,主要包括:
109:通过爬虫软件爬取目标网站的url信息。爬虫可以采用基于python的scrapy框架,该框架目前比较成熟与主流。主要获取的数据结构如
110:获取目标网站发布数据中的帖子、文章、评论的url、发布时间,网站账号。
111:将发布时间的格式年月日时分秒,转换成时间戳。处理后的数据结构是——帖子、文章、评论等的url,发布的时间戳,网站账号。
数据匹配单元主要用于完成电信运营商或者第三方提供的用户数据处理单元的结果数据与网站的帖子、文章、评论等数据处理单元结果数据的算法匹配,包括:
112:把电信运营商或者第三方提供的用户数据处理单元的结果数据,网站的帖子、文章、评论等数据处理单元的结果数据,找出这两份数据中相同url的记录。合并成新的数据集
113:生成用户唯一上网识别号、url、点击ts时间戳、发布ts时间戳、网站账号这样的数据结构。
114:判断点击ts时间戳与发布ts时间戳是否相等。
115:点击ts时间戳与发布ts时间戳不相等,则丢弃,匹配不成功。
116:点击ts时间戳与发布ts时间戳相等,匹配成功。
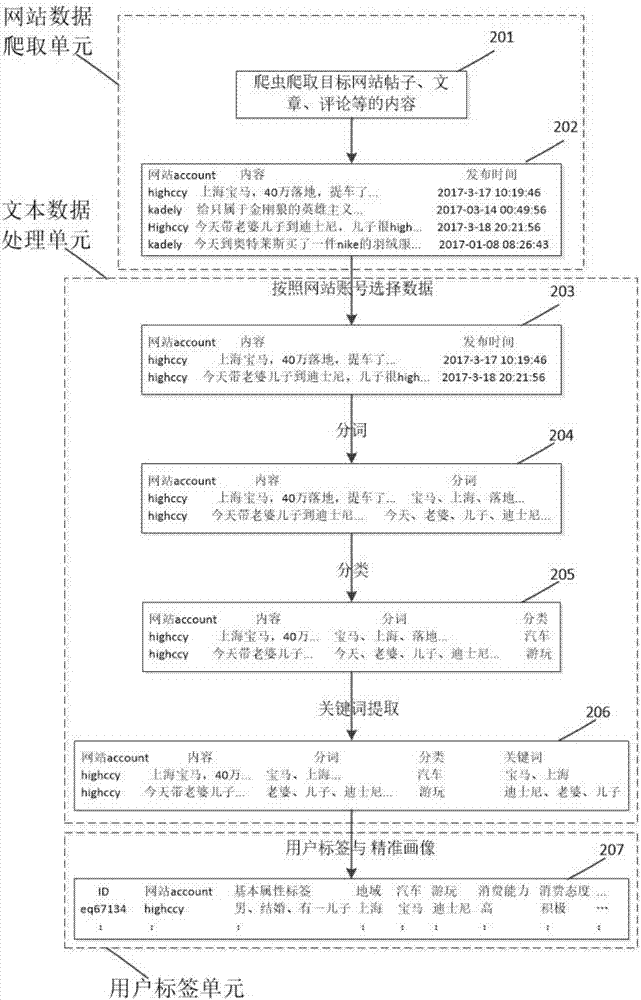
用户画像模块如图2所示。由三个独立单元组成,网站数据爬取单元,文本数据处理单元,用户标签单元。
网站数据爬取单元主要用来爬取网站的具体内容,包括:
201:爬虫爬取目标网站帖子、文章、评论等的内容,采用的技术与步骤109一样,爬取的商户与步骤109有区别,步骤109是爬取目标网站帖子、文章、评论等url信息。此处是爬取帖子、文章、评论里面的内容。
202:获取网站数据,数据结构为:目标网站帖子、文章、评论的网站账号、内容、发布时间。
文本数据处理单元是用户画像模块核心,完成网站数据爬取单元获取数据的算法处理。
203:对202得到数据,按照用户唯一上网识别号对应的网站账号,筛选出网站发布帖子、文章、评论的内容,作为一个数据集。
204:对203得到数据集进行分词处理,可采用开源的分词工具如:jieba分词、scikit-learning、ansj,这些分析工具都自带有分词词库。分词的结果如204所示。
205:对204的分词结果进行分类处理,识别出用户关注哪一领域。可以采用朴素贝叶斯、knn最近邻、svm支持向量机等算法进行分类。
206:进行关键词提取,提取出用户感兴趣的具体方面。可以采用权重策略的tf-idf算法,提取关键词。
用户标签单元的处理,包括:
207给用户打标签,最终完成精准画像。文本数据处理单元处理后,获得用户的关注点。利用这些关注点,给用户打上标签。文本数据处理单元得到的结果,作为用户标签单元的输入。可以通过分类算法:逻辑回归、决策所、朴素贝叶斯、knn最近邻、svm支持向量机、神经网络等给用户打上最终的标签,实现精准画像。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何不经过创造性劳动想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求书所限定的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!