方案文本生成方法及系统与流程
本发明涉及文本处理领域,特别是涉及一种方案文本生成方法及系统。
版权申明
本专利文件披露的内容包含受版权保护的材料。该版权为版权所有人所有。版权所有人不反对任何人复制专利与商标局的官方记录和档案中所存在的该专利文件或者该专利披露。
背景技术:
协同倍增创新方法(collaborativeinnovation&multiplication,cim),是一种基于协同创新方法和资源复用的五大发明原理(组合法、分割法、多用法、抽取法、复制法)的专利创新方法,其核心思想是基于已有的相关问题的专利信息,综合组合法、分割法、多用法、抽取法、复制法,提出解决新问题的专利方案。通过这种方式,拓展创新思维,提高发明效率。
海云协同架构是一种结合海计算和云计算的新型架构。一方面,它充分利用了海端的分布式智能和云端强大的计算能力,另一方面,它通过海端智慧减少了云端的存储和计算压力,并且使云端更好的服务于海端。
爬虫技术是一种“自动化浏览网络”的程序,它按照一定的规则,自动在万维网上抓取用户需要的信息。随着互联网的发展,网络成为大量信息的载体。爬虫技术也成为数据采集的重要组成部分,是大数据分析中最为基础的一步。
文本分析技术是指对文本的表示及其特征项的选取,是文本挖掘、信息检索中的基本问题。它将无结构的原始文本转化为结构化的计算机可以识别和处理的信息,从而建立数学模型来描述和代替文本,最终实现从大量文本中挖掘有效信息的目的。文本语义分析是识别文本主题、类别与意义等语义信息的过程,在自然语言处理、信息过滤、信息分类、信息检索、语义挖掘等领域都普遍应用。
深度学习具有分布式特征表达、自动特征提取、端到端机器学习和良好的泛化能力等优势,在语音识别、图像识别和自然语言处理等很多领域得到令人瞩目的成功应用。而文本通常由多个句子构成序列组成段落,由多个词构成序列组成句子,可以利用深度学习中基于序列的模型进行预测生成。andrejkarpathy等专家学者的研究验证了基于深度学习实现文本生成的可行性。
现有的创新方法仅仅提供了理论依据,专利的创新需要发明人拥有足够多的相关知识,并未实现最大程度地利用现有专利资源。
技术实现要素:
为了解决上述的以及其他潜在的技术问题,本发明的实施例提供了一种方案文本生成方法,所述方案文本生成方法包括:采集方案数据,形成方案素材并对所述方案素材进行处理,获取方案特征词的特征矩阵;对方案数据进行文本语义分析获取方案数据的潜在主题,将所述方案数据的文本表征为词向量并根据所述词向量生成与词向量对应的近义词表;根据输入的语句或词语查询所述近义词表,形成查询词组并根据所述潜在主题和所述查询词组获取与所述查询词组相关的多个技术方案;从相关度高的技术方案中选取关键词,利用所述特征矩阵计算与所述查询词组最相关的关键词,生成关键词组;对所述关键词组进行筛选和组合,生成技术方案描述文本,并将所述技术方案描述文本输入到预设的方案文本生成模型,通过所述方案文本生成模型生成并输出技术方案参考文本。
于本发明的一实施例中,利用爬虫技术采集方案数据。
于本发明的一实施例中,对所述方案素材进行处理具体包括:对所述方案素材进行词语划分,去除停用词,进行词性标注,保留相关词性形成清洗数据。
于本发明的一实施例中,所述获取方案特征词的特征矩阵具体包括:从所述清洗数据中提取多个方案特征词,并对所述方案特征词对应的特征向量进行降维;根据降维后的特征向量生成对应的特征矩阵。
于本发明的一实施例中,利用预设的文本分析模型对方案数据进行文本语义分析,利用深度学习中基于序列的模型将方案数据的文本表征为词向量。
于本发明的一实施例中,所述文本分析模型具体为:隐含狄利克雷分布主题生成模型,所述深度学习中基于序列的模型具体为递归神经网络模型。
于本发明的一实施例中,所述预设的方案文本生成模型具体为:根据固定文本输入格式训练生成的lstm模型。
本发明还提供一种方案文本生成系统,所述方案文本生成系统包括:数据采集处理模块,语义分析模块,查询获取模块以及文本生成模块;所述数据采集处理模块用于采集方案数据,形成方案素材并对所述方案素材进行处理,获取方案特征词的特征矩阵;所述语义分析模块包括:主题单元,用于对方案数据进行文本语义分析获取方案数据的潜在主题;近义词表单元,用于将所述方案数据的文本表征为词向量并根据所述词向量生成与词向量对应的近义词表;所述查询获取模块包括:查询单元,根据输入的语句或词语查询所述近义词表,形成查询词组;获取单元,用于根据所述潜在主题和所述查询词组获取与所述查询词组相关的多个技术方案;关键词组单元,用于从相关度高的技术方案中选取关键词,利用所述特征矩阵计算与所述查询词组最相关的关键词生成关键词组;所述文本生成模块包括:描述文本单元,用于对所述关键词组进行筛选和组合,生成技术方案描述文本;文本生成单元,用于将所述技术方案描述文本输入到预设的方案文本生成模型,通过所述方案文本生成模型生成并输出技术方案参考文本。
于本发明的一实施例中,所述数据采集处理模块利用爬虫技术采集方案数据。
于本发明的一实施例中,所述数据采集处理模块对所述方案素材进行处理具体包括:对所述方案素材进行词语划分,去除停用词,进行词性标注,保留相关词性形成清洗数据。
于本发明的一实施例中,所述数据采集处理模块获取方案特征词的特征矩阵具体包括:从所述清洗数据中提取多个方案特征词,并对所述方案特征词对应的特征向量进行降维,根据降维后的特征向量生成对应的特征矩阵。
于本发明的一实施例中,所述主题单元利用预设的文本分析模型对方案数据进行文本语义分析;所述近义词表单元利用深度学习中基于序列的模型将方案数据的文本表征为词向量。
于本发明的一实施例中,所述文本分析模型具体为:隐含狄利克雷分布主题生成模型,所述深度学习中基于序列的模型具体为递归神经网络模型。
于本发明的一实施例中,所述预设的方案文本生成模型具体为:根据固定文本输入格式训练生成的lstm模型。
如上所述,本发明的方案文本生成方法及系统具有以下有益效果:
本发明实施例可以针对输入的技术问题查询最相关的技术方案,生成有助于创新构思的关键词组,自动化生成技术方案参考文本,达到充分利用现有专利的知识和技术,启发人们创造性思维,进一步提升人们创新效率的目的,解决“创新难”、“创新少”的问题,最终实现技术方案创新和创新方案数量的倍增。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1显示为本发明的方案文本生成方法的流程示意图。
图2显示为本发明的方案文本生成方法的使用实例示意图。
图3显示为本发明的方案文本生成系统的原理框图。
元件标号说明
100方案文本生成系统
110数据采集处理模块
120语义分析模块
121主题单元
122近义词表单元
130查询获取模块
131查询单元
132获取单元
133关键词组单元
140文本生成模块
141描述文本单元
142文本生成单元
s101~s105步骤
具体实施方式
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需说明的是,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
请参阅图1至图3。须知,本说明书所附图式所绘示的结构、比例、大小等,均仅用以配合说明书所揭示的内容,以供熟悉此技术的人士了解与阅读,并非用以限定本发明可实施的限定条件,故不具技术上的实质意义,任何结构的修饰、比例关系的改变或大小的调整,在不影响本发明所能产生的功效及所能达成的目的下,均应仍落在本发明所揭示的技术内容得能涵盖的范围内。同时,本说明书中所引用的如“上”、“下”、“左”、“右”、“中间”及“一”等的用语,亦仅为便于叙述的明了,而非用以限定本发明可实施的范围,其相对关系的改变或调整,在无实质变更技术内容下,当亦视为本发明可实施的范畴。
本实施例的目的在于提供一种方案文本生成方法及系统,用于解决现有技术中难以最大程度地利用现有文档资源生成方案文本的问题。以下将详细阐述本发明的方案文本生成方法及系统的原理及实施方式,使本领域技术人员不需要创造性劳动即可理解本发明的方案文本生成方法及系统。
本实施例基于海云协同服务平台和cim技术原理,采用爬虫技术、文本分析技术和深度学习算法对专利数据进行采集处理和信息挖掘,针对问题查询最相关专利,生成有助于专利创新构思的关键词组,研究挖掘专利发明与其所解决问题之间、同类专利发明之间、不同类专利发明之间的潜在关联。当遇到新问题时,通过特征提取和关联性研究挖掘出类似问题与相关产品。基于资源复用发明原理与专利文本的结构特点,研究设计特征挖掘算法提取关联数据特征,研究设计文本预测与生成算法,自动化生成可参考的专利文本,最终实现专利创新和专利倍增。
具体地,如图1所示,本实施例提供了一种方案文本生成方法,所述方案文本生成方法包括以下步骤:
步骤s101,采集方案数据,形成方案素材并对所述方案素材进行处理,获取方案特征词的特征矩阵。
步骤s102,对方案数据进行文本语义分析获取方案数据的潜在主题,将所述方案数据的文本表征为词向量并根据所述词向量生成与词向量对应的近义词表。
步骤s103,根据输入的词语查询所述近义词表,形成查询词组并根据所述潜在主题和所述查询词组获取与所述查询词组相关的多个技术方案。
步骤s104,从相关度高的技术方案中选取关键词,利用所述特征矩阵计算与所述查询词组最相关的关键词,生成关键词组。
步骤s105,对所述关键词组进行筛选和组合,生成技术方案描述文本,并将所述技术方案描述文本输入到预设的方案文本生成模型,通过所述方案文本生成模型生成并输出技术方案参考文本。
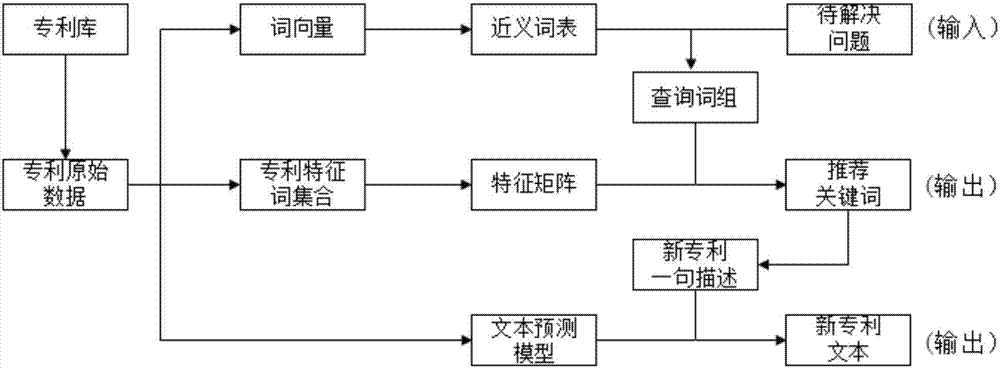
以下对本实施例的步骤s101~步骤s105进行详细说明,如图2所示,并以技术方案为专利方案为例进行具体说明。
步骤s101,采集方案数据,形成方案素材并对所述方案素材进行处理,获取方案特征词的特征矩阵。
例如,于本实施例中,如图2所示,从专利数据库采集专利方案数据,形成专利方案素材并对所述专利方案素材进行处理,获取专利方案特征词的特征矩阵。
本实施例中,利用爬虫技术采集方案数据,具体地,采取selenium加webdriver的动态爬虫方案,首先获取各个专利类别的目录,再通过翻页遍历每个目录下的前几百项专利,形成专利创新的素材;其中,所述专利方案数据包括但不限于专利的标题,摘要,专利分类号,专利申请号等基本信息。
于本实施例中,对所述方案素材进行处理具体包括:对所述方案素材进行词语划分,去除停用词,进行词性标注,保留相关词性形成清洗数据。具体地,可以利用分词算法对专利数据进行词语划分,去除停用词后进行词性标注,保留相关词性处理,实现对原始专利数据的清洗。例如:利用中文分词工具jieba分词,结合工具原始字典与专利素材自定义分词字典;利用jieba分词进行词性标注;过滤掉对后期结果无显著意义的介词、副词、助词、连词、标点符号等,筛选出有较高信息价值的名词、动词等作为特征词。于本实施例中,所述获取方案特征词的特征矩阵具体包括:从所述清洗数据中提取多个方案特征词,并对所述方案特征词对应的特征向量进行降维;根据降维后的特征向量生成对应的特征矩阵。具体地,选出清洗后专利信息最明显的特征,在保留文本核心信息的同时尽量减少特征词数目,对特征向量进行降维,实现方案特征词提取。
然后根据降维后的特征向量生成对应的特征矩阵。具体地,利用词项加权方法词频-逆向文件频率(termfrequency–inversedocumentfrequency,tf-idf)将所述方案特征词转化为向量空间模型即生成对应的特征矩阵,,计算出降维后特征向量对应的特征矩阵。
具体地,将清洗选择的特征词作为文档特征,建立一个文档--特征词矩阵(n×n维,n个文档,m个特征词),矩阵的每一行代表一个文档的特征向量,矩阵的一列代表一个关键词在文档中出现的频率。运用主成分分析(principalcomponentsanalysis,pca)对词语特征--文档矩阵进行降维,将n维原始文档--特征词空间转换为m维正交特征空间。再运用tf-idf计算降维后的正交矩阵(n×m维)中各词的权重,计算出降维后的特征矩阵,同时实现了特征提取。
利用词项加权方法词频-逆向文件频率(termfrequency–inversedocumentfrequency,tf-idf)将所述方案特征词转化为向量空间模型即生成对应的特征矩阵,实现基于统计的特征提取与降维。
步骤s102,对方案数据进行文本语义分析获取方案数据的潜在主题,将所述方案数据的文本表征为词向量并根据所述词向量生成与词向量对应的近义词表。
于本实施例中,利用预设的文本分析模型对方案数据进行文本语义分析,例如运用隐含狄利克雷分布(latentdirichletallocation,lda)主题生成模型等相关模型进行专利信息的文本语义分析,挖掘出原始专利语料的潜在主题。
于本实施例中,利用深度学习中基于序列的模型将方案数据的文本表征为词向量。例如,利用深度学习思想,将专利文本词语表征为向量,根据词向量生成近义词表。
于本实施例中,所述文本分析模型具体可以是隐含狄利克雷分布(latentdirichletallocation,lda)主题生成模型,lda为非监督机器学习的一种方法,可识别大规模语料或文档集中的潜在主题信息。所述深度学习中基于序列的模型具体是递归神经网络(recurrentneuralnetworks,rnns)模型。
根据词向量生成近义词表具体为:
计算词向量与词向量之间的余弦值,即利用向量空间相似度描述专利文本相似度。若两词项含义愈接近,则相似度数值越大,遍历得出各特征词与指定特征词的相似度。
如表1所示,词语间相似度的大小表征词项之间的关联强弱,设定特征词的相似度阈值,筛选出高于阈值的词生成近义词表,存储在数据库。
表1近义词及词语间的相似度示例
步骤s103,根据输入的语句或词语查询所述近义词表,形成查询词组并根据所述潜在主题和所述查询词组获取与所述查询词组相关的多个技术方案。
其中,输入的语句或词语为对待解决的技术问题的描述,若输入语句,则对语句进行关键词提取,形成输入词语。通过查询所有输入词语的近义词,生成最终的查询词组。
例如,首先将输入词语加入查询词语。然后针对输入词语的词语,检索所述近义词表,若检索到该词语,则选取与该词语相似度最大的前几个近义词,并按相关度由大到小的顺序加入查询词组;若没有检索到该词语,不做处理。通过查询所有输入词语的近义词,生成最终的查询词组。
具体地,依据查询词组的重要程度和主题相关度赋权重,计算每个技术方案(专利)对于查询词组的相关度,并排序。
例如,首先对查询词组的每个词语赋权重,词语在查询词组中位置越靠前,对应的权重越大。基于所述查询词组中的每个词语,查找每个技术方案(专利)对应的特征值,并乘以对应的词语权重,最后将所有词语得出的值进行加和即计算每个技术方案(专利)对应查询词组的加权和。将加权和进行降序排序,选取前几个技术方案,作为最相关的技术方案。
步骤s104,从相关度高的技术方案中选取关键词,利用所述特征矩阵计算与所述查询词组最相关的关键词,生成关键词组。
例如,选取最相关专利的关键词,根据特征矩阵,计算与查询词组最相关的关键词,生成有助于专利创新构思的关键词组。
具体地,对于相关度高的技术方案,选取最相关的关键词,并查询特征矩阵中关键词对应的特征值。若不同技术方案中关键词相同,则对其特征值进行加和。对所有关键词的特征值进行降序排序,选取前十几个特征值对应的关键词按顺序加入关键词组。
步骤s105,对所述关键词组进行筛选和组合,生成技术方案描述文本,并将所述技术方案描述文本输入到预设的方案文本生成模型,通过所述方案文本生成模型生成并输出技术方案参考文本。
具体地,选取预设的方案文本生成模型和预设的文本预测与生成算法,以结构一致的专利文本为输入训练专利文本生成模型。
对所述关键词组进行筛选组合,生成技术方案描述文本,其中,所述技术方案描述文本例如为对于需要提出的新专利进行一句描述,并将此作为方案文本生成模型的输入,通过所述方案文本生成模型,预测这句话后面最可能出现的字,再将原始输入加上预测的这个字作为新输入,预测下一个字,直至输出为停止标志,最终生成并输出可参考的专利文本。
最终可通过人工干预的方式对自动化生成的可参考的专利文本进行筛选,得出最佳理想解,从而产生出新的专利。
如图3所示,本实施例还提供一种方案文本生成系统100,所述方案文本生成系统100包括:数据采集处理模块110,语义分析模块120,查询获取模块130以及文本生成模块140。
以下对本实施例中的方案文本生成系统100进行详细说明。
于本实施例中,所述数据采集处理模块110用于采集方案数据,形成方案素材并对所述方案素材进行处理,获取方案特征词的特征矩阵。
例如,于本实施例中,从专利数据库采集专利方案数据,形成专利方案素材并对所述专利方案素材进行处理,获取专利方案特征词的特征矩阵。
具体地,本实施例中,所述数据采集处理模块110利用爬虫技术采集方案数据,采取selenium加webdriver的动态爬虫方案,首先获取各个专利类别的目录,再通过翻页遍历每个目录下的前几百项专利,形成专利创新的素材;其中,所述专利方案数据包括但不限于专利的标题,摘要,专利分类号,专利申请号等基本信息。
于本实施例中,所述数据采集处理模块110对所述方案素材进行处理具体包括:对所述方案素材进行词语划分,去除停用词,进行词性标注,保留相关词性形成清洗数据。
具体地,可以利用分词算法对专利数据进行词语划分,去除停用词后进行词性标注,保留相关词性处理,实现对原始专利数据的清洗。例如:利用中文分词工具jieba分词,结合工具原始字典与专利素材自定义分词字典;利用jieba分词进行词性标注;过滤掉对后期结果无显著意义的介词、副词、助词、连词、标点符号等,筛选出有较高信息价值的名词、动词等作为特征词。
于本实施例中,所述数据采集处理模块110获取方案特征词的特征矩阵具体包括:从所述清洗数据中提取多个方案特征词,并对所述方案特征词对应的特征向量进行降维,根据降维后的特征向量生成对应的特征矩阵。
具体地,选出清洗后专利信息最明显的特征,在保留文本核心信息的同时尽量减少特征词数目,对特征向量进行降维,实现方案特征词提取。
然后根据降维后的特征向量生成对应的特征矩阵。具体地,利用词项加权方法词频-逆向文件频率(termfrequency–inversedocumentfrequency,tf-idf)将所述方案特征词转化为向量空间模型即生成对应的特征矩阵,计算出降维后特征向量对应的特征矩阵。
具体地,将清洗选择的特征词作为文档特征,建立一个文档--特征词矩阵(n×n维,n个文档,m个特征词),矩阵的每一行代表一个文档的特征向量,矩阵的一列代表一个关键词在文档中出现的频率。运用主成分分析(principalcomponentsanalysis,pca)对词语特征--文档矩阵进行降维,将n维原始文档--特征词空间转换为m维正交特征空间。再运用tf-idf计算降维后的正交矩阵(n×m维)中各词的权重,计算出降维后的特征矩阵,同时实现了特征提取。
利用词项加权方法词频-逆向文件频率(termfrequency–inversedocumentfrequency,tf-idf)将所述方案特征词转化为向量空间模型即生成对应的特征矩阵,实现基于统计的特征提取与降维。于本实施例中,所述语义分析模块120包括:主题单元121和近义词表单元122。
所述主题单元121用于对方案数据进行文本语义分析获取方案数据的潜在主题。
于本实施例中,所述主题单元121利用预设的文本分析模型对方案数据进行文本语义分析;例如运用隐含狄利克雷分布(latentdirichletallocation,lda)主题模型等相关模型进行专利信息的文本语义分析,挖掘出原始专利语料的潜在主题。
所述近义词表单元122用于将所述方案数据的文本表征为词向量并根据所述词向量生成与词向量对应的近义词表。于本实施例中,所述近义词表单元122利用深度学习中基于序列的模型将方案数据的文本表征为词向量。例如,利用深度学习思想,将专利文本词语表征为向量,根据词向量生成近义词表。
于本实施例中,所述文本分析模型具体可以是隐含狄利克雷分布(latentdirichletallocation,lda)主题生成模型,lda为非监督机器学习的一种方法,可识别大规模语料或文档集中的潜在主题信息。所述深度学习中基于序列的模型具体是递归神经网络(recurrentneuralnetworks,rnns)模型。
根据词向量生成近义词表具体为:
计算词向量与词向量之间的余弦值,即利用向量空间相似度描述专利文本相似度。若两词项含义愈接近,则相似度数值越大,遍历得出各特征词与指定特征词的相似度。词语间相似度的大小表征词项之间的关联强弱,设定特征词的相似度阈值,筛选出高于阈值的词生成近义词表,存储在数据库。
如上表1所示,词语间相似度的大小表征词项之间的关联强弱,设定特征词的相似度阈值,筛选出高于阈值的词生成近义词表,存储在数据库。
于本实施例中,所述查询获取模块130包括:查询单元131,获取单元132以及关键词组单元133。
所述查询单元131用于根据输入的语句或词语查询所述近义词表,形成查询词组。
其中,输入的语句或词语为待解决的技术问题,若输入语句,则对语句进行关键词提取,形成输入词语。通过查询所有输入词语的近义词,生成最终的查询词组。
例如,首先将输入词语加入查询词语。然后针对输入词语的词语,检索所述近义词表,若检索到该词语,则选取与该词语相似度最大的前几个近义词,并按相关度由大到小的顺序加入查询词组;若没有检索到该词语,不做处理。通过查询所有输入词语的近义词,生成最终的查询词组。
所述获取单元132用于根据所述潜在主题和所述查询词组获取与所述查询词组相关的多个技术方案。
具体地,依据查询词组的重要程度和主题相关度赋权重,计算每个技术方案(专利)对于查询词组的相关度,并排序。可以举例说明。
例如,首先对查询词组的每个词语赋权重,词语在查询词组中位置越靠前,对应的权重越大。基于所述查询词组中的每个词语,查找每个技术方案(专利)对应的特征值,并乘以对应的词语权重,最后将所有词语得出的值进行加和即计算每个技术方案(专利)对应查询词组的加权和。将加权和进行降序排序,选取前几个技术方案,作为最相关的技术方案。
所述关键词组单元133用于从相关度高的技术方案中选取关键词,利用所述特征矩阵计算与所述查询词组最相关的关键词生成关键词组。
例如,选取最相关专利的关键词,根据特征矩阵,计算与查询词组最相关的关键词,生成有助于专利创新构思的关键词组。
具体地,对于相关度高的技术方案,选取最相关的关键词,并查询特征矩阵中关键词对应的特征值。若不同技术方案中关键词相同,则对其特征值进行加和。对所有关键词的特征值进行降序排序,选取前十几个特征值对应的关键词按顺序加入关键词组。
于本实施例中,所述文本生成模块140包括:描述文本单元141和文本生成单元142。
所述描述文本单元141用于对所述关键词组进行筛选和组合,生成技术方案描述文本。
所述文本生成单元142用于将所述技术方案描述文本输入到预设的方案文本生成模型,通过所述方案文本生成模型生成并输出技术方案参考文本。
具体地,选取预设的方案文本生成模型和预设的文本预测与生成算法,以结构一致的专利文本为输入训练专利文本生成模型。所述预设的方案文本生成模型具体为:根据固定文本输入格式训练生成的lstm(long-shorttermmemory,长短期记忆模型)模型和rgu(gatedrecurrentunit,门控循环单元)模型。
对所述关键词组进行筛选组合,生成技术方案描述文本,其中,所述技术方案描述文本例如为对于需要提出的新专利进行一句描述,并将此作为方案文本生成模型的输入,从而通过所述方案文本生成模型生成并输出可参考的专利文本。
最终可通过人工干预的方式对自动化生成的可参考的专利文本进行筛选,得出最佳理想解,从而产生出新的专利。
综上所述,本发明实施例可以针对输入的技术问题查询最相关的技术方案,生成有助于创新构思的关键词组,自动化生成技术方案参考文本,达到充分利用现有专利的知识和技术,启发人们创造性思维,进一步提升人们创新效率的目的,解决“创新难”、“创新少”的问题,最终实现技术方案创新和创新方案数量的倍增。所以,本发明有效克服了现有技术中的种种缺点而具高度产业利用价值。
上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何熟悉此技术的人士皆可在不违背本发明的精神及范畴下,对上述实施例进行修饰或改变。因此,举凡所属技术领域中包括通常知识者在未脱离本发明所揭示的精神与技术思想下所完成的一切等效修饰或改变,仍应由本发明的权利要求所涵盖。
- 还没有人留言评论。精彩留言会获得点赞!