一种基于搜索引擎的数据同步方法及系统与流程
本发明涉及通信
技术领域:
,特别是一种基于搜索引擎的数据同步方法及系统。
背景技术:
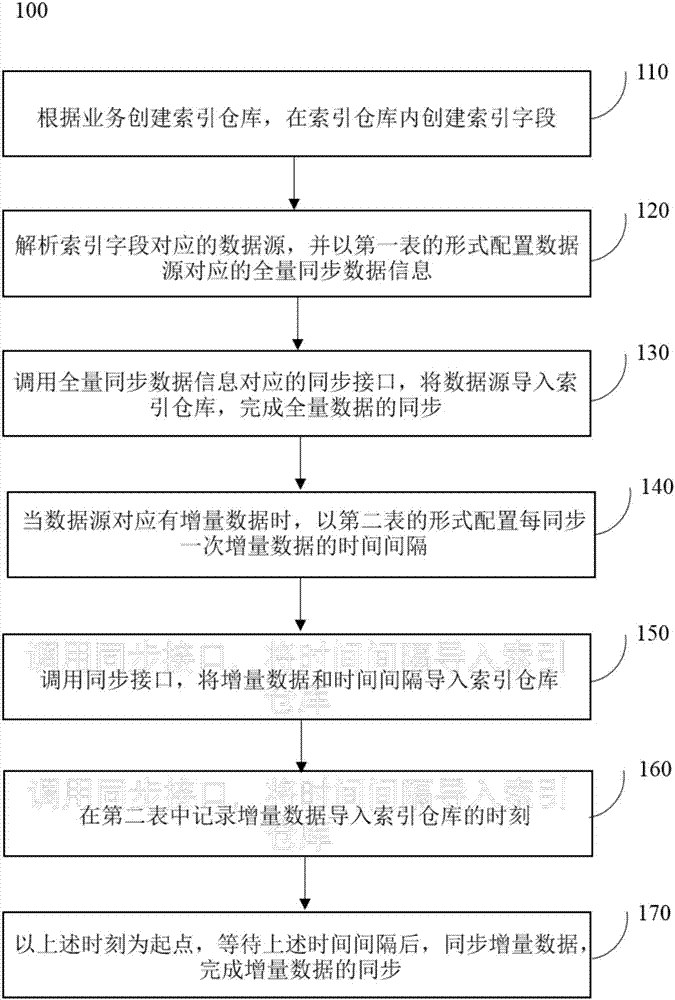
:在这个信息化的时代,搜索引擎在各行各业发挥着极其重要的作用,例如,网店的店主需要向搜索引擎提供关于其商品的简介,用于买家搜索和阅读。而传统的搜索引擎,其后台管理是通过代表数据信息的字符串来实现数据的传递,然而字符串不能直接一目了然的被开发者获知,在同步数据的过程中数据可能会被丢失或篡改,导致数据信息不准确,而管理者又很难在短时间内获知。另外,商家等用户提供的数据源的格式种类繁多,而后台管理中解析数据源的插件不能百分百满足各类格式的数据源的解析,导致数据源的解析失败,这极大的影响了搜索引擎对于数据信息传递的效率和准确性。技术实现要素:本发明提供一种基于搜索引擎的数据同步方法及系统,用于解决数据同步过程效率低下的问题,实现了实时自动同步数据,保证了数据的完整性和准确性。本发明解决上述技术问题的技术方案如下:一种基于搜索引擎的数据同步方法,包括:步骤1、根据业务创建索引仓库,在所述索引仓库内创建索引字段;步骤2、解析所述索引字段对应的数据源,并以第一表的形式配置所述数据源对应的全量同步数据信息;步骤3、调用所述全量同步数据信息对应的同步接口,将所述数据源导入所述索引仓库,完成全量数据的同步。本发明的有益效果是:本发明通过配置索引字段以及以表的形式配置全量同步数据信息,避免了传统的利用字符串等作为信息载体的问题,实现了数据信息的可视化;另外,在通过同步接口将全量数据导入索引仓库后,管理人员进入后台管理页面可查看全量数据是否已存在于索引仓库中。本方法极大地提高了将全量数据导入索引仓库的成功率和准确率,实现了实时自动同步数据,保证了数据的完整性和准确性。在上述技术方案的基础上,本发明还可以做如下改进。进一步,所述同步方法还包括:步骤4、当所述数据源对应有增量数据时,以第二表的形式配置每同步一次所述增量数据的时间间隔;步骤5、调用所述同步接口,将所述增量数据和所述时间间隔导入所述索引仓库;步骤6、在所述第二表中记录所述增量数据导入所述索引仓库的时间;步骤7、以所述时刻为起点,等待所述时间间隔后,同步所述增量数据,完成增量数据的同步。本发明进一步的有益效果是:在一项业务对应的全量数据经同步后,若该全量数据有对应的增量数据时,还可以对该增量数据进行同步,增大了数据同步的灵活性。进一步,所述步骤1包括:步骤1.1、根据业务创建索引仓库;步骤1.2、向所述索引仓库内导入配置文件;步骤1.3、在所述配置文件中配置查询信息,所述查询信息包括数据源表和数据源唯一编码;步骤1.4、根据所述数据源表,创建索引字段,所述索引字段包括索引字段名和所述字段名对应的字段类型。进一步,当所述第一表配置有多个所述数据源对应的所述全量同步数据信息时,所述步骤3包括:按照所述数据源唯一编码的顺序,依次调用所述全量同步数据信息对应的同步接口,将多个所述数据源导入所述索引仓库;或者,当所述第一表配置有多个所述数据源对应的所述全量同步数据信息,且接收到仅同步一个所述数据源的指令时,所述步骤3包括:根据该数据源对应的数据源唯一编码,调用所述全量同步数据信息对应的同步接口,并将该数据源导入所述索引仓库。进一步,需要重新同步一个数据源或多个数据源时,所述步骤3还包括:根据需要重新同步的数据源对应的所述数据源唯一编码,调用所述全量同步数据信息对应的同步接口,将需要重新同步的数据源导入所述索引仓库。本发明还提供了一种基于搜索引擎的数据同步系统,包括:索引字段创建模块,用于根据业务创建索引仓库,并在所述索引仓库内创建索引字段;同步数据信息配置模块,用于根据所述索引字段创建模块创建的所述索引字段,解析所述索引字段对应的数据源,并以第一表的形式配置所述数据源对应的全量同步数据信息;同步数据导入模块,用于根据所述同步数据信息配置模块配置的所述全量同步数据信息,调用所述全量同步数据信息对应的同步接口,并将所述数据源导入所述索引仓库。本发明的有益效果是:本系统通过索引字段创建模块配置索引字段以及通过同步数据信息配置模块以表的形式配置全量同步数据信息,避免了传统的利用字符串等作为信息载体的问题,实现了数据信息的可视化;另外,在通过同步数据导入模块将全量数据导入索引仓库后,管理人员进入后台管理页面可查看全量数据是否已存在于索引仓库中。本系统极大地提高了将全量数据导入索引仓库的成功率和准确率,实现了实时自动同步数据,保证了数据的完整性和准确性。进一步,所述同步数据信息配置模块还用于:当所述数据源对应有增量数据时,以第二表的形式配置每同步一次所述增量数据的时间间隔;所述同步数据导入模块还用于:调用所述同步接口,将所述增量数据和所述时间间隔导入所述索引仓库;所述同步数据信息配置模块还用于:在所述第二表中记录所述增量数据导入所述索引仓库的时间;所述同步数据导入模块还用于:以所述时刻为起点,等待所述时间间隔后,同步所述增量数据。进一步,所述索引字段创建模块具体用于:根据业务创建索引仓库,向所述索引仓库内导入配置文件,在所述配置文件中配置查询信息,所述查询信息包括数据源表和数据源唯一编码,根据所述数据源表,创建索引字段,所述索引字段包括索引字段名和所述字段名对应的字段类型。进一步,当所述第一表配置有多个所述数据源对应的所述全量同步数据信息时,所述同步数据导入模块用于:按照所述数据源唯一编码的顺序,依次调用所述全量同步数据信息对应的同步接口,将多个所述数据源导入所述索引仓库;或者,当所述第一表配置有多个所述数据源对应的所述全量同步数据信息,且接收到仅同步一个所述数据源的指令时,所述同步数据导入模块用于:根据该数据源对应的数据源唯一编码,调用所述全量同步数据信息对应的同步接口,并将该数据源导入所述索引仓库。进一步,需要重新同步一个数据源或多个数据源时,所述同步数据导入模块还用于:在根据需要重新同步的数据源对应的所述数据源唯一编码,调用所述全量同步数据信息对应的同步接口,将需要重新同步的数据源导入所述索引仓库。附图说明图1为本发明实施例一提供的一种基于搜索引擎的数据同步方法的流程示意图;图2为本发明实施例二提供的一种基于搜索引擎的数据同步方法的流程示意图;图3为图1和/或图2中的步骤110的流程示意图;图4为本发明实施例三提供的一种基于搜索引擎的数据同步系统的示意性结构图。具体实施方式以下结合附图对本发明的原理和特征进行描述,所举实例只用于解释本发明,并非用于限定本发明的范围。实施例一:一种基于搜索引擎的数据同步方法100,如图1所示,包括:步骤110、根据业务创建索引仓库,在索引仓库内创建索引字段;步骤120、解析索引字段对应的数据源,并以第一表的形式配置数据源对应的全量同步数据信息;步骤130、调用全量同步数据信息对应的同步接口,将数据源导入索引仓库,完成全量数据的同步。实施例二:可选的,作为本发明的另一个实施例,如图2所示,所述方法100包括:步骤110、根据业务创建索引仓库,在索引仓库内创建索引字段;步骤120、解析索引字段对应的数据源,并以第一表的形式配置数据源对应的全量同步数据信息;步骤130、调用全量同步数据信息对应的同步接口,将数据源导入索引仓库,完成全量数据的同步;步骤140、当数据源对应有增量数据时,以第二表的形式配置每同步一次增量数据的时间间隔;步骤150、调用同步接口,将增量数据和时间间隔导入索引仓库;步骤160、在第二表中记录增量数据导入索引仓库的时刻;步骤170、以上述时刻为起点,等待上述时间间隔后,同步增量数据,完成增量数据的同步。具体的,在上述实施例中,如图3所示,图1和/或图2中的步骤110包括:步骤111、根据业务创建索引仓库corel;步骤112、向索引仓库的core1/conf文件夹中导入配置文件;步骤113、在配置文件中配置查询信息,查询信息包括查询规则、数据源表和数据源唯一编码;步骤114、根据数据源表,创建索引字段,该索引字段包括索引字段名和字段名对应的字段类型。其中,步骤113中配置查询信息,具体的为:将uniquekey参数值设置为数据源的唯一编码(即id),例如:<uniquekey>docid</uniquekey>;将defaultsearchfield参数值设置为搜索时默认是搜索数据源表中数据源对应的字段,例如:<defaultsearchfield>doctitle</defaultsearchfield>;将solrqueryparser参数属性defaultoperator的值设置为默认的查询规则,例如:<solrqueryparserdefaultoperator="or"/>。其中,一项业务对应一个数据源,一个数据源对应一个唯一编码。步骤114中创建索引字段,具体的为:设置数据源表中需要同步到搜索引擎中的数据源对应的字段名、字段类型,例如:<fieldname="doctitle"type="text_ik"indexed="true"stored="true"omitnorms="true"/>,其中,name属性值为字段名称,type属性值为字段类型。另外,需要说明的是,在实施例一和实施例二中,用于解析索引字段对应的数据源的工具为apachetika开源插件,并且该开源插件中的解析数据算法经过了优化,使得该开源插件可对任何格式(例如:mysql、oracle、txt、word、ppt、excel和pdf)的数据源进行解析,且解析的成功率为100%,这极大地提高了将全量数据导入索引仓库的成功率和准确率,保证了数据的完整性和准确性。同时,需要说明的是,全量同步数据信息为配置信息,该配置信息通过三张表来记录数据源的连接信息、数据源表的个数以及数据源对应的索引字段,用于定位、连接和搜索数据源,另外,关于增量数据的同步,除了上述三张表,还包括第四张表,该第四张表记录同步增量数据的时间间隔以及将增量数据导入索引仓库的时间。另外,多项业务对应多个数据源,每项业务的配置信息都会记录在上述表中,例如,对于数据源的全量同步,上述三张表分别为表1、表2和表3,业务有a业务和b业务,那么a业务对应的配置信息分布在表1的第一行、表2的第一行和表3的第一行,b业务对应的配置信息分布在表1的第二行、表2的第二行和表3的第三行。当全量数据(即数据源)对应有增量数据并需要同步时,执行步骤140~170,其中,在调用同步接口将时间间隔和增量数据成功导入索引仓库后,记录导入时间,在等待上述时间间隔后,上述增量数据即可同步进入全量数据对应的索引仓库,完成增量数据的同步,例如,时间间隔为5分钟,增量数据导入索引仓库的时间为8点15分,等待5分钟后,在8点20分同步增量数据,完成增量数据的同步,无需再次调用全量同步数据信息对应的同步接口。另外,上述时间间隔可视具体情况而定。当调用全量同步数据信息对应的同步接口并将数据源导入索引仓库后,工作人员可登陆后台管理页面,进入索引仓库,查询数据源是否存在,如果存在,说明导入成功,如果不存在,可能是用户提供的数据源地址连接不上,或是硬件问题,可人工干预,重新从步骤110开始进行数据同步操作。具体的,在实施例二中,步骤120、步骤140和步骤160中,配置全量同步数据信息时需要建立第一表,配置对应的增量数据每同步一次的时间间隔时需要建立第二表。其中,第一表包括search_db_tb表、search_db表、search_db_tb_field表,第二表包括sys_task表。其中,search_db_tb表:iddb_idtb_namequerydelta_query_iddelta_querysearch_db_tb表包括的项目为:id、db_id、tb_name、query、delta_query_id和delta_query。其中,id为表主键;db_id为search_db表的主键;tb_name为数据表名称;pk_id为数据表主键;query为同步数据时的查询sql语句;delta_query_id为增量同步数据时执行的查询sql语句,查询结果为需要增量同步的数据id;delta_query为增量同步数据时执行的查询sql语句,根据delta_query_id字段值中的sql执行结果查询数据。search_db表:idservice_idurldriverusernamepasswordidsearch_db表包括的项目为:id、service_id、url、driver、username和passwordid。id为表主键;service_id为search_index表的主键;url,driver,username,password-id为数据路连接信息。search_db_tb_field表:search_db_tb_field表包括的项目为:id、tb_id、field_name、index_name、is_filter_html、is_pinyin、index_pinyin_name和doc_obtainid。id为表主键;tb_id为search_db_tb表的主键;field_name为数据表要同步到搜索引擎中的字段名;index_name为数据表字段在搜索引擎中对应的字段名称;is_filter_html表示字段值是否过滤html标签(1表示过滤,2表示不过滤)is_pinyin表示字段值是否转拼音(1表示转拼音,2表示不转拼音)index_pinyin_name表示成转拼音的字段值,同步到搜索引擎后的字段名称;doc_obtain表示是否根据路径取文件内容(1表示是,2表示否)。sys_task表:idtask_nameclass_pashexpressionlast_task_timelsys_task表包括的项目为:id、task_name、class_pash、expression和last_task_time。id为表主键;task_name为增量事务名称;class_pash为增量事务路径;expression为增量事务时间间隔;last_task_time为上一次增量事务执行的时间。需要说明的是,一个全量同步数据当有多个增量数据需要同步时,则对应地执行多次步骤140~步骤160。具体的,在上述实施例中,当第一表配置有多个数据源对应的全量同步数据信息时,步骤130包括:按照数据源唯一编码的顺序,依次调用全量同步数据信息对应的同步接口,将多个数据源导入索引仓库;或者,当第一表配置有多个数据源对应的全量同步数据信息,且接收到仅同步一个数据源的指令时,步骤130包括:根据该数据源对应的数据源唯一编码,调用含有该数据源唯一编码的同步接口,并将该数据源导入索引仓库。另外,需要重新同步一个数据源或多个数据源时,步骤130还包括:根据需要重新同步的数据源对应的数据源唯一编码,调用全量同步数据信息对应的同步接口,将需要重新同步的数据源导入索引仓库。本发明通过配置索引字段以及以表的形式配置全量同步数据信息,避免了传统的利用字符串等作为信息载体的问题,实现了数据信息的可视化;另外,在通过同步接口将全量数据导入索引仓库后,管理人员进入后台管理页面可查看全量数据是否已存在于索引仓库中,进一步地,由于本发明使用的用于解析数据源的工具为apachetika开源插件,且该开源插件中的解析数据算法经过了优化,使得该开源插件可对任何格式(例如:mysql、oracle、txt、word、ppt、excel和pdf)的数据源进行解析,且解析的成功率为100%。本方法极大地提高了将全量数据导入索引仓库的成功率和准确率,实现了实时自动同步数据,保证了数据的完整性和准确性。实施例三:本发明还提供了一种基于搜索引擎的数据同步系统200,如图4所示,包括:索引字段创建模块,用于根据业务创建索引仓库,并在索引仓库内创建索引字段;同步数据信息配置模块,用于根据索引字段创建模块创建的索引字段,解析索引字段对应的数据源,并以第一表的形式配置数据源对应的全量同步数据信息;同步数据导入模块,用于根据同步数据信息配置模块配置的全量同步数据信息,调用全量同步数据信息对应的同步接口,并将数据源导入索引仓库。另外,需要说明的是,在一项业务对应的全量数据经同步后,若该全量数据有对应的增量数据时,还可以对该增量数据进行同步。相应的,同步数据信息配置模块还用于:当数据源对应有增量数据时,以第二表的形式配置每同步一次增量数据的时间间隔;同步数据导入模块还用于:调用同步接口,将增量数据和时间间隔导入索引仓库;同步数据信息配置模块还用于:在第二表中记录将增量数据导入索引仓库的时刻;同步数据导入模块还用于:以时刻为起点,等待时间间隔后,同步增量数据,完成增量数据的同步。其中,索引字段创建模块具体用于:根据业务创建索引仓库,向索引仓库内导入配置文件,在配置文件中配置查询信息,并根据查询信息,创建索引字段,其中,查询信息包括查询规则、数据源表和数据源唯一编码,索引字段包括索引字段名和字段名对应的字段类型。当第一表配置有多个数据源对应的全量同步数据信息时,同步数据导入模块用于:按照数据源唯一编码的顺序,依次调用全量同步数据信息对应的同步接口,将多个数据源导入索引仓库;或者,当第一表配置有多个数据源对应的全量同步数据信息,且接收到仅同步一个数据源的指令时,同步数据导入模块用于:根据该数据源对应的数据源唯一编码,调用全量同步数据信息对应的同步接口,并将该数据源导入索引仓库。需要重新同步一个数据源或多个数据源时,同步数据导入模块还用于:根据需要重新同步的数据源对应的数据源唯一编码,调用全量同步数据信息对应的同步接口,将需要重新同步的数据源导入索引仓库。需要说明的是,该系统由java语言开发,通过索引字段创建模块配置索引字段以及通过同步数据信息配置模块以表的形式配置全量同步数据信息,避免了传统的利用字符串等作为信息载体的问题,实现了数据信息的可视化;另外,在通过同步数据导入模块将全量数据导入索引仓库后,管理人员进入后台管理页面可查看全量数据是否已存在于索引仓库中,进一步地,由于本发明在同步数据信息配置模块中使用的用于解析数据源的工具为apachetika开源插件,且该开源插件中的解析数据算法经过了优化,使得该开源插件可对任何格式(例如:mysql、oracle、txt、word、ppt、excel和pdf)的数据源进行解析,且解析的成功率为100%。本系统极大地提高了将全量数据导入索引仓库的成功率和准确率,实现了实时自动同步数据,保证了数据的完整性和准确性。另外,由于本发明在同步数据信息配置模块中使用的用于解析数据源的工具为apachetika开源插件,且该开源插件中的解析数据算法经过了优化,使得该开源插件可对任何格式的数据源进行解析,且经测试,解析的成功率为100%,如果出现解析不成功的,那可能是对方的数据库连接不上,或是硬件问题。以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1