一种基于强化学习的车辆跟驰模型建立方法与流程
本发明涉及一种基于强化学习的车辆跟驰模型建立方法,属于汽车无人驾驶技术领域。
背景技术:
汽车的发明加快了人员、物资、信息的流动,缩短了空间距离,节约了时间,加快了社会的发展,具有里程碑意义。同时,带来了严重的社会问题和环境问题。例如,在汽车行驶过程中,驾驶员需要精神高度集中,不断在加速状态和减速状态之间切换汽车的状态,增加了交通事故发生的可能性。
无人驾驶汽车是降低交通事故发生率和驾驶强度,实现交通事故接近零伤亡的行之有效的手段。现有的车辆跟驰决策模型能够很好地描述有人驾驶汽车的跟驰决策行为,但无法很好地描述无人驾驶汽车的跟驰决策行为。无人车辆跟驰技术的应用可以把驾驶员从高强度的驾驶操作中解脱出来,避免交通事故的发生。跟驰模型的研究始于1950年,60多年来国内外研究人员对车辆跟驰模型进行了大量的研究,取得了众多的研究成果,其中比较典型的理论模型有gipps模型,idm模型,krauss模型,wiedemann模型,元胞自动机模型。
gipps模型是微观交通流模型中被广泛使用的一种安全距离模型。该模型能够比较真实的反映汽车的走停行为,同时,通过道路上实际观测的数据,很容易对模型中的参数进行校验。由于所需要的参数少,计算简单,该模型在实际中有着广泛的应用,如英国的sistm,美国的varsim都使用此模型。但是,避免碰撞的假设与实际情况存在一定的差距。在实际的驾驶中,驾驶员并没有完全按照安全距离行驶。
idm模型是一种基于刺激-响应方法的模型,它计算瞬时加速度。idm模型中的刺激是当前距离差和需求距离差的差距比率,跟驰车辆试图追上远离的前导车辆,或者跟驰车辆因前导车辆越来越近而减速。但是idm模型是一种纯确定性的模型,仅基于确定性刺激来获取瞬时加速度,因此它无法对不合理行为进行建模。krauss是一种纯刺激-响应的模型,它在时间上是离散的。krauss试图对人类个别的、不合理的反应进行建模。该模型使用随机参数来描述idm模型无法模拟的特征。这种随机变量具有高效的物理建模能力,能够建模加速情形,并提供与驾驶员行为一致的模型。该模型在sumo中使用。
wiedemann模型是德国karlsruhe大学的wiedemann于1974年建立的一种心理-物理模型。不同的驾驶员可能对同一个刺激产生不同的反应。例如,如果驾驶员离某辆车很远或者很近,那么他对相对距离变化的反应肯定会不同。该模型把驾驶状态分为4类,从而描述驾驶员可能所处的状态,控制对同一刺激的反应:自由驾驶、接近模式、跟随模式、制动模式。但是驾驶员的驾驶行为是一个复杂的过程,受心理、物理、环境等因素的影响。不同的驾驶员对速度和距离变化的感觉和评价是不同的,因此该模型很难进行校验。
元胞自动机模型在空间和时间上是离散的,从而减少了计算的复杂度。该模型把交通系统描述为大小相同的元胞晶格,使用一些规则来控制车辆在元胞之间移动。元胞能够承载单个车辆,并且能使车辆在下一个时间步内移动到下一个元胞。但是,模型中的车辆跟驰规则毕竟与真实的车辆驾驶行为存在较大的差距。
在实现本发明的过程中,发明人发现现有的跟驰模型方法至少存在以下问题:(1)现有的车辆跟驰模型方法是基于经验公式,通过人为地设定模型参数来描述车辆的跟驰行为,由于跟驰行为的复杂性,人为设定的参数不能反映车辆真实的跟驰行为;(2)现有的跟驰模型,无论是针对有人驾驶车辆的跟驰模型还是针对无人驾驶车辆的跟驰模型,都没有考虑无人驾驶汽车的特性及其对有人驾驶汽车的影响,由于汽车驾驶员已经习惯了有人驾驶汽车的反应时间而无人驾驶汽车的反应时间极短,当汽车驾驶员前方的无人驾驶汽车突然停止时,后方驾驶员往往因为来不及刹车而造成追尾等交通事故;(3)现有的车辆跟驰模型方法基于数据驱动,需要大量的数据验证模型的正确性,但是很难保证所使用的数据包含了所有的特殊状态;(4)基于现有的车辆跟驰模型方法作出的决策往往不是最优决策。
技术实现要素:
为了克服现有技术中存在的不足,本发明目的是提供一种基于强化学习的车辆跟驰模型建立方法。该方法首先观察无人驾驶车辆所处环境的状态,然后对无人驾驶车辆在所处环境状态下所选择的动作对当前环境状态及未来的影响进行评价;重复这个过程直到无人驾驶汽车每次选择的动作都是最优的。该方案以较低的计算时间开销,无需人为设定参数,无需数据驱动,并且所选择的动作具有最优性。
为了实现上述发明目的,解决已有技术中存在的问题,本发明采取的技术方案是:一种基于强化学习的车辆跟驰模型建立方法,包括以下步骤:
步骤1、定义经验缓存d、创建q值网络,设置存储经验的经验缓存d={mi,mi+1,...,mi+n-1}的容量为n,式中mi表示第i步到第i+1步环境从一个状态转换到另一个状态的一次转换样本,mi+1表示第i+1步到第i+2步环境从一个状态转换到另一个状态的一次转换样本…mi+n-1表示第i+n-1步到第i+n步环境从一个状态转换到另一个状态的一次转换样本,创建q值网络,q值网络采用多层感知器网络,q值表示目标车辆的长期回报;
步骤2、随机初始化环境中所有车辆位置、速度、加速度和环境状态,环境状态作为q值网络的输入;
步骤3、选择并执行动作,记录转移样本,计算长期回报,以概率ε随机选择一个动作,其中ε可通过公式(1)计算得到,
式中,t表示当前时间步数,执行该动作并观察环境状态和立即奖励,再将环境从一个状态转换到另一个状态的转换样本m=(s,a,s',r)加入到经验缓存中,其中,
式中,hfront表示执行动作前目标车辆与前方车辆的时距,hrear表示执行动作前目标车辆与后方车辆的时距,x表示执行动作前目标车辆的位置,xfront表示执行动作前目标车辆前方车辆的位置,xrear表示执行动作前目标车辆后方车辆的位置,l表示目标车辆的车长,lfront表示目标车辆前方车辆的车长,lrear表示目标车辆后方车辆的车长,v表示执行动作前目标车辆的速度,vfront表示执行动作前目标车辆前方车辆的速度,vrear表示执行动作前目标车辆后方车辆的速度;
其中,
式中,h'front表示执行动作后目标车辆与前方车辆的时距,h'rear表示执行动作后目标车辆与后方车辆的时距,x'表示执行动作后目标车辆的位置,x'front表示执行动作后目标车辆前方车辆的位置,x'rear表示执行动作后目标车辆后方车辆的位置,l表示目标车辆的车长,lfront表示目标车辆前方车辆的车长,lrear表示目标车辆后方车辆的车长,v'表示执行动作后目标车辆的速度,v'front表示执行动作后目标车辆前方车辆的速度,v'rear表示执行动作后目标车辆后方车辆的速度,δt表示时间步长,afront表示目标车辆前方车辆的加速度,arear表示目标车辆后方车辆的加速度,a表示目标车辆的加速度,其范围为a∈[-3.0,2.0],每个加速度之间间隔为0.1,单位为m/s2;
其中,立即奖励r可通过公式(4)计算得到,
式中,
式中,r表示立即奖励,γ表示折扣因子,γ∈[0,1],q(s',a')表示在执行动作后的环境状态s'下选择加速度a'的q值;
步骤4、更新q值网络权重,对误差函数loss进行一次梯度下降,可以通过公式(6)计算得到,
loss=[y-q(s,a)]2(6)
式中,q(s,a)表示在执行动作前的环境状态s下选择加速度a的q值,将执行动作后的环境状态赋给执行动作前的环境状态,即s=s',其中梯度下降方法包括,adagrad、rmsprop及adam;
步骤5、步数是否超过最大时间步数,重复步骤3至步骤4,直到步数超过最大时间步数timestepmax的值或碰撞;
步骤6、步数是否超过最大回合数,重复步骤2至步骤5,直到步数超过最大回合数episodemax的值。
本发明有益效果是:与已有技术相比,本发明具有以下优点,(1)该模型建立方法是智能车辆在不断地学习和探索中得到,与传统的人为设定模型参数、对真实驾驶数据进行拟合相比,不需要预先设定参数和提供驾驶数据。(2)该模型建立方法不但对安全的跟驰行为进行了学习和探索,并且对可能会导致交通事故的跟驰行为也进行了学习和探索,传统的基于驾驶数据的模型使用的驾驶数据是安全跟驰行为的驾驶数据,没有可能会造成交通事故的跟驰行为的驾驶数据,也没有对可能会造成交通事故的跟驰行为进行研究和建模;(3)该模型建立方法不但考虑了周围车辆对目标车辆的影响,而且考虑了目标车辆的行为对周围车辆的影响,传统的车辆跟驰模型方法只考虑了周围车辆对目标车辆的影响。(4)该模型建立方法考虑了无人驾驶汽车和有人驾驶汽车的区别,与传统只考虑无人驾驶汽车或只考虑有人驾驶汽车的跟驰模型相比,能有效地减少追尾交通事故;(5)该模型建立方法基于强化学习,作出的决策是最优的,传统的车辆跟驰模型方法作出的决策不是最优的。
附图说明
图1是本发明方法步骤流程图。
图2是本发明中的卷积神经网络结构图。
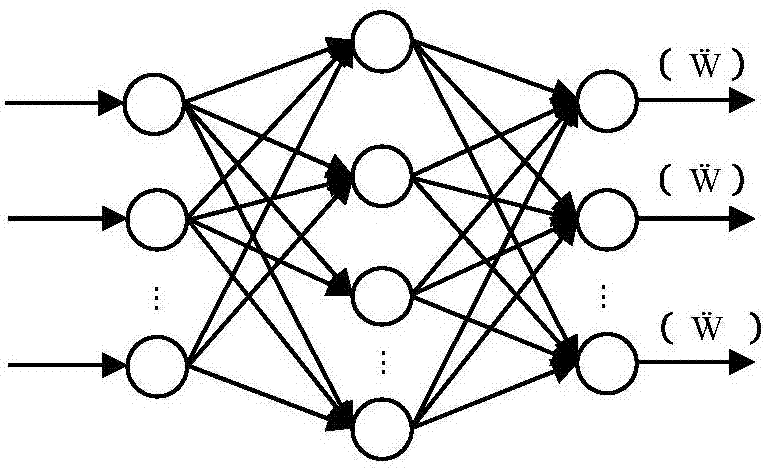
图3是本发明中的q值网络结构示意图。
具体实施方式
下面结合附图对本发明作进一步说明。
如图1所示,一种基于强化学习的车辆跟驰模型建立方法,包括以下步骤:
步骤1、定义经验缓存d、创建q值网络,设置存储经验的经验缓存d={mi,mi+1,...,mi+n-1}的容量为n,式中mi表示第i步到第i+1步环境从一个状态转换到另一个状态的一次转换样本,mi+1表示第i+1步到第i+2步环境从一个状态转换到另一个状态的一次转换样本…mi+n-1表示第i+n-1步到第i+n步环境从一个状态转换到另一个状态的一次转换样本,创建q值网络,q值网络采用多层感知器网络,q值表示目标车辆的长期回报;
步骤2、随机初始化环境中所有车辆位置、速度、加速度和环境状态,环境状态作为q值网络的输入;
步骤3、选择并执行动作,记录转移样本,计算长期回报,以概率ε随机选择一个动作,其中ε可通过公式(1)计算得到,
式中,t表示当前时间步数,执行该动作并观察环境状态和立即奖励,再将环境从一个状态转换到另一个状态的转换样本m=(s,a,s',r)加入到经验缓存中,其中,
式中,hfront表示执行动作前目标车辆与前方车辆的时距,hrear表示执行动作前目标车辆与后方车辆的时距,x表示执行动作前目标车辆的位置,xfront表示执行动作前目标车辆前方车辆的位置,xrear表示执行动作前目标车辆后方车辆的位置,l表示目标车辆的车长,lfront表示目标车辆前方车辆的车长,lrear表示目标车辆后方车辆的车长,v表示执行动作前目标车辆的速度,vfront表示执行动作前目标车辆前方车辆的速度,vrear表示执行动作前目标车辆后方车辆的速度;
其中,
式中,h'front表示执行动作后目标车辆与前方车辆的时距,h'rear表示执行动作后目标车辆与后方车辆的时距,x'表示执行动作后目标车辆的位置,x'front表示执行动作后目标车辆前方车辆的位置,x'rear表示执行动作后目标车辆后方车辆的位置,l表示目标车辆的车长,lfront表示目标车辆前方车辆的车长,lrear表示目标车辆后方车辆的车长,v'表示执行动作后目标车辆的速度,v'front表示执行动作后目标车辆前方车辆的速度,v'rear表示执行动作后目标车辆后方车辆的速度,δt表示时间步长,afront表示目标车辆前方车辆的加速度,arear表示目标车辆后方车辆的加速度,a表示目标车辆的加速度,其范围为a∈[-3.0,2.0],每个加速度之间间隔为0.1,单位为m/s2;
其中,立即奖励r可通过公式(4)计算得到,
式中,
式中,r表示立即奖励,γ表示折扣因子,γ∈[0,1],q(s',a')表示在执行动作后的环境状态s'下选择加速度a'的q值;
步骤4、更新q值网络权重,对误差函数loss进行一次梯度下降,可以通过公式(6)计算得到,
loss=[y-q(s,a)]2(6)
式中,q(s,a)表示在执行动作前的环境状态s下选择加速度a的q值,将执行动作后的环境状态赋给执行动作前的环境状态,即s=s',其中梯度下降方法包括,adagrad、rmsprop及adam;
步骤5、步数是否超过最大时间步数,重复步骤3至步骤4,直到步数超过最大时间步数timestepmax的值或碰撞;
步骤6、步数是否超过最大回合数,重复步骤2至步骤5,直到步数超过最大回合数episodemax的值。
- 还没有人留言评论。精彩留言会获得点赞!