基于完全矫正Boosting和子空间学习算法的步态识别方法与流程
本发明属于计算机视觉领域,尤其涉及一种基于完全矫正boosting和子空间学习算法的步态识别方法。
背景技术:
步态识别技术在远距离身份识别方面具有巨大的应用的前景,步态识别的目的就是通过对人体运动的图像序列进行分析处理,从而实现对个体的身份识别。一个完整的步态识别技术包括运动检测、周期检测、特征提取、算法识别这四个过程。
特征提取与分类是步态识别技术中的关键步骤,直接影响到步态识别的最终识别性能。实际中获得的原始数据分布在高维空间中,难以进行相关的计算与分析,因此需要进行数据降维。
在常用降维算法中,主成分分析方法及线性判别分析易受到视野遮挡,角度,服饰,路面情况等因素的限制和影响。例如在测试对象服饰情况变动较大的情况下,这类算法就无法有效地进行特征提取以供进行步态识别。局部线性嵌入方法和局部保持投影方法可以较好地处理训练样本,但这两种算法容易导致过拟合,以致识别率急剧下降。为了解决这一问题,研究学者提出了利用boosting算法,随机抽取多个局部线性子空间的子空间集成学习方法,这种方法的原理是训练多个弱分类器,同时通过随机抽取增强分类器间的独立性来提高分类器的分类准确率,再采用boosting算法来提高分类算法的准确度。但是,采用该种方法需要生成大量的局部线性子空间,因此效率较低。同时boosting算法要求事先必须知道弱分类算法的正确率下限,因此难以应用于实际问题中。
此外,现行的多数子空间学习方法的识别性能对所选训练样本集依赖性强,在针对高维图像空间有限训练样本集的情况下难以获得最优子空间,影响了特征提取的准确率以及步态识别的识别性能。
技术实现要素:
针对现有主流子空间学习方法在进行特征提取过程中存在的不足,本发明结合图嵌入框架,提出了一种基于完全矫正boosting和子空间学习算法的步态识别方法,其包括以下步骤:
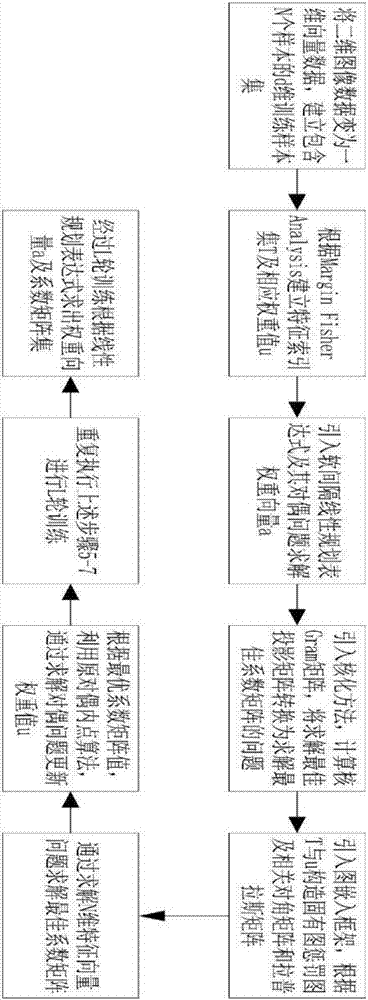
步骤1:将二维图像数据转换为一维向量数据;
步骤2:利用获得的一维向量建立包含n个样本的d维训练样本集x;
步骤3:根据边际fisher分析的原理构造特征索引集t,令m=|t|表示集合t的基数,初始权重值um=1/m;
步骤4:引入软间隔线性规划表达式将求解目的权重向量a的问题转换为形如lpboost算法的线性规划表达式及其拉格朗日对偶的求解问题;
步骤5:利用列生成算法的方式生成一个d维矩阵φt,将求解目的d×qt大小的投影矩阵vt的问题转换为求解该d维矩阵φt的前qt个最大特征值对应的特征向量的问题;
步骤6:基于集合t以及对应的权重值[um]构造固有图g={x,s}及惩罚图gp={x,sp},其中x是顶点集,s及sp是对应图的相似矩阵;构造对应图的相似矩阵s及sp;构造对应图的对角矩阵d,dp,及拉普拉斯矩阵l,lp;
步骤7:利用步骤6获得的矩阵化简矩阵φt的表达式,通过矩阵的左乘右乘运算,将φt表示为一个n维矩阵ψt的运算表达式,矩阵ψt的维度远小于矩阵φt的维度;
步骤8:通过求解n维矩阵ψt的前qt个最大特征值对应的特征向量得到d维矩阵φt的前qt个最大特征值对应的特征向量,即可求解ψl条件下对应的最佳投影矩阵vl;
步骤9:根据拉格朗日对偶问题的求解更新权重值um的值;
步骤10:重复执行步骤6、7、8、9进行l轮训练;
步骤11:根据步骤4中的线性规划表达式,利用l轮训练后的结果计算得到目的权重向量a=[a1,...,al]t;利用步骤8中得到的最佳投影矩阵经过l轮训练获得投影矩阵集
前述方案针对的是原始数据可分的情况,针对原始数据非线性可分的情况,本发明进一步提出了利用核方法的子空间集成学习算法,其原理是将原始空间中的数据变换到高维甚至是无穷维hilbert空间以使数据线性可分。该方法包括以下步骤:
步骤1:将二维图像数据转换为一维向量数据;
步骤2:利用获得的一维向量建立包含n个样本的d维训练样本集x;
步骤3:根据边际fisher分析的原理构造特征索引集t,令m=|t|表示集合t的基数,初始权重值um=1/m;
步骤4:引入软间隔线性规划表达式将求解目的权重向量a的问题转换为形如lpboost算法的线性规划表达式及其拉格朗日对偶的求解问题;
步骤5:根据核方法的原理得到核gram矩阵k的表达式:kij=k(xi,xj)=φ(xi)·φ(xj),计算矩阵k的具体值;
步骤6:根据核方法的原理令投影矩阵vt=φat,其中φ=[φ(x1),φ(x2),...,φ(xn)],at是系数矩阵,从而将求解投影矩阵的问题转换为求解最优系数矩阵的问题;
步骤7:基于集合t以及对应的权重值[um]构造固有图g={x,s}及惩罚图gp={x,sp},其中x是顶点集,s及sp是对应图的相似矩阵;构造对应图的相似矩阵s及sp;构造对应图的对角矩阵d,dp,及拉普拉斯矩阵l,lp;
步骤8:利用步骤5中的表达式重写矩阵φt的表达式,将求解最优系数矩阵at列向量的问题转换为求解n维矩阵φt的前qt个最大特征值对应的特征向量的问题;
步骤9:利用新的表达式通过拉格朗日对偶问题更新权重值um的值;
步骤10:重复执行步骤7,8,9进行l轮训练;
步骤11:利用l轮训练根据步骤4中的线性规划表达式计算得到目的权重向量a=[a1,...,al]t;利用步骤7得到系数矩阵集
本发明具有以下有益效果:
本发明利用完全矫正boosting算法与集成学习的原理通过多次迭代得到多个不同权重分布的子空间,解决了现有技术在进行数据降维与分类时在有限训练集情况下难以得到最优子空间的问题,提升了特征提取的准确率,从而提高了步态识别的识别性能。用usfhumanid数据库中的数据进行实验,利用完全矫正boosting算法的子空间集成学习比单一的子空间学习算法识别率更高。
附图说明
图1是本发明的基本算法流程图;
图2是对本发明基本算法进行核方法拓展的算法流程图。
具体实施方式
下面结合附图对本发明进行详细说明。
如图1所示为本发明的基本算法流程图。本发明的完全矫正boosting和子空间集成学习算法的步态识别方法包括以下步骤:
步骤1:将二维图像数据转换为一维向量数据。
步骤2:利用获得的一维向量建立包含n个样本的d维训练样本集x。
步骤3:根据marginfisheranalysis的原理构造特征索引集t,令m=|t|表示集合t的基数,初始权重值um=1/m。
步骤4:引入软间隔线性规划表达式将求解目的权重向量a的问题转换为形如lpboost算法的线性规划表达式及其拉格朗日对偶的求解问题。
步骤5:利用列生成算法的方式生成一个d维矩阵φt,将求解目的d×qt大小的投影矩阵vt的问题转换为求解该d维矩阵φt的前qt个最大特征值对应的特征向量的问题。
步骤6:基于集合t以及对应的权重值[um]构造固有图g={x,s}及惩罚图gp={x,sp},其中x是顶点集,s及sp是对应图的相似矩阵,其包括:
(1):构造对应图的相似矩阵s及sp
(2):构造对应图的对角矩阵d,dp,及拉普拉斯矩阵l,lp。
步骤7:利用上步获得的矩阵化简矩阵φt的表达式,通过矩阵的左乘右乘运算,将φt表示为一个n维矩阵ψt的运算表达式,矩阵ψt的维度远小于矩阵φt的维度。
步骤8:通过求解n维矩阵ψt的前qt个最大特征值对应的特征向量得到d维矩阵φt的前qt个最大特征值对应的特征向量,即可求解ψl条件下对应的最佳投影矩阵vl。
步骤9:根据拉格朗日对偶问题的求解更新权重值um的值。
步骤10:重复执行步骤6,7,8,9进行l轮训练。
步骤11:根据步骤4中的线性规划表达式,利用l轮训练后的结果计算得到目的权重向量a=[a1,...,al]t;利用步骤8中得到的最佳投影矩阵经过l轮训练获得投影矩阵集
本发明结合图嵌入框架,提出的用于步态识别当中的全新的利用完全矫正boosting算法技术的子空间集成学习方法,实现了高分类识别率的子空间集成学习,以提高特征提取的准确率,从而提高步态识别系统的整体性能。
上述方案针对的是原始数据可分的情况。对于原始数据非线性可分的情况,本发明进一步提出了利用核方法的子空间集成学习算法,其流程图如图2所示,其原理是将原始空间中的数据变换到高维甚至是无穷维hilbert空间以使数据线性可分。以下详细介绍该方法的具体实现步骤:
步骤1:将二维图像数据转换为一维向量数据。
步骤2:利用获得的一维向量建立包含n个样本的d维训练样本集x。
步骤3:根据marginfisheranalysis的原理构造特征索引集t,令m=|t|表示集合t的基数,初始权重值um=1/m。
步骤4:引入软间隔线性规划表达式将求解目的权重向量a的问题转换为形如lpboost算法的线性规划表达式及其拉格朗日对偶的求解问题。
步骤5:根据核方法的原理得到核gram矩阵k的表达式:kij=k(xi,xj)=φ(xi)·φ(xj),计算矩阵k的具体值。
步骤6:根据核方法的原理令投影矩阵vt=φat,其中φ=[φ(x1),φ(x2),...,φ(xn)],at是系数矩阵,从而将求解投影矩阵的问题转换为求解最优系数矩阵的问题。
步骤7:基于集合t以及对应的权重值[um]构造固有图g={x,s}及惩罚图gp={x,sp},其中x是顶点集,s及sp是对应图的相似矩阵,其中包括:
(1):构造对应图的相似矩阵s及sp。
(2):构造对应图的对角矩阵d,dp,及拉普拉斯矩阵l,lp。
步骤8:利用步骤5中的表达式重写矩阵φt的表达式,将求解最优系数矩阵at列向量的问题转换为求解n维矩阵φt的前qt个最大特征值对应的特征向量的问题。
步骤9:利用新的表达式通过拉格朗日对偶问题更新权重值um的值。
步骤10:重复执行步骤7,8,9进行l轮训练。
步骤11:利用l轮训练根据步骤4中的线性规划表达式计算得到目的权重向量a=[a1,...,al]t;利用步骤7得到系数矩阵集
本发明的算法框架旨在求解权重向量a=[a1,...,al]t,及投影矩阵集
下面对本发明的具体实施进行详细说明。
(一)将二维的图像数据i进行转换,将其转换为一维向量数据。利用这些数据构造一个包含n个样本的d维训练样本集
(二)利用marginfisheranalysis筛选特征索引集t的元素,构造特征索引集
基数,定义权重值um=1/m。根据特征索引集t,权重向量及投影矩阵必须对t中任
意数据集满足如下公式(1):
其中
(三)定义一个向量hm=[hmt],hmt对应投影矩阵vt以及集合t中的第m个集(im,jm,km),表达式见公式(2):
(四)为了最终得到权重向量,采用如下的软间隔线性规划表达式:
其中ζm为引入的松弛变量,d为惩罚因子且
利用kkt条件进行简化得到如下表达式:
(五)利用列生成算法将投影矩阵vt的计算问题转化为如下形式的子问题求解:
通过简单的矩阵运算,得到表达式(6)的目标函数:
tr()表示矩阵的求迹运算。定义一个d×d大小的矩阵φt:
根据表达式(8),求解最优投影矩阵vt的问题转化为求解矩阵d维矩阵φt的前qt个最大特征值对应的特征向量的问题,矩阵vt的列向量即为矩阵φt的前qt个最大特征值对应的特征向量。
(六)基于集合t和对应的权重值u构造两个有向加权图:固有图g={x,s},惩罚图g={x,sp},其中x是顶点集,s是固有图的d×d维的相似矩阵,sp是惩罚图的n×n维的相似矩阵,分别定义两个相似矩阵中的元素如下:
分别定义固有图及惩罚图的对角矩阵和拉普拉斯矩阵d,dp,l,lp如下:
其中
(七)根据(六)中的表达式,可将矩阵φt重新写为如下表达式:
当矩阵φt的维度d较大时,无法直接求解其特征值,因此定义一个n维的矩阵ψt,n远小于d,ψt=(lp-fl)xtx,同时令矩阵ψt满足如下表达式:
ψtv=(lp-fl)xtxv=λv(13)
在该表达式的两端同时左乘矩阵x,得到如下表达式:
因此通过求解n维矩阵ψt的前qt个最大特征值对应的特征向量即可得到d维矩阵φt的前qt个最大特征值对应的特征向量,从而计算出投影矩阵。
(八)利用计算出的投影矩阵通过表达式(2)计算对应的hmt,将hmt代入表达式(5)的对偶问题中,利用原对偶内点算法更新权重值um。
(九)重复执行步骤(六)(七)(八)进行l轮训练。
(十)经l轮训练后利用表达式(3)计算目的权重向量a=[a1,...,al]t,利用表达式(14)得到投影矩阵
对于原始数据线性可分的情况利用上述步骤即可实现对权重向量a及投影矩阵vt的求解,对于原始数据非线性可分的情况本发明引入核方法拓展的算法,核方法的具体执行步骤如下:
(十一)对于利用核方法的子空间集成学习框架,引入n维核gram矩阵k,kij=k(xi,xj)=φ(xi)·φ(xj)。引入d×n矩阵φ,φ=[φ(x1),φ(x2),...,φ(xn)]。则投影矩阵vt可表示为φ中元素的线性组合:vt=φat(15)。
(十二)执行上述步骤(一)(二),同时计算核gram矩阵k。
(十三)执行上述步骤(六),生成固有图和惩罚图及相关矩阵。
(十四)将表达式(15)代入表达式(2)中,可得到新的hmt的表达式:
其中k.i表示矩阵k的第i列列向量。根据表达式(15)目标函数表达式(7)可以重新写成包含矩阵at与矩阵k的形式:
因此表达式(12)中的矩阵φt可以重新写为如下形式:
φt=(lp-fl)k(18)
则可通过求解n维矩阵φt的特征向量来求解系数矩阵at,矩阵φt的前qt个最大特征值对应的特征向量即为最优系数矩阵at的列向量。
(十五)根据表达式(16)计算hmt的值,然后将其代入表达式(5)的对偶问题中,利用原对偶内点算法更新权重值um。
(十六)重复执行步骤(十三)(十四)(十五)进行l轮训练。
(十七)经l轮训练后利用表达式(3)计算目的权重向量a=[a1,...,al]t,利用表达式(18)得到系数矩阵集
本发明利用完全矫正boosting算法与集成学习的原理通过多次迭代得到多个不同权重分布的子空间,解决了现有技术在进行数据降维与分类时在有限训练集情况下难以得到最优子空间的问题,提升了特征提取的准确率,从而提高了步态识别的识别性能。用usfhumanid数据库中的数据进行实验,利用完全矫正boosting算法的子空间集成学习比单一的子空间学习算法识别率更高,同时该子空间集成学习的核化版本比原始版本的识别率更高。
需要注意的是,上述具体实施例是示例性的,本领域技术人员可以在本发明公开内容的启发下想出各种解决方案,而这些解决方案也都属于本发明的公开范围并落入本发明的保护范围之内。本领域技术人员应该明白,本发明说明书及其附图均为说明性而并非构成对权利要求的限制。本发明的保护范围由权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!