基于Bootstrap的变权重模型组合预测方法与流程
本发明涉及工程结构疲劳寿命预测,尤其是涉及基于bootstrap的变权重模型组合预测方法。
背景技术:
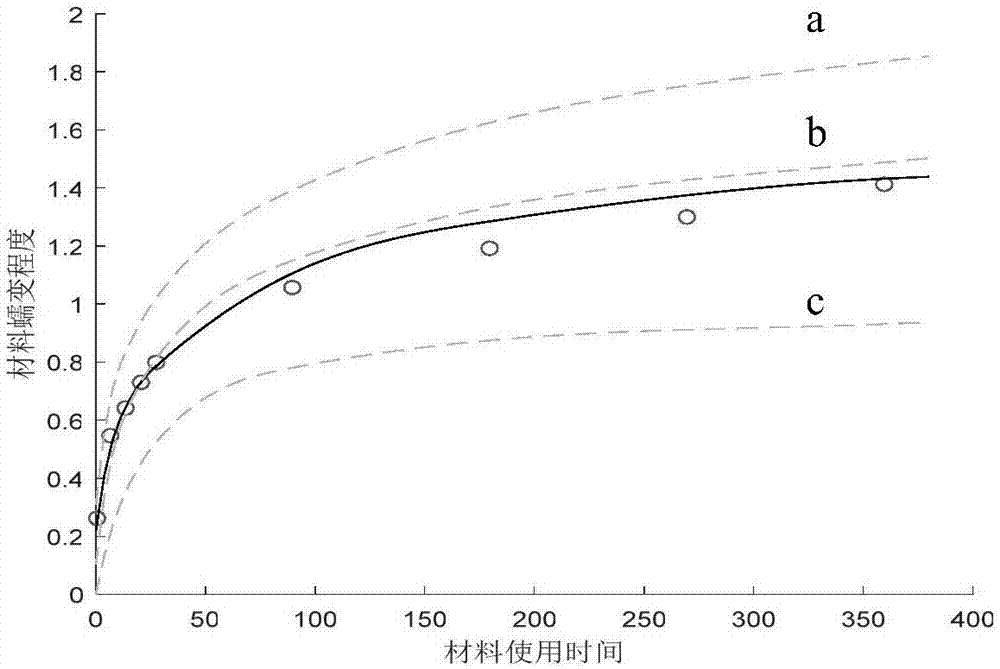
:众所周知,工程结构构件随着应力周期性变化而经历疲劳裂纹的形成及扩展、直至失效断裂,从而导致工程结构功能性失效,发生疲劳破坏。工程结构构件的疲劳是个复杂的过程,受多种因素的影响,要精确地预估构件的疲劳寿命,需要选择合适的模型进行预测,存在不确定性,不仅需要宏观力学方面的研究,包括疲劳裂纹发生、发展直至破坏的机理,还需要微观力学方面的研究包括位错理论等,此外,还涉及到蠕变现象、金属材料科学、力学、疲劳理论和计算方法等多门学科。只有更深刻地认识了疲劳破坏的机理,综合多种因素,将宏观和微观研究结合起来,才能使预测结果更合理,可靠。通常,所能得到的几个合适模型都具有一定优点,单单取最优的单模型对疲劳寿命进行预估得到的结果往往并不是很理想,于是在工程结构上的疲劳寿命预测需要采用综合各模型的属性与优点赋与相应的权重,通过拟合权重得到权重函数,进行变权重模型合并预测。然而,传统变权重模型合并预测方法未对所做预测做出一个区间范围评定。技术实现要素:本发明针对现有技术的缺点,提供以达到预测快捷性、区间性的目的的基于bootstrap的变权重模型组合预测方法。本发明包括以下步骤:1)数据获取,具体方法如下:在特定环境下对工程结构构件试样进行蠕变试验,记录随时间变化试样中发生的蠕变量,得到待处理的工程结构构件蠕变量数据,运用bootstrap方法对合并数据进行k次再抽样,得到k组再抽样样本数据;2)根据所预测的数据类型选用所属的至少2种不同的单模型预测方法来预测试样中发生的蠕变量,记各单项模型预测方法为gi(x),(i=1,2,…,m),由各种单模型预测方法得到的不同的工程结构构件试样蠕变样本的预测结果;3)建立变权重的多模型合并预测总模型,基于预测误差最小,使用得到的k组再抽样样本数据,建立优化问题求解权重函数wi(x)的待定系数,并对权重函数wi(x)进行归一化处理,得到k组不同的wi(x),代入即可得到k个不同的变权重预测总模型,根据待预测的输入量,由预测总模型可得到对应预测结果,进而得到了k组变权重模型合并预测结果;在步骤3),所述建立变权重的多模型合并预测总模型的具体步骤可为:(1)建立单预测模型gi(x),(i=1,2,…,m)对应的权重函数的待定方程wi(x),其可为一次或二次多项式形式:wi(x)=pi0+pi1x或wi(x)=pi0+pi1x+pi2x2;(2)建立变权重模型合并预测模型:(3)建立优化问题:0≤wi(xj)≤1(4)求解优化问题得到权重函数的待定系数:(5)对权重函数进行归一化处理:其中为若wi(x)为负值,则赋值为0,若为非负值,则赋值为wi(x);(6)基于归一化权重函数建立变权重模型合并预测总模型:4)使用得到的k组变权重模型合并预测结果,采用百分位法,可得到变权重模型预测方法的百分位置信区间预测;在步骤4)中,所述使用得到的k组变权重模型合并预测结果,采用百分位法,可得到变权重模型预测方法的百分位置信区间预测的具体方法可为:使用k个变权重预测总模型进行预测,得到k个对应输入xp的预测结果yp,将k组预测结果进行排序,[yp1,yp2,…,ypk],对每个数据点的预测结果采用百分位法求得预测置信区间,即:置信水平为1-α的置信区间估计为其中和为经验百分位数,分别对应于每个数据点的预测结果的第和第个值。在步骤1)中,所述运用bootstrap方法所使用的抽样方法为有放回的抽样;所述k次再抽样的值并不做限定,k值越大,所得置信区间可靠性越高。本发明的有益效果是:所述一种针对工程结构疲劳寿命的基于bootstrap与变权重模型合并预测方法,建立优化问题,根据合并区域数据的特征计算得到各个模型的权重函数,不同模型的预测方法合并起来,充分利用各单项预测模型所包含的有用信息,将模型合并的权重取值与变量取值关联起来,提高预测精度;结合bootstrap方法获得置信区间预测,极大提高了算法的合理性和可靠性,使用方便,能有效提高经济效益,更加符合实际工程需要。附图说明图1为基于bootstrap与变权重模型合并预测方法的流程图。图2为变权重模型合并预测方法与其他3个单项模型预测方法对比图。在图1中,标记a为模型1,b为模型2,c为模型3,○为样本数据,—为变权重模型合并预测结果。图3为基于bootstrap与变权重模型合并预测方法的预测置信区间图。在图3中,标记○为样本数据,……为变权重模型合并预测结果。具体实施方式下面结合说明书附图,对本发明作详细描述。图1是本发明的流程图,本发明所述的一种针对工程结构疲劳寿命的基于bootstrap与变权重模型合并预测方法,通过充分利用各单项预测模型所包含的有用信息,将模型合并的权重取值与变量取值关联起来,提高预测精度;结合bootstrap方法获得置信区间预测,包括以下步骤:本实施例中,选用钢骨混凝土试样进行的蠕变试验得到的数据进行具体说明。步骤1:数据获取:在特定环境下对钢骨混凝土试样进行蠕变试验,记录随时间变化试样中发生的蠕变量,得到待处理的钢骨混凝土蠕变量数据,运用bootstrap方法对合并数据进行k次再抽样,得到k组再抽样样本数据。钢骨混凝土蠕变量数据如表1所示,数据分成两个部分,合并区域的数据用于求解权重函数,预测区域的数据用于和预测结果进行对比验证。表1试样蠕变实验数据步骤2:根据所预测的数据类型选用所属的至少2种不同的单模型预测方法来预测试样中发生的蠕变量,记各单项模型预测方法为gi(x),(i=1,2,…,m),由各种单模型预测方法得到的不同的钢骨混凝土蠕变样本的预测结果。本实施例中,当前用来预测混泥土蠕变系数的可选合理模型选用3种:aci-209、asshto、ceb-fip;步骤3:建立变权重的多模型合并预测总模型,基于预测误差最小,使用得到的k组再抽样样本数据,建立优化问题求解权重函数wi(x)的待定系数,并对权重函数wi(x)进行归一化处理,得到k组不同的wi(x),代入即可得到k个不同的变权重预测总模型,根据待预测的输入量,由预测总模型可得到对应预测结果,进而得到了k组变权重模型合并预测结果。具体过程如下:步骤3-1:建立单预测模型gi(x),(i=1,2,…,m)对应的权重函数的待定方程wi(x),其可为一次或二次多项式形式:本实施例中,采用二次的权重函数的待定方程:wi(x)=pi0+pi1x+pi2x2步骤3-2:建立变权重模型合并预测总模型:步骤3-3:建立优化问题:0≤wi(xj)≤1步骤3-4:求解优化问题得到权重函数的待定系数:步骤3-5:对权重函数进行归一化处理:其中为若ωi(x)为负值,则赋值为0,若为非负值,则赋值为ωi(x)。步骤3-6:得到变权重模型合并预测的模型:步骤4:使用得到的k组变权重模型合并预测结果,采用百分位法,可得到变权重模型预测方法的百分位置信区间预测。具体过程如下:步骤4-1:使用k个变权重预测总模型进行预测,得到k个对应输入xp的预测结果yp,将k组预测结果进行排序,[yp1,yp2,…,ypk],对每个数据点的预测结果采用百分位法求得预测置信区间,即:置信水平为1-α的置信区间估计为其中和为经验百分位数,分别对应于每个数据点的预测结果的第和第个值。置信水平为0.9的变权重模型合并预测方法的置信区间预测结果如表2所示。表2bootstrap预测方法的置信区间时间(day)2890180270360材料蠕变系数0.7961.0541.1891.2971.41置信上界0.8171.1971.3991.5041.571置信下界0.7431.0271.1491.2051.241图2给出了变权重模型合并预测方法与其他3个单模型预测结果的对比,从图2可以看出,变权重模型合预测方法预测的结果比单项模型预测方法更精确,预测效果更佳。图3给出了基于bootstrap与变权重模型合并预测方法得到的预测置信区间。可以看出,在该实例中所得预测区间包含了实验结果值。置信区间的预测为预测结果实现了区间范围评定,改进了原有算法的合理性且提供更多的信息。因此,本发明能够直接提高工程结构疲劳寿命预测方法的预测精度,实现工程结构疲劳寿命预测方法的区间范围评定,解决了目前工程结构疲劳寿命预测效果差、未求解预测置信区间的问题;算法简单,并且通用性较好,可以提高预测结果的说服力。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1